
基于改进型MBF的命名数据网PIT存储结构研究
2018-03-03 07:35许亚平刘开华马东来杨奕康
重庆邮电大学学报(自然科学版) 2018年1期
许亚平,李 卓,刘开华,马东来,杨奕康
(1.天津大学 微电子学院,天津 300072;2.天津师范大学 天津市无线移动通信与无线能量传输重点实验室,天津 300387;3.中国铁塔股份有限公司,山西 大同 037000)
0 引 言
近年来,互联网规模呈现爆发性增长的趋势,超高清视频以及人工智能技术不断发展,使用户不再满足于传统的点到点通信方式,而是希望可以广泛分发、共享数据信息。然而基于传统TCP/IP(transmission control protocol/internet protocol)技术的互联网通信模型逐渐暴露出IP地址空间耗尽、移动性差等弊端,使得无法满足用户对于高质量通信的要求。为了应对这些不足,一种新型未来网络架构命名数据网(named data networking,NDN)[1]被提出。与传统的 TCP/IP网络不同,NDN使用面向数据内容的通信方式,以内容名称代替IP地址,不再关心内容存储在哪里,而仅关心内容本身[2]。NDN通过在网络节点部署缓冲存储器,极大地提高了网络资源的共享率,降低了网络负载,提升了数据传输的性能。
NDN中的通信由数据消费者驱动,通过交换携带内容名称的兴趣包和数据包来实现[1]。消费者通过向网络发送一个兴趣包来向数据提供者请求数据。当NDN路由器接收到兴趣包后,路由器转发平面中的待定 Interest 表(pending interest table, PIT)[1]则会记录兴趣包的名称以及来源端口。当提供者发送的数据包到达路由器后,通过检索PIT来获取转发该包的端口,并删除相应记录。路由器无论接收的是兴趣包还是数据包,都需要对PIT进行检索,因此要求PIT具有极高的处理速度。同时,考虑到NDN中内容名称长度不定,结构类似于统一资源定位符(uniform resource locator,URL),远比IP地址复杂,所以PIT需要更多的存储空间来记录兴趣包的名称信息。
为满足PIT对处理速度和存储空间的需求,本文通过巧妙地利用Bitmap提出一种改进的数据结构B-MBF(Bitmap-mapping bloom filter)。同时,在B-MBF的基础上,提出性能高效的PIT存储结构B-MaPIT。该存储结构不但显著地提高了名称检索速度,而且进一步降低了存储消耗。
1 相关研究
针对转发平面中PIT面临的问题,目前研究人员已经提出一些有效的算法。2012年,文献[3]首次提出了名称组件编码(name component encoding,NCE)算法,基于该算法,文献[4]构建名称组件树以降低存储在PIT中大量名称的存储消耗。为进一步减少存储消耗,文献[5]提出Radient组件编码算法。但树形结构的深度会影响检索速度的提高,而且组件和编码之间的映射过程降低了整体的检索性能。文献[6-7]提出基于哈希表检索的算法来提高检索速度,并用名称的哈希值代替名称存储于哈希表以降低存储消耗。然而哈希表作为静态存储,会造成大量存储空间的浪费,且哈希冲突也会影响该算法的性能。为规避树形结构和哈希表的缺点,文献[8-9]提出在PIT结构的每个转发端口部署一个Bloom filter来记录到达该端口的兴趣包。然而,当检索数据包时却不得不查找每一个Bloom filter以获取数据包的转发端口,这样将造成检索时间增加。此外,文献[10]对Bloom filter进行改进,提出了MBF(mapping bloom filter)索引结构,该结构的数据检索时间复杂度与哈希表相同,且其片内存储消耗可以降低到2.097 MByte。但是,该结构的检索性能与PIT要求的线性处理速度仍有一定差距。
2 基于改进型MBF的PIT存储结构B-MaPIT
通过对PIT的相关研究,本节首先总结PIT的设计需求,在此基础上,结合 Bitmap提出一种改进的索引结构B-MBF。其次,基于这种索引结构,提出一种PIT存储结构B-MaPIT,并对其具体的结构、检索算法以及性能进行详细地分析。最后,通过仿真实验,进一步测试和验证了B-MaPIT存储结构在存储消耗,数据表构建速度和吞吐量方面的性能高效性。
2.1 PIT的设计需求
在NDN路由器中,PIT的作用是记录已转发但未得到响应的兴趣包的转发信息。当兴趣包到达路由器转发平面后,PIT为其创建或更新条目,其中,每个条目的内容为:
此外,针对检索过程所使用的匹配算法,由于TCP/IP网络路由器使用的最长前缀匹配算法会消耗更多的处理时间,对于高度动态的PIT来说,该算法不适用。为了提高PIT的数据检索性能,PIT使用基于字符串的准确匹配算法[12]对兴趣包和数据包进行检索。假设,内容名称为/A/B/C的兴趣包或数据包到达,PIT仅需检索名称域content name为/A/B/C的条目,然后针对该包进行相应的处理。
2.2 B-MBF
标准型Bloom filter是空间高效的数据结构,且执行检索的时间复杂度为O(1)。但是Bloom filter只能判断某元素是否在集合中,不能确定该元素的具体物理存储地址。针对Bloom filter的这个缺点,文献[10]对其进行改进,提出了一种衍生数据结构MBF。该结构不仅可以同时支持查找和映射物理存储地址,而且可以极大降低片内存储消耗。
文献[10]中,MBF作为索引结构,由2个比特数组构成:一个标准型Bloom filter和一个定位数组(mapping array,MA)。Bloom filter用于判断某元素是否在MBF中,定位数组的映射数值则作为片外存储单元的偏移地址。为了实现Bloom filter到定位数组的映射,Bloom filter被等分为j部分,定位数组的大小与Bloom filter等分部分数量相同,也为j比特。同时,定位数组的比特位与Bloom filter的每部分一一对应。在元素插入前,定位数组中每一个比特的初始状态都为0。当插入元素到MBF时,如果元素的哈希函数值映射到Bloom filter的某个部分,则其对应的定位数组比特位的数值就被设置为1。通过k个哈希函数到Bloom filter的映射,可以得到定位数组最终的映射数值,即片外存储单元的偏移地址。根据偏移地址,片外存储单元中的元素信息就可以被找到。最后,在下一个元素到来之前,定位数组再次初始化为全0状态。
虽然MBF极大降低了片内存储单元的存储消耗,但是为存储元素信息,该结构必须在片外存储单元部署一个静态存储,且需要预留足够的存储空间等待元素插入,这样将增加片外存储单元的存储消耗,造成大量存储空间的浪费。此外,MBF的检索速度仍与线性处理速度具有一定差距。针对这些不足,本文在MBF的基础上,结合Bitmap提出一种改进的数据索引结构B-MBF,以进一步降低片外存储消耗,改善检索性能。
B-MBF结构由MBF和Bitmap两部分组成,其具体数据结构如图1所示。其中,Bitmap的槽个数和定位数组的大小成指数关系。也就是说,若定位数组大小设定为j比特,那么Bitmap的槽个数将为2j。同时,Bitmap被等分为N个部分,且每个槽的大小由原来的1比特扩展成2字节,最大可存储数值为65 535。因此,在等分Bitmap时,理论上使得每部分的槽个数小于或等于65 536的N值均可取,但为方便管理内存分配,N值应尽量选择可取范围内的最大值。此外,每部分将对应一个动态存储空间。未存入元素前,所有动态存储空间的内存大小都为0,其基地址统一存储在一个指针数组中。需要注意的是,当某元素插入MBF,定位数组的映射数值不再作为片外存储单元的直接偏移地址,而是指示元素在Bitmap中的位置。在元素插入过程中,首先根据定位数组数值计算出元素在Bitmap的第几个部分,以及该部分中的具体位置。随后,按照元素进入该部分的顺序为其标号,该序号则被记录在Bitmap的槽中,作为片外存储单元的地址偏移量。最后,通过该部分的基地址与元素的地址偏移量,为该元素申请内存单元,并将对应的元素信息存储到该内存单元。随着元素的不断插入,片外存储单元为其动态分配内存单元,其存储消耗随元素数量增加而增加,避免了存储空间的浪费。
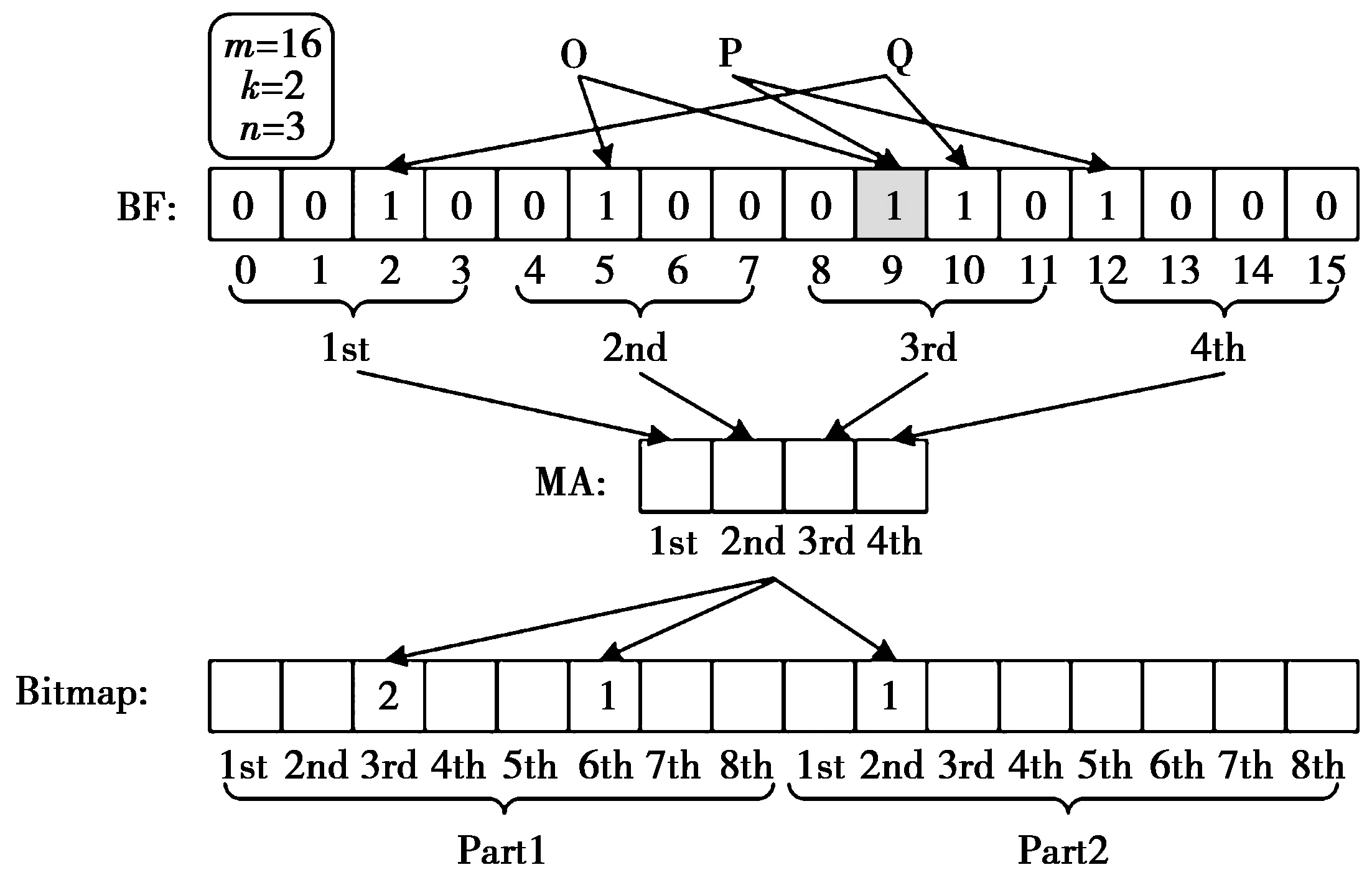
图1 B-MBF索引结构示意图Fig.1 Index structure of B-MBF
同时,在Bloom filter检索过程中,B-MBF采用一个哈希函数对元素进行哈希编码,并将产生的定长二进制序列分为多段,每段二进制序列作为映射Bloom filter的一个哈希函数值。不同于文献[10]中2个哈希函数的计算复杂度,B-MBF仅进行一次哈希运算即可实现多次哈希映射,从而进一步提高了检索速度。
图1给出了B-MBF索引结构执行元素插入的一个例子。假设Bloom filter的大小为16 bit,分为4部分,进行2次哈希映射。与此相应,定位数组被设定为4 bit,Bitmap的槽个数设定为16,并被等分为2部分。在该例子中,3个元素O,P和Q被依次插入到B-MBF,且每个元素插入前,定位数组的初始值都为0。元素O首先插入到MBF中,其定位数组映射数值为0110。其次,根据定位数组数值计算出该元素在Bitmap中的位置为第1部分的第6个槽。作为第1部分的第1个元素,元素O被标记为序号1,并将该序号记录在槽中作为片外存储单元的地址偏移量。与元素O的插入过程相似,元素P的定位数组映射数值为0011,需插入到Bitmap的第1部分的第3个槽,序号被标记为2;元素Q的定位数组映射数值为1010,即对应Bitmap的第2部分的第2个槽,序号被标记为1。
对B-MBF索引结构的检索算法而言,其过程与插入算法相似。此外,为支持删除操作,B-MBF可以为Bloom filter配置一个CBF(counting bloom filter),并在Bloom filter和CBF之间执行同步操作。同时,B-MBF需记录Bitmap中删除的元素序号,当元素序号增加到阈值65 535而不能继续增加时,之后插入的元素则重新使用已删除的序号作为地址偏移量。
2.3 B-MaPIT
2.3.1 B-MaPIT存储结构
针对2.1节中所提到的PIT的特点和需求,本文基于B-MBF数据结构,提出一种性能高效的PIT存储结构B-MaPIT,其具体结构如图2所示。
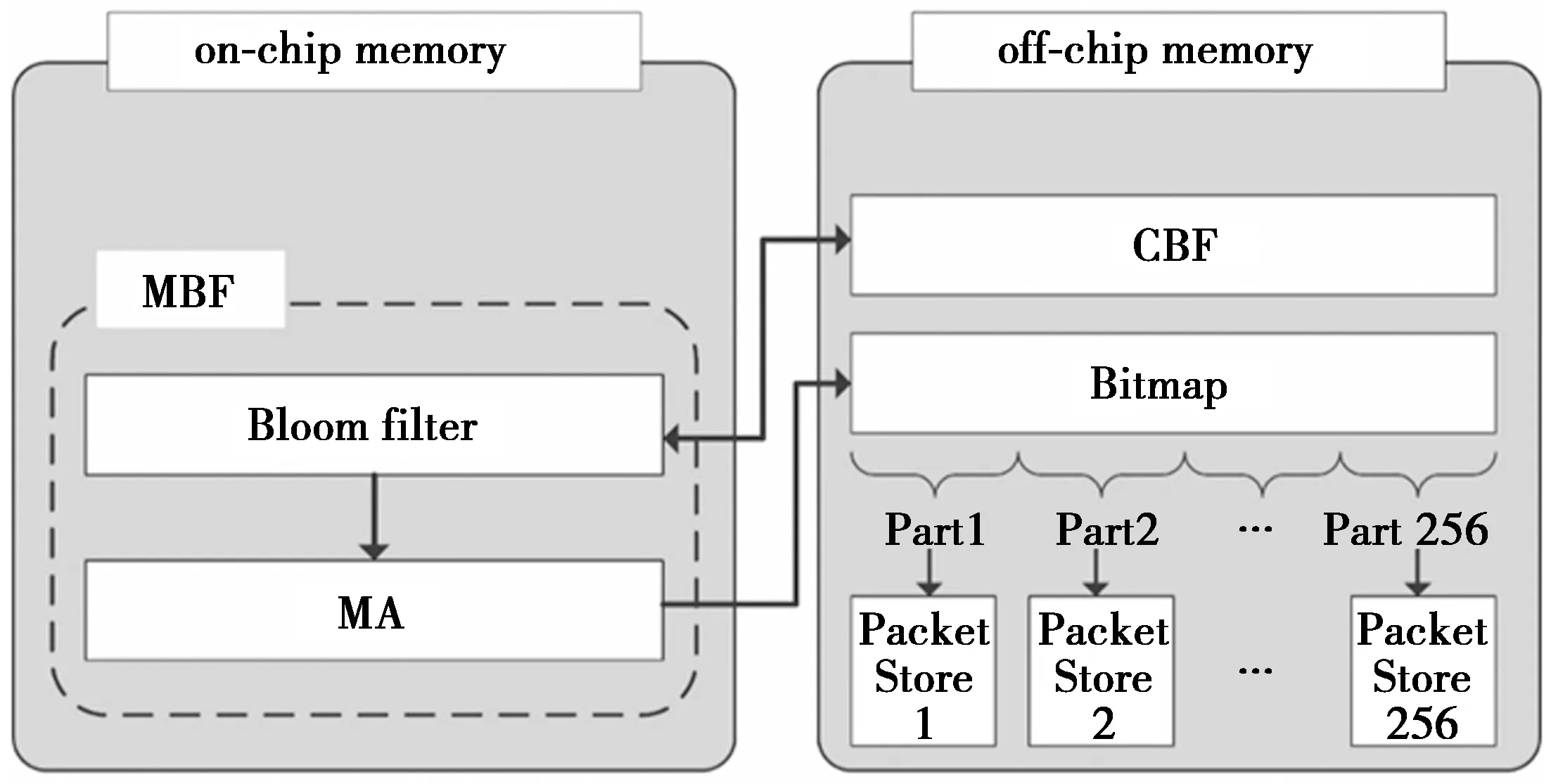
图2 B-MaPIT存储结构示意图Fig.2 Storage structure of B-MaPIT
考虑到PIT对于大容量、高性能的需求,本文根据实际应用中的各类存储器[13]的性能,对B-MaPIT结构采用2级存储器部署模式:片内存储单元和片外存储单元。片内存储单元用于部署MBF,使用静态随机存取存储器(static random access memory,SRAM)实现;片外存储单元部署CBF,Bitmap以及多个小型存储空间Packet Store,使用动态随机存取存储器(dynamic random access memory,DRAM)实现。在图2中,B-MBF作为数据索引结构,且Bitmap的每一部分对应一个动态存储空间Packet Store,用于存储实际的兴趣包的转发信息。其中,Bitmap记录的兴趣包的序号作为Packet Store的地址偏移量。通过对片内存储单元中Bloom filter和片外存储单元中CBF进行同步,实现B-MaPIT的删除和更新操作。此外,考虑到B-MBF存在哈希冲突,对于映射到Bitmap同一位置的兴趣包,其转发信息将以线性链表的形式链接在对应Packet Store的条目后面。
根据PIT百万级别数据存储数量的事实,同时也为了将B-MaPIT的误判率控制在更合理范围内,MBF结构中Bloom filter的大小被设置为224bit,定位数组的大小被设置为24 bit。与此对应,Bitmap的槽个数也被设定为224,并被划分为256个部分,即对应256个Packet Store。为了提高检索速度,B-MaPIT采用性能良好的非加密哈希函数CityHash256[14]来代替MD5和SHA1,对兴趣包的名称域content name进行哈希编码,产生一个256 bit的定长二进制序列,并将其分为12段,即B-MBF索引结构将采用12个哈希函数进行哈希映射。
2.3.2 B-MaPIT检索算法
无论兴趣包还是数据包到达路由器,PIT都会对其执行相应的处理操作。本节分别针对兴趣包和数据包详细介绍B-MaPIT对2种包的处理算法。
对于到达的兴趣包,路由器首先提取兴趣包的名称域content name,在内容存储(content store,CS)中进行检索。如果CS中没有响应兴趣包的数据包,那么路由器则会在B-MaPIT中检索兴趣包的转发信息。在B-MaPIT执行检索操作时,首先根据兴趣包的名称域content name在MBF的Bloom filter中查找,通过哈希映射判断B-MaPIT是否存在兴趣包的转发信息。若转发信息不存在,则该兴趣包将被转发到转发信息库(forwarding information base,FIB)。同时,兴趣包将被插入到Bloom filter与CBF,并在Bitmap中记录序号,然后根据该序号和对应Packet Store的基地址来申请内存单元,记录转发信息。若转发信息存在,则通过B-MBF结构获取Bitmap中记录的序号,再依据序号和基地址访问 Packet Store,对转发信息进行更新。如果误判导致转发信息存在,则将该兴趣包转发到FIB,通过FIB查找并将其转发到下一跳路由器。
对于到达的数据包,路由器首先提取数据包的名称域content name,在B-MaPIT中进行检索。与兴趣包在B-MaPIT中的检索算法相似,通过哈希映射确定B-MaPIT中是否存在数据包匹配的兴趣包条目。若存在,则根据Bitmap中的序号和对应Packet Store的基地址访问Packet Store。如果转发信息的条目为空,则丢弃该数据包,并在CBF中删除相应的记录;否则,路由器将按照条目中的转发信息将数据包转发到相应端口,并从Bitmap,CBF以及Packet Store中删除对应的条目。最后,为了保证B-MaPIT的信息准确性,在删除记录后,B-MaPIT将执行片内存储单元Bloom filter和片外存储单元CBF的同步操作。
2.3.3 B-MaPIT性能分析
在时间复杂度方面,MBF到Bitmap的槽定位过程仅需要进行一次除法运算和一次取余运算,无需迭代,因此,B-MBF结构的时间复杂度与MBF[10]相同,都为O(1)。对B-MaPIT而言,执行名称检索操作时B-MBF到Packet Store的寻址过程也只需要一次简单的加法运算,其执行检索的时间复杂度应等于B-MBF的时间复杂度,即O(1)。
在误判概率方面,考虑到Packet Store和Bitmap作为一般的数据结构,不会造成误判,所以,B-MaPIT的误判概率完全取决于MBF,其误判率与MaPIT[10]相同,B-MaPIT使用的MBF为概率型数据结构,其发生误判的概率由Bloom filter和定位数组的误判概率组成。根据文献[10],Bloom filter和定位数组的误判概率可分别表示为
P1=(1-ρ)k
(1)
(2)
将(1)式和(2)式的误判概率相加,可得到B-MaPIT发生误判的概率为
(3)
(1)—(3)式中:n表示PIT中存储的元素个数;m表示Bloom filter比特数组的大小;j表示定位数组的大小;k表示B-MaPIT所使用的哈希函数个数;ρ和α分别表示为ρ=(1-1/m)kn和α=(m/j-1)/(m-1)·j。
3 B-MaPIT性能评价
本节使用一台普通计算机对B-MaPIT存储结构的存储消耗、数据表构建速度和吞吐量进行测试。其中,计算机的操作系统采用32位的Windows7 sp3,核心部件CPU包含2个核,采用Intel Core i3-3220 3.30 GHz,内存为DDR3 4 GB频率1 333 GHz。通过与基于NCE、哈希表(hash table,HT)的PIT结构以及MaPIT结构进行比较,来展现B-MaPIT存储结构高效的性能。
3.1 实验设置
实验中的4种PIT存储结构全部采用C++程序语言实现。同时,4种PIT结构均使用2级存储器部署模式:片内存储单元部署索引结构,片外存储单元记录PIT的具体信息。此外,基于HT的PIT结构使用MD5和SHA1生成24 bit的二进制序列作为哈希函数的映射值;MaPIT结构则使用MD5和SHA1产生12个24 bit的二进制序列作为哈希函数的映射值,且定位数组被设置为24 bit。考虑到2.1节中PIT的需求,本节的实验输入数据采用来自DMOZ和ALEXA[10]的2 000 000条不同的域名。
3.2 B-MaPIT的存储消耗
在存储消耗的实验中,从片内存储单元和片外存储单元对比分析了4种PIT结构的存储消耗。其中,假设片外存储单元内每条PIT条目的内存大小为6字节。
表1给出了原始数据以及4种PIT结构具体的片内存储单元的存储消耗结果。参考表1的实验数据,可以明显看到,B-MaPIT, MaPIT和HT结构的片内存储消耗是静态的,而NCE结构的片内存储消耗则随名称数量增加而增加。实验结果表明,除HT结构外,其他3种PIT结构均可以有效减少片内存储消耗,但B-MaPIT和MaPIT的片内存储消耗最小,仅为2.097 MByte。
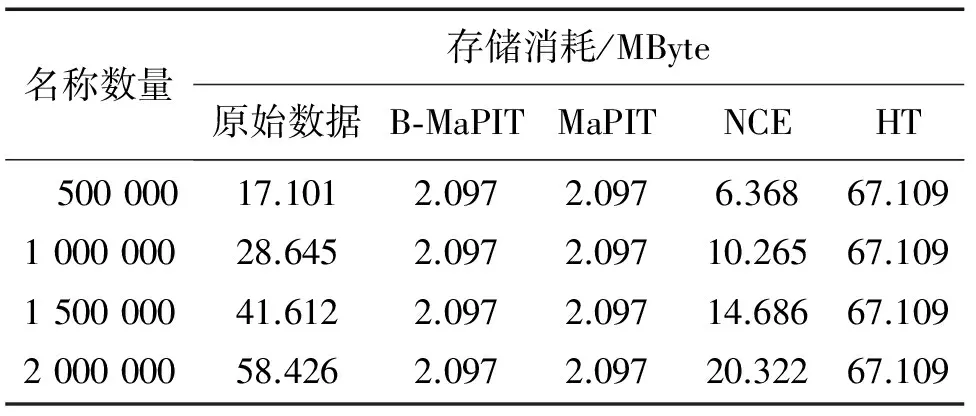
表1 片内存储单元存储消耗Tab.1 Memory consumption of on-chip memory
表2给出了4种PIT结构在片外存储单元的存储消耗结果。从表2可以看到,MaPIT,NCE结构和HT结构的片外存储单元是静态存储,其存储消耗与名称数量无关,均为224×6≈100.66 MByte。B-MaPIT使用Bitmap实现了内存动态分配,其片外存储消耗随名称数量增加而增加。在未输入名称前,其片外存储消耗仅取决于Bitmap,为224×2≈33.55 MByte;当输入2 000 000条名称时,片外存储消耗为224×2+2×106×6≈45.55 MByte,仍低于其他PIT结构存储消耗的一半。因此, B-MaPIT在片外存储消耗方面具有最优秀的表现。
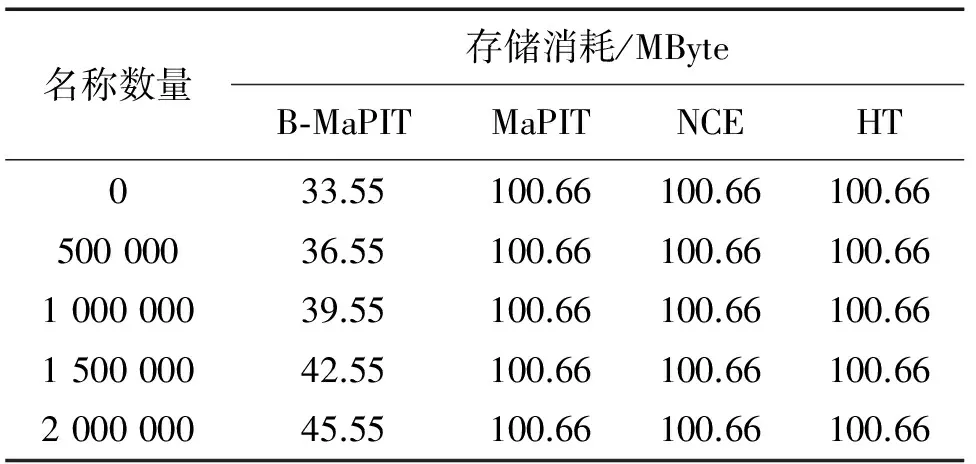
表2 片外存储单元存储消耗Tab.2 Memory consumption of off-chip memory
从片内和片外存储消耗的结果可以看到,B-MaPIT在存储消耗方面表现非常出色,能够有效降低整体的存储消耗,避免存储空间的浪费。
3.3 B-MaPIT数据表构建速度
针对PIT数据表构建速度的测试,实验采用2 000 000条名称作为输入数据,依次输入到这4种PIT结构中,且每输入500 000条名称记录一次各PIT结构的运行时间,以测试各结构的构建速度。
表3为4种PIT结构的数据表构建时间。由表3可知,基于NCE的PIT结构其基本思想是字符查找树,由于树形结构查找速度较慢,导致基于NCE的PIT结构的数据表构建时间最长。当输入名称达到2 000 000条时,其构建时间约为B-MaPIT结构的24倍。B-MaPIT,MaPIT和HT结构都采用基于哈希的思想,其时间复杂度为O(1),但B-MaPIT结构仅使用一个哈希函数实现12次哈希映射,有效减少哈希运算次数,提高了数据表的构建速度,其构建时间仅为HT结构的1/12,MaPIT结构的1/9。从表3的数据可以明显看出,B-MaPIT结构在数据表构建速度性能上表现最佳。
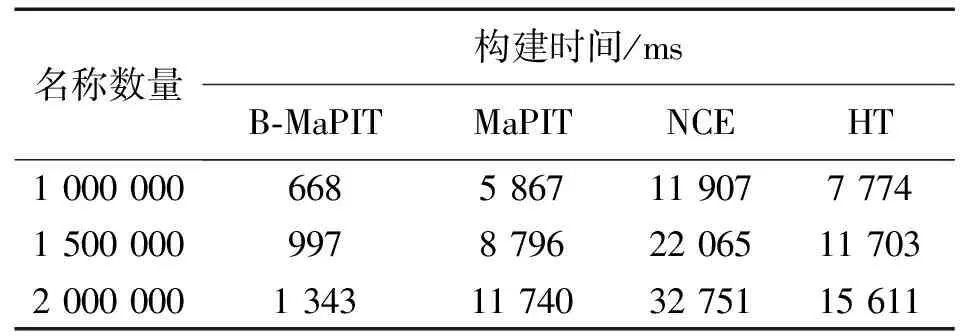
表3 PIT数据表构建时间Tab.3 Building time of PIT
3.4 B-MaPIT的吞吐量
在PIT结构吞吐量的实验测试中,分别针对名称数量为1 000 000, 1 500 000和2 000 000条名称的数据集进行实验,并比较4种PIT结构的吞吐量,其结果如图3所示。
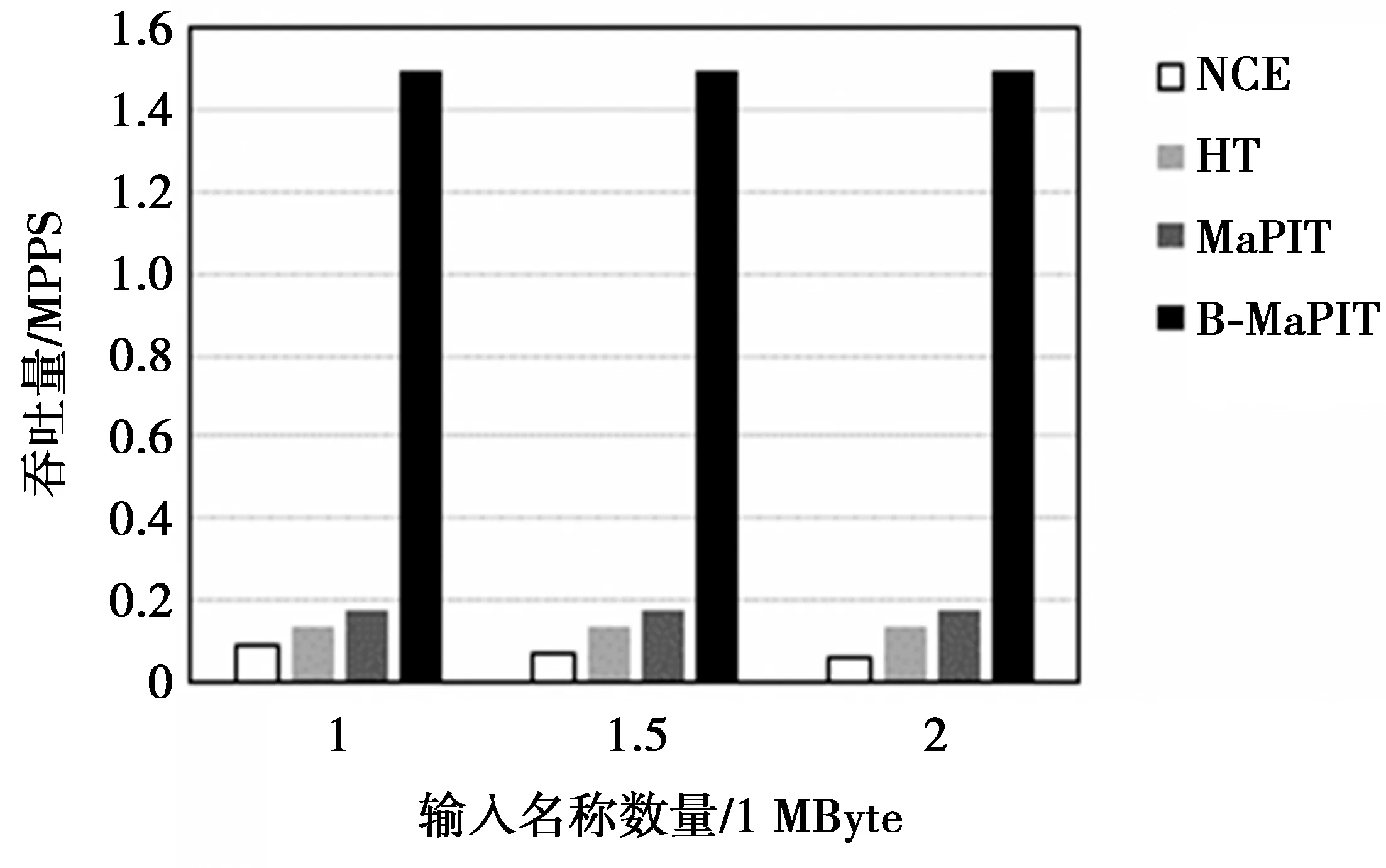
图3 PIT结构的吞吐量Fig.3 Throughput of PIT
图3表明,随着查找名称数量的增加,基于NCE的PIT结构的吞吐量呈现下降趋势,而基于哈希算法的3种PIT结构的吞吐量基本保持不变。以每秒百万数据包(million packet per second,MPPS)为单位,当查找名称数量达到2 000 000时,NCE结构、HT结构、MaPIT以及B-MaPIT的吞吐量分别为0.061 MPPS,0.128 MPPS,0.170 MPPS,1.495 MPPS。显然,由于仅使用一个哈希函数完成12次哈希映射,B-MaPIT结构在吞吐量性能方面远优于其他几种PIT结构。
4 结束语
根据PIT大容量、高性能的设计需求,本文基于Bitmap提出了一种改进的索引结构B-MBF,以提高检索速度,并进一步减少片外存储单元的存储消耗。同时,在此数据结构的基础上,设计了高效的PIT存储结构B-MaPIT,满足了PIT对存储空间和检索速度的要求。经过实验测试,本文提出的B-MaPIT在存储消耗,数据表构建速度和吞吐量性能方面有了极大的改善,提高了转发平面的工作性能。未来的工作是以多线程实现B-MaPIT存储结构,并在FPGA(field programmable gate array)或GPU(graphic processing unit)上进行部署,以进一步测试该存储结构的性能。
[1] ZHANG Lixia, ESTRIN D, BURKE J, et al. Named data networking (NDN) project[J]. Transportation Research Record Journal of the Transportation Research Board, 2010, 1892(1):227-234.
[2] 王品,黄焱,王超,等. 基于自相关的宽范围高精度频偏估计算法[J]. 计算机工程, 2011, 37(4):102-103.
WANG Pin, HUANG Yan, WANG Chao, et al. Autocorrelation-based frequency offset estimation algorithm with wide range and high accuracy[J]. Computer Engineering, 2011, 37(4):102-103.
[3] WANG Yi, HE Keqiang, DAI Huichen, et al. Scalable name lookup in NDN using effective name component encoding[C]// IEEE. Distributed Computing Systems, 2012 IEEE 32nd International Conference on. Macau, China: IEEE, 2012:688-697.
[4] DAI Huichen, LIU Bin, CHEN Yan, et al. On pending interest table in named data networking[C]//Proceedings of the eighth ACM/IEEE symposium on Architectures for networking and communications systems. Austin, Texas, USA: ACM, 2012: 211-222.
[5] SAXENA D, RAYCHOUDHURY V. Radient: scalable, memory efficient name lookup algorithm for named data networking[J]. Journal of Network and Computer Applications, 2016, 63: 1-13.
[6] VARVELLO M, PERINO D, LINGUAGLOSSA L. On the design and implementation of a wire-speed pending interest table[C]//IEEE. Computer Communications Workshops (INFOCOM WKSHPS), 2013 IEEE Conference on. Turin, Italy: IEEE, 2013: 369-374.
[7] YUAN Haowei,CROWLEY P.Scalable pending interest table design:from principles to practice[C]//IEEE. IEEE INFOCOM 2014-IEEE Conference on Computer Communications.Toronto,Canada:IEEE,2014:2049-2057.
[8] YOU W, MATHIEU B, TRUONG P, et al. Dipit: a distributed bloom-filter based pit table for ccn nodes[C]// IEEE. Computer Communications and Networks (ICCCN), 2012 21st International Conference on. Munich, Germany: IEEE, 2012: 1-7.
[9] LI Zhaogeng, BI Jun, WANG Sen, et al. Compression of pending interest table with bloom filter in content centric network[C]//Proceedings of the 7th International Conference on Future Internet Technologies. Seoul, Korea: ACM, 2012: 46-46.
[10] LI Zhuo, LIU Kaihua, ZHAO Yang, et al. MaPIT: an enhanced pending interest table for NDN with mapping bloom filter[J]. IEEE Communications Letters, 2014, 18(11): 1915-1918.
[11] PERINO D, VARVELLO M. A reality check for content centric networking[C]//Proceedings of the ACM SIGCOMM workshop on Information-centric networking. Toronto, Ontario, Canada: ACM, 2011: 44-49.
[12] YUAN Haowei, SONG Tian, CROWLEY P. Scalable NDN forwarding: concepts, issues and principles[C]//IEEE. Computer Communications and Networks (ICCCN), 2012 21st International Conference on. Munich, Germany: IEEE, 2012: 1-9.
[13] ROSSINI G, ROSSI D, GARETTO M, et al. Multi-terabyte and multi-gbps information centric routers[C]//IEEE. INFOCOM, 2014 Proceedings IEEE. Toronto, Canada: IEEE, 2014: 181-189.
[14] Google Project Hosting. The City family of hash functions[EB/OL]. (2013-12-18)[2017-08-24]. http://code.google.com/p/cityhash.
(编辑:魏琴芳)
猜你喜欢
现代应用物理(2022年1期)2022-05-17
电脑报(2022年13期)2022-04-12
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
科技创新与应用(2020年29期)2020-10-20
电脑报(2020年24期)2020-07-15
软件导刊(2019年4期)2019-06-09
科教导刊·电子版(2018年2期)2018-06-05
林业调查规划(2017年6期)2017-03-27
工业设计(2016年8期)2016-04-16
