
基于改进VGG卷积神经网络的前方车辆目标检测
2018-02-25 12:30黄妙华
数字制造科学 2018年4期
陈 毅,黄妙华,胡 胜
(1.武汉理工大学 现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070;2.武汉理工大学 汽车零部件技术湖北省协同创新中心,湖北 武汉 430070)
前方车辆目标检测指从道路场景中识别出车辆目标,是智能驾驶领域中的重要组成部分。近几年,国内外对前方车辆目标检测做了较多研究,在提高检测精度问题上的关注重点有两个方面,一是特征选择和提取;二是检测算法的优化。目前在特征选择上主要有车底阴影特征[1-3]、车辆对称性特征[4-5]、车辆边缘特征[6-7]等车辆外观特征以及HOG(histogram of oriented gradient)特征[8-9]、LBP(local binary patterns)特征[10]、Haar-like特征[11-12]、SIFT(scale-invariant feature transform)特征[13-14]等统计学特征。目前典型的车辆检测算法有SVM(support vector machine)算法、Adaboost算法和神经网络算法等,但是均存在检测精度低等缺点。
随着深度学习理论和实践迅速发展,基于机器学习的目标检测和分类进入了一个新的阶段。2013年R-CNN作为深度学习目标检测应用领域的先驱,创新地将传统机器学习和深度学习结合起来,提出选择性搜索(selective search)等经典算法,在VOC2007测试集的平均准确率被提升至48%;2014年时通过修改网络结构提高到66%。继而出现了像Fast R-CNN[15]、Faster R-CNN[16]、Mask R-CNN[17]、YOLO[18]和fast YOLO[19]等目标检测网络的优化。其中Fast R-CNN、Faster R-CNN存在计算量大,训练及测试速度慢等问题,YOLO、fast YOLO则存在目标定位精度差,训练时间长等问题。
为解决上述问题,笔者在传统的检测方法基础上进行改进,运用改进后的VGG(visual geometry groups)深度卷积神经网络训练车辆分类器。首先,通过图像滤波算法抑制图像噪声;然后运用改进的二次自适应阈值分割算法,并通过两次形态学处理后,获取车辆底部阴影区,进而得到车辆假设区域;最后通过预先运用VGG深度卷积神经网络训练好的车辆分类器对假设区域进行分类识别,最终得到车辆的具体位置。改进后的算法在提高车辆目标检测精度的前提下,提高检测效率。
设计的车辆目标检测系统框架如图1所示。其主要分为3个阶段:图像预处理、提取车辆假设区域和验证车辆假设区域。
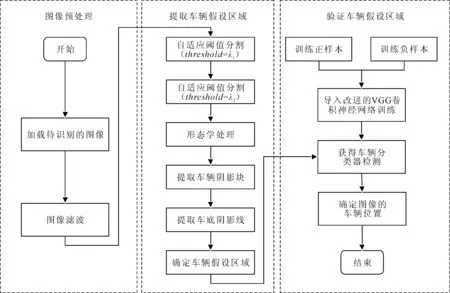
图1 车辆目标检测系统框架
1 车底阴影假设区域提取
目前车底阴影区域提取方法主要采用阈值分割法,文献[1]采用图像均值和方差差值作为分割阈值,能较好地分割出里面和其他非感兴趣目标,但不能有效抑制大面积阴影干扰;文献[2]在此基础上提出了二次自适应阈值分割法,有效提高了分割效果,但是其计算过程复杂,计算量大,降低了车辆目标识别效率;为确保车底阴影区尽可能保留,降低漏检率,提高检测精度,笔者采用两次自适应阈值分割法,首先从原始图像中提取感兴趣区ROI(region of interest),即图2中上下线之间区域,并根据式(1)和式(2)计算ROI中像素点均值和方差。
(1)
(2)
式中:μ为ROI的像素均值;σ为ROI的像素方差;M、N分别为灰度图像的高度和宽度;f(m,n)为灰度图像中(m,n)处的图像灰度值。
第一次自适应阈值分割的阈值如式(3)所示,其目的是消除高亮像素点的干扰,然后统计ROI中低于threshold1的所有像素点的灰度值,并按照式(1)计算其均值。第二次自适应阈值分割的阈值如式(4)所示。图像阈值分割效果如图3所示,从图3可看出采用的二次自适应阈值分割法能有效抑制环境噪声干扰,分割道路上的车辆目标,以便于后续准确提取车辆底部阴影线。
(3)
threshold2=μ2
(4)
式中:μ1为第一次自适应阈值分割ROI的像素点的灰度均值;μ2为第二次自适应阈值分割ROI中低于threshold1的像素点灰度均值。

图2 原始图像

图3 本文图像阈值分割效果
经过上述阈值分割后,仍然会有部分小面积区域会影响后续的车底阴影线的提取,为了消除其干扰,采用两次形态学处理,第一次采用5×5的矩形核进行腐蚀操作,消除小面积破损区域,第二次采用7×7矩形核进行膨胀操作,进一步分割道路与车辆,便于后续提取车底阴影线,图4为形态学处理效果。
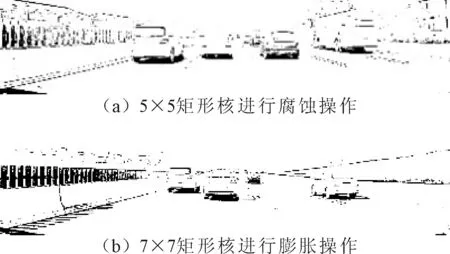
图4 形态学处理效果
经过上述操作可以看出,处理结果中初步包含了所有车辆目标的阴影区,提取车底阴影线的具体步骤如下:①从上至下、从左至右依次遍历每个像素点,当满足式(5)时,记f(x,y)为阴影线起点,当满足式(6)时,记f(x,y)为终点;②当确定了阴影线的起始点时,将纵向跨度小于10行,并且横向重合度大于80%的阴影先合并为一条阴影线,即为所要提取的车辆目标阴影线。
f(x,y-1)-f(x,y)=
255&f(x,y+1)-f(x,y)=0
(5)
f(x,y-1)-f(x,y)=
0&f(x,y+1)-f(x,y)=255
(6)
2 基于改进VGG深度卷积神经网络的车辆目标检测验证
由于现实道路环境受到光照、建筑物、树木等影响较大,因此仅凭借车底阴影作为车辆目标检测的唯一标准会产生大量误检结果,因此需要对基于车底阴影产生的假设区域进行验证,以减少误检率,提高检测精度。深度卷积神经网络相比传统的机器学习算法具有提取包含目标本质的隐形特征能力,从而省去了手工提取特征的步骤,具有易扩展和高鲁棒性的特点。笔者采用VGG深度卷积神经网络算法对产生的假设区域进行验证。
2.1 样本集制作
针对智能驾驶汽车,前方车辆为主要检测目标,因此为进一步提高检测精度,所选的训练正样本集主要为车辆尾部图像。目前,常用的车辆检测数据集有MIT-CBCL车辆数据集(516幅128×128的ppm格式图像)、UA-DETRAC车辆数据集(8 250个车辆目标)等,但是这些数据集正样本数量较小,并且正样本中车辆的姿态多样,因此需要制作特殊的训练正样本集。制作的正样本集主要由两部分组成:汽车之家官网车辆尾部图像和公开车辆数据集,共计9 497幅图像,将其分为7 314张训练集图像和2 183幅测试集图像,部分正样本如图5所示。针对道路环境特点,负样本集主要包括行人、道路、树木、房屋和天空等。负样本集共计19 306幅图像,将其分为15 852幅训练集图像和3 454幅测试集图像,部分负样本如图6所示。为了进一步加快后续神经网络的训练和测试速度,将正负样本集归一化为64×64大小的图像。

图5 部分正样本图像

图6 部分负样本图像
2.2 网络结构设计
采用的网络结构基于由Simonyan和Zisserman在2014年提出的VGG网络[20],其结构如图7所示。该网络结构共有13个卷积层,每个卷积层的卷积核大小均为3×3,卷积步长为1,卷积核个数从最初的64依次增长到128、256以及512。池化层卷积核大小为2×2,步长为2。但是其网络模型的参数太多,在训练过程中需要保存权值和偏置以及部分中间结果,这些数据将储存在有限的GPU上,会给GPU带来巨大负担,并且影响训练和测试速度。因此如何减少VGG网络结构参数成为提高训练测试效率的关键技术。
通过研究VGG网络结构发现,训练参数主要产生于全连接层中,其中FC-4096共有4 096个节点,其参数占总参数的70%,为减少VGG网络训练参数,将原始的VGG网络结构进行优化,去掉一层全连接层FC-4096,其余保持原VGG网络结构不变,此优化方式不仅减少了训练参数,提高了训练效率,同时也提高了检测精度。

图7 VGG卷积神经网络结构图
2.3 网络训练
在网络训练开始时,随机初始化参数进行训练,训练过程分为两个阶段:前向传播计算和反向传播计算。前向传播可用式(7)进行计算。
xl=f(ul) withul=wxl-1+b
(7)
式中:f(ul)为激励函数;xl为当前层的输出;ul为当前层的输入;w,b分别为上一层的权重和偏置。
采用RelU激励函数,其相较于Sigmoid函数和tanh函数具有快速计算和快速收敛的优点,计算公式为ReLU=max(0,x)。
反向传播的核心是计算损失函数值,目前常用的损失函数有平方误差函数,交叉熵等。笔者采用平方误差函数作为损失函数,如式(8)所示,然后用式(9)作为车辆检测结果的评价指标。
(8)
式中:C为样本个数;n为训练次数;t为训练样本的正确结果;y为网络训练的输出结果。
(9)
式中:TP为正样本测试结果为正的个数;FP为负样本测试结果为正的个数;TN为正样本测试结果为负的个数;FN为负样本测试结果为负的个数。
3 试验结果分析
训练测试硬件环境为:处理器为Intel(R) Core(TM)i7-6800K;内存为8 G;显卡采用GeForce GTX1060 3 GB。软件环境为:操作系统为Windows 7 旗舰版;编程工具采用Python3.5和TensorFlow深度学习框架。训练测试参数为:迭代步数为10 000;初始学习率为0.001。通过分别运用常规6层卷积神经网络、经典VGG16卷积神经网络以及改进的VGG16卷积神经网络对上述数据集进行训练测试。最终得到测试集损失函数值变化如图8所示,从图8中可以看出3种卷积神经网络的损失函数值均下降很快,说明3种卷积神经网络均能较快地学习车辆目标特征,最终改进的VGG16卷积神经网络结构得到的损失函数值最小,说明其能更好地学习车辆目标特征。测试集准确率变化如图9所示,从图9中可以看出采用改进的VGG16卷积神经网络结构在测试集上的准确率最高,最终测试集准确率如表1所示。

图8 测试集损失函数值变化图

图9 测试集准确率变化图

卷积神经网络结构名称测试集准确率6层卷积神经网络61.27%VGG16卷积神经网络88.53%改进的VGG16卷积神经网络91.95%
运用训练结果对实际图像进行测试得到测试结果如图10和图11所示。

图10 图2(a)的测试结果图

图11 图2(b)的测试结果图
从图10和图11可以看出,改进的VGG卷积神经网络结构拥有更好的检测能力,最终能获得较好的检测效果。
4 结论
针对目前前方车辆目标检测准确率较低的问题,提出了优化的检测方法,首先通过双阈值分割提取出车底阴影特征,获取车辆目标假设区域,然后运用改进的VGG卷积神经网络进行训练车辆分类器,并对车辆目标假设区域验证。在测试集上进行测试的结果表明,该方法获得较高的检测准确率,并在实际图像检测中取得良好的检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
文苑(2020年11期)2020-11-19
电子制作(2019年13期)2020-01-14
中国诗歌(2019年6期)2019-11-15
制造技术与机床(2019年9期)2019-09-10
电子制作(2019年11期)2019-07-04
西南交通大学学报(2018年6期)2018-12-18
北京航空航天大学学报(2018年1期)2018-04-20
河北遥感(2017年2期)2017-08-07
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
