
柑桔叶片黄龙病光谱特征选择及检测模型
2018-03-01 09:35刘燕德肖怀春孙旭东朱丹宁韩如冰叶灵玉王均刚马奎荣
农业工程学报 2018年3期
刘燕德,肖怀春,孙旭东,朱丹宁,韩如冰,叶灵玉,王均刚,马奎荣
0 引 言
黄龙病是柑桔产业中一种毁灭性的病害。果树一旦感染会迅速传播,为尽早发现并移除染病果树,当前该病检测方法较为常用的有田间症状诊断和核酸分子检测2种。前者是园艺师凭经验判断,准确率不高。后者为试验人员在室内进行化学分析诊断,成本较高,周期也长[1-2]。
随着黄龙病危害越来越大,黄龙病检测成为当前一个热点话题。相关研究表明用高光谱成像技术检测黄龙病表现出一定的潜力[3]。梅慧兰等在370~1 000 nm范围内获取 5类柑桔叶片的高光谱图像,结合偏最小二乘判别分析构建黄龙病的早期鉴别及病情分级模型,分类准确率达 96.4%[4-5]。邓小玲等在高光谱技术基础上采用最小噪声变换算法对柑桔黄龙病进行识别并分类,结果病情识别率达 90%以上,说明该技术对黄龙病病情的诊断具有较高的可行性[6]。Sankaran等干燥粉碎柑桔叶片后,利用傅里叶近红外光谱仪对叶片黄龙病进行诊断,判别率达到了95%[7]。上述研究中普遍存在数据维度较高,变量数较多,建立的模型也复杂且数据降维方法单一。用多种变量筛选方法及其组合方法对数据降维,优选变量使模型复杂度降低,提高预测精度。相比于主成分分析(principal component analysis,PCA)在数据降维上的简单易行,无信息变量消除算法(uninformative variable elimination,UVE)不仅可以剔除无关信息,还可以极小化变量之间的共线性影响[8]。遗传算法(genetic algorithm,GA)可防止过拟合现象,增强模型稳定性[9]。连续投影算法(successive projections algorithm,SPA)能消除冗余信息,保证更少变量数所包含的样品信息最全。从而达到优化模型的目的。
本研究运用高光谱成像技术获取轻度、中度、重度、缺锌和正常 5类柑桔叶片的图像;分别采用 UVE、UVE-GA和UVE-SPA三种数据降维(或组合)方法对叶片高光谱中的特征变量进行优选;结合极限学习机(extreme learning machine,ELM)与最小二乘支持向量机(least squares support vector machine,LS-SVM)2种定性判别方法构建柑桔黄龙病判别模型,并对模型进行验证优选,以期为柑桔黄龙病的高光谱快速诊断提供一种参考方法。
1 材料与方法
1.1 试验材料
根据当地农业园艺师的指导,于2016年10月在江西省万安县某果园基地采摘柑桔叶片。该基地被随机划分为5块小区域,每块小区域中选3棵柑桔果树,两两间隔12 m,从树的下方往上方采摘叶片,共采摘5类样品200片,其中40个轻度,42个中度、41个重度、40个缺锌和37个正常(其中黄龙病叶片和缺锌叶片表征相似,通过是否有“红鼻子果”来区分)。将所有叶片进行前期处理(清洗、晾干、压平等)后放冰箱 4 ℃左右保存。
在实验室进行高光谱图像采集(温度:22 ℃;湿度:60%),并按照国家标准规定的黄龙病检测方法-聚合酶链式反应(polymerase chain reaction,PCR)对每一片叶片进行标定。PCR测试引物分别根据Jagoueix等报道的O1O2和Hocquellet等报道的A2J5,由南京金斯瑞公司合成[10-11]。PCR测试结果如图1所示。PCR主要是扩增DNA至几个数量级从而呈现亮带,结果为阴性的是未染病样品,阳性的是染病样品。由于缺锌与黄龙病样品表面症状相似,故采用PCR进行测试,阳性的为黄龙病样品,对阴性泛黄的叶片采用原子吸收方法测定,均为缺锌样品。分析方法如文献[12]所示。综合 PCR结果和原子吸收方法,筛选轻度黄龙病、中度黄龙病、重度黄龙病、缺锌和正常5类样品,其中筛选失败样品数量分别为4、7、5、4和1个,并未计入采样数量之中,故参与试验的每类样品数量为36个。

图1 柑桔黄龙病叶片普通PCR测试结果Fig.1 Results of common PCR test for citrus Huanglongbing leaves
从图1可知,用O1O2作引物进行的PCR测试结果更清晰。正常、缺锌、轻度黄龙病、中度黄龙病和重度黄龙病依次呈现出亮带,且随黄龙病轻重等级,亮带颜色越来越亮[13]。DNA标记用途是DNA凝胶电泳时用来对比,以估算样品DNA分子量,M.DNA分子量标准(300~800 bp)。缺锌样品 PCR测试出现的亮带较黄龙病样品PCR测试出现的亮带暗淡,可能与叶片缺乏锌元素有关;而正常叶片PCR测试并未出现亮带[14]。而选用缺锌叶片是因其症状与患黄龙病叶片相似,具体结果如表1所示。
1.2 检测装置与图像采集过程
1.2.1 检测装置
自行搭建的高光谱成像系统包括光源、光谱采集暗箱、光谱成像仪、位移平台和计算机等硬件。光源为 2盏功率20 W的卤素灯(OSRAM,DECOSTAR51,MR16),通过稳压电源提供能量。光谱采集暗箱为 790 mm×790 mm×1 800 mm大小,用来消除外部环境中的光线。CCD摄像机(Hamamatsu C8484-05G)和光谱仪(ImSpector,V10E,芬兰)组成的光谱系统用于获取样品高光谱图像,通过USB数据线连接到计算机主板上的1 394图像采集卡。位移平台由步进电机和载物台组成,用来放置和移动样品。

表1 样品种类Table 1 Sample categories
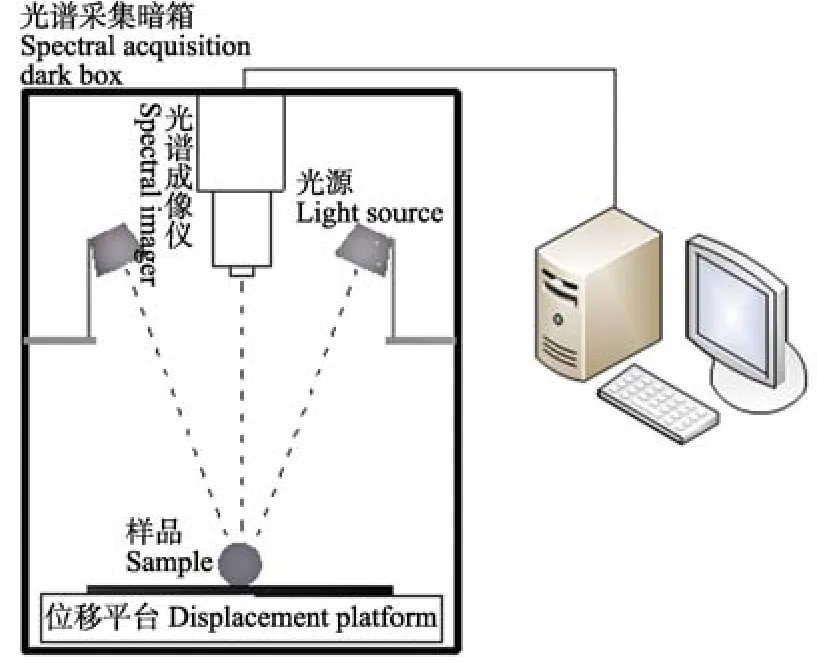
图2 高光谱成像系统Fig.2 Hyperspectral imaging system
1.2.2 图像采集
为获取最佳高光谱图像,采集前对系统参数进行设置,如曝光时间、移动速度和光谱仪分辨率等。通过SpectraVIEW 软件设置试验中参数:相机曝光时间为20 ms,分辨率为1 344×1 024像素,位移平台移动速度为16 mm/s,光谱范围是400~1 000 nm,光谱成像仪分辨率为2.8 nm。试验前系统预热30 min左右,可以消除基线漂移的影响。将叶片平铺在位移平台上,通过SpectraVIEW 控制步进电机带动位移平台移动进行连续扫描,从每个样品中获取256张图片,利用基于VC++6.0环境下的线图合成软件将 256张线图合并转化成高光谱三维图像,进一步用EVNI4.5软件对图像进行分析和数据提取[15]。
1.3 图像标定
为避免暗电流对叶片图像的影响,将采集到的图像进行黑白标定[16]。其步骤为与采集叶片图像相同条件下盖上镜头盖扫描一段全黑图像B,随后取下镜头盖扫描标准聚四氟乙烯材料制成的白板,得到全白的标定图像W。最后根据标定公式(1)进行标定,将采集到的原始图像Iλ转变为相对图像Rλ。

式中Rλ为标定后的图像;RW为全白图像;RB为全黑图像;Iλ为原始图像。运用 SpectraVIEW软件将所有图像标定完后进行下一步分析。
1.4 叶片高光谱数据处理算法
将叶片高光谱图像用 ENVI4.5软件处理获得的平均光谱数据维数较高,且含无关信息变量,为降低维度,首先用无信息变量消除法剔除无关信息,接着用遗传算法和连续投影算法进行变量筛选,最后结合 ELM 和LS-SVM建立判别模型,预测样品对其进行验证,若误判率满足条件则得到最佳模型,否则对降维参数进行进一步优化分析,直到获得最佳模型。具体流程如图3所示。

图3 柑桔叶片高光谱数据处理流程Fig.3 Hyperspectral data processing flow chart of citrus leaves
1.4.1 光谱数据降维算法
1)无信息变量消除算法
无信息变量消除算法(UVE)是一种针对偏最小二乘(partial least squares,PLS)回归系数建立的变量选择方法,其思想是根据向量所对应回归系数的稳定性来选取变量,可有效地筛选有用波长变量,剔除无贡献和冗余变量。光谱矩阵x与类别值Y之间的线性关系式如2所示。

式中x表示光谱矩阵,Y为类别值,βi是系数矩阵,b是误差向量。即把同维数的随机变量(人工添加随机噪声)与光谱进行拼接,通过交叉验证建立多个偏最小二乘回归模型,得到对应回归系数矩阵 βi,计算 βi的平均值和标准偏差相除的商iC来评价其稳定性。

式中βi表示系数矩阵βi的平均值,S(βi)表示对应矩阵的标准偏差,把 Ci大于人工添加随机噪声的稳定性 Cj对应的列向量用于PLS回归模型中[17-19],其中 Ci为光谱的稳定性指标, Cj为噪声的稳定性指标。
2)特征变量选择算法
遗传算法(GA)是一种基于生物遗传和进化机制且适合于复杂系统优化的自适应概率全局搜索算法,依据遗传机制和自然选择,在迭代同时将适应度低的个体淘汰,保留优良个体。主要用于选择最优模型的波长,将交互验证的均方根误差作为适应度函数。一般包括 6个步骤:个体编码;初始化;适应度的计算;选择;交叉;变异。其中后 4步依次交替进行,经遗传后产生新的种群,对其适应度进行评价,直至达成终止的标准[20-21]。
连续投影算法(SPA)作为一种特征变量选择方法,在重叠的光谱信息中提取有效信息,使光谱变量之间的共线性达到最小,冗余度最低。该算法在初始情形下选择一个波长,前向循环,计算未选择波长的投影向量,并挑选投影最大值对应的波长,然后将投影向量与波长进行组合,直至循环结束。此方法有利于减少计算量、简化模型结构、提高建模速度[22]。GA是解决最优化问题时选择最佳变量,而SPA是选择信息比重大的变量,二者在本文中为并列关系。
1.4.2 定性判别建模算法
极限学习机(ELM)是一种以单隐含层前馈神经网络为基础的新型网络学习算法,简单实用,解决了传统神经网络训练参数选取困难、易陷入局部最优等缺点,并以学习速度快、泛化能力强等著称,在回归预测、模式识别等领域得到了广泛的应用。最小二乘支持向量机变传统不等式约束为等式约束,以平方误差损失函数之和代替训练集的经验损失。最小二乘支持向量机的训练过程中,在高维空间里通过一个最小二乘价值函数获取一个线性方程组,从而将求解二次规划问题转化为求解线性方程组[23]。两种判别方法相比,ELM方法的模型优化速度较快,而 LS-SVM方法模型分析精度较高,本研究期望通过计算分析探索一种快速而准确的定性判别分析方法。
2 结果与分析
2.1 感兴趣区域提取与光谱特征分析
黄龙病叶片呈现的症状非常复杂,在不同生长季节可表现不同的症状类型。发病初期,顶部少数新梢叶片停止转绿,表现为树冠顶部枝梢黄化,即出现“黄梢”;显现期,表现为由叶脉基部和侧脉附近开始黄化,逐渐扩大形成黄、绿相间的不对称斑驳,形状和大小不一;在染病后成熟期表现为果蒂部深红色,俗称“红鼻子果”。黄稍作为其特异性的典型症状,是识别黄龙病的主要依据。与其他原因造成的柑桔叶片症状极为类似,且已感染此病但尚未表现明显的柑桔叶片难以依据症状准确诊断,故要与其他方法相结合。用ENVI4.5软件获取5类叶片叶脉右侧中间感兴趣区域的平均光谱后续分析[24-25]。
5类叶片(轻度、中度、重度黄龙病、缺锌和正常)的代表性高光谱曲线如图4所示,可以看出5种叶片的光谱曲线大致趋势相似。550 nm处是叶绿素的强反射峰,黄龙病阻碍植物光合作用,导致该处叶片的反射峰高于正常叶片。700~1 000 nm为叶片的高反射率区域,由于叶片中的有机分子含有较多的氢基团,较明显的反射峰位于原始高光谱720 nm处,反射峰主要由O-H键4级倍频伸缩振动导致。因黄龙病叶片中含水量偏低,造成反射率低于正常叶片,并随着病情加重逐渐降低,重度黄龙病叶片的反射峰最低。缺锌叶片在该处的反射峰可能是锌营养元素不足造成的,缺锌叶片与黄龙病叶片光谱曲线存在重合之处可能是叶片所缺的元素与黄龙病阻碍光合作用导致叶片所丢失的元素相同[26-28]。

图4 5类柑桔叶片的代表性高光谱Fig.4 Representative hyperspectral of 5 kinds of citrus leaves
2.2 叶片高光谱数据降维处理
2.2.1 叶片高光谱数据无信息变量消除
用UVE对256个原始光谱变量剔除无用信息变量。在该过程中产生随机变量个数设置为 200个。变量剔除结果如图5所示,左、右侧分别为256个原始变量和200个随机变量的稳定性分布曲线,两条水平线为变量选择阈值的上下限,处于这两者之间的数值对应的变量不用于建模,而两者之外数值对应的变量被保留。阈值选定标准为随机变量稳定性最大值的98%,经UVE筛选后的变量数为105个。
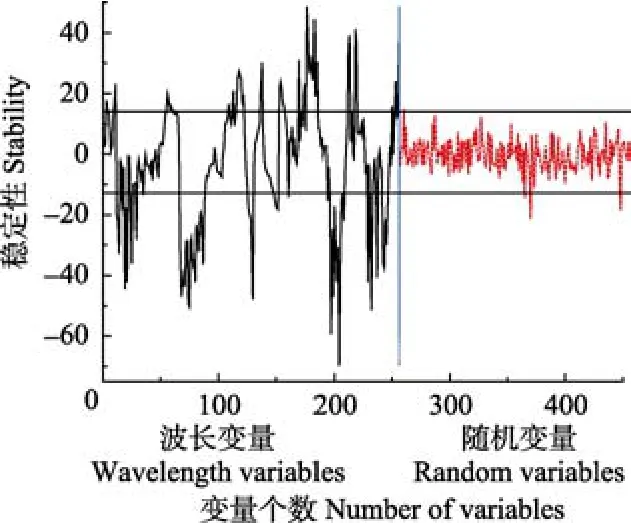
图5 UVE筛选结果Fig.5 The screening results by UVE
2.2.2 叶片高光谱数据特征变量筛选
经UVE选择后的105个变量采用GA筛选防止其过拟合现象发生。遗传算法参数设定如下:初始种群规模为30,交叉概率为0.5,变异概率为0.01,遗传迭代次数为100。以偏最小二乘的交互验证均方根误差(root mean square error of cross validation,RMSECV)看作GA的适应度函数,优选出相关性高的变量。图 6为遗传算法的优化结果。迭代 100次期间方差趋于稳定,对应交互验证均方根误差为最低时对应的变量被选为最佳变量数。此时特征变量由105个降到36个,从而尝试进一步优化模型。

式中yi,actual为第i个样品的设定值,yi,predicted为预测集交互验证过程中第i个样品的预测值;n为预测集样品数。

图6 遗传算法优化过程Fig.6 Optimization process by genetic algorithm
经UVE选择105个变量的基础上尝试SPA变量筛选,得到共线性最小的19个有效波长。运行SPA算法程序时最大、最小变量数目分别设为 50、10。筛选结果为372.03,393.55,395.94,398.33,422.25,498.76,656.58,670.93,692.45,725.93,795.27,845.49,874.18,931.57,945.92,962.66,969.83,974.61,977 nm共19个有效波长,以此作为ELM和LS-SVM模型输入变量。
2.3 定性判别分析模型
样品保存过程中有11个损坏,试验中予以剔除,包括5个轻度、2个中度、4个重度,将样品划分为轻度、中度、重度黄龙病、缺锌、正常5类,后续将这5类169个叶片按照3∶1的比例随机划分建模集和预测集,其中建模集有127个样品(包括轻、中、重黄龙病分别25、21、26个,缺锌26个,正常29个),剩余42个为预测集样品。采用[2,4,6,8,10]作为判别模型的参考值,其中2、4、6分别表示轻度、中度和重度黄龙病叶片,8表示缺锌叶片,10表示正常叶片。结合LS-SVM和ELM分别建立判别模型。两类样品的中间值作为阈值对预测样品进行分类。
2.3.1 ELM判别模型
极限学习机(ELM)是一种输入权值随机选择和输出权值估算分析的单一隐含层前馈网络,对输出权值分析,得出全局最优解,避免较多的收敛问题[29]。
为防止 ELM网络过拟合现象,在训练前结合 UVE剔除无关信息的光谱来确定ELM网络隐含层神经元的数目,权值变量j和隐含节点偏置d随机确定,训练过程中未进行调整。本文中初始化隐含层神经元数目为 10,并以10作为间隔逐渐增加至80,用分类正确率来确定最佳的隐含层神经元数目。分别将sine,sigmoidal,Hardlim3个不同的函数作为ELM隐含层神经元的激励函数进行训练,确定最佳激励函数。图7显示了3种不同激励函数下各隐含层神经元数目对ELM性能的影响[30-32]。可看出随着神经元数目的增加,分类正确率都有增长的趋势,当数目为50时,sigmoidal函数作为激励函数的ELM网络分类正确率最高达到95%。故后续的ELM模型中用sigmoidal作为激励函数,且隐含层神经元数设为50。
由于全谱输入时,变量共线性高且模型复杂。变量选择可以减少共线性,减少模型复杂度,分别以全谱、多种变量方法筛选后的变量作输入,建立 ELM 模型进行对比。

图7 三种激励函数下ELM网络分类正确率与隐含层神经元数目的关系Fig.7 Relationships between classifiction correct rate and number of hidden-layer neurons of extreme learning machine (ELM)on three incentive function
2.3.2 最小二乘支持向量机判别模型
最小二乘支持向量机(LS-SVM)是一种针对小样本的统计学方法,常用的核函数有线性函数(Link_kernel)及径向基函数(RBF_kernel)。经不同组合变量选择方法筛选后的最小二乘支持向量机模型判别结果,预测样品用来评价其预测能力,并从 Link_kernel和 RBF_kernel两个核函数出发考察LS-SVM模型的效果。Link核函数涉及的一个主要参数是γ,而RBF核函数涉及的两个主要参数是 σ2和 γ,作为评判参数来考察样品分类的误判率。γ和σ2一般采用两步搜索法确定,第一步用较大步长进行查找,确定其界限,第二步在该界限内用较小步长进行最佳参数寻找,从而得到所需参数。
用LS-SVM方法建立的判别模型与ELM模型进行对比,建模集和预测集的划分与前述一致,如表2所示。
从表2中可以看出,在隐含层神经元数目都为50的条件下,4种 ELM 模型大致上都能判别黄龙病。经UVE-SPA和UVE-GA组合筛选的ELM模型,虽误判率最低都为4.76%,预测均方根误差为0.190 5,但前者的预测相关系数高于后者为0.975 2。综合预测相关系数、误判率等几项指标看,均好于其余3种模型。故UVE-SPAELM模型更优。
用Link_kernel函数作为核函数的LS-SVM模型明显优于 RBF_kernel为核函数的 LS-SVM 模型。其中UVE-GA与UVE-SPA筛选的变量作输入时模型误判率最低为0,而全谱作为输入时误判率最高,可能是全谱数据中含有无用信息和冗余信息变量导致。图8为UVE-SPALS-SVM 和 UVE-SPA-ELM 判别模型预测结果,UVESPA-ELM 模型有 42个预测集样品中有一个轻度黄龙病误判为中度黄龙病,一个中度黄龙病误判为轻度黄龙病,误判率为4.76%。UVE-SPA-LS-SVM没有一个样品被误判,误判率为0,故效果最佳。最后用另外一批样品包括轻度黄龙病、中度黄龙病、重度黄龙病、缺锌和正常 5类,每类各10个对判别模型验证试验并进行PCR测试,其中有1轻度被误判为中度、1个中度被误判为重度,误判率符合最佳模型要求。
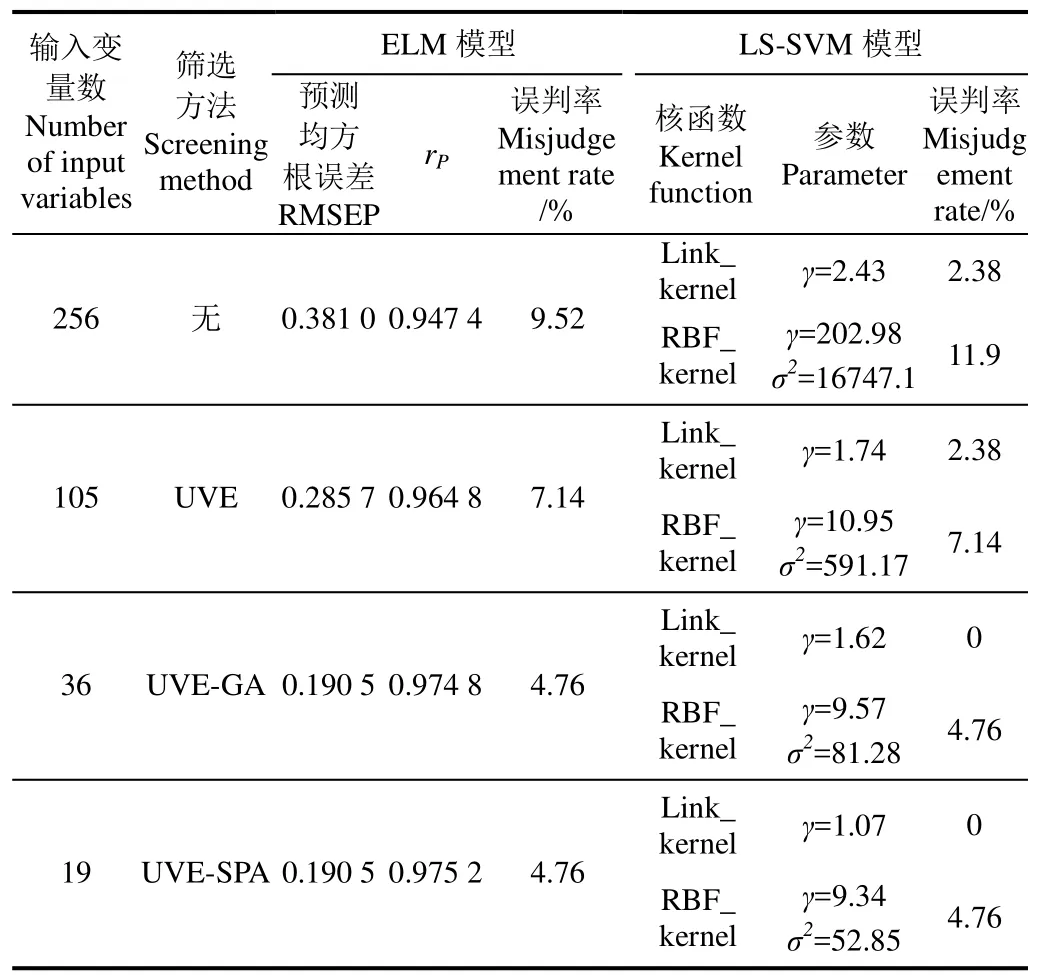
表2 不同输入变量下ELM和LS-SVM模型预测结果Table 2 Prediction results of ELM and LS-SVM model in different input variables
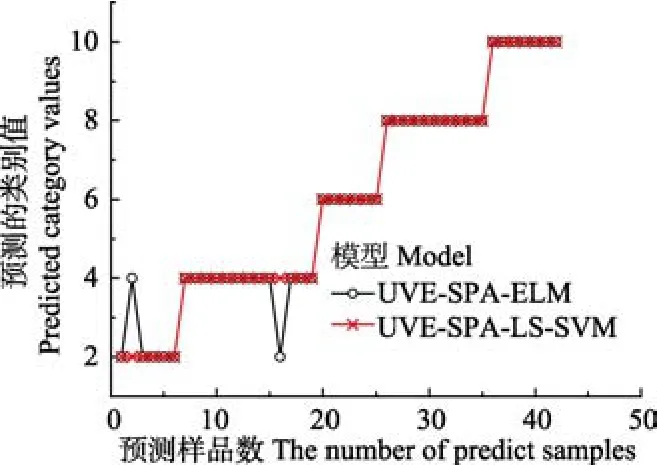
图8 ELM与LS-SVM模型预测结果Fig.8 Prediction results of ELM and LS-SVM model
2.3.3 定性判别模型对比分析
利用UVE与GA,SPA组合方法对柑桔叶片高光谱进行变量筛选,结合ELM和LS-SVM两种方法分别建立判别模型,用42个预测集样品来评价模型预测能力。
1)隐含层神经元数目为50时,采用UVE-SPA组合对光谱变量进行筛选,优化ELM模型输入变量,判别效果更优,误判率为4.76%。
2)线性函数 Link_kernel作为核函数,惩罚因子 γ最小为 1.07时,利用 UVE-SPA组合筛选变量作为LS-SVM输入的模型预测能力最好,误判率为0。
3)在输入相同的条件下,UVE-SPA-LS-SVM模型的判别效果明显优于UVE-SPA-ELM模型,且误判率更低,同时前者针对变量少的数据,具有更强的泛化能力。
3 结 论
利用不同变量筛选方法组合,对柑桔叶片高光谱特征变量进行选择,结合ELM和LS-SVM建立判别模型,对柑桔黄龙病进行分类,取得了较低的误判率。特别是经UVE-SPA变量筛选后建立的LS-SVM模型效果明显优于ELM模型,该模型的核函数为Link_kernel函数,惩罚因子(γ)最小为1.07,输入变量数19个虽不是最少,但误判率最低为0。用全谱作输入变量时LS-SVM模型复杂程度最高且预测能力最差,误判率为最高11.9%,可能是包含无用信息和冗余信息变量造成的。研究表现针对高维数据,特征变量筛选在模型优化方面表现出一定的潜力,提高分类精度同时优化模型,显示出UVE与SPA组合的变量筛选方法结合LS-SVM快速诊断柑桔黄龙病的可行性。
[1] 胡浩,殷幼平,张利平,等. 柑橘黄龙病的常规PCR及荧光定量PCR检测[J]. 中国农业科学,2006,39(12):2491-2497.Hu Hao, Yin Youping, Zhang Liping, et al. Detection of citrus Huanglongbing by conventional and two fluorescence quantitative PCR assays[J]. Scientia Agricultura Sinica, 2006,39(12): 2491-2497. (in Chinese with English abstract)
[2] Hawkins S A, Park B, Poole G H, et al. Detection of citrus Huanglongbing by Fourier transform infrared-attenuated total reflection spectroscopy[J]. Applied Spectroscopy, 2010,64(1): 100-108.
[3] 梅慧兰,邓小玲,洪添胜,等. 柑橘黄龙病高光谱早期鉴别及病情分级[J]. 农业工程学报,2014,30(9):140-148.Mei Huilan, Deng Xiaoling, Hong Tiansheng, et al. Early detection and grading of citrus huanglongbing using hyperspectral imaging technique[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014, 30(9): 140-148. (in Chinese with English abstract)
[4] 梁爽,赵庚星,朱西存. 苹果树叶片叶绿素含量高光谱估测模型研究[J]. 光谱学与光谱分析,2012,32(5):1367-1370.Liang Shuang, Zhao Gengxing, Zhu Xicun. Hyperspectral estimation models of Chlorophyll content in apple lesves[J].Spectroscopy and Spectral, 2012, 32(5): 1367-1370. (in Chinese with English abstract)
[5] 岳学军,全东平,洪添胜,等. 柑桔叶片叶绿素含量高光谱无损检测模型[J]. 农业工程学报,2015,31(1):294-303.Yue Xuejun, Quan Dongping, Hong Tiansheng, et al.Non-destructive hyperspectral measurement model 0f chlorophyll content for citrus leaves [J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(1): 294-303. (in Chinese with English abstract)
[6] 邓小玲,郑建宝,梅慧兰,等. 基于高光谱成像技术的柑橘黄龙病病情诊断及分类[J]. 西北农林科技大学学报(自然科学版),2013,41(7):99-106.Deng Xiaoling, Zheng Jianbao, Mei Huilan, et al.Identification and classification of citrus Huanglongbing disease based on hyperspectraI imaging[J]. Journal of Northwest A&F University (Natural Science Edition) , 2013,41 (7): 99-106. (in Chinese with English abstract)
[7] Sankaran Sindhuja, Ehsani Reza. Visible-near infrared spectroscopy based citrus greening detection: Evaluation of spectral feature extraction techniques[J]. Crop Protection,2011, 30 (11): 1508-1513.
[8] 吴迪,吴洪喜,蔡景波,等. 基于无信息变量消除法和连续投影算法的可见-近红外光谱技术白虾种分类方法研究[J]. 红外与毫米波学报,2009,28(6):423-427.Wu Di, Wu Hongxi, Cai Jingbo, et al. Classifying the speies of exopalaemon by using visible and near infrared spectra with uninformative variable elimination and successive projections algorithm[J]. Journal of Infrared and Millimeter Waves, 2009, 28(6): 423-427.(in Chinese with English abstract)
[9] Haiyan Cena, Lu Renfu, Zhu Qibing, et al. Nondestructive detection of chilling injury in cucumber fruit using hyperspectral imaging with feature selection and supervised classif i cation[J]. Postharvest Biology and Technology, 2015,111: 352-361.
[10] 李韬,柯冲. 应用Nested PCR技术检测柑桔木虱及其寄主九里香的柑桔黄龙病带菌率[J]. 植物保护学报,2002,29(1):31-35.Li Tao, Ke Chong. Detection of the bearing rate of Liberobacter asiaticum, in citrus psylla and its host plant Murraya panciculata by Nested PCR[J]. Acta Phytophylacica sinica, 2002, 29(1): 31-35. (in Chinese with English abstract)
[11] Hocquellet A, Toorawa P, Bove J M, et al. Detection and identification of the two Candidatus Liberobacter species associated with citrus huanglongbing by PCR amplification of ribosomal protein genes of the β operon[J]. Molecular and Cellular Probes, 1999, 13(5): 373-379.
[12] Ghaedi M Niknam, K Soylak M. Cloud Point Extraction and Flame Atomic Absorption Spectrometric Determination of Lead, Cadmium and Palladium in Some Food and Biological Samples[J]. Pakistan Journal of Analytical & Environmental Chemistry, 2011, 12(1/2): 488-496.
[13] 袁亦文,蒋自珍,王德善. 柑桔黄龙病病情分级标准探讨[J]. 浙江农业科学,2010(1):121-123.Yuan Yiwen, Jiang Zizhen, Wang Deshan. Study on classification standard of Citrus Huanglongbing disease[J].Zhenjiang Nongye Kexue, 2010, (1): 121-123. (in Chinese with English abstract)
[14] 李修华,李民赞,Won Suk Lee,等. 柑桔黄龙病的可见-近红外光谱特征[J]. 光谱学与光谱分析,2014,34(6):1553-1559.Li Xiuhua, Li Minzhan, Won Suk Lee, et al. Visible-NIR spectral feature of citrus greening disease[J]. Spectroscopy and Spectral Analysis, 2014, 34(6): 1553-1559. (in Chinese with English abstract)
[15] 李江波,饶秀勤,应义斌,等. 基于高光谱成像技术检测脐橙溃疡[J]. 农业工程学报,2010,26(8):222-231.Li Jiangbo, Rao Xiuqin, Ying Yibin, et al. Detection of navel oranges canker based on hyperspectral imaging technology[J].Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2010, 26(8): 222-231. (in Chinese with English abstract)
[16] Govindarajan Konda Naganathan, Lauren M Grimes,Jeyamkondan Subbiah, et al. Visible/near-infrared hyperspectral imaging for beef tenderness prediction[J].Computers and Electronics in Agriculture, 2008, 64(2): 225-233.
[17] 孙通,吴宜青,刘秀红,等. 激光诱导击穿光谱联合UVE变量优选检测大豆油中的铬含量[J]. 光谱学与光谱分析,2016,36(10):3341-3345.Sun Tong, Wu Yiqing, Liu Xiuhong, et al. Detection of chromium content in soybean oil by laser induced breakdown spectroscopy and UVE method[J]. Spectroscopy and Spectral Analysis, 2016, 36(10): 3341-3345. (in Chinese with English abstract)
[18] 李倩倩,田旷达,李祖红,等. 无信息变量消除法变量筛选优化烟草中总氮和总糖的定量模型[J]. 分析化学,2013,41(6):917-921.Li Qianqian, Tian Kuangda, Li Zuhong, et al. Model of total nitrogen and total sugar in tobacco optimizing after uninformative variable elimination[J]. Chinese Journal of Analytical Chemistry, 2013, 41(6): 917-921. (in Chinese with English abstract)
[19] 于雷,洪永胜,周勇,等. 高光谱估算土壤有机质含量的波长变量筛选方法[J]. 农业工程学报,2016,32(13):95-102.Yu Lei, Hong Yongsheng, Zhou Yong, et al. Wavelength variable selection methods for estimation of soil organic matter content using hyperspectral technique[J]. Transactions of the Chinese Society of Agricultural Engineering(Transactions of the CSAE), 2016, 32(13): 95-102. (in Chinese with English abstract)
[20] 简葳玙,徐祖华,祝铃钰,等. MC-UVE-GA-PLS算法用于精馏软测量辅助变量选择[J]. 计算机与应用化学,2015,32(11):1343-1346 Jian Weiyu, Xu Zuhua, Zhu Lingyu, et al. Secondary variable selection in distillation column soft sensor using MC-UVE-GA-PLS algorithm[J]. Computers and Applied Chemistry, 2015, 32(11): 1343-1346. (in Chinese with English abstract)
[21] Zheng Wenbin, Fu Xiaping, Ying Yibin. Spectroscopy-based food classification with extreme learning machine[J].Chemometrics and Intelligent Laboratory Systems, 2014, 139:42-47.
[22] 刘思伽,田有文,张芳,等. 采用二次连续投影法和 BP人工神经网络的寒富苹果病害高光谱图像无损检测[J].食品科学,2017,38(8):277-282.Liu Sijia, Tian Youwen, Zhang Fang, et al. Hyperspectral imaging for nondestructive detection of hanfu apple diseases using successive projections algorithm and BP neural network[J]. Food Science, 2017, 38(8): 277-282. (in Chinese with English abstract)
[23] 孙丽萍,张冬妍. 基于分层信息融合的木材干燥过程含水率在线检测[J]. 农业工程学报, 2013, 29(1): 257-263.Sun Liping, Zhang Dongyan. Online testing of lumber drying moisture based on layered information fusion[J]. Transactions of the Chinese Society of Agricultural Engineering(Transactions of the CSAE), 2013, 29(1): 257-263. (in Chinese with English abstract)
[24] 林孔湘. 柑桔黄龙病问题的讨论[J]. 柑桔科技通讯,1977,(z2):28-38.Lin Kongxiang. Discussion on the problem of citrus greening[J]. Citrus Technology Communication, 1977, (z2):28-38. (in Chinese with English abstract)
[25] 王爱民,邓晓玲. 柑桔黄龙病诊断技术研究进展[J]. 广东农业科学,2008,10(6):101-103.Wang Aimin, Deng Xiaoling. The research on the diagnosis technology of Citrus Huanglongbing[J]. Guangdong Agricultural Sciences, 2008, 10(6): 101-103. (in Chinese with English abstract)
[26] Stewart I, Leonard C D. The cause of yellow tipping in citrus leaves[J]. Proceedings of the Florida State Horticultural Society, 1952, 65: 25-27.
[27] Stone M L, Solie J B, Raun W R, et al. Use of spectral radiance for correcting in-season fertilizer nitrogen deficiencies in winter wheat[J]. Transactions of the ASAE,1996, 39: 1623-1631.
[28] Sundaram J, Kandala C V, Butts C L. Application of near infrared spectroscopy to peanut grading and quality analysis:Overview[J]. Sensing & Instrumentation for Food Quality &Safety, 2009, 3(3): 156-164.
[29] Leardi R, González A L. Genetic algorithms applied to feature selection in PLS regression: How and when to use them[J]. Chemometrics and Intelligent Laboratory Systems,1998, 41(2): 195-207.
[30] 张海东,李贵荣,李若诚,等. 近红外光谱结合极限学习机和GA-PLS算法检测普洱茶茶多酚含量[J]. 激光与光电子学进展,2013,50(4):180-186.Zhang Haidong, Li Guirong, Li Ruocheng, et al.Determination of tea polyphenols content in puerh tea using near-infrared spectroscopy combined with extreme learning machine and GA-PLS algorithm[J]. Laser & Optoelectronics Progress, 2013, 50(4): 180-186. (in Chinese with English abstract)
[31] 郭文川,王铭海,谷静思,等. 近红外光谱结合极限学习机识别贮藏期的损伤猕猴桃[J]. 光学精密工程,2013,21(10):2720-2727.Guo Wenchuan, Wang Minghai, Gu Jingsi, et al.Identification of bruised kiwifruits during storage by near infrared spectroscopy and extreme learing machine[J]. Optics and Precision Engineering, 2013, 21(10): 2720-2727. (in Chinese with English abstract)
[32] 孙俊,卫爱国,毛罕平,等. 基于高光谱图像及 ELM 的生菜叶片氮素水平定性分析[J]. 农业机械学报,2014,45(7):272-277.Sun Jun, Wei Aiguo, Mao Hanping, et al. Discrimination of lettuce leaves’ nitrogen status based on Hyperspectral imaging technology and ELM[J]. Transactions of the Chinese Society for Agricultural Machinery, 2014, 45(7): 272-277..(in Chinese with English abstract)
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
文苑(2018年22期)2018-11-15
现代园艺(2018年1期)2018-03-15
现代园艺(2018年3期)2018-02-10
现代园艺(2018年3期)2018-02-10
现代园艺(2018年3期)2018-02-10
家庭科学·新健康(2017年10期)2017-10-26
南方农业·下旬(2016年8期)2017-02-23
陕西画报(2016年1期)2016-12-01
