
基于私有云和物理机的混合型大数据平台设计及实现
2018-03-06 11:05王永坤金耀辉
计算机工程与科学 2018年2期
王永坤,罗 萱,金耀辉,2
(1.上海交通大学网络信息中心,上海 200240;2.上海交通大学光纤通信国家重点实验室,上海 200240)
1 引言
随着社会对大数据分析技术的需求日益高涨,用于支撑大数据分析的底层数据平台技术也得到了长足的发展。开源社区提供了很多开源技术方案,例如Apache Hadoop、Apache Hive[1]、Apache Spark[2]来解决数据的存储、查询和计算,并且有专门公司提供企业级服务。在数据平台之上,提供了Hue、Jupyter、Zepplin等交互计算接口,并提供基本的访问控制。很多厂商也基于大数据分析技术的标准框架,提供了建立在云上的大数据平台方案,包括国外的亚马逊云AWS(Amazon Web Services)、谷歌云平台大数据产品、微软云(Azure)上的Hadoop,国内有阿里云大数据服务Max Compute、天池、及数加、腾讯大数据、百度大数据+。云上的解决方案可扩展性强,可以满足用户不断变化的需求。
虽然这些云平台上的数据平台方案规模大、技术水平高、可扩展性高,但是相对而言成本也比学校等非盈利机构的内部平台要高,而且涉及的知识产权问题等较严格,数据开放共享的难度较大。因此,我们的目标是能完全独立地使用开源社区的解决方案来搭建一个数据平台,以较低的成本来搭建高性能、可扩展的数据平台,而且不被任何一种私有技术锁定。
为了实现这一目标,接下来介绍我们的混合数据平台设计:基于私有云和物理服务器的混合数据平台设计。将数据平台建立在云上具有管理简单、可扩展性好等优点,但是性能损失较大。在2016年10月于巴塞罗那举办的Openstack峰会上有用户报告了基于KVM(Kernel-based Virtual Machine)云主机方案的数据平台,运行Spark异常检测任务(Spark Anomaly Detection Job),所用的时间是基于物理服务器上的数据平台的近2倍(1.95×)(基于容器(Nova-LXD等)的方案会大大减少额外开销,运行Spark异常检测任务用时是物理服务器数据平台的1.1倍(10%的额外开销)。但是,考虑到用户对各种云主机需求的多样性以及平台的稳定性,我们的私有云平台使用了基于KVM的解决方案)。出于高性能的数据处理考虑,我们将数据平台的主体部分搭建在物理服务器上。当数据平台的处理能力不足时,动态扩展到我们的私有云平台上。
我们的平台完全使用开源软件,自己选取设计组件,自己搭建和运维。开源软件代码公开并且由开源社区维护,适合高校这种IT经费相对较少但是智力资源较多的环境。我们的平台用于校内及部分公开服务,也定期提供给数据大赛这种大规模、高强度、集中式、密集计算的场景使用。在这样的应用场景下,我们的混合数据平台设计方案可以很好地兼顾性能和弹性使用需求。
根据我们了解,这在国内外高校中也是一种大胆的尝试,希望我们的经验可以给其它院校和机构一些参考。
我们的贡献概括如下:
(1)设计了一种混合的数据平台架构:数据平台的主体运行在物理服务器上,当资源不足时,动态扩展到内部的私有云平台上;
(2)选取硬件并配置了生产环境,给出基本的评测结果验证了这种设计的可行性;
(3)使用这种混合数据平台服务了校内外的用户,并介绍了其中的经验和见解。
2 背景及相关工作
2.1 异构数据实时采集、计算和存储
得益于各行各业信息化的普及和物联网的发展,各行各业的数据量正以惊人的速度增长。同时,因为数据源不同,数据格式也多种多样,呈现异构特征。如何采集、传输和计算大量异构的数据是一个非常大的挑战。Apache Kafka是一个分布式的数据传输和共享系统。Apache Flume、Fluentd等都是广泛应用的数据采集传输工具。
不同的数据源会生成不同的数据,形成多维数据,数据字段和格式不相同。对有些数据如交换机流量甚至需要自己定义如何从数据流中分割出数据包。由于数据生成速度快而且数据量较大,不适合使用传统的文件系统和关系型数据库。需利用分布式的文件系统来进行实时存储,并且选取的分布式文件系统需要很好地支持后续的计算。例如谷歌设计了GFS(Google File System)[3]来作分布式存储。开源社区也开发了分布式文件系统HDFS(Hadoop Distributed File System),广泛用于各个大数据存储处理场景。目前流行的企业内部的数据湖(Data Lake)的做法也一般使用HDFS来做存储。
2.2 异构数据的计算
对于海量多源异构数据,不太适合使用传统的关系型数据库来存储和查询。所以,谷歌公司设计了名为BigTable[4]的数据模型,变schema-on-write为schema-on-read,数据可以非常灵活地以动态的标签或者列名来存储。谷歌公司同时提出了MapReduce[5]的分布式计算模型,通过使用Map和Reduce操作,可以非常方便地将计算扩展到大量机器上。开源社区也跟进开发了Hadoop系统来实现MapReduce操作,并使用HBase等NoSQL系统来存储无结构化数据。
2.3 按需分配、灵活可扩的云平台
云计算在过去10年中得到了长足的发展,技术相对比较稳定。在传统的服务器操作系统层面,Xen、KVM以及后续的容器技术已经发展成为稳定的生产级别可用的技术。特别是KVM技术,有Redhat等Linux操作系统主要发行商支持,作为生产环境有很大的稳定性保障。随着虚拟数据中心技术的兴起,也诞生了很多虚拟数据中心的开源项目,特别是Openstack,被IBM、HP、VMware等大公司共同推广和维护,成为建设虚拟数据中心和云计算平台的主流框架。
Openstack等云计算框架是“基础设施即服务IaaS(Infrastructure as a Service)”的具体实现,可以提供灵活的虚拟数据中心方案。它提供了计算、存储、网络、镜像、认证、计量等管理模块以及其他模块,用户可以非常方便地创建自己的虚拟网络,启动虚拟主机并挂载虚拟硬盘,开始自己的业务,无需担心底层的实现和运维。虚拟主机和存储等模块支持动态扩展和扩容,当用户发现自己的资源紧张的时候,可以随时请求更多的CPU、内存、存储以及虚拟机等资源。因此,云平台对处理复杂多变的需求非常有效,这也是我们选择将云平台作为数据平台动态扩展池的主要原因。
3 混合数据平台架构设计
根据已有成熟的开源软件框架,搭建了数据平台和私有云平台。所有组件都是开源免费的。系统的总体架构如图1所示。具体组件及设计考虑会在下面几节展开介绍。

Figure 1 Architecture of hybrid data platform图1 混合数据平台架构
3.1 总体架构
混合型数据平台的总体架构如图1所示。一部分按数据平台要求设计的物理服务器被专职用作数据平台计算和存储(图1中标记Big Data的虚线框内的服务器)。另外一部分物理服务器按照云计算的要求定制后,专职用做云计算的场景(图1中标记Private Cloud的虚线框内的服务器)。两批服务器通过多个冗余的接入交换机接到数据中心网络中。两个集群的一部分服务器共享接入交换机,通过Rack aware的配置让管理员和系统知道数据所处的网络位置,为云和数据平台之间的数据交换提供了高速通道。
3.2 私有云平台架构
校级云平台架构如图2所示。底层是基础设施层,采用了时下业界流行的Openstack框架来实现软件定义网络、弹性计算以及软件定义存储等功能。关于软件定义存储,我们将Openstack的块存储模块Cinder和对象存储开源软件Ceph结合起来,将存储资源虚拟化成存储池,实现了块存储、对象存储和文件存储三种服务形式,为虚拟机或者其他用户需求提供灵活稳定的存储服务。
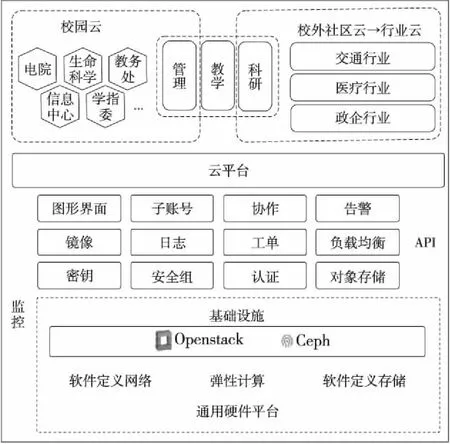
Figure 2 Architecture of private cloud图2 云平台架构及组件
关于计算模块,我们使用了Openstack计算管理模块Nova,并且用KVM来作为虚拟机的实现。我们并没有选用性能更好的容器,是出于稳定性和操作系统的多样性考虑。在物理服务器上,我们使用了开源Linux操作系统的服务器发行版CentOS。
在图2的中间部分,可以看到各种虚拟基础设施的管理功能,基本是标准的Openstack开源组件,例如镜像管理模块Glance、网络管理模块Neutron、认证管理模块Keystone和界面模块Horizon等。我们对前端访问做了负载均衡设计,对数据库组件做了高可用设计,保障业务平稳运行。我们也进行了部分定制,保证和校园内的其他业务能够无缝链接起来。
3.3 数据平台架构
设计的数据平台如图3所示。中间部分是数据平台的核心组件,包括Hadoop的HDFS和YARN(Yet Another Resource Negotiator)资源调度管理器,都做了高可用设计,特别是针对控制结点使用了高可用方案。下面详细介绍各部分的设计和考虑。

Figure 3 Architecture of big data platform图3 大数据平台架构及组件
3.3.1 文件系统
使用Hadoop的分布式文件系统HDFS来储存数据。HDFS的控制结点NameNode存储了文件系统的元数据,因此NameNode需要提供高可用的热备功能来保证NameNode长时在线。HDFS内置了NameNode HA的实现。默认使用的是ZKFC(ZooKeeper Failover Controller),使用Apache Zookeeper集群来做同步锁。
数据平台也采用默认的HA方案。使用两台物理结点(并且部署在不同机架上)来启动两个NameNode,配置三个结点为日志结点(JournalNode),用于在两个NameNode之间同步数据。使用ZKFC和Zookeeper集群来保证只有一个活跃NameNode结点,当活跃NameNode无响应时主动切换到备用的NameNode。
3.3.2 高可用作业调度系统
使用Hadoop YARN来做调度器,自动调度和部署用户的任务到不同机器上运行。资源管理器(ResourceManager)是YARN的一个重要组件,负责为所有的任务调度资源,因此资源管理器也需要高可用HA配置。在两个结点分别配置两个一样的资源管理器,使用内置的、利用Zookeeper集群的热备系统来自动检测失败的资源管理器,并切换到活跃的资源管理器上。
3.3.3 查询和计算
支持大部分的计算框架,包括将SQL转换为MapReduce任务的Apache Hive、使用RDD(Resilient Distributed Datasets)[6]的Spark计算框架以及原生的MapReduce和Streaming任务。对于不习惯命令行的用户,也提供了HUE来很方便通过网页提交查询、查看任务进展和查看结果或出错信息。对于习惯使用IPython[7]Notebook风格来进行数据分析的用户,也搭建了Jupyter Hub和Zepplin,让用户使用Python Notebook或者Spark Notebook来进行交互式的数据分析。
3.3.4 数据集成
对于如何将数据导入到数据平台中,使用以下三种方式:
对于流式数据,使用Apache Kafka来实时进行数据分享和交换,同时将数据导入到数据平台的Hadoop中来做离线计算;
对于结构化数据,使用Apache Sqoop来选取相关的数据表并且尽量按照原来的表结构存储到数据平台的Hadoop中;
对于其它的各种以文件形式存在的数据,在进行格式转换后上传至数据平台中。
3.3.5 其它配置
访问控制方面,使用Kerberos[8]来验证用户的身份。对文件系统,根据文件的用户和分组来进行访问控制;对于Hive查询,也使用Sentry来实现访问控制。
针对监控,部署了Zabbix、Grafana以及netdata,可以非常方便地查看整个系统资源的实时和历史使用状况。
另外,备份和恢复是每个系统必须考虑的问题。在应用程序层(HDFS)默认设置了三个数据副本,这样既实现了高可用和高访问吞吐量,也在一定程度上实现了数据的备份。三个数据副本分别在不同机架的不同机器中,避免了机器或者机架不可用时丢失数据的情况。很多元数据保存在关系型数据库MySQL中,设计了MySQL集群来保证其高可用性,同时也做定期的备份。
3.4 混合数据平台
本节介绍混合数据平台工作调度器调度策略。在我们的数据平台上有一个调度器,监控集群负载,通过启动或者停止虚拟机来弹性分配或者释放私有云上的计算资源。调度器的工作流程如图4所示。
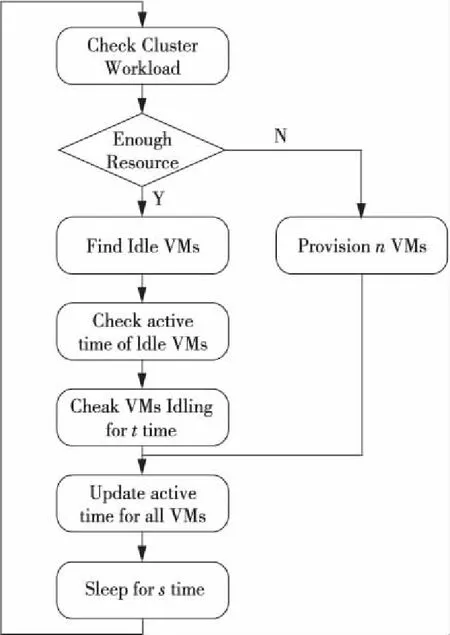
Figure 4 Flow of controller for allocating new VMs图4 调度器工作流程
从图4可以看到,调度器是个无限循环精灵进程,检查集群的负载。如果资源不够,则从云上分配n个虚拟机VM(Virtual Machine)。基于数据三副本的考虑,每次分配的虚拟机数目n是3的倍数。如果本次分配虚拟机数n过小,不能满足新任务的需求,则在下面几个循环中会很快补足;如果本次分配虚拟机数过多,则在后面的循环中会被不断回收。也通过不断学习用户提交任务的历史数据,根据时间动态调整每次分配的虚拟机个数,避免每次都过多或者过少地分配虚拟机。虚拟机分配好后,这些新分配的虚拟机,和已经存在的虚拟机,它们的活跃时间(Active Time)被更新为当前时间。如果本次循环发现集群资源充裕,则找出空闲的虚拟机,检查这些空闲的虚拟机的活跃时间与当前时间的差值,空闲超出一定阈值t的虚拟机被释放。阈值t是根据集群历史负载和当前负载情况动态计算出来的,这样可以避免频繁分配和释放虚拟机。
一般地,仅从云上补充计算资源。关于存储,涉及数据的迁移,结点间的数据需要再平衡,网络带宽可能会成为瓶颈,所以除了本地读写可以加速的任务,一般不推荐使用数据存储弹性方案。
4 应用评估
本节介绍如何根据需求选取服务器来搭建生产环境,并作了基本的评估。
4.1 数据平台部署
对数据平台的服务器,我们简单地按功能分为两大类:一类是控制结点;另一类是计算和存储结点。控制结点需要存取元数据,对内存和存储性能要求较高。所以,使用大内存结点(256 GB),存储介质使用了4+块高性能、大容量的闪存固态盘SSD(Sold State Drives),这些固态盘配置成磁盘阵列RAID10模式(磁盘组内是RAID1,磁盘组间是RAID0),容错能力比较好。计算和存储结点的存储容量要求较高,为了更好地利用磁盘空间,给每个结点选用了12块6TB的磁盘,并且配置成JBOD(Just a Bunch of Disks)模式,对于数据安全和负载平衡,则通过数据平台软件在多机间实现。另外,对所有结点都额外配置了2块10 KRPM 600 GB热插拔硬盘,将其配置成RAID1给操作系统使用。结点间使用了双路万兆网卡互联。在操作系统内使用动态链路聚合模式将两路链接聚合起来,带宽加倍可达到20 Gbps。两种服务器配置如表1所示。第一期我们购置了16台服务器,包括4台控制结点、12台计算和存储结点,总存储容量接近900 TB。第二期在2017年底会扩容10倍,后期计划扩容至目前规模的30倍左右。

Table 1 Specifications of servers for big data platform
Openstack云平台主要为校内约6万师生教职工的科研、教学活动提供服务,同时作为数据平台的弹性扩展池,在数据平台资源匮乏时,也提供计算资源。目前整个集群有40台2U服务器,第二期在2017年底会扩容4~5倍。
4.2 测试配置
本节的目的是验证混合数据平台可以按照预期来提供服务。数据平台基本组件都是基于开源软件和推荐配置,所以我们的目的不是和其他平台进行性能比较。我们的目的是对系统进行测试以验证性能和功能符合预期,并且提供结果给用户来估计任务耗时。有关数据平台的性能测试,学术界、产业界和开源社区已经有大量很好的工作。有关测试工具,用户可以参考中国科学院计算技术研究所的BigDataBench[9]以及英特尔公司的HiBench[10]。本文选择HiBench 5.0版本来进行测试。
本文测试的主要软件版本如表2所示。

Table 2 Software configuration
使用MapReduce任务来测试数据平台,因为我们发现很多用户仍然使用MapReduce (或者间接通过Hive产生MapReduce任务),并且MapReduce任务执行时间较长,对CPU、内存、网络资源都有需求。限于篇幅没有展示对内存、磁盘使用优化得更好的Spark框架的评估结果。
4.3 测试及分析
下面几个测试的场景是:物理集群的资源已经全部被用户任务占满,新来的任务要么等在调度队列中,要么分到很小的资源配额来缓慢运行。物理集群资源用完后才分配虚拟机来扩展,理由如下:如果物理集群的资源未饱和时,添加私有云虚拟机并调度任务的部分或者全部子任务到云主机上运行,被调度到云上的任务的完成时间可能会变长,因为物理集群的性能要远远高于云主机(云主机服务器的CPU进行了超售Over provision,即云主机的云CPU性能一般是要低于物理机的CPU,云主机间的网络带宽也被限速至0.5 Gbps,而物理集群内部是双万兆聚合,可达20 Gbps。也在考虑给大数据平台的扩展虚拟机进行特殊的网络设置,提高带宽,这是将来的工作)。所以,一般在物理集群资源用尽后才扩展到私有云上,这样充分利用了物理集群的处理能力,又避免了与云上用户争夺资源。
4.3.1 可扩展性测试
在本节想确认系统的处理能力是否会随着虚拟机的不断加入而不断增强。通过运行相同的任务,但是不断添加计算资源,来观察任务的执行时间,从而判断系统的处理能力是否得到增强。通过停止或者压测物理集群上的计算结点来使物理集群的资源不可用,从而使集群任务调度器YARN把子任务调度到新增加的虚拟机上来,以验证新添加的资源的有效性及可扩展性。
图5显示了可扩展性测试的结果。分别启动3个、6个、9个虚拟机(8个云CPU核16 GB内存,下同),然后由物理集群的YARN调度HiBench中的Terasort排序任务,使用Hadoop MapReduce框架执行。可以明显看出,随着虚拟机个数的增多,任务的执行时间急剧减少。这符合我们的预期。用集群中的三台物理机做了对比(两个CPU共32线程、128 GB内存),图5也验证了物理机的性能要远远高于虚拟机的。所以,在资源有空余的情况下,会优先把用户的任务调度到物理机上。
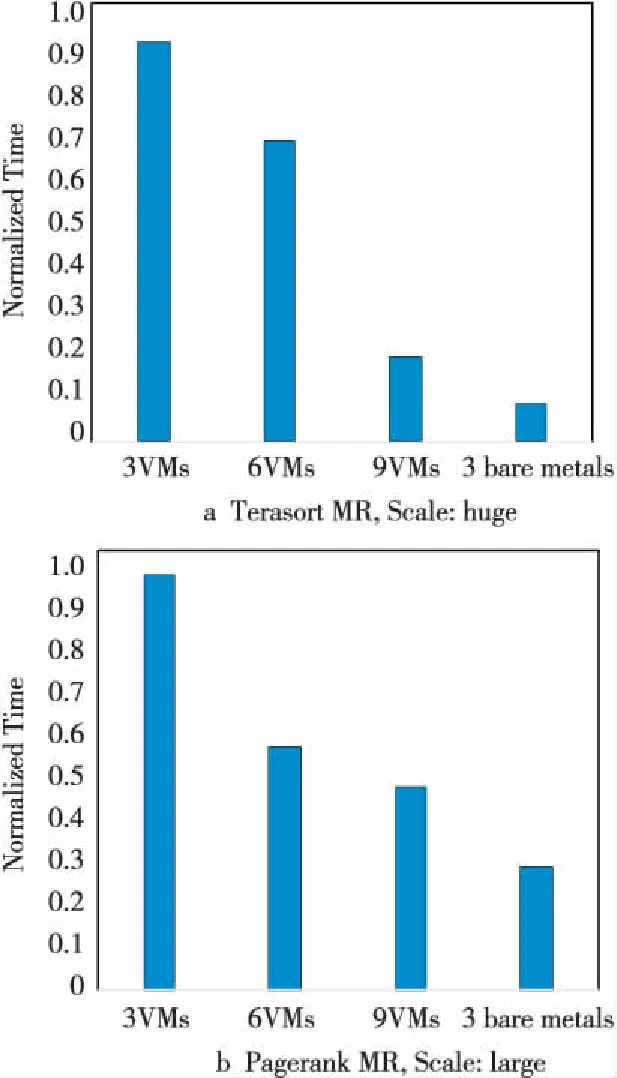
Figure 5 Scalability test (Hibench Scale:huge)图5 可扩展性测试 (HiBench扩展度:huge)
通过图5观察到性能增加并非是线性的,这是由任务的特性决定的,下一节将专门进行分析。
4.3.2 负载类型测试
上节根据用户任务对计算、磁盘、网络等资源使用的使用情况,将用户任务简单分为计算密集型和IO密集型两种。计算密集型的任务主要消耗CPU和内存,而IO密集型任务则需要更多的磁盘存取操作和网络传输操作。
排序测试Terasort在使用MapReduce框架时涉及大量的磁盘读写和网络传输。从图5a中可以看到,即使云主机的IO性能与物理机差距很大,但是在增加虚拟机结点个数后,性能仍然得到不断提升。

Figure 6 Evaluation with mixed tasks (Scale:large)图6 混合任务测试 (扩展度:large)
Pagerank排序算法涉及很多迭代过程,是计算密集型任务。图5b也显示了当虚拟机个数不断增加时,Pagerank任务的执行时间也不断减少。
从图5也看到,增加虚拟机的个数,性能并非线性增加,这是由任务的本身特性决定的。增加资源只能减少高并发度子任务的运行时间,其他部分的时间并没有减少。例如,Pagerank算法,初始时有很多并行的子任务,需要大量的计算资源,因此增加虚拟机个数显著增加了并行度,所以前期的计算时间显著减少。后期部分不断迭代收敛时,不需要很多计算资源,而且后期迭代次数是比较稳定的,所以即使前期高度并行计算部分的时间大大减少了,但是后面迭代的时间并没有改变,所以总的执行时间不会减少太多。这就是我们从图5b中看到的从6 VMs到9 VMs时,性能提升并不明显。可以预计,再增加更多的虚拟机,性能提升也不明显。但是,如果我们增大任务的并行度需求,例如增大数据量,增加虚拟机后性能提升仍然是非常显著的。
4.3.3 混合任务测试
在本节模拟多用户同时执行各类型任务的场景。HiBench 5.0默认是顺序启动任务,前面任务结束后再启动下一个任务。我们稍微改动了HiBench 5.0的任务启动脚本,让所有任务同时启动执行。这些任务包括Aggregation、Kmeans、Pagerank、Wordcount、Bayes和Terasort。执行的时间长短也不一,既有几分钟即可完成的任务,如Wordcount,也有长达几小时的任务,如Bayes。
图6展示了同时启动多个不同类型负载后的执行时间。我们可以看到,各种任务混合在一起,随着虚拟机资源的增大(3 VMs到9 VMs),执行时间明显缩短,处理能力不断提升。
我们又观察到了性能增加并非是线性的,即从6 VMs到9 VMs,性能增加不显著。上一节专门做了分析,此处原因类似。我们认为,增大数据量,提高并行度,对资源需求量明显增大,那么增加资源后性能提升的效果才会明显。
4.3.4 物理集群和虚拟机共同执行任务
前文给出的性能测试结果是在物理集群负载饱和时扩展到云主机后的场景。本节也简单讨论一下物理集群未满载时启动云虚拟机这种场景。直观上讲,添加云主机对资源需求较大的任务是有帮助的,特别是一些并行度较大、子任务间通信较少的任务(云主机之间带宽远小于物理集群)。然而,对并行度不大但是迭代和归并通信要求较多的场景,添加云虚拟机并不会提高性能,因为云虚拟机的CPU的性能没有物理服务器好,特别地,云虚拟机的网络带宽被限制在0.5 Gbps,而物理集群的网络带宽是20 Gbps,远高于云主机的带宽。图7给出了物理集群负载未饱和状态下的扩展性测试结果。可以看到单纯使用物理机器(3BMs)集群时,性能比后面添加虚拟机性能要好。这也验证了我们的猜测。所以,我们只在物理集群负载饱和的状态下添加云虚拟机来接收新负载。我们在不断探索各种负载类型,寻找最优的场景使用云虚拟机来扩展集群;也在探讨使用专门的网络来连接两个集群,消除网络带宽的瓶颈。
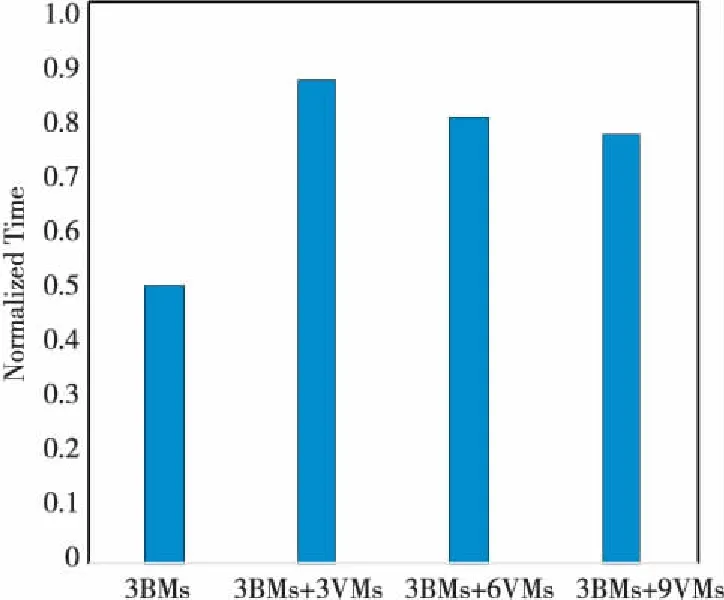
Figure 7 Scalability test when bare metal cluster is not fully loaded (Terasort MR,Scale:huge.Data Nodes are started on VMs)图7 物理集群未饱和状态下的扩展性测试 (Terasort MR,HiBench扩展度:huge,云主机上数据结点也启动起来)
4.3.5 虚拟机及数据平台程序启动时延
在生产环境中,我们目测到的启动时延约为数秒。我们并没有进行精确的定量分析,因为面向的场景一般是高负载持续数十分钟或数小时甚至更长时间段。
在我们的测试中,虚拟机及数据平台程序数秒的启动延时对性能加速的影响很小,可以忽略不计。我们也有兴趣在将来研究在极端情况下(例如云平台负载很高的情况下),用于扩展的虚拟机的启动时延及其他因素的影响;我们也有兴趣测试频繁启动和销毁扩展虚拟机时系统的加速情况。限于篇幅,在此不作讨论。
5 生产应用
目前我们使用数据平台集群支撑了校内上网行为分析、基因序列拼接、自然语言处理研究以及各种数据比赛,包括大规模的上海开放数据创新应用大赛SODA(Shanghai Open Data Apps),具体细节可以参考我们2016年的工作[11]。数据平台以项目或者课题组申请的方式来申请使用,不开放给个人申请,以保证重要的项目及课题组能有充分的资源。对分散的个人任务,我们推荐在私有云上搭建自己的平台进行小规模测试和分析。目前数据平台在平时的磁盘使用量为20 TB以上(三副本约60 TB以上)。上线一年多累计运行了1万多个用户分析任务。
6 结束语
尝试完全使用开源软件设计并配置了一个弹性数据平台。该数据平台主要构筑在物理服务器上,保证了分析性能,当资源紧张时,可以动态扩展到私有云平台上。私有云平台也是同样基于开源软件构建的。构建了生产环境并服务了广大师生,以及社会上的专业赛事。使用开源的评测工具给出了初步的分析结果并提供了我们的见解。将来会更加深入地测试多个影响调度性能的因素。
[1] Thusoo A,Sarma J,Jain N,et al.Hive-A warehousing solution over a map-reduce framework[J]. Proceedings of the VLDB Endowment, 2009 2(2):1626-1629.
[2] Zaharia M,Chowdhury M,Franklin M J,et al.Spark:Cluster computing with working sets[C]∥Proc of the 2nd USENIX Workshop on Hot Topics in Cloud Computing,2010:10.
[3] Ghemawat S,Gobioff H,Leung S.The Google file system[C]∥Proc of the 19th ACM Symposium on Operating Systems Principles,2003:29-43.
[4] Chang F,Dean J,Ghemawat S,et al:Bigtable:A distributed storage system for structured data[C]∥Proc of the 7th Symposium on Operating Systems Design and Implementation(OSDI 2006),2006:205-218.
[5] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C]∥Proc of the 6th Symposium on Operating System Design and Implementation (OSDI 2004),2004:137-150.
[6] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:A fault-tolerant abstraction for in-memory cluster computing[C]∥Proc of the 9th USENIX Symposium on Networked Systems Design and Implementation,2012:15-28.
[7] Bernard J. Running scientific code using IPython and SciPy[J].Linux Journal,2013(228):Article No.3.
[8] Neuman B C,Ts’o T. Kerberos:An authentication service for computer networks[J].IEEE Communications,1994,32 (9):33-38.
[9] Wang Lei, Zhan Jian-feng, Luo Chun-jie, et al.BigDataBench:A big data benchmark suite from internet services[C]∥Proc of the 20th IEEE International Symposium on High Performance Computer Architecture,2014:488-499.
[10] Huang S, Huang J, Dai J,et al.The HiBench benchmark suite:Characterization of the MapReduce-based data analysis[C]∥Proc of the 26th International Conference on Data Engineering,2010:41-51.
[11] Wang Yong-kun, Jin Yao-hui.Design of data platform and application in data competition [J/OL].Journal of Frontiers of Computer Science and Technology,2017-04-12. [2017-09-25].http://kns.cnki.net/kcms/detail/11.5602.TP.20170412.1115.002.html.(in Chinese)
[12] Bhardwaj A P,Deshpande A,Elmore A J,et al.Collaborative data analytics with dataHub[J].Proceedings of the VLDB Endowment,2015:1916-1919.
[13] Armbrust M,Xin R S,Lian C,et al.Spark SQL:Relational data processing in Spark[C]∥Proc of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD’15),2015:1383-1394.
[14] Melnik S,Gubarev A,Long J,et a.Dremel:Interactive analysis of web-scale datasets[J].Communications of the ACM,2011,54(6):114-123.
[15] Johnson T.Performance measurements of compressed bitmap indices[C]∥Proc of the 25th International Conference on Very Large Data Bases (VLDB’99),1999:278-289.
[16] DeCandia G,Hastorun D,Jampani M,et al.Dynamo:Amazon’s highly available key-value store[C]∥Proc of the 21st ACM Symposium on Operating Systems Principles, 2007:205-220.
附中文参考文献:
[16] 王永坤,金耀辉.数据平台的设计和实现以及大赛中的应用[J/OL].计算机科学与探索,2017-04-12. [2017-09-25].http://kns.cnki.net/kcms/detail/11.5602.TP.20170412.1115.002.html.
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
军事运筹与系统工程(2019年4期)2019-09-11
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
