
基于二维路由的流量工程解决方案
2018-03-03 07:41:10徐明伟
重庆邮电大学学报(自然科学版) 2018年1期
耿 男,杨 芫,徐明伟
(清华大学 计算机科学与技术系, 北京 100084)
0 引 言
随着互联网的高速发展,网络规模不断扩大,网络中的数据流量也迅速增加,给网络带来了巨大的压力和挑战。单纯地进行硬件升级不仅难以解决负载不均衡的问题,而且还造成了极大的资源浪费和升级费用[1],流量工程(traffic engineering)成为解决互联网高速发展所带来压力的更有效途径。流量工程可以进行流量控制,解决负载不均衡、网络资源利用率低、时延长等问题,还可以预留链路带宽资源应对网络故障和突发流量。流量工程提升了网络性能,提高了网络服务提供商的服务质量,从而也提升了用户体验。
当前流量工程受限于对网络流量的认识和当前的路由技术。对于前者,网络中各条链路的流量状况对流量工程进行流量调度有很大的影响,在知晓哪些链路拥堵、哪些链路空闲、哪些数据流是造成网络拥堵的主因等这些信息后,才能做出最为恰当的流量调度决策。然而,统计网络中的流量信息面临着很多困难,如准确性、统计开销等。因而很多研究工作提出了各自的流量工程方案来应对这一挑战,如大流测量等。实际上,网络中大流特征十分明显,少数的几条大流占据了绝大部分的链路流量,且持续时间长,非常适合流量调度。
对于后者,流量工程的实施必须受限于已有的路由技术。比如基于目的地址转发、流量不分流等。有一类工作在现有的约束条件下设计合理的方案进行流量工程,如带约束的优化、基于地址分块的流量拆分;另外,还有一类工作则是在原始路由技术的基础上用较低的开销进行改造,实现更为细粒度和灵活的流量控制,如多维路由。不过多维路由面临着转发表空间膨胀,可扩展性差等问题。
事实上,上述2个挑战是相互独立的,很多解决方案也是可以通过一定方式进行组合的,实现优势互补。
二维路由(two-dimensional IP routing)[2]作为多维路由的一种,在进行路由决策和转发数据报文的时候不仅考虑目的地址,同时还要考虑源地址。本文中我们提出了二维路由大流调度方案,并结合大流测量技术建立了二维路由优化模型,然后提出了随机算法求得优化问题的近似解。该方案不仅实现了网络流量细粒度的灵活控制,而且还具有很好的可扩展性以及更低的多维流表开销。我们通过实验证明方案的可行性,并通过仿真实验证明,二维路由比传统路由方式具有更好的流量工程效果,并且二维路由方案已接近最优方案,不需要额外的维度进行流量控制。
1 流量工程主要挑战和相关研究
1.1 流量矩阵测量挑战
流量矩阵也即任意2个网络节点之间链路上流统计信息的集合,如流量大小。很多流量工程方案[3-4]的实施需要测量或估计网络的流量矩阵,从而根据网络状况制定合适的调度方案,因而流量矩阵测量的准确性会对流量工程的效果产生直接的影响。很多研究工作[5-6]都是在假设流量矩阵已知的前提下进行的。尽管测量网络流量矩阵的方案有很多[7],但是测量结果误差仍然接近20%[8],主要就是因为链路上数据流量在实时变化,并且难以预测。除此之外,在现有设备上测量链路流量所带来的开销也为基于流量矩阵的流量工程增添了很多阻碍。
1.1.1 非流量感知路由
非流量感知路由可以在流量矩阵测量不准确、网络流量时刻变化的情况下,实现鲁棒的流量工程。文献[9]提出了一种最优静态路由的方式,其将最小化最大链路利用率作为流量工程的优化目标。对于给定的网络拓扑,此时存在一个最优路由方式rD对应的最大链路利用率(maximum link utilization,MLU)为MLU(D,rD),静态路由方式r对应的最大链路利用率为MLU(D,r),其中,D为任意流量需求,亦即流量矩阵。定义性能比α为各种流量矩阵D下MLU(D,r)与MLU(D,rD)的最大比值,最优静态路由的优化目标就是最小化这一比值。文献[10]研究表明,在其实验拓扑下,对于任意流量矩阵,存在一种静态路由方式使得性能比α不超过2。不过文献[9-10]这种非流量感知的路由方式具有自己的局限性,首先单纯基于目的地址进行流量调度效果并不好,基于源和目的地址进行流调度[11]粒度更细、效果更优,其次求解最优路由需要解大型线性规划问题,复杂度高,可扩展性一般,最后,当网络中节点或链路发生故障的时候需要进行重路由,开销较大。
1.1.2 高效的流量测量
实际网络链路中的数据流量其实是由极少数的大流(通常称为elephant flow或者large flow)主导的[12]。这类大流数目很少,但是数据量很大,而且持续时间通常较长。显然这些大流非常适合进行流量调度,开销小,调度效果仍有保证,而且调度策略的时效性长。仅仅测量网络中的大流信息,对于测量误差和链路状况变动都具有更高的容忍性。
文献[13]提出的ICE-Buckets(independent counter estimation buckets)算法实现了基于per-flow的低误差率大流测量;文献[14]提出了一种利用缓存辅助的大流测量方案CASE(cache-assisted stretchable estimator),能够实现300 Gbit/s的吞吐量和低误差率;文献[15]提出了2个方案,分别是CSS(compact space-saving)和WCSS(window compact space-saving)。CSS对经典方法space-saving[16]进行了改进,消除了大量指针操作并减少了75%的存储空间;WCSS结合了CSS和滑动窗口策略,能够周期性更新大流统计信息。
基于大流进行流量调度的工作有很多,其应用场景以数据中心为主。Hedera[17]使用OpenFlow协议通过交换机获得数据统计信息,然后通过近似算法放置大流,实验结果显示,这种集中式的大流调度方案能起到有效的流量调度效果。Mahout[18]和MicroTE(micro traffic engineering)[19]与Hedera不同,它们在主机上获得统计信息,降低了测量大流信息的开销,实现了另一种基于大流的流量工程。
1.2 路由设备转发控制能力挑战
路由设备转发控制能力是制约流量工程效果的另一重要因素。这里路由设备转发控制能力是指流量工程中路由设备对网络数据转发控制的粒度。尽管互联网是基于分组进行数据传输的,但是流量工程中进行分组级别的调度在技术上是难以实现的。在传统网络的路由设备中,一般是基于目的IP地址进行数据报文的转发,当一个数据包到达时,路由器会根据数据包的目的IP地址在转发表中匹配相应的转发表项,然后依据下一跳指令执行转发操作。在进行流量工程时,可以配置一些静态路由改变转发策略。实际上,数据包包头包含了很多信息(源地址、目的地址、源端口号、目的端口号等),这些字段能够支持更加细粒度的流量调度,获得更好的流量工程效果。细粒度的流量工程已经成为当前互联网的重要需求[20],不过,在传统设备上实施细粒度的流量工程开销很大,因而路由设备的转发控制能力一定程度上制约了流量工程的实施。
1.2.1 带约束的优化
很多工作将路由和转发机制的种种限制作为约束加入到流量工程的优化模型当中,例如流量不可拆分、基于目的地址转发等。这些优化模型加上约束后通常由普通的线性规划变为(混合)整数规划,直接求解这类优化问题十分困难,通常会选择一些启发式的方法求得问题的近似解。文献[21]提出DEFT(distributed exponentially-weighted flow splitting)方案,其将链路权值和链路流量均作为变量加入到流量分割模型中,然后通过一种二阶段迭代的方式求得接近最优的近似解,实现负载均衡。文献[22]提出在软件定义网络(software defined network,SDN)在增量部署的情况下,利用其集中控制的特性收集全网信息,建立线性规划方程求解。总体而言,使用带约束的优化方式进行流量工程,如何保证求解方案接近最优且保持低开销是每个工作都要考虑的问题。
1.2.2 基于地址块拆分流量
基于地址块拆分流量最简单、最常见的方式是基于哈希的等价多路径(equal-cost multi-path,ECMP),即将数据流通过五元组哈希的方式分散到多条等价路径上,之后又有人提出了加权成本多路径(weighted cost multi-path,WCMP)处理带有特定权值的流分割需求。文献[23]提出了Niagara方法,基于源地址或者目的地址进行流量拆分。一个简单的例子,假如我们要将某链路流量按照1∶3∶4的比例拆分到3条路径上去,可以设置地址块对应相应的转发表项,比如3条转发表项分别是目的地址为*000的流去往路径1且具有高优先级;目的地址为*0的流的去往路径2且具有低优先级;目的地址为*1的流去往路径3且具有低优先级。这种基于地址块的分流方式,可以大大缩减流表存储空间,实验表明,Niagara只需要原始流表数的1.2%~37%。不过,该方法与ECMP共有的局限性在于无法依据流量在地址块上的分布进行流量分割,可能会造成实际分割的流量比例与预期的分流比例相差较大。
1.2.3 多维路由
如果数据流的转发不仅仅通过目的地址进行控制,而且还支持源地址、端口号、协议号等域值的匹配,那么这种路由方式就是多维路由。多维路由能够实现细粒度的流量控制,达到更灵活、高效的流量工程效果,但需要路由和转发机制的支持。
多协议标签交换(multi-protocol label switching,MPLS)[24]可以在端到端之间建立隧道,支持源和目的IP地址、源和目的端口号、协议号等多个维度,然而MPLS配置复杂,开销大,难以跨域,流量的变动会使隧道性能大大降低,因而MPLS并未在全球广泛部署。SDN的OpenFlow协议为转发表项提供了40多个匹配域,流量控制粒度很细。基于SDN的分流方式也有很多,如MicroTE[19]等方式,它们通过控制器下发流表规则进行细粒度的分流。不过,这种多维流表的方式势必会造成转发表空间的爆炸,目前SDN交换机支持的流表数目只有上万条,而主干网目的地址转发表项就已经超过了60万条,而且已有的多维流表压缩方案也并不能从根本上解决该问题[25]。因而尽管SDN在细粒度的流量工程方面存在着很大的便利性,但是要想大规模部署仍然面临着很大的阻碍。文献[2]提出了二维路由策略,在传统路由方式的基础上只增加了一个维度,即路由转发决策不仅仅依赖于目的地址,也依赖于源地址。
2 二维路由方案介绍
2.1 二维路由概念与特点
二维路由是多维路由的一种,与传统路由相比,二维路由在目的地址的维度基础上又增加了源地址的维度。从控制层面来讲,路由器在进行路由决策的时候,不仅考虑目的地址,而且还要考虑源地址,也就是说,具有相同目的地址不同源地址的报文可能具有不同的下一跳。从数据层面上来讲,转发表项中需要加入源地址匹配字段,参与转发匹配。显然源地址的加入使得路由转发设备对流量的控制粒度更加细化,在进行流量工程的时候可以有更加灵活的选择。
若将传统网络和SDN分别看做维度上的2个极端,那么二维路由则是二者的折中,并且更加倾向于传统网络。这就使得二维路由具有很多优质的特性:①二维路由实现了细粒度的转发控制,能够实现更加灵活的流量工程策略;②二维路由是基于传统路由协议改造的,因而具有很多传统网络的特性,如鲁棒性、可扩展性等,支持增量部署[26];③二维路由相比于SDN,具有更少的维度,实际上2个维度已经足够实现高效的流量工程,并且大大减少三态内容寻址存储器(ternary content addressable memory,TCAM)空间的消耗,支持更大规模的网络;④二维路由是一种思想,它还可以灵活地与其他流量工程技术相结合,实现更好的流量调度效果。
2.2 二维路由大流调度方案
由1.1.2可知,单纯调度大流就可以实现较好的流量工程效果,由于大流数目很少,因而在二维路由中只需要很少的二维转发表项即可,开销很小,且策略有效性持续较长。综上,基于大流的二维路由进一步增强了方案的可扩展性。
二维路由应用的场景一般是传统的企业网或广域网,本文提出的二维路由大流调度方案是基于开放最短路径优先(open shortest path first,OSPF)协议的系统设计,硬件设备是传统的路由设备,二维转发表使用的是访问控制列表(access control list,ACL)。
二维路由大流调度系统主要由3部分组成:分别为大流测量;集中路径计算;转发决策下发和执行。
2.2.1 大流测量
由于传统路由设备不能像OpenFlow交换机那样具有数据统计功能,因而不能直接进行流量统计,更不能进行大流统计。文献[13-15]已经提出了线速、准确、低开销的大流测量方案,本文并没有提出新的大流测量方案,而是直接采用了文献[15]中的一种设计方案进行大流测量。
大流测量需要执行大流检测算法,并且需要将统计数据汇报给集中路径计算单元。一种直接的方式是将大流检测算法放到路由设备上执行,但是这样会给路由器带来很大的负担;另一种方式是在路由设备间添加一个新的测量设备,然而这种方式会带来一定的时延,还有一种方式是通过交换机镜像将链路上的数据流导入到一台测量设备上进行大流检测。本文采用的是最后一种方法。
2.2.2 集中路径计算
本方案需要一个路径计算单元,能够收集测量设备统计的流信息,进行大流调度的计算。本文中,我们根据二维大流调度场景,提出了一个专门针对该场景的数学优化模型,并修改了随机取整算法[27]求得优化模型的近似解。
2.2.3 转发决策下发和执行
路径计算单元计算得到大流的调度决策,需要将转发决策下发到路由器执行生成相应的二维转发表。本文仍旧采用OSPF(open shortest path first)中基于最短路径的路径计算方式,令每一台路由器不仅维持一个正常的链路权值矩阵,还要维持一组针对每一条大流的调度链路权值矩阵。每一个调度链路权值矩阵的最短路径计算结果正好是该大流的调度路径,该过程很容易通过简单算法实现。路径计算单元计算出这些调度链路权值矩阵之后,通过类似文献的链路状态通告(link-state advertisement,LSA)扩展方案,将权值信息通告给全网,路由器收到扩展LSA之后对相应的调度链路权值矩阵执行最短路径算法生成二维转发表配置到ACL中。当数据包到达的时候,路由器优先匹配ACL中的二维转发表,然后匹配传统的转发表。
2.3 二维大流调度模型和求解算法
2.3.1 二维路由大流调度模型
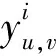
minφ=max{ue,∀e:(u,v)∈E}
(1)
subject to:
∀e:(u,v)∈E
(2)
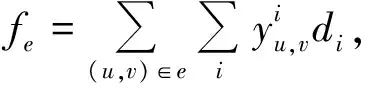
(3)
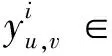
(4)
fe+be≤ce,∀e:(u,v)∈E
(5)

(6)
(7)
2.3.2 优化模型求解
上述优化问题属于一种0-1整数规划问题,容易证明其属于NP-hard问题,并不能在多项式时间内求得最优解。
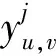
需要注意的是上述模型并没有强调二维路由,也就是该模型同样适用于传统路由。二维路由与传统路由的差异体现在大流需求i的定义上,使用二维路由,可以将基于目的地址的大流分割为较小的子流,从而更加细粒度的控制流量。
2.4 真实实验和仿真实验设计与结果分析
2.4.1 真实实验设计和结果分析
本文实现了一个二维路由大流调度的系统原型:①依照文献[15]实现了测量大流和背景流的测量算法,并部署到一台计算机上;②在另一台笔记本上实现了路径计算单元,通过2.3.2节中所提算法求得调度路径,然后转换成调度链路矩阵权值,通过扩展LSA告知路由器;③修改了Quagga代码,使其识别扩展LSA并能进行二维路由转发路径的计算和转发表(access control list,ACL)生成。
使用9台真实路由器搭建了Abilene研究网络,每个链路容量为1 Gbit/s,链路权值均设为50。使用交换机将关键链路的流量镜像到测量设备上。测量设备与路径计算单元通过socket建立连接。
本文通过一个简单案例验证了该系统的反应时间,实验结果如图1所示。首先我们使用iperf在每条链路上产生150 Mbit/s的背景流量,然后在t=0 s时刻,在Denver节点使用iperf产生一条100 Mbit/s的去往New York节点的UDP(user datagram protocol)流,并通过link 1。在t=2 s时,产生一条除源地址外都相同的流。由图1可以发现,其中一条流在0.2 s内调度到了link 2上,因而在该案例中,可知该系统能够实现较快的流量调度。
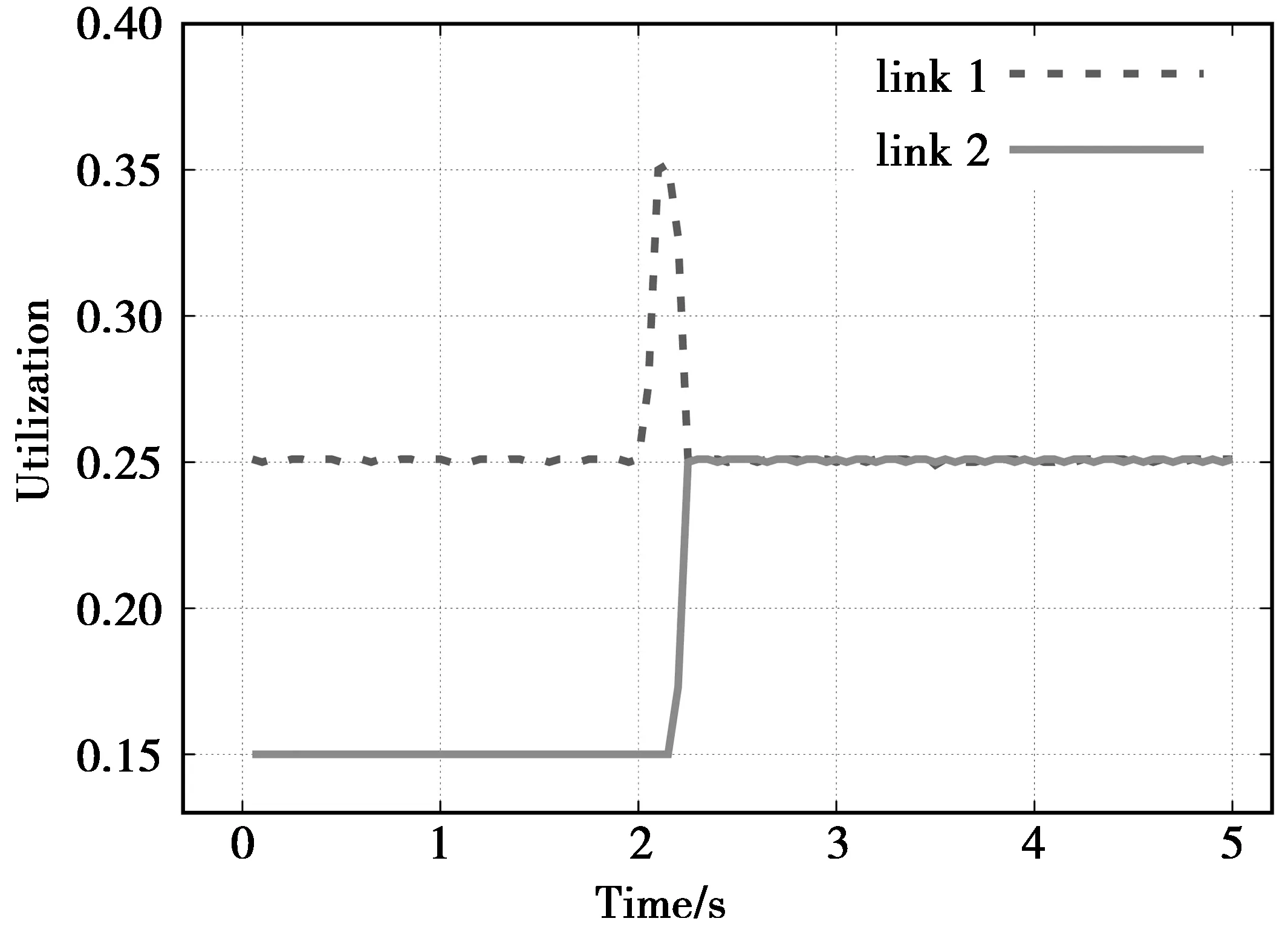
图1 大流调度实验结果Fig.1 Experiment results of large flow scheduling
2.4.2 仿真实验设计和结果分析
实验拓扑选取Rocket fuel公开的网络拓扑库,如表1所示,AS表示拓扑所属自治域系统。拓扑的链路权值使用公开数据库中提供的数值,链路容量依照下面规则给出:若链路两端节点的度都大于5,则链路容量为9 953 Mbit/s,否则链路容量为2 488 Mbit/s。
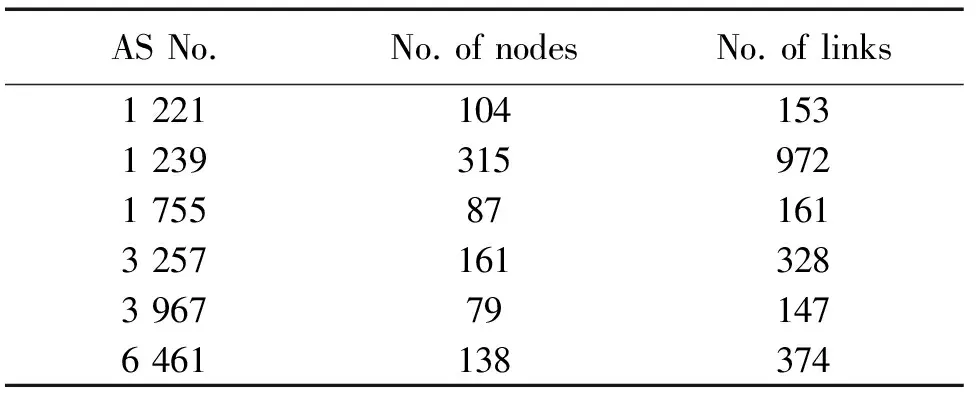
表1 Rocketfuel拓扑Tab.1 Rocketfuel topologies
通过对Caida(the cooperative association for Internet data analysis)公开数据分析,网络背景流量大约为链路容量的15%~20%,大流大小(数据速率)为100~120 Mbit/s,每个节点对间包含的大流数目大约为0~2条。实验中,随机产生15%~20%链路容量范围内的背景流量,然后随机选取30个具有不同源和目的节点的节点对(节点对可相同),每个节点对之间随机一条速率为100~120 Mbit/s的基于目的地址的大流。二维数据流(基于源和目的地址的流)由目的大流分解得到,具体来说,对于每一条目的大流,首先随机产生0~2条子流,这些子流占目的大流总量的15%~40%,剩下的大流流量再分割成若干子流,这些子流每条占目的大流数据总量的5%~15%。每个实验结果取10次仿真结果的平均值。
本文对表1中的6个拓扑进行了仿真,对比了OSPF、基于目的地址的大流调度(dst-based randomized rounding)以及基于二维路由的大流调度(TD-based randomized rounding)这3种方案的性能比(含义同2.2.1节中的性能比),仿真结果如图2所示。可以观察到,对于每一种拓扑,OSPF的性能比最高,也就是负载最不均衡;基于目的地址进行大流调度的性能比大约在1.1;而基于二维的大流调度性能比接近1.0。显然基于二维路由的大流调度效果高于传统路由方式,而且接近最优,不需要再添加额外的维度。
3 结束语
本文从流量矩阵测量和路由设备转发控制能力2个角度出发,介绍了流量工程的这2个挑战和解决挑战的一些研究角度及现有方案。本文结合上述挑战提出了二维路由大流调度方案,具有细粒度、可扩展性、低开销的特性,真实实验证明了方案的可行性,仿真实验证明了方案的有效性。
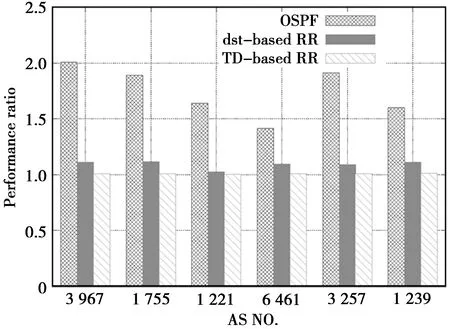
图2 大流调度仿真结果Fig.2 Simulation results of large flow scheduling
[1] HONG C Y, KANDULA S, MAHAJAN R, et al. Achieving high utilization with software-driven WAN[C]//ACM SIGCOMM.Hong Kong,China:ACM Press,2013:15-26.
[2] YANG S, XU M, WANG D, et al. Two dimensional router: Design and implementation[R]. Beijing: Tsinghua University, 2012.
[3] SRIDHARAN A,GUÉRIN R,DIOT C.Achieving near-optimal traffic engineering solutions for current OSPF/IS-IS networks[J].IEEE/ACM TON,2005,13(2):234-247.
[4] SRIVASTAVA S, AGRAWAL G, PIORO M, et al. Determining link weight system under various objectives for OSPF networks using a Lagrangian relaxation-based approach[J]. IEEE TNSM, 2005, 2(1): 9-18.
[5] BHATIA R, HAO F, KODIALAM M, et al. Optimized network traffic engineering using segment routing[C]//IEEE INFOCOM.Hong Kong, China: IEEE Press, 2015: 657-665.
[6] HARTERT R, SCHAUS P, VISSICCHIO S, et al. Solving segment routing problems with hybrid constraint programming techniques[C]//Springer International Publishing Switzerland CP. Cork, Ireland: Springer, Cham Press, 2015: 592-608.
[7] MEDINA A, TAFT N, SALAMATIAN K, et al. Traffic matrix estimation: Existing techniques and new directions[C]//ACM SIGCOMM. Pittsburgh, Pennsylvania: ACM Press, 2002, 32(4): 161-174.
[8] ZHANG Y, ROUGHAN M, DUFFIELD N, et al. Fast accurate computation of large-scale IP traffic matrices from link loads[C]//ACM SIGMETRICS. San Diego, CA, USA: ACM Press, 2003, 31(1): 206-217.
[9] APPLEGATE D, COHEN E. Making routing robust to changing traffic demands: algorithms and evaluation[J]. IEEE/ACM TON, 2006, 14(6): 1193-1206.
[10] APPLEGATE D, COHEN E. Making intra-domain routing robust to changing and uncertain traffic demands: Understanding fundamental tradeoffs[C]//ACM SIGCOMM.Karlsruhe,Germany:ACM Press,2003:313-324.
[11] CHIESA M, RÉTVRI G, SCHAPIRA M. Lying Your Way to Better Traffic Engineering[C]//ACM CoNEXT. Irvine, California, USA: ACM Press, 2016: 391-398.
[12] ESTAN C,VARGHESE G.New directions in traffic measurement and accounting:Focusing on the elephants,ignoring the mice[J].ACM TOCS,2003,21(3):270-313.
[13] EINZIGER G, FELLMAN B, KASSNER Y. Independent counter estimation buckets[C]//IEEE INFOCOM. Hong Kong, China: IEEE Press, 2015: 2560-2568.
[14] LI Y,WU H,PAN T,et al.Case:Cache-assisted stretchable estimator for high speed per-flow measurement[C]//IEEE INFOCOM.San Francisco,CA,USA:IEEE Press,2016:1-9.
[15] BEN-BASAT R, EINZIGER G, FRIEDMAN R, et al. Heavy hitters in streams and sliding windows[C]//IEEE INFOCOM.San Francisco,CA,USA:IEEE Press,2016:1-9.
[16] METWALLY A, AGRAWAL D, EL ABBADI A. Efficient computation of frequent and top-k elements in data streams[C]//Springer Verlag Berlin Heidelberg ICDT. Edinburgh,UK:Springer,Berlin,Heidelberg Press,2005:398-412.
[17] AL-FARES M, RADHAKRISHNAN S, RAGHAVAN B, et al. Hedera: Dynamic Flow Scheduling for Data Center Networks [C]//USENIX NSDI. Boston, MA, USA: USENIX Press, 2010, 10: 19-19.
[18] CURTIS A R, KIM W, YALAGANDULA P. Mahout: Low-overhead datacenter traffic management using end-host-based elephant detection[C]//IEEE INFOCOM. Shanghai, China: IEEE Press, 2011: 1629-1637.
[19] BENSON T, ANAND A, AKELLA A, et al. MicroTE: Fine grained traffic engineering for data centers[C]//ACM CoNEXT. Tokyo, Japan: ACM Press, 2011: 8.
[20] MENDIOLA A, ASTORGA J, JACOB E, et al. A survey on the contributions of Software-Defined Networking to Traffic Engineering[J]. IEEE Communications Surveys & Tutorials, 2017, 19(2): 918-953.
[21] XU D, CHIANG M, REXFORD J. DEFT: Distributed exponentially-weighted flow splitting[C]//IEEE INFOCOM. Anchorage,Alaska,USA:IEEE Press,2007:71-79.
[22] AGARWAL S, KODIALAM M, LAKSHMAN T V. Traffic engineering in software defined networks[C]//IEEE INFOCOM.Turin,Italy:IEEE Press,2013:2211-2219.
[23] KANG N, GHOBADI M, REUMANN J, et al. Efficient traffic splitting on commodity switches[C]//ACM CoNEXT. Heidelberg, Germany: ACM Press, 2015: 6.
[24] AWDUCHE D O. MPLS and traffic engineering in IP networks[J].IEEE communications Magazine,1999,37(12):42-47.
[25] ZHU H, XU M, LI Q, et al. MDTC: An efficient approach to TCAM-based multidimensional table compression[C]//IEEE IFIP Networking. Toulouse, France: IEEE Press, 2015: 1-9.
[26] XU M, YANG S, WANG D, et al. Efficient Two Dimensional-IP routing: An incremental deployment design[J]. Elsevier CN, 2014(59): 227-243.
[27] RAGHAVAN P, TOMPSON C D. Randomized rounding: a technique for provably good algorithms and algorithmic proofs[J]. Combinatorica, 1987, 7(4): 365-374.
(编辑:刘 勇)
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
移动通信(2021年5期)2021-10-25 11:41:48
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
网络安全和信息化(2018年3期)2018-11-07 03:02:44
中国交通信息化(2014年3期)2014-06-05 03:07:09
电测与仪表(2014年16期)2014-04-22 05:20:30
计算机工程(2014年6期)2014-02-28 01:25:54
河南科技(2014年5期)2014-02-27 14:08:56
