
FM集成模型在广告点击率预估中的应用
2018-02-27 03:06张青川于重重谢小兰
计算机应用与软件 2018年1期
潘 博 张青川 于重重 谢小兰
(北京工商大学计算机与信息工程学院 北京 100048)
0 引 言
随着广告计费方式的改变,广告点击率CTR(Click-through Rate)估计在广告投放过程中占有越来越重要的地位。在预测效果的评价标准中,AUC (Area Under Curve)为ROC(Receiver Operating Characteristics)曲线下的面积,可以反映分类器的平均性能,并对不同的ROC曲线进行比较,比起ROC曲线更能反映分类器效果。因此AUC值适合作为CTR 预估模型的评价标准,一个完美分类器的AUC为1.0,而随机猜测的AUC为0.5。
随着机器学习技术的发展,这一技术被逐渐采用到广告点击率预估中。基于机器学习的CTR预估方法一般可以分为三种:线性机器学习模型、非线性机器学习模型,以及融合模型。线性机器学习模型具有简单易实现、易扩展、易在线更新的特点,可以处理超大规模的数据,因此在产业界应用较为广泛。文献[1]首次将CTR预估问题由概率估计问题转成回归问题。该文提出用逻辑回归LR(Logistic Regression)来解决CTR预估问题,将具体广告、环境抽象成特征,用特征来达到泛化的目的,从而对广告点击率进行预测。文献[2]提出了基于L-BFGS的OWLQN(Orthant Wise Limitedmemory Quasi Newton)优化算法,解决了逻辑回归损失函数在L1正则化非连续可导的问题。这个方法的优点在于:这是一种Batch Learning的方法,可以收敛到全局最优解,且收敛速度快;损失函数中使用了L1正则化,避免过拟合的同时输出稀疏模型。
线性机器学习模型虽然简单易扩展,但是表达能力有限,不能学习特征间的非线性关系,即使构造出复杂特征+轻量模型的形式也不一定对线性模型有效,而且费时费力。因此非线性模型也被研究用来预估广告CTR,形成简单特征+复杂模型的形式。文献[3]首次提出使用点击日志计算搜索结果的点击率,结合搜索引擎查询日志和用户点击日志,自动优化搜索引擎的检索质量。通过分析用户在当前返回的排序结果中点击链接的日志,使用支持向量机算法最大化Kendall相关系数,从而达到排序结果接近最佳排序的目的。文献[4]提出了一种在线贝叶斯概率回归模型OBPR(Online Bayesian Probability Regression)用于在搜索广告情景下对广告CTR进行预测。
为了进一步提高点击率预估的效果,近些年来融合模型也得到了一些尝试。文献[5]针对Facebook的社交广告点击率预估研究,提出了迭代决策树算法GBDT(Gradient Boost Decision Tree)+LR的融合模型。该方法结合了GBDT非线性模型能拟合非线性特征的特点,以及LR线性模型具有很好的扩展性以及模型训练速度快的特点,融合之后的AUC比GBDT和LR单模型均高出3%。文献[6]提出了人工神经网络+决策树(ANN+MatrixNet)融合模型。ANN用来拟合ID类离散特征,输出点击概率。MatrixNet为Yandex公司版本的GBDT,用来拟合连续特征和ANN模型输出的特征。该融合模型有效地融合了CTR预估中的分类特征和连续特征,实验效果比LR、MatrixNet和ANN单模型要好。
广告数据呈现的高维稀疏性和特征之间存在着高度非线性关联的特点,虽然上述融合模型能同时具有非线性模型与线性模型的优点,但是MatrixNet、GBDT和LR等模型仍然无法有效学习特征间的非线性关系,所以对于高维稀疏、类别不平衡的广告数据无法建立准确的CTR预估模型。本文将针对已有的数据量大、高维稀疏、类别不平衡的广告数据集,重点研究FM集成模型以使广告点击率预估具有更高的效率和更好的模型精度。
1 FM集成模型原理
1.1 问题描述
本文研究的广告点击率预估问题可以描述为:输入一个用户查询和其他信息(如性别、年龄、地域、兴趣爱好等),经过点击率预估系统计算输出每一则广告的点击概率,即广告的预估点击率。图1中的黄色模块描述了一个广告点击率预估系统的构建流程。

图1 点击率预估系统工作流程
针对高维稀疏、类别不平衡的广告数据建立广告点击率预估模型是本文研究重点。本文利用因子分解机FM(Factorization Machine)模型自动拟合特征间的交互,处理高维稀疏问题;同时提出了FM集成模型,解决了分类不均衡问题。本文结合文献[7]中GBDT的高层特征提取方法形成GBDT+FM融合模型,利用大数据处理平台Hadoop的分布式系统对该模型进行并行式训练,减少模型对海量广告数据的训练时间。
1.2 集成学习概述
集成学习用多重或多个弱分类器结合为一个强分类器,从而达到提升分类效果的目的。文献[8]对解决不均衡问题的集成模型进行了分类,集成学习主要是基于Bagging[9]和Boosting[10]两种基本思想。Bagging通过自举汇聚原始训练集来训练不同的分类器。也就是从原始数据集随机采样N次得到N个数据集,通常这N个数据集和原始数据集保持同样的大小,从而通过重采样过程获得数据多样性。N个数据集建好后,将某种学习算法分别作用于每个数据集,得到N个分类器。当对新数据进行分类时,应用这N个分类器进行分类,选择分类器投票结果中最多的类别为最后的分类结果。
Boosting与 Bagging 很类似,使用的多个分类器的类型都是一样的。但是在Boosting中,不同的分类器是通过串行训练获得,每个新分类器都根据已训练出的分类器的性能进行训练,通过集中关注被已有分类器错分的那些数据来获得新的分类器。Boosting分类的最终结果是根据所有基分类器的权重加权求和得到的,该权重代表的是分类器在上一轮迭代中的成功度。AdaBoost算法[14]已成为目前最流行的Boosting算法,该算法的效率与Freund改进算法很接近,却可以非常容易地应用到实际问题中。
本文数据集中的未被点击的广告数(反例数目)比被点击的广告数(正例数目)多出25倍,显然属于非均衡分类问题。为了解决非均衡分类问题,本文采用多重数据抽样方法,构造基于数据集多重抽样的集成分类器,同时采用了AUC作为模型评价指标。
1.3 FM集成模型
FM是由Steffen Rendle[11-12]提出的一种基于矩阵分解的机器学习算法。其最大的特点是对于稀疏的数据具有很好的学习能力。本文涉及广告CTR预估,其数据同样具有高维稀疏的特点,因此采用FM模型作为基分类器,结合了Bagging和Boosting的集成思想进行集成学习。由于本文中广告原始数据集正负比例相差较大,类别分布不均衡。为了使输入到单个分类器的样本均衡,本文将正负样本分开存储,分别进行采样。其中正例可全采样或过采样,负例样本欠采样,得到的N个数据集进行转换后分别输入FM模型进行单独训练,每个FM单模型会有自己的输出和模型AUC指标。各个模型的输出通过自身AUC加权求和形成最终的FM集成分类器,其算法流程图见图2。
一般Bagging所用的基分类器为不稳定算法,如决策树,集成才会有较大的效果。此处稍微不同于Bagging思想的地方在于,一方面为了达到样本类别均衡,另一方面尽量不丢失原始数据模式。FM模型为稳定算法,此处集成是为了拟合不同分桶中的负例样本。通常广告数据量很大,对N个数据集进行串行式训练会消耗大量时间。针对这个问题,本文基于大数据平台Hadoop中的MapReduce离线计算框架进行并行化训练,从而提高效率,其模型见图3。

图3 FM集成算法的并行化训练模型图
负样本是基于Hive分桶采样的,如将负样本分为N桶,将第1桶负列样本和正例样本混合作为训练集1,将第2桶负列样本和正例样本混合作为训练集2,以此类推,将第N桶负列样本和正例样本混合作为训练集N。分桶的大小需要经过实验来确定。通过Map对每个数据集同时进行单独训练出对应FM模型,然后通过Reduce对各个模型的输出通过自身AUC加权求和,形成最终的FM集成分类器。该模型既实现了Bagging和Boosting的集成思想的结合,又降低了训练时间成本,从而实现了精度与效率的双赢。
2 广告点击率预估模型实验
2.1 实验数据集与实验环境介绍
本文采用3个实验数据集:① 腾讯多媒体展示广告数据集。② SIGKDD Cup2012 track2[15]提供的广告点击日志数据。③ 国内最大的定向广告联盟——百度联盟的点击日志。三个数据集包含会话日志、用户信息、广告信息三方面内容。
本文采用文献[7]中基于GBDT 特征提取方法,不仅能提升模型的效果,而且可以减少特征工程的成本和时间,因此可利用该算法分别提取出其中的ID类特征与GBDT类特征(高层特征)。针对类标签信息,从三个数据集中抽出相同数量训练集、测试集,信息如表1所示。

表1 训练集、测试集类标签信息
实验平台为基于Hadoop的大数据处理平台,用到的组件包括HDFS分布式文件系统、MapReduce离线计算框架、YARN分布式资源管理系统、Hive分布式数据仓库和Spark的MLlib机器学习算法库。实验中集群规模为1个Master节点,3个Slave节点,集群网络拓扑信息如图4所示。
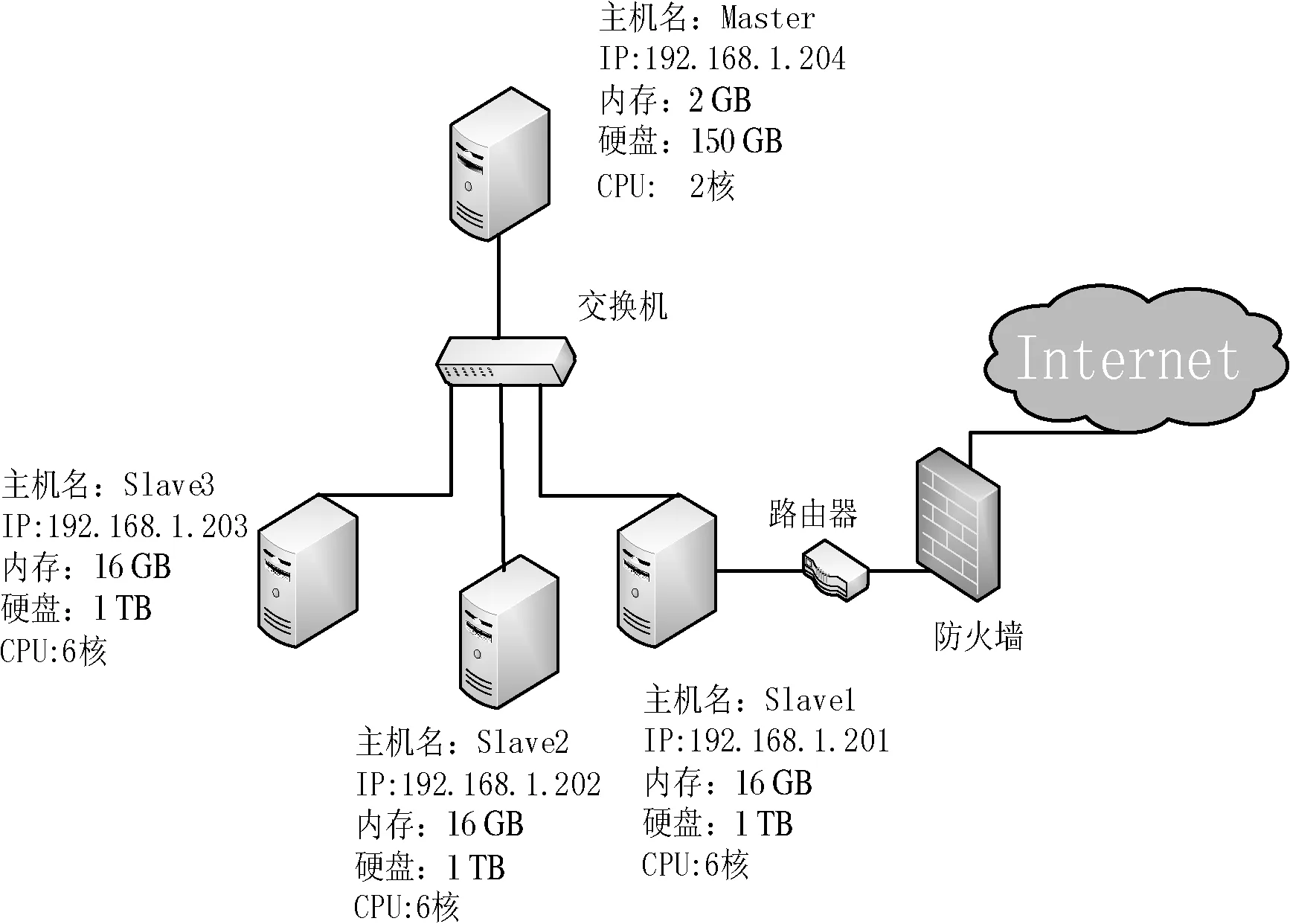
图4 集群网络拓扑
2.2 实验总体框架
实验总体框架如图5所示。
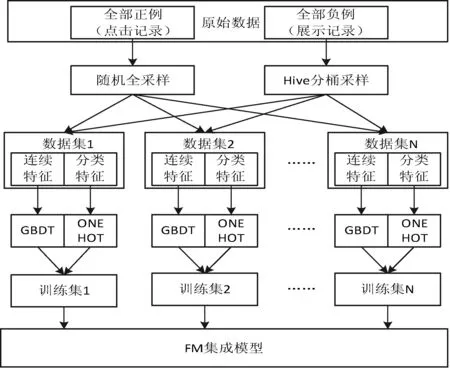
图5 FM集成模型实验总体框架
原始数据按正例(点击记录)和负例(展示记录)分别存放到不同的表。对于正例进行随机全采样,即采样样本的数据量等于原始正例的数量;对负例进行分桶采样,第1桶与正例样本组成数据集1,第2桶与正例样本组成数据集2,以此类推,第N桶与正例样本组成数据集N。采样得到的各个数据集由连续特征和分类特征组成,对于连续特征训练GBDT模型提取高层二值特征向量;对于分类特征进行ONE HOT独热编码,形成高维稀疏特征。将两种特征组合在一起形成最终的N个训练集。这些训练集用来学习最终的FM集成模型。
2.3 实验过程
2.3.1 单模型实验
本文采用的三个广告数据集均为稀疏数据。本文利用GBDT 模型的多维特征提取方法提取出的高层特征,并联合独热编码后的 ID 类特征一起输入到 CTR 预估模型。为了验证FM模型比LR模型能更好处理高维稀疏数据,对两者进行了对比实验。实验结果如表2所示。
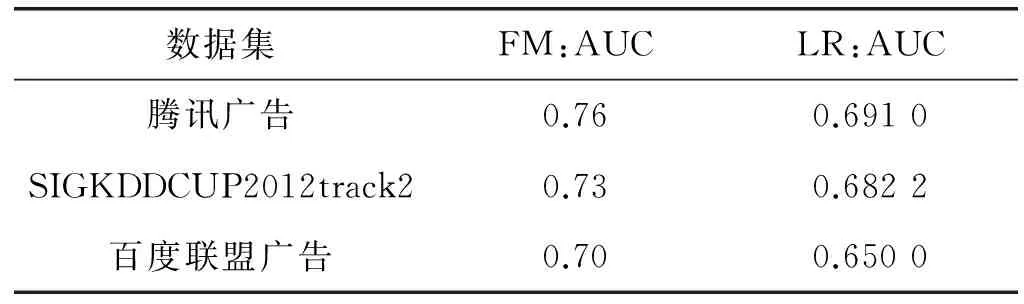
表2 FM与LR在三个数据集上的AUC
由表可以看出,FM模型在三个稀疏数据集都表现出比LR模型更好的预估性能。FM 因子分解机基于因子分解,能拟合特征之间的相关性,可以有效地滤除高维稀疏数据中的“噪声”,提取出权重较高的特征。
2.3.2 采样实验
当训练数据类别分布极度不平衡时,严重影响模型的预测精度。因此在本文中,当负样本多余正样本两个数据量级时,需采取合理的采样策略使训练样本尽量平衡且不丢失有效信息。本文实验了在三个数据集上的多种正负样本比例时FM模型的效果,AUC取平均值,结果如图6所示。
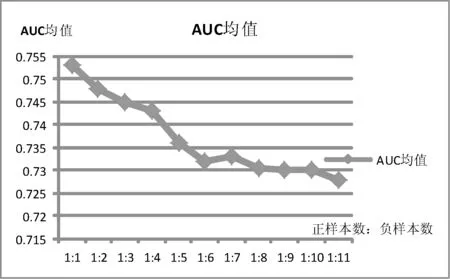
图6 不同正负样本比例下FM模型的AUC指标
由图6可见,AUC随负样本的比重增多呈现出下降的趋势。当正负比例1∶1时AUC最大,为0.752 4。除了以上的正负比之外,本实验也测试了全量数据下(正负比为1∶25)FM模型效果,其AUC值为0.605 4。当对正样本重采样,负样本欠采样(正负比分别为2∶2,2∶3,2∶4)时,AUC停留在0.5左右,即模型没有预测效果。故本文将采用正负样本采样比为1∶1的数据集进行单模型训练。
2.3.3 模型集成实验
对于不均衡分类问题,必须经过采样使训练样本尽量平衡。但采样之后的数据有可能丢失大量的有效信息,即便确定了合理的采样比例,还是会有信息的丢失,所以提出了FM集成模型,将分桶采样后的数据分别输入FM单模型训练,然后将单模型输出按AUC加权求和,得到最终的FM集成模型输出。实验的输入数据为ID类特征,同2.3.2节一样在三个数据集上取AUC均值为实验结果,如图7所示。其中横坐标1代表只有一个单模型,2代表第一个单模型与第二个单模型集成,3代表第三个单模型与前两个模型集成,依次类推,25代表第25个单模型与前面24个单模型集成。
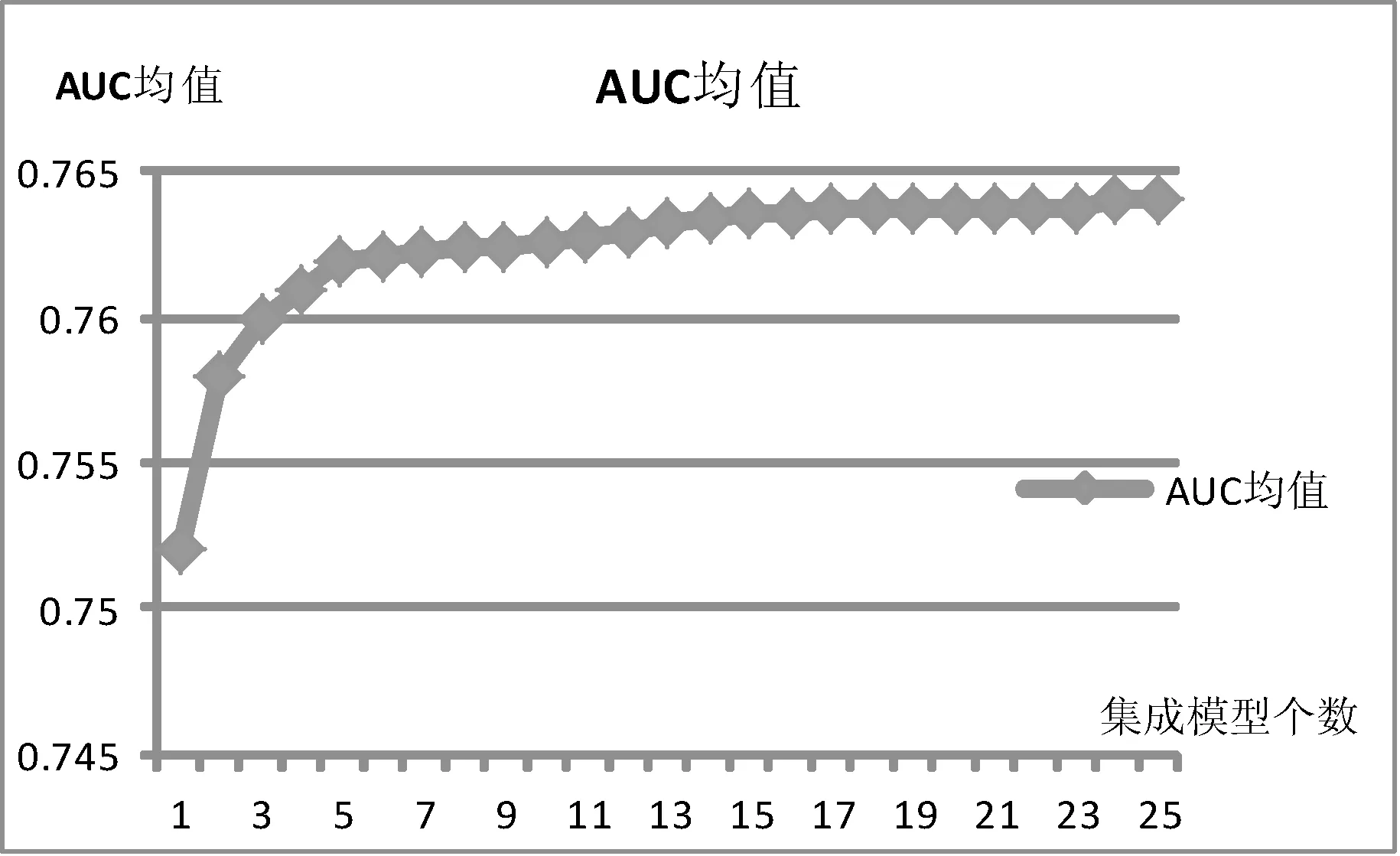
图7 FM集成模型指标与集成模型个数关系图
由图7可知,前5个模型累计集成的时候变化较大,后面随着单模型的加入AUC仍然在上升,但上升相对缓慢。FM集成模型的AUC比FM单模型AUC提高0.01以上,效果较明显。
2.3.4 模型对比验证
实验将ID类特征和GBDT类特征输入分别输入到LR模型、FM模型和FM集成模型进行AUC比较,进一步验证FM模型对于其他输入特征的有效性。采用的训练数据条数为1 511 992条,正负样本比为1∶1。与文献[7] 相同,ID类特征通过独热编码后的维数为3 963 094维,连续类特征通过训练好的GBDT模型后得到的高层特征维数为3 840(27×30)维。实验结果如表3所示。

表3 FM模型与FM集成模型对比实验结果
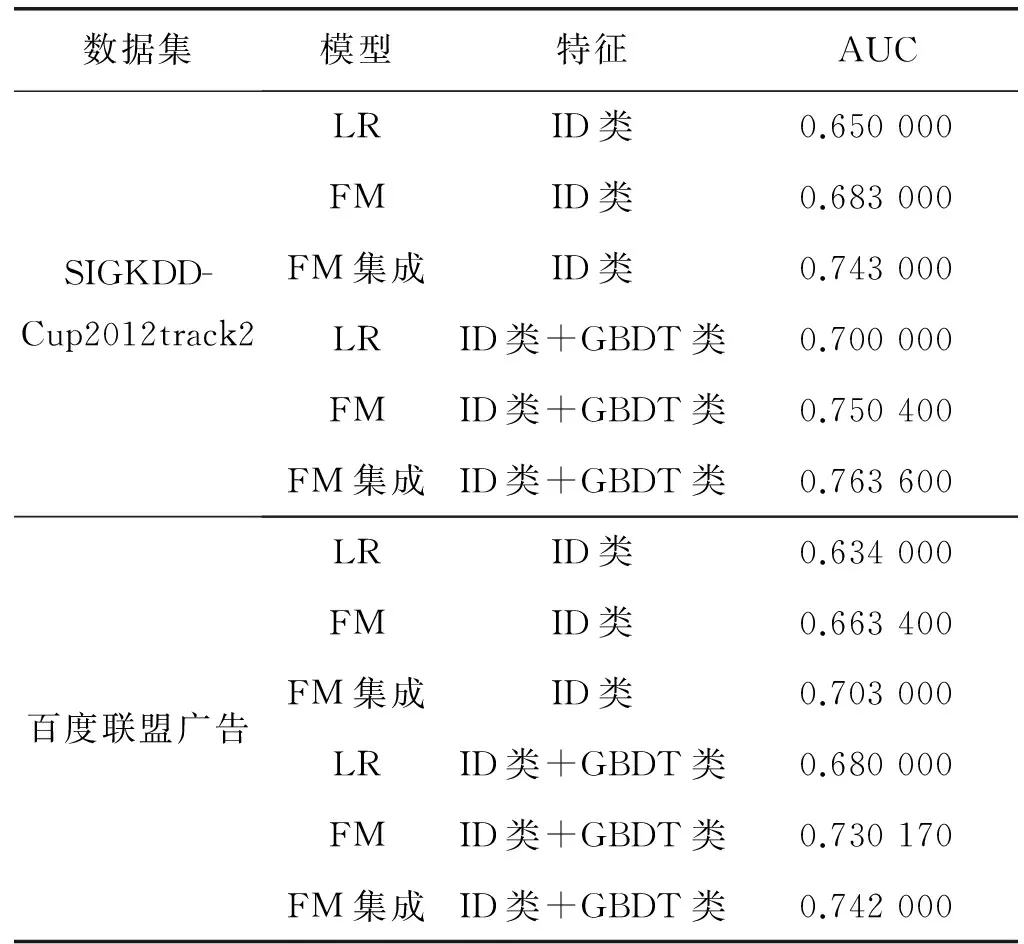
续表3
由表3可知,在三个数据集上,无论输入的是ID类特征还是ID类特征+GBDT类特征,FM集成模型AUC指标均为最高,比FM模型高0.01以上,比LR模型高出0.07以上;LR模型的AUC最低,其表达能力有限,不能学习特征间的非线性关系。显然,相比其他模型,FM集成模型具有更好学习能力。
3 结 语
本文首先对集成学习进行了概述,涉及到解决不均衡问题的集成模型的分类,介绍了Bagging和Boosting两种基本思想;然后提出了本文的FM集成模型架构;最后通过采样实验、模型集成实验、模型对比验证,实验验证了FM集成模型的有效性。
类别不平衡问题在互联网广告点击率预估当中是常见问题,本文提出了FM集成模型,结合GBDT高层特征提取方法,形成GBDT+FM的融合模型,并用Hadoop实现了并行化。该模型在减少建模人工成本和时间成本的同时,也能有效提高精度。
[1] McMahan H B, Holt G, Sculley D, et al. Ad click prediction: a view from the trenches[C]//Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2013: 1222-1230.
[2] Shan L, Lin L, Sun C, et al. Predicting ad click-through rates via feature-based fully coupled interaction tensor factorization [J]. Electronic Commerce Research and Applications, 2016, 16:30-42.
[3] Agarwal D, Agrawal R, Khanna R, et al. Estimating rates of rare events with multiple hierarchies through scalable log-linear models[C]//Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010: 213-222.
[4] Dembczynski K, Kotlowski W, Weiss D. Predicting ads click-through rate with decision rules[C]//Workshop on targeting and ranking in online advertising, WWW’08. 2008.
[5] Shen S, Hu B, Chen W, et al. Personalized click model through collaborative filtering[C]//Proceedings of the fifth ACM international conference on Web search and data mining. ACM, 2012:323-332.
[6] Agarwal D, Chen B C, Elango P. Spatio-temporal models for estimating click-through rate[C]//Proceedings of the 18th international conference on World wide web. ACM, 2009:21-30.
[7] 田嫦丽, 张珣, 潘博,等. 互联网广告点击率预估模型中特征提取方法的研究与实现[J]. 计算机应用研究, 2017, 34(2):334-338.
[8] Galar M, Fernandez A, Barrenechea E, et al. A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches[J]. Systems, Man, and Cybernetics, Part C: Applications and Reviews, IEEE Transactions on, 2012, 42(4):463-484.
[10] Rok Blagus, Lara Lusa. Gradient boosting for high-dimensional prediction of rare events[J]. Computational Statistics and Data Analysis,2016.
[11] Rendle S. Factorization machines[C]//Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 2010: 995-1000.
[12] Rendle S. Social network and click-through prediction with factorization machines[C]//KDD-Cup Workshop,2012.
[13] Richardson M, Dominowska E, Ragno R. Predicting clicks: estimating the click-through rate for new ads[C]//Proceedings of the 16th international conference on World Wide Web. ACM, 2007:521-530.
[14] Pouria Ramzi, Farhad Samadzadegan, Peter Reinartz. An AdaBoost Ensemble Classifier System for Classifying Hyperspectral Data[J]. Photogrammetrie, Fernerkundung, Geoinformation, 2014(1):27-39.
[15] SIGKDD12 Cup[OL]. http://www.kddcup2012.org/c/kddcup2012-track2.
猜你喜欢
矿山安全信息(2022年22期)2022-11-24
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
电子技术与软件工程(2017年14期)2017-09-08
电子制作(2017年24期)2017-02-02
海峡姐妹(2015年8期)2015-02-27
海外英语(2013年3期)2013-08-27
