
基于局部特征的卷积神经网络模型
2018-03-03 01:26顾大权赵章明
计算机工程 2018年2期
施 恩,李 骞,顾大权,赵章明
(解放军理工大学 气象海洋学院,南京 211101)
0 概述
大数据的发展促使深度学习在语音识别、图像分类、文本理解等众多领域得到了广泛应用,深度学习的计算模式是先从训练数据出发,经过一个端到端的模型,然后直接输出得到最终结果[1]。卷积神经网络(Convolutional Neural Network,CNN)是深度学习的重要分支,由于CNN具有特殊的网络结构,因此其在图像处理领域具有深远的研究前景,近年来得到高度重视并引起广泛研究[2]。
卷积神经网络起源于Hbbel和Wiesel对猫的视觉皮层神经元细胞研究[3],并在多层感知器的基础上发展成为一种深层神经网络。纽约大学的LeCun Yann提出了经典卷积神经网络模型LeNet[4-5],该网络模型采用后向传播算法(Back Propagation,BP)更新网络权值参数,对此后的研究工作有着深远的影响。此后,AlexNet网络模型[6]被认为是对卷积神经网络改进工作中的重大突破。此后还出现了GoogleNet、ResNet等新的网络模型,它们的主要改进思路是增加网络深度。
由于卷积神经网络受生物视觉认知方式启发而来,具有特殊的网络结构,与BP神经网络等其他神经网络相比,卷积神经网络在处理图像时具有直接性和高效性:直接性体现在卷积神经网络可以直接将原始图像作为输入,避免了对图像的复杂前期预处理,提高了算法效率;高效性体现在卷积神经网络的权值参数少、收敛速度快,很大程度上加快了网络的训练过程。同时,卷积神经网络因其学习和记忆特性,在识别图像时无需给出经验知识和判别函数,只需通过样本训练网络,并根据网络输出与样本目标输出的差值调整权值参数,利用训练好的网络能够对输入图像进行分类,达到识别目的。
传统的卷积神经网络在处理特征模糊、歧义性大的输入图像时容易受到图像中不相关信息误导,难以保证较高的识别率。若能将图像中不相关的信息屏蔽,提高特征明显的局部图像对整幅图像输出结果的影响权重,即能有效提高对于特征模糊图像的识别率。基于上述思想,本文构建基于局部特征的卷积神经网络模型(Convolutional Neural Network Model Based on Local Feature,CNN-LF)。
1 卷积神经网络
卷积神经网络作为深度学习的重要分支,被广泛应用于图像处理、模式识别等领域。该网络最大的特点在于采用局部连接、权值共享、下采样的方法来模拟生物视觉神经元细胞的工作机制,对输入图像的形变、平移和翻转具有较强的适应性。其中局部连接使网络中的每一个神经元只与上一层网络中邻近的部分神经元相连,简化了网络模型;权值共享使得卷积滤波器共享相同的权重矩阵和偏置项,很大程度上减少了需要训练的权值参数数量;下采样能够减小特征图的分辨率,从而降低计算复杂度,并使网络对图像的平移、形变不敏感[7-10]。
与其他神经网络相比,卷积神经网络的独特性在于采用卷积层和下采样层交替的方式提取图像特征,从而减少训练参数的数量,在保持网络学习能力的同时,降低网络训练难度[11]。
1.1 卷积层
在卷积层中,输入特征图与卷积滤波器相卷积,卷积结果加上一个偏置项作为激活函数的输入,经过激活函数处理后得到该层的输出特征图。为一个k阶矩阵,包含k×k个可训练参数。对于一个大小为m×n的输入特征图,与k×k的卷积核相卷积之后,输出特征图大小为(m-k+1)×(n-k+1)。卷积层的表达形式为:
(1)
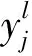
图1展示了一个5×5的输入图像与3×3的卷积核相卷积的过程。
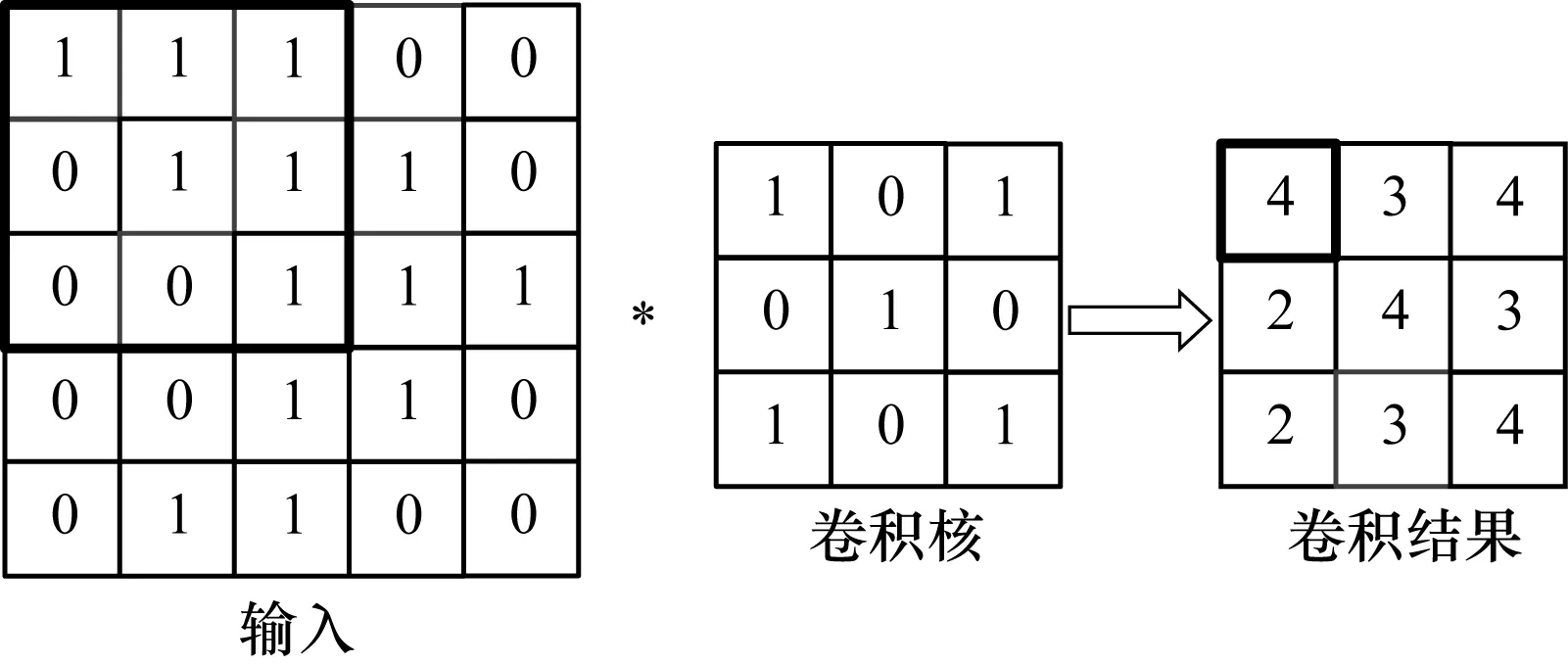
图1 卷积操作示意图
1.2 下采样层
在下采样层中,要对输入特征图进行降分辨率。将提取到的图像特征映射到更小的平面范围中,以简化网络结构,降低计算规模。下采样是以一定步长对输入特征图进行采样,而非连续采样,一般情况下采样步长与采样核宽度相一致。若采样核大小为s×s,则需要将输入特征图划分为若干个s×s的子区域进行映射,每个区域经过采样函数后输出一个特征值,这就使输出特征图的尺寸降为输入特征图的1/s。下采样层的表达形式为:
(2)

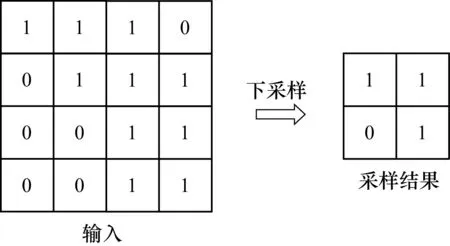
图2 下采样示意图
2 CNN-LF模型
2.1 改进思想
卷积神经网络在识别图像过程中有时会因为输入图像中存在干扰信息而影响识别结果,图3为包含干扰信息的2张手写数字图像。在图3(a)中,右侧图像是左侧图像取左下部分的局部图像,在图3(b)中,右侧图像是左侧图像取右下部分的局部图像。当图像中存在干扰信息时,容易影响卷积神经网络的识别结果,如图3中的数字“8”和“0”容易被识别为数字“6”。若对歧义性大的图像中特征较为明显的局部进行识别,则能有效解决这一问题,如图3中右侧的2张局部图像,其图像特征明显,不存在干扰信息,便于卷积神经提取图像特征。

图3 包含干扰信息的数字图像
基于上述思想,本文设计一种基于局部特征的卷积神经网络模型(CNN-LF),通过对特征明显的局部图像进行识别,屏蔽输入图像中的干扰信息。
2.2 CNN-LF模型结构
CNN-LF基于经典卷积神经网络模型LeNet-5。LeNet网络模型首次引入部分连接、权值共享以及下采样方法,被认为是真正意义上的卷积神经网络,在此基础上发展的LeNet-5最早被应用银行支票上的手写数字识别,识别率达到了99.2%[12-13]。与LeNet-5相比,CNN-LF在激活函数的选取和全连接分类层的构造上进行改进,并增加局部特征提取 (Local Feature Extration,LFE) 层和概率权重综合 (Probability Importance Synthesis,PIS) 层,CNN-LF的总体结构如图4所示。

图4 CNN-LF模型总体结构
CNN-LF由3个部分组成:改进的LeNet-5作为子网络,LFE层,PIS层,下面分别进行详细说明。
2.3 改进的LeNet-5模型
CNN-LF的子网络由经改进后的LeNet-5构成,该网络包含7层结构,除输入层和输出层以外,还包含2层卷积层(C1,C2)、2层下采样层(S1,S2)和1层全连接层(F1),其网络结构示意如图5所示。
图5 改进的LeNet-5模型结构
卷积层C1中包含6个大小为5×5的卷积核,得到6幅大小为24×24的输出特征图;卷积层C2中包含12个大小为5×5的卷积核,得到12幅大小为8×8的输出特征图;下采样层S1与S2都是对输入特征图进行平均值采样(Mean-Pooling),经采样后输出特征图的分辨率降为输入特征图的1/4。
LeNet-5是卷积神经网络的经典模型,该网络模型在文献[2-3]中有详细的说明,本文对LeNet-5的改进主要包括以下3点:
1)调整网络结构、网络层间连接方式。改进后的网络中C2层的卷积核数量为12,得到12幅输出特征图且每一幅输出特征图都与S1层的6幅输出特征图存在连接,而原LeNet-5中该层次卷积核数量为16,每一幅输出特征图只与上一采样层的部分输出特征图存在连接。
2)对网络高层结构进行简化。LeNet-5的高层包括2层全连接层,并用径向基(RBF)函数处理得到网络输出。由于全连接层中包含大量权值参数,因此减少全连接层的数量有利于降低计算复杂度。改进后的LeNet-5仅包含一层全连接层F1,F1为S2的12个特征图展开形成的列向量。输出层采用Softmax函数,Softmax函数常用于多分类问题中,由于其的归一化特性,改进后的LeNet-5的输出可以视为概率向量,该向量中的每一个元素代表对应分类的概率。
3)对激活函数的选择进行优化。LeNet-5中激活函数采用tanh双曲正切函数,该函数作为激活函数存在梯度饱和问题,即当输入很大或很小时,求得的梯度值接近于0,使得网络收敛缓慢[8-9]。本文借鉴AlexNet的做法,以ReLU函数作为激活函数,该函数具有单侧抑制、相对宽阔的激活范围以及稀疏激活性的特点,与tanh相比效果更优。
2.4 LFE层
LFE层主要用于提取输入图像的局部特征,作用于子网络之前,不包含需要训练的权值参数。由于输入图像的中间部分包含图像的主要特征,在提取局部特征时,若简单地对对输入图像进行等分,容易破坏图像特征,因此需要根据图像大小采取相应的划分策略,以尽量保留图像中间部分的特征。此外,还需要用空白信息,将提取到的局部特征图拓展到与原输入图神经网络对于输入图像具有平移不变性,因像相同的分辨率,以保证网络结构的一致性,由于卷积此对局部图像进行填充并不会影响网络识别图像特征。LFE层对输入图像的处理过程如图6所示。由于实验中的输入图像分辨率为28×28,因此设置提取局部特征的窗口大小为18×18,能够包含输入图像中间部分的主要特征。经过LFE层之后,得到4幅与输入图像同分辨率的局部图像。
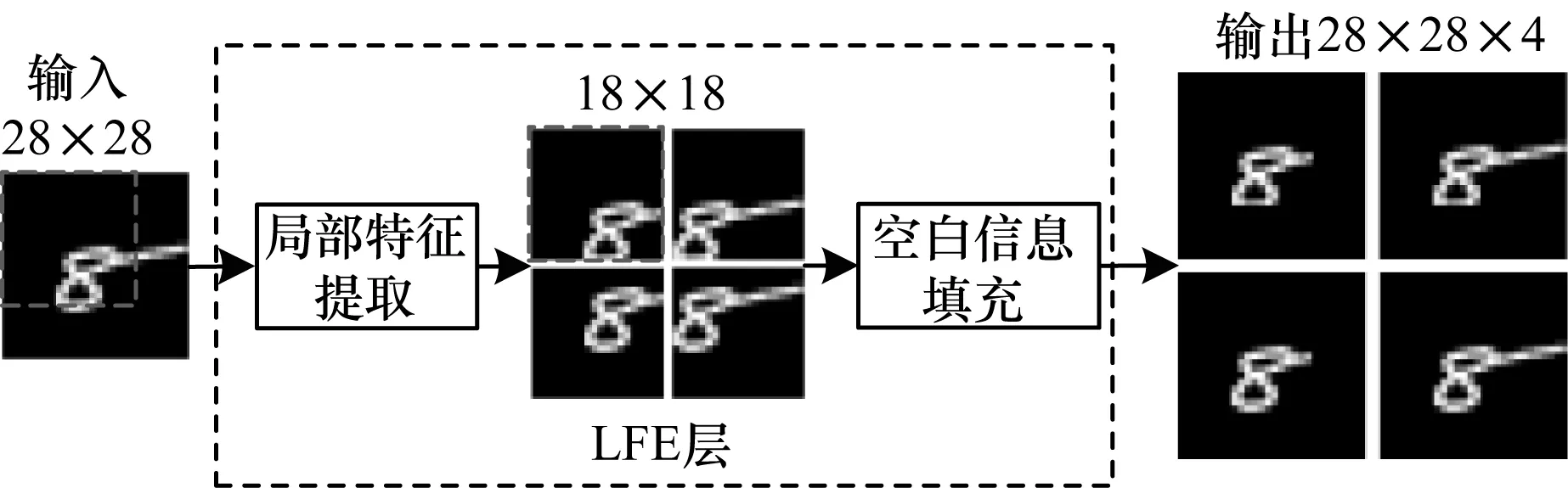
图6 LFE层数据处理过程
2.5 PIS层
PIS层对子网络输出的概率向量进行综合计算,首先用softplus函数处理输入的概率向量,再对概率向量进行求和,得到最终的输出向量,输出向量中的最大元素对应的序号即为CNN-LF的分类结果。softplus函数的数学表达形式如下:
f(x)=ln(1+ex)
(3)
softplus函数曲线如图7所示,其中虚线为对照直线。

图7 softplus函数曲线
由图7可知,当自变量取值为0~1时,softplus函数的斜率随自变量的增大而增大,因此,softplus函数能够进一步增大强信号与弱信号之间的差异。输入的概率向量经softplus函数处理后,向量中较大的元素能够获得更大的权重。图8为PIS层对输入的概率向量综合处理得到输出的过程。PIS层输入的概率向量和CNN-LF最终的输出都为列向量(10×1),图8中仅将分类值为“6”和“8”(向量中第6个和第8个元素)的元素值列出,网络最终的识别结果为输出向量中最大元素对应分类值。
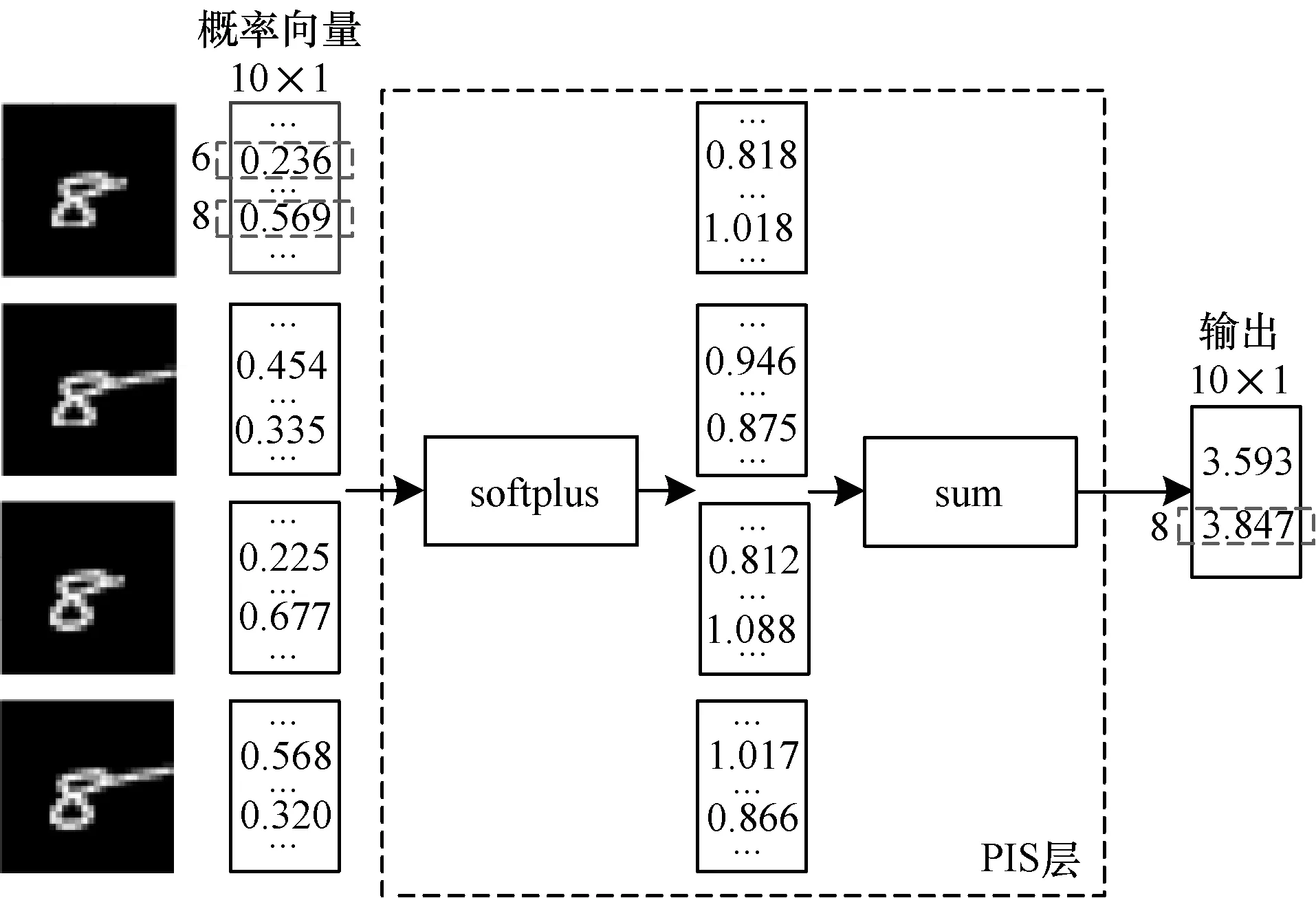
图8 PIS层数据处理过程
3 实验与结果分析
为验证CNN-LF的性能,本文在MNIST手写数字数据集上进行实验,分别用CNN-LF和LeNet-5实现了手写数字识别,针对实验结果进行对比分析。
3.1 实验数据
MNIST手写数字数据集由Google实验室的Corinna Cortes和纽约大学的Yann LeCun建立,共包含70 000幅样本图像,其中60 000幅为训练集,10 000幅为测试集。MNIST数据集中的每一个手写数字样本都是一幅分辨率为28×28的灰度图像,由于采集样本的对象不同,对于同一数字,不同样本之间存在很大差异性。图9是从MNIST数据集中分别提取数字“0”和数字“1”的16个样本。

图9 MNIST数据集中的数字“0”和“1”
3.2 实验结果
设计实验将CNN-LF与经典卷积神经网络LeNet-5进行对比。对比实验中,除了两者的网络结构不同以外,保持其他的网络参数相一致,依据Xavier初始化方法对两者的卷积核进行初始化[14-16],训练过程采取随机梯度下降方法,每次输入20个样本进行训练(即每识别20个样本调整一次权值),学习率为0.01,使用带动量项的BP算法更新权值,动量系数取0.9[17]。图10为LeNet模型和CNN-LF模型的实验结果对比。实验中CNN-LF在训练阶段每迭代一次(处理60 000个样本)耗时约为2 min,训练网络时网络迭代次数越大,训练后的网络识别率就越高。

图10 训练迭代次数与识别率
由图10可以看出,与LeNet-5相比,CNN-LF的识别错误率更低,尤其是在迭代次数较小的情况下,CNN-LF能够将识别错误率降低1.0%~1.5%。当训练迭代次数达到40次时,CNN-LF基本达到收敛状态,此时的错误率为0.45%。由于CNN-LF增加了LFE层和PIS层,网络结构更为复杂,因此在对比实验中CNN-LF在训练阶段的耗时高于LeNet-5模型。
3.3 采样分析
为进一步验证CNN-LF性能,本文根据LeNet-5的测试结果对测试样本进行重采样,获取迭代次数为20 时LeNet-5识别错误的数据集(Testing Error set)。Testing Error set中的图像特征较为模糊,歧义性较大,图11为Testing Error set中的部分样本图像。

图11 Testing Error set中部分样本
在Testing Error set上对不同迭代次数下的CNN-LF和LeNet-5进行测试,实验结果如表1所示。表1中Iterations表示用于测试的CNN-LF在训练阶段的迭代次数,其中结果表明,CNN-LF在识别特征不明显的图像时能够保持较高的识别率,在迭代次数相同的情况下,CNN-LF与传统卷积神经网络相比,识别错误率更低。
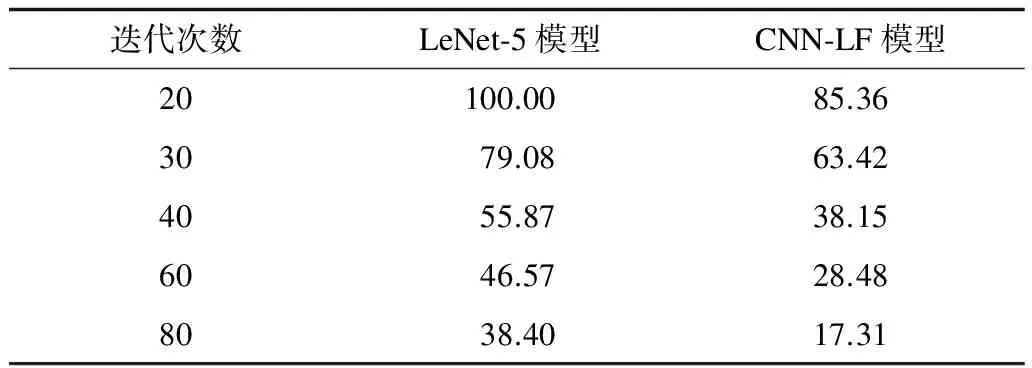
表1 在Testing Error set上的识别错误率 %
4 结束语
本文在传统卷积神经网络的基础上,构建一个新的网络模型CNN-LF。通过增加局部特征提取层和概率权重综合层对图像的局部特征进行识别,并根据输出的概率向量将局部图像的识别结果以一定的权重进行累加,得到最终的网络输出。通过在MNIST数据集上进行对比实验,并在重采样得到的Testing Error set上进一步分析,证明该模型比传统的卷积神经网络模型识别率更高,尤其对于特征模糊的图像具有较高的适用性。后续工作是进一步优化CNN-LF模型,并将其应用于其他图像识别领域。
[1] 郑 胤,陈权崎,章毓晋.深度学习及其在目标和行为识别中的新进展[J].中国图象图形学报,2014,19(2):175-184.
[2] 周志华,陈世福.神经网络集成[J].计算机学报,2002,25(1):1-8.
[3] RUMELHART D,MCCLELLAND J.Parallel Distributed Processing:Explorations in the Microstructure of Cognition:Foundations [M].Cambridge,USA:MIT Press,1987.
[4] LeCUN Y,BOTTOU L,BENGIO Y.Gradient-based Learning Applied to Document Recognition[J].Proceedings of the IEEE,1998,86 (11):2278-2324.
[5] LECUN Y,HUANG F J.Large-scale Learning with SVM and Convolutional for Generic Object Categorization[C]//Proceedings of IEEE Computer Society Conference on Computer Vision & Pattern Recognition.Washington D.C.,USA:IEEE Press,2006:284-291.
[6] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet Classification with Deep Convolutional Neural Networks[M]//PEREIRA F,BURGES C J C,BOTTOU L,et al.Advances in Neural Information Processing Systems 25.[S.l.]:Neural Information Processing Systems Foundation,Inc.,2012:1097-1105.
[7] 常 亮,邓小明,周明全,等.图像理解中的卷积神经网络[J].自动化学报,2016,42(9):1300-1312.
[8] KALCHBRENNER N,GREFENSTETTE E,BLUNSOM P.A Convolutional Neural Network for Modelling Sentences[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.[S.l.]:Association for Computational Linguistics,2014:655-665.
[9] JI Shuiwang,XU Wei,YANG Ming,et al.3D Convolutional Neural Networks for Human Action Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231.
[10] YANG Weixin,JIN Lianwen,TAO Dacheng.DropSample :A New Training Method to Enhance Deep Convolutional Neural Networks for Large-scale Unconstrained Handwritten Chinese Character Recognition[J].Pattern Recognition,2010,20(1):17-21.
[11] 张佳康,陈庆奎.基于CUDA技术的卷积神经网络识别算法[J].计算机工程,2010,36(15):179-181.
[12] LeCUN Y,BENGIO Y,HINTON G.Deep Learning[J].Nature,2015,521(7553):436-444.
[13] GARCIA C,DELAKIS M.Convolutional Face Finder:A Neural Architecture for Fast and Robust Face Detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(11):1408-1423.
[14] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2014:580-587.
[15] KARPATHY A,TODERICI G,SHETTY S,et al.Large-scale Video Classification with Convolutional Neural Net-works[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2014:1725-1732.
[16] DONAHUE J,JIA Yangqing,VINYALS O,et al.DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition[J].Computer Science,2013,50(1):815-830.
[17] ZAMORA-MARTNEZ F,FRINKEN V,ESPAABOQUER A S,et al.Neural Network Language Models for Off-line Handwriting Recognition[J].Pattern Recognition,2014,47(4):1642-1652.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
江苏通信(2018年4期)2018-12-04
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年7期)2017-04-18
