
改进的基于狄利克雷混合模型的推荐算法
2018-03-01 05:25董坚峰张玉峰戴志强
吉林大学学报(工学版) 2018年2期
董坚峰,张玉峰,戴志强
(1.吉首大学 软件学院,湖南 张家界427000;2.中山大学 管理学院,广州510275;3武汉大学 信息资源研究中心,武汉430072)
0 引 言
选择模型在机器学习过程中一直属于研究热点以及研究难点[1]。随着互联网技术的高速发展以及在各个领域里应用越来越广泛的网络应用,网络数据所具有的时间与空间上的动态变化特征已不能被人所忽视,变得越来越重要。针对一些新闻、网页等文本信息类构造文本推荐模型时,必须要充分考虑这些数据的时间与空间上的动态变化特征。一些专家学者为了在某种程度上解决这一问题,创建了贝叶斯非参数模型[13]。通过非参数贝叶斯先验,能够对模型的规模自动改变,进而与数据的复杂性相适应。近几年,贝叶斯非参数模型在相关领域如文本建模型领域[2]和推荐系统[3]等的作用越发重要。
狄利克雷过程混合模型具有应用灵活和推理算法高效的特点,目前在贝叶斯非参数模型中极为重要。作为混合模型组件的先验,DP狄利克雷过程混合模型与参数型话题模型比较接近:在狄利克雷分布中隐含狄利克雷分配作用[4]。全部基于可交换的基本假设,包括狄利克雷分布混合模型和狄利克雷过程混合模型。可交换性假设在狄利克雷过程混合模型当中,标志着一个共享狄利克雷过程可产生全部数据单元,可交换性能够通过混合模型的全部组件得到满足,即组件的概率不随着组件的顺序变化而改变。不过,这个假设在大部分应用中都不成立。
文本建模在网络应用中是应用广泛的推荐技术。许多专家学者对文本的建模做了一些研究工作,文本存在的话题包括一个或者多个,其中单词概率分布问题即指话题。新的话题伴随时间的延续而产生,已存在的话题有可能消失或者发生其他变化。这种现象与空间上比较相类似,可能在某区域范围之内只出现一个话题,在不同的地点同一个话题的分布也会变化。混合模型组件在相关情景之中,与可交换性假设并不相符,其动态性在某种时间或者空间的协变量上持续存在。一些该领域的专家学者做了一些改进传统混合模型考虑组件动态性的相关工作研究[5],大部分都考虑话题在时间上的动态性,比如,由Lin等[6]提出的马尔科夫模型,对话题在离散时间协变量上的相关性处理就主要基于马尔科夫链的狄利克雷过程[7]。
空间与时间相关性事实上也是有关联性的[8]。一维欧几里得空间通过时间被形式化,而二维欧几里得空间被形式化成为地点。两者从这个意义上讲是一致的[9]。在给定协变量空间上我们可以考虑创建相关狄利克雷过程,混合模型的组件在生命周期内以其为先验,而组件参数在生命周期内也会发生改变[10-12]。
传统文本建模模型大多以可交换性的基本假设为前提,对文本数据时间与空间上的动态变化相关性考虑不周,无法对这些具有动态性的网络数据进行有效建模。在动态数据建模的研究中,前人的工作多分别考虑随离散时间、连续时间或地点变化的贝叶斯先验,忽视了协变量的统一性。本文提出的贝叶斯非参数先验函数式狄利克雷过程,可以发生任意协变量变化。在建模过程中,利用函数定义域中取值的变化改变混合模型组件参数。在函数空间上,通过投影和约束狄利克雷过程来获取任意协变量空间相关参数空间上的狄利克雷过程。针对函数式狄利克雷过程,本文更进一步设计出了基于吉布斯采样的高效推演算法。仿真实验结果表明,本文提出的将函数式狄利克雷过程作为动态非参数先验具有良好的有效性。
1 相关定义
定义1 假设α为正实数,概率空间Θ上任意随机分布G,假如对概率空间Θ中可测变量能够有限划分随机向量(G(A1),G(A2),…,G(A n)),并且符合狄利克雷模型分布,则其可以形式化表示为:(G(A1),G(A2),…,G(A n))~Dir(G0(A1),G0(A2),…,G0(A n)),则称G为一个狄利克雷过程,记为G~DP(αG0)。
定义2 狄利克雷混合模型(DPM)指的是将贝叶斯层级模型的先验设置为狄利克雷过程的模型。狄利克雷混合模型主要应用范围为一些非参数聚类任务,其优点为不用额外预先调整任务聚类数目,该模型能够依据任务中得到的数据自主进行学习[13]。狄利克雷混合模型表示成产生式过程为:
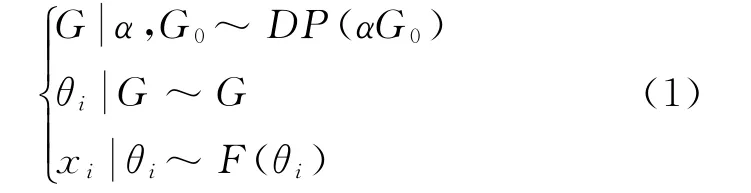
式中:{x1,x2,…,x n}代表观测到的数据信息,F(·)代表着变量为(θ1,θ2,…,θn)的似然方程,θi的选取过程为从DP中随机抽取,符合可交换性假设。但在实际应用中这个假设并不是十分的科学合理,因此,本文提出协变量相关的狄利克雷过程来替换公式(1)中的G。
2 函数式狄利克雷过程
参数空间,即狄利克雷过程组件参数概率空间由(Ω,Σ)表示,其中协变量空间由Θ表示。构建某个概率测度D∗时,可以在一个可数有限的连续函数空间上进行,而该概率测度中的某个组件都是函数,并且这些函数是连续有限的,把它叫做functionalatom,即函数单元,其中协变量空间Θ的子空间由函数的定义域表示。任意索引Φ∈Θ由协变量空间给定,并且给定概率测度D∗,首先,采取重归一化和限定操作方法,主要针对D∗,选择函数单元f,其中定义域包含Φ。随后从函数空间至参数空间,把相关函数单元投影为相应的单元f(Φ)。在这种情况下,可获取概率测度DΦ,主要从概率空间Ω得到。
通过对以上步骤的总结,针对狄利克雷过程,给D∗加上了一个先验,进而得到以下公式:
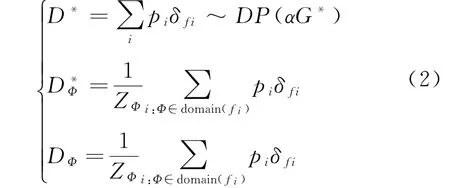
通过上述公式可知,f上的概率分布由G∗表示,一个连续函数空间由f表示,其中协变量空间上的子空间为其函数的定义域,而{f i}是G∗独立抽样,为可数无限个,再者,ZΦ=∑i:Φ∈domain(f i)p i代表归一化参数,确保归一化概率测度在任意协变量空间上的任意一点Φ。如例如所示,给定无向图的全部节点集合ℝ与ℝ2共同组成协变量空间,而ℝ中某个子集与节点子集合,以及ℝ2中某个子集合属于其对应函数单元的定义域,
(1)边际分布
参考狄利克雷过程的性质可知[14],通过投影和限定操作可知对某个狄利克雷过程依然属于狄利克雷过程,所以,DΦ与在上述构建过程中都属于狄利克雷过程。具体得出以下引理:
引理1 在(Ω,Σ)上表示狄利克雷过程,设D=∑p iδθi~DP(μ)。
1)随机概率测度的计算,通过重归一化和限定D到X上得到的值同样是DP,Ω上的可测量子集由X⊆Ω表示。
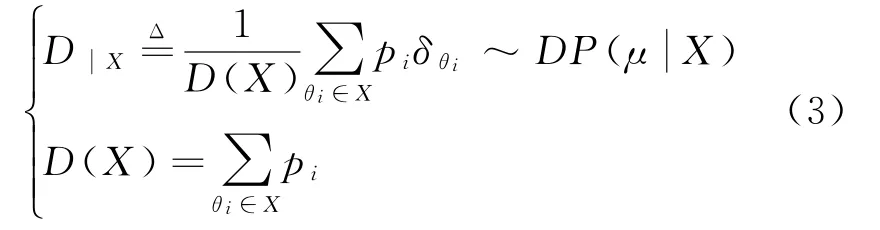
2)对D进行投影,通过可测量函数g:Ω→Ω′计算得到的概率测度同样是DP。
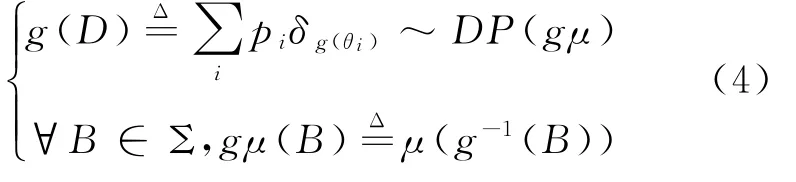
通过上述引理可知,得到Dφ边际分布如下所示:

通过上式可知,在(Ω,Σ)上定义的一个测度为μφ,得到∀A∈Σ,如下式所示:

(2)动态混合模型
可用于混合模型的非参数先验为协变量相关的狄利克雷分布{Dφ}φ∈Θ。有可能重复的索引为φ1,…,φn,通过协变量空间形式化的给定,观察(x1,φ1),…,(x n,φn)数据,发现其来自以下产生式过程。
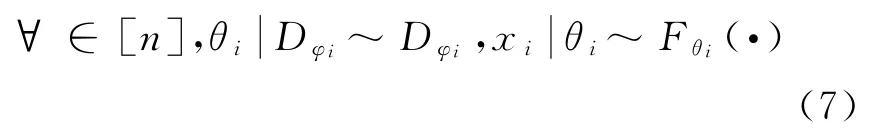
通过上式可知,参数θ的概率分布由Fθ(·)表示。对参数θi的混合模型的组件进行抽样计算,计算得到观察的数据x i,该数据在协变量θi处,通过该函数决定θi的具体数值,而在表达式中已经通过积分的形式去掉了函数f i。
3 函数基分布计算
一些专家与学者提出基于截线权值与协变量数值关系来构造动态非参数贝叶斯先验的方法[15]。但此类构造算法中狄利克雷过程原子的坐标信息是一定值,不能随协变量的数值变化来进行调整。也有一部分专家学者提出一类基于中国餐馆过程的构建动态非参数贝叶斯先验方法[16],此种方法的缺点在于只考虑协变量空间是一维实数ℝ,应用范围不广。
在上述内容中,利用函数空间构建协变量相关的狄利克雷过程,介绍了一些方式方法。在机器学习过程中,为有效应用这种构建方法,需要使用G∗的基分布,即Base distribution。在构建狄利克雷过程相关性时,起到决定性作用的是基分布,如果应用于不同的范围,则相应的选择也不一致。
为使相关内容更为简捷,设g:domain(g)→Ω为随机函数,在协变量空间中的独立随机子集上限定整个协变量空间中的随机过程。具体内容如下:
(1)通过domain(g)关于子集的分布抽样决定函数的定义域。
(2)基过程(Base process),即这个随机过程主要指对定义在整个协变量空间上的随机过程{go(φ)}φ∈Θ进行抽样go:Θ→Ω,得到相应的函数值,通过{go(φ)}φ∈Θ的具体实现得到go:Θ→Ω。综上所述,限定)可得到随机函数。在此计算过程中,可假定函数取值与定义域之间具有一定的独立性。
3.1 函数取定义域的先验分布
在具体混合模型中,在协变量空间上,对混合模型组件的生命期限进行刻画过程中,利用函数的定义域进行相关计算,所选择的协变量和具体应用具有某种联系[17]。比如,针对某些话题模型,因其随时间变化而变化,很自然地把时间当作协变量,进而把一段时间的间隔当作函数的定义域,与ℝ上的线段相对应,其中线段的起始点证明这个混合模型开始产生,而其终点则证明此混合模型组件已经消失。在应用图像分割过程中,可将ℝ2上的某个连续区域当作混合模型组件的生命期限。并且针对这个混合模型的生命期限构建模型,在创建之前我们需要寻找一个合理的先验分布,应用于函数的定义域中。
参照Kolmogrov extension theorem基本原理,即柯尔莫哥洛夫扩展定理可知,可对定义域的有限维边际分布进行间接利用,对函数定义域的分 布 进 行 构 建,得 到。选择的φ不同,构建的任意分布也各不相同。即可在度量为d:Ω×Ω→ℝ的协变量空间上应用与直径相关的φ。
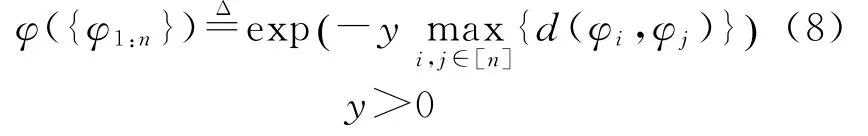
通过上式可知,我们可将其当作比较特殊的模型之一,即协变量空间Θ={1,2,…}的动态非参数先验考虑离散的固定长度的时间段为混合模型组件的生命期限。如果将{a i,a i+1,…,b i}设为协变量空间,当满足条件时,马尔科夫狄利克雷过程与我们的模型相互等价,这个过程与时间具有相关性。此结论与公式(4)~(8)的表述相同。其中,仅需进行简单的修改,就可在连续协变量空间ℝ上进行推广。设[a i,b i)为定义域,并且,针对普通欧几里得协变量空间Rd,上述公式可确保定义域的直径较小,并且这种概率极高。
3.2 函数组件的基过程
动态混合模型的非参数先验利用函数式狄利克雷过程实现,基过程的作用和标准狄利克雷过程混合模型中的基分布作用相似,两者都可应用于混合模型组件的参数先验,但是把基过程作为参数先验时,如果给定的协变量发生变化,则也允许参数改变。基过程的选择与标准狄利克雷过程混合模型相似,也和具体的应用密切相关。在选择基过程时,可选取与数据似然分布共轭的基过程。在本章节随后内容中,重点分析应用过程中的三种共轭基过程。
3.2.1 基于常函数的基分布分析
常函数的基过程比较简单,当协变量发生变化时,也允许混合模型的组件参数发生变化[18]。即 ∀φ,go(φ)=c,c~H0,通过该式可知,Ω上的概率分布为H0。H0与数据似然概率在实际应用过程中共轭时,可设计较为简单的折叠式吉布斯采样算法。
3.2.2 基于高斯过程的基分布分析
由实数向量代表概率分布的参数,即由θ∈R M代表Fθ(x),很自然地将会应用高斯分布描述θ的边际分布,协变量间的相关性通过高斯过程进行刻画。具体而言,设定一个协方差函数K(φ,φ′),一 个 平 均 函 数m(φ),可 将g0~GP(m,K)定义为基过程。
3.2.3 相关狄利克雷分布分析
假设已知W数目,并且数据单元为离散性质,比如应用有限话题模型时,假设基过程为类别模型。以此为背景,有效应用W-单形表面,实现对g0(φ)的取值。由于该过程在有限的空间中,属于一种特殊例子,在构建相关狄利克雷分布{g(φ)}φ∈Θ时,可应用函数式狄利克雷过程实现,可将Ω=[W]设为参数空间。具体而言,假设,在常数空间上,由代表有限测度。总而言之,应用该过程计算得到相关概率测度。通过这种方法成功构建了基过程,该基过程主要基于相关狄利克雷分布。得到预测分布,实现了更加便捷的计算方式,由此可知,所应用的推理算法具有较高效率。
4 基于吉布斯采样的推理算法
经过观察,假设n个数据X1:n的协变量分别为Φ1:n时,获取划分数据是此推理算法的主要目标,由于模型为非参数的,此算法实际之前并不明确所划分的数目。而一个函数式狄利克雷过程实际就相当于一个划分。详细来讲,与中国传统餐馆过程表示的餐桌分配相类似,为要求数据的函数分配Z1:n。通过对上述问题的形式化,形成数据X1:n的产生式过程,具体下述公式所示:
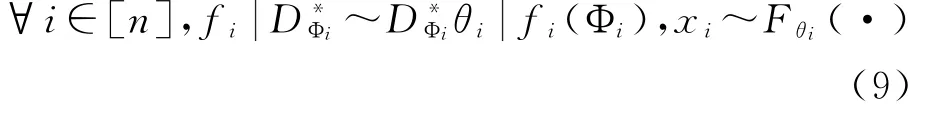
通过上述公式可知,在f1:n不重复的函数由表示,而函数则有c l次的发生。综上所述,可将函数分配进行如下表示,即z i∈[K]。
4.1 预测分布
在吉布斯采样算法中,最关键的设计为预测分布[10]。其中x为给定的数据单元,而Φ属于协变量索引,进而得到z,的预测分布。其主要依据为{z1:z(n-1),θ1:(n-1)},而混合狄利克雷过程,即Mixture of Dirichlet process为D∗的后验分布,应当重点关注狄利克雷过程混合模型与混合狄利克雷过程的区别,积分掉后验分布中的狄利克雷过程,可获取预测分布。
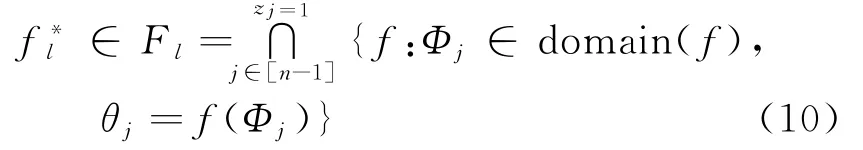
换而言之,对K个不同观察值给定,并且等价于{z1:(n-1),θ1:(n-1)},而且在集合f中包含着第l个观察,合计发生了c l次。可将进 一 步形式化,值得关注的是,每一个观察位置在传统狄利克雷过程后验分布的分析过程中都是已知的,不过函数单元的明确位置在推导过程中并不明确,仅仅了解到每一个观察有可能存在的区域部分。此类后验分布即称为混合狄利克雷过程[2]。详细来讲,给定函数为,其条件分布为,该函数D∗后验为DP(μ∗+∑iciδfi∗),最终获取给定时D∗的后验分布公式如下所示:
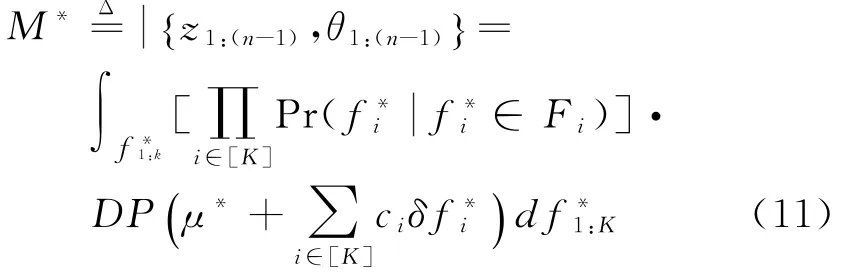
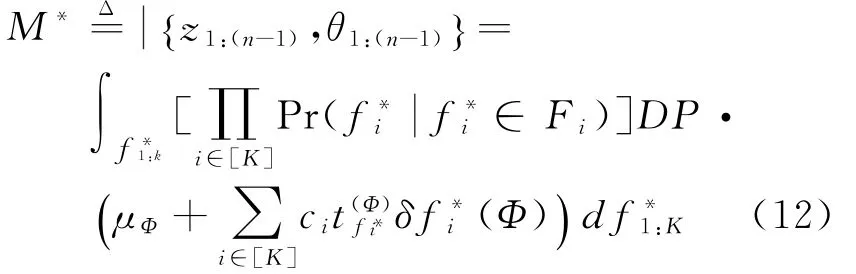
虽然,很多狄利克雷过程的混合为DΦ,在给定θ的情况下,全部Φ∈domain(f)=θ的函数,f对θ的影响是相同的。我们在这种情况下可对公式(12)进行简化,得到下述公式:

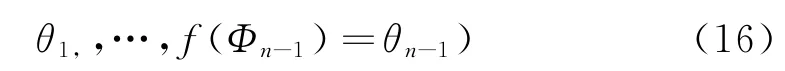
根据上述条件,可积分掉公式(13)中的狄利克雷过程,进而获得如下所示的预测分布z,:
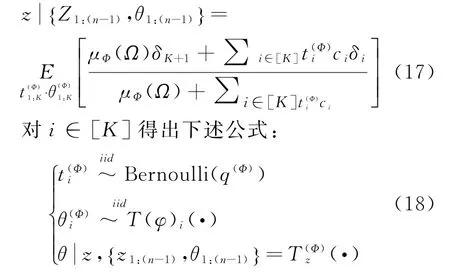
在上述公式中,δK+1代表着对某个新的函数进行分配,而如上述两个公式中的所示。
4.2 吉布斯采样
通过吉布斯采样法可对全部函数的z1:n,z i∈[K]进行分配,其中函数的数目由K代表,伴随迭代过程的进行,K的取值也将发生改变。另外,通过吉布斯采样,还能够对不同函数出现的次数c0:K进行维护,而每次迭代为,利用此算法可重新采样全部的z1:n,对每一个函数出现的次数进行更新。以下为Z n采样方法,包括赋值至协变量Φn及数据单元x n上。
(1)辅助变量采样:针对 每个k∈[K]中,对进行采样,进一步明确的定义域是否存在Φn,针对的定义与公式(4)~(14)相同。
(2)一般采样赋值:针对每个k∈[K],对进行采样,其中为分配至已存在函数的概率,而p(z n=k+1)∞为分配至新函数的概率,而基过程在Φn处的边际分布为和HΦn(·)。
(3)折叠采样赋值:对F与G∗进行适当的选择,可积分掉参数,对折叠采样算法进行设计。针对全部观察数据,其中数据x n由函数产生的概率表示如下式所示:
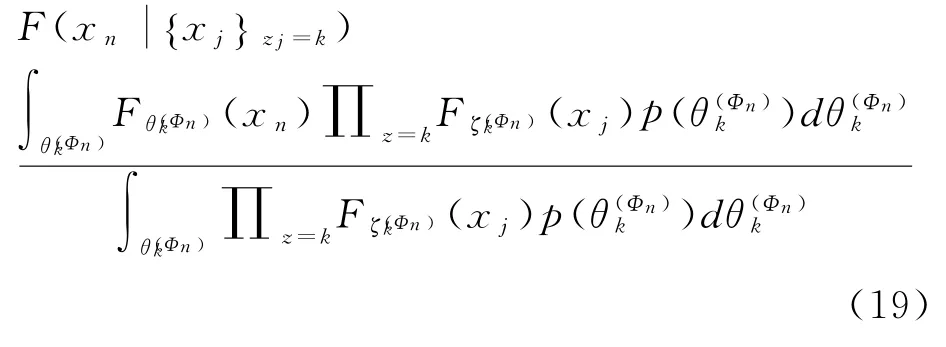
5 仿真实验与结果分析
5.1 通过模拟数据进行实验
针对已改进的高斯混合模型进行模拟实验。模拟产生了两个高斯组件。再参照泊松分布原理,即新的高斯组件通过每一个时间片段产生数目平均可为0.4个。采用几何分布形式,设定组件生命周期平均值为5,并且平均值呈布朗运动变化态势,方差为1。可对30个时间片段进行模拟实验,依据当前组件,将每个时间片段进行独立抽样,抽样的数据点为200个。并可应用函数式狄利克雷过程混合模型,聚类产生的相关数据,将时间片段设为协变量。将平均值为零的高斯过程设为基过程,其中式(8)为函数定义域分布。应用吉布斯采样算法,进行5000次的迭代运算,得到聚类的结果数据。
度量真实结果与聚类结果间的差异,可应用信息差异Variation of information[19]实现,再对所提模型进行评测,其中信息差异定义如下式所示:
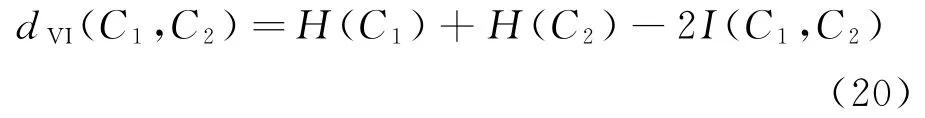
对比两种基线方法,即对比DPM标准狄利克雷过程混合模型与马尔科夫狄利克雷过程混合(Markov-DPM)模型可知。协变量空间在以上设置中的时间片段是离散的,两个过程相互等价。两者间的差异性在于推理算法的不同,其中函数式狄利克雷过程应用的推理算法为批处理法,而马尔科夫狄利克雷过程混合模型应用的推理算法为序列采样法。
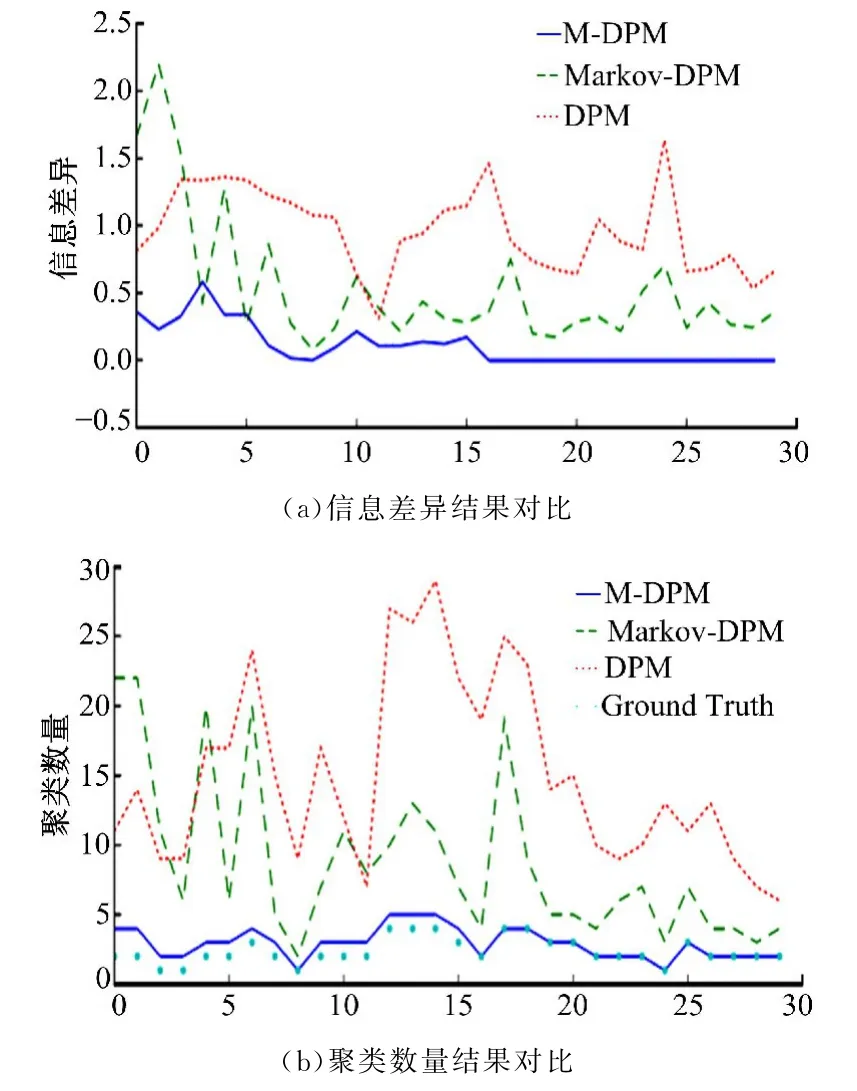
图1 模拟数据的聚类实验结果比较Fig.1 Comparison of clustering results of simulated data
由图1所示实验结果可知,每一时间片段的信息差异值显示在上半部分,每一时间片段真实聚类数目显示在下半部分。对比结果表明,与Markov-DPM相比,M-DPM在所有时间点的表现更具优势,主要原因在于批处理推理算法可应用全局信息,比Markov-DPM序列采样算法更具优势。与此同时,由于应用动态数据构建模型更加科学,与标准狄利克雷过程混合模型DPM的表现相比,Markov-DPM与M-DPM的优点更多。综上所述,利用M-DPM得到的结果聚类数目与真实结果更贴近,与标准DPM聚类结果相比,具有明显的优势。
5.2 M-DPM和DPM发现话题的数目对比实验
实验重点对1987年~2001年NIPS会议论文中的话题时间线进行分析[11]。该论文集共包含的文章有2484篇,属于公开的数据集。每一个话题在话题模型中都与单词分布相关,每篇文章也都与话题分布相关。我们的话题先验利用了函数式狄利克雷过程,在时间办变量上,每一个话题都存在一个生命周期,至少包含一个起点和终点,话题的分布在起点与终点间随时间的变化而变化。对生命期限的先验分布进行设置,设指数分布的参数为0.6,相关狄利克雷分布为基分布。图2显示了本实验针对1987年~2001年NIPS会议论文中的话题时间线的挖掘结果,由实验结果可知,发现产生了新的话题,而已存在的话题不见了,伴随时间的变化,每一个话题权重最高的关键词也在改变。
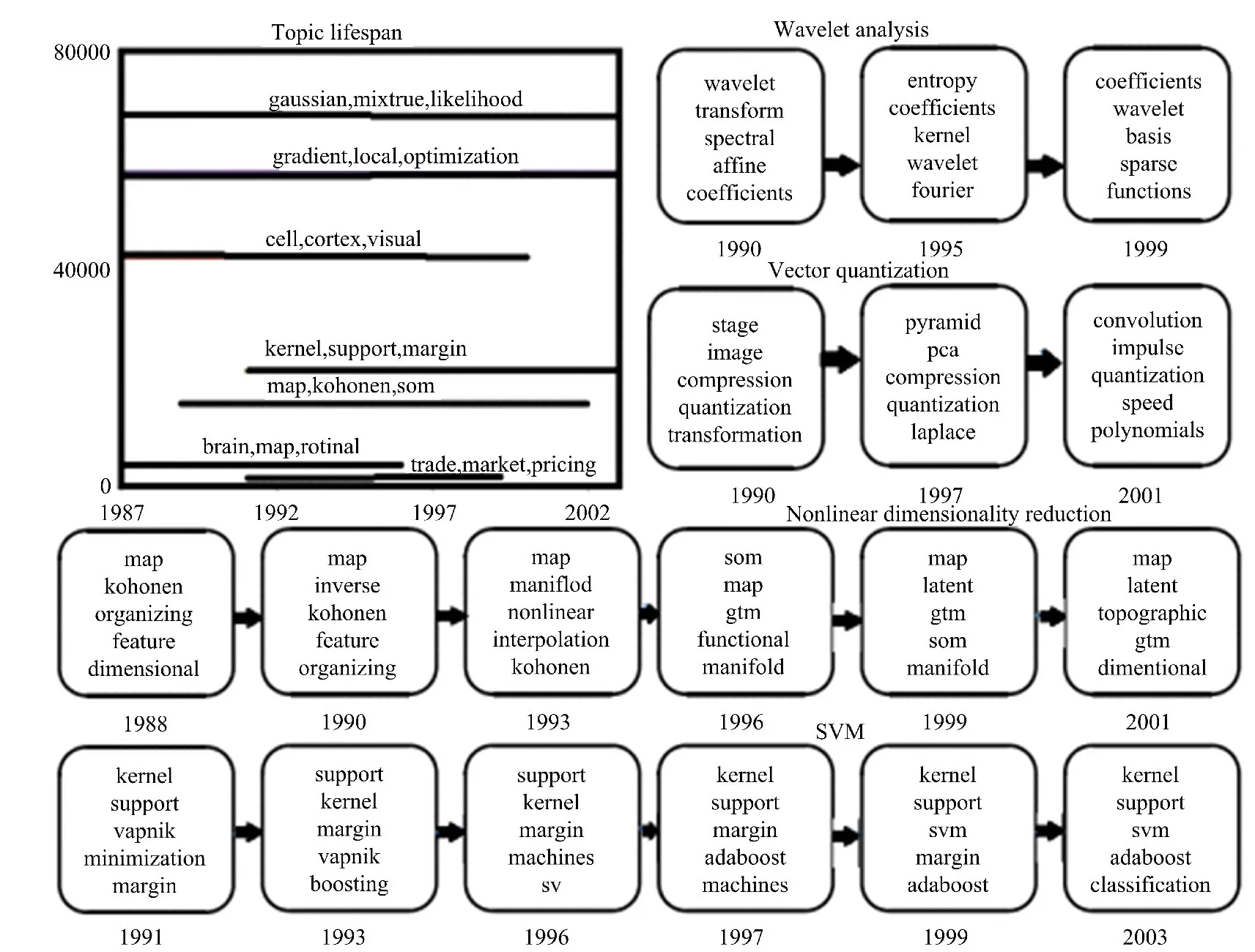
图2 话题时间线挖掘结果Fig.2 Result of mining time series
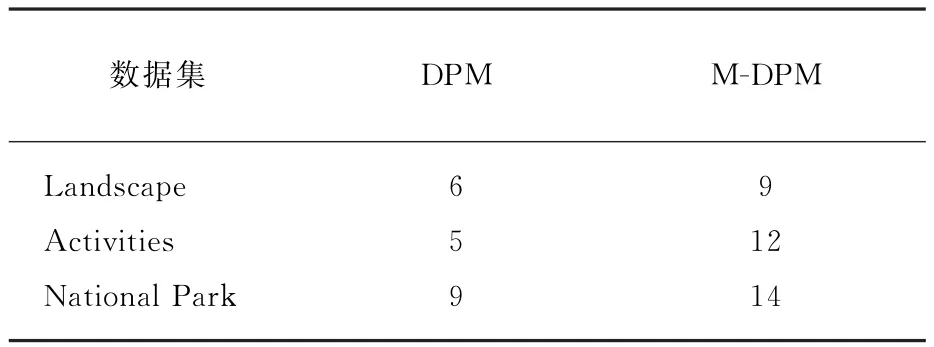
表1 M-DPM和DPM发现话题的数目Table 1 M-DPM and DPM find the number of topics
因标准狄利克雷混合模型不考虑地点信息,经过比较,如表1所示,显示出了DPM在3个数据集上发现话题的数目,以及M-DPM在3个数据集上发现话题的数目。经过对比可知,与DPM话题数目相比,M-DPM发现话题的数目更多一些,这是比较合理的情况,由于M-DPM对地点信息进行了认真的考虑,进一步约束了话题的范围,M-DPM所发现的话题具有更清晰的意义。
5.3 M-DPM和DPM似然性对比实验
在实验中,对函数式狄利克雷过程挖掘随空间变化的话题性能进行评测。在相关网站中对与GPS信息相关的图片标签数据进行抓取,并且对3个数据集进行抓取,具体包括National Park,Activities以及Landscape。为了分析过程更加方便,本文只把在美国领域范围内的GPS信息照片进行保留,并且把某些低频标签去除,这些低频标签出现的次数少于15次。最终分别得到了1505个图片,11 868个图片,2109个图片的3个数据集,以及3个标签,分别为2313个标签,2381个标签,2374个标签。
另外,表2为M-DPM与DPM两者比较的结果,我们采用似然性量化法,对M-DPM随空间变化在话题模型上的表现进行评测。从表中数据可知,与应用狄利克雷过程做先验的话题模型相比,应用函数式狄利克雷过程做先验的话题模型优势更多一些。

表2 比较似然性Table 2 Comparative likelihood
6 结束语
本文提出了一种改进的主要基于函数式DPM模型过程动态推荐模型。该模型对传统狄克雷混合模型在动态数据建模方面的问题进行改进,创建相关狄利克雷过程的参数与协变量空间联系,同时狄利克雷过程仍然属于边际分布。应用函数式狄利克雷过程,可针对产生、消失以及参数改变的混合模型组件进行有效建模,并可作为动态先验融入非参数混合模型。仿真实验结果表明,与应用传统狄利克雷过程做先验的话题推荐模型相比,本文提出的推荐算法优势更加明显。
[1]解男男,胡亮,努尔布力,等.基于Web日志挖掘的网页推荐方法[J].吉林大学学报:理学版,2013,51(2):267-272.Xie Nan-nan,Hu Liang,Nurbolz,et al.Web recommender system based on Web lob minim[J].Journal of Jilin University(Science Edition),2013,51(2):267-272.
[2]董立岩,王越群,贺嘉楠,等.基于时间衰减的协同过滤推荐算法[J].吉林大学学报:工学版,2017,47(4):1268-1272.Dong Li-yan,Wang Yue-qun,He Jia-nan,et al.Collaborative filtering recommendation algorithm based on time decay[J].Journal of Jilin University(Engineering and Technology Edition)2017,47(4):1268-1272.
[3]Jiang J,Lu J,Zhang G,et al.Scaling-up item-based collaborative filtering recommendation algorithm based on hadoop[C]∥Services,IEEE,2011:490-497.
[4]Chen W,Niu Z,Zhao X,et al.A hybrid recommendation algorithm adapted in e-learning environments[J].World Wide Web,2014,17(2):271-284.
[5]Qiu T,Chen G,Zhang Z K,et al.An item-oriented recommendation algorithm on cold-start problem[J].EPL,2011,95(5):58003.
[6]Lin K,Wang J,Wang M,et al.A hybrid recommendation algorithm based on Hadoop[D].Institute of Electrical and Electronics Engineers Inc.2014.
[7]Zhang J,Peng Q,Sun S,et al.Collaborative filtering recommendation algorithm based on user preference derived from item domain features[J].Physica A Statistical Mechanics&Its Applications,2014,396(2):66-76.
[8]Zhong Z,Sun Y,Wang Y,et al.An improved collaborative filtering recommendation algorithm not based on item rating[C]∥IEEE,International Conference on Cognitive Informatics&Cognitive Computing.IEEE,2015:230-233.
[9]Lu Z,Shen H.A security-assured accuracy-maximised privacy preservingcollaborative filtering recommendation algorithm[C]∥Proceedings of the 19th International Database Engineering&Applications Symposium,Yokohama,Japan,2015:72-80.
[10]Huang Y M,Kuo Y H,Chen J N,et al.NP-miner:a real-time recommendation algorithm by using web usage mining[J].Knowledge-Based Systems,2006,19(4):272-286.
[11]邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670.Deng Ai-lin,Zuo Zi-ye,Zhu Yang-yong.Collaborative filtering recommendation algorithm based on item clustering[J].Mimi-micro Systems,2004,25(9):1665-1670.
[12]Huang Z,Zeng D,Chen H.A comparison of collaborative-filtering recommendation algorithms for E-commerce[J].Intelligent Systems of IEEE,2007,22(5):68-78.
[13]严宇宇,陶煜波,林海.基于层次狄利克雷过程的交互式主题建模[J].软件学报,2016(5):1114-1126.Yan Yu-yu,Tao Yu-bo,Lin Hai.Interactive topic modeling based on hierarchical Dirichlet Process[J].Journal of Software,2016(5):1114-1126.
[14]Caron F,Davy M,Doucet A.Generalized polya urn for time-varying Dirichlet process mixtures[C]∥Proceedings of Proc of UAI’07,Corvallis,Oregon,2007:33-40.
[15]Caron F,Davy M,Doucet A.Generalized Polya Urn for time-varying Dirichlet process mixtures[J].2012.
[16]Rabaoui A,Viandier N,Duflos E,et al.DPMs for the density estimation in a dynamic nonlinear modeling:application to GPS positioning in urban canyons[J].IEEE Transactions on Signal Processing,2012,60:1638-1655.
[17]Blei D M,Frazier P.Distance dependent Chinese restaurant processes[C]∥Proceedings of Proc of ICML’10,Haifa,Israel,2010:87-94.
[18]Zhang M,Hurley N.Avoiding monotony:improving the diversity of recommendation lists[C]∥Proceedings of Proceedings of the 2008 ACM Conference on Recommender Systems,ACM,2008:123-130.
[19]Xu M,Zhu J,Zhang B.Fast max-margin matrix factorization with data augmentation[C]∥Proceedings of the 30th International Conference on Machine Learning(ICML-13),2013:978-986.
[20]Li L,Chu W,Langford J,et al.Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms[J].Wsdm,2012:297-306.
猜你喜欢
现代装饰(2022年5期)2022-10-13
中国卫生统计(2022年2期)2022-05-28
陕西理工大学学报(自然科学版)(2021年3期)2021-06-23
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
数学小灵通(1-2年级)(2020年4期)2020-06-24
自动化学报(2017年5期)2017-05-14
探测与控制学报(2015年4期)2015-12-15
中国卫生(2014年12期)2014-11-12
新高考·高二数学(2014年7期)2014-09-18
