
基于SSM框架的数据采集系统的设计与实现
2018-02-24 13:55周少波
电脑知识与技术 2018年34期
关键词:爬虫
周少波
摘要:随着大数据技术的迅速发展以及智能手机的普及,其应用已渗入到人类社会的各个领域并发挥越来越重要的作用。本系统基于SSM框架的数据采集系统,前台采用的是SpringBoot框架和JSP技术进行开发,后台采用HtmlUnit框架进行爬虫业务的开发,采用MySQL 数据库及MongoDB进行数据的存储和支撑,开发模式采用的是B/S模式的Web应用程序。实现了数据抓取配置,数据提取配置,数据抓取,数据excel表格下载,关键字管理,登录,修改密码,退出系统等功能。在设计上具有友好的交互界面,系统用户可以在管理界面上对后台进行爬虫配置。系统用户在配置成功后,开启爬虫,即可不再受任何时间限制地进行数据抓取了。
关键词:爬虫;SpringBoot;数据抓取;MongoDB;B/S
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)34-0045-03
1引言
随着大数据技术的发展与其日益完善,很多传统企业的运作都开始加入了大数据技术,使企业能在发展市场上走在其他同行企业的前面。但是,要使用大数据技术,首先要有足量大的数据作为支撑才有意义,因而,数据采集就必然是其最基础,最重要的部分。因此,生产一个高效稳定的数据采集系统迫在眉睫。目前,爬虫技术采集数据成为数据采集方式的有力补充和发展。爬虫技术采集数据不仅减少了对数据采集的人力、物力的投入,并且突破了时间与空间的限制,不仅节省了资源,而且提高了数据采集的效率和准确度。总之,大数据技术在各行业的普及,爬虫数据采集技术必将得到发展,其关注度一定会逐渐增加。为生产一个高效稳定的数据抓取系统,作者经过研究几种不同的爬虫制作方案,经充分的考虑,最后给出了一个较为理想的爬虫制作方案,并结合当前部署和维护方便及其扩展性较好的B/S架构来开发一个高效稳定的数据抓取系统。基于B/S模式的数据采集系统完美地克服了人工采集方式所带来的人力、物力以及时间上的浪费,同时也保证了数据的产出速率和准确率。
2 需求分析
本系统需要技术人员才能进行操作,且系统定位为企业内部使用系统,所以并没有需要对用户类型进行过于严格的分类管理,因此用户类型仅需有系统管理员和数据采集员两类。
系统管理员需求:系统管理员可管理数据采集员账户、修改密码、登录系统、管理爬虫规则、查看爬虫数据、下载爬虫数据、启动/停止爬虫、解析数据、开启定时器、关键字管理、退出系统等功能。
1)登录:因为这个系统目前设定为企业内部系统,而非商业性系统,因此无须开放注册功能。系统管理员的账户密码在系统部署时在数据库进行预设。所有用户在登录时,系统校验用户名和密码,正确则放行,错误则弹出提示信息。
2)修改密码:可以修改个人密码和数据采集员密码。
3)管理数据采集员账户:系统管理员可以对数据采集员账户进行添加、删除、修改。
4)管理爬虫规则:管理员可以像数据采集员一样,对爬虫规则进行添加、和配置删除。
5)查看爬虫数据:查看当前爬虫产生的原数据和提取数据。
6)下载爬虫数据:爬虫数据成功提取后,可以导出为excel文档。
7)启动/关闭爬虫:手动开启/关闭指定的爬虫规则,自动功能开启后禁用。
8)解析数据:立即提取数据
9)开启定时器:开启后,使用预设的定时时间,定时对爬虫规则进行定时的进行数据抓取和数据提取(一般网站都是白天的访问量最高,晚上最低,所以可以预设时间为晚上抓取数据,白天提取数据。这样可以充分利用爬虫系统的网络带宽)。
10)关键字管理:本数据采集系统的爬虫功能将制成三种爬虫工作模式,第一种是默认的常规逐层爬虫。第二种是搜索模式,通过将关键字输入到网站搜索栏,然后进行搜索,例如对百度搜索结果进行爬虫。第三种是URL拼接模式,按照RestFul的一个URL代表一个资源的概念,一般网站的URL都是设计得有规律的,URL拼接模式就是通过关键字拼接起来作为URL进行请求爬虫。关键字管理功能就是对关键字进行导入和删除。
11)退出系统功能:退出系统
数据采集员需求:数据采集员可修改密码、登录系统、管理爬虫规则、查看爬虫数据、下载爬虫数据、启动/停止爬虫、解析数据、关键字管理、退出系统等功能。
① 登录:因为这个系统目前设定为企业内部系统,而非商业性系统,因此无须开放注册功能。系统管理员的账户密码在系统部署时在数据库进行预设。所有用户在登录时,系统校验用户名和密码,正確则放行,错误则弹出提示信息。
② 修改密码:可以修改个人密码。
③ 管理爬虫规则:对爬虫规则进行添加、和配置删除。
④ 查看爬虫数据:查看当前爬虫产生的原数据和提取数据。
⑤ 下载爬虫数据:爬虫数据成功提取后,可以导出为excel文档。
⑥ 启动/关闭爬虫:手动开启/关闭指定的爬虫规则,自动功能开启后禁用。
⑦ 解析数据:立即提取数据。
⑧ 关键字管理:本数据采集系统的爬虫功能将制成三种爬虫工作模式,第一种是默认的常规逐层爬虫。第二种是搜索模式,通过将关键字输入到网站搜索栏,然后进行搜索,例如对百度搜索结果进行爬虫。第三种是URL拼接模式,按照RestFul的一个URL代表一个资源的概念,一般网站的URL都是设计得有规律的,URL拼接模式就是通过关键字拼接起来作为URL进行请求爬虫。关键字管理功能就是对关键字进行导入和删除。
⑨ 退出系统功能:退出系统。
3系统设计
3.1功能模块划分
3.1.1 前台的主要功能模块
根据需求分析,明白了本系统分为前台和后台两个部分进行设计。前台主要用于登录系统、管理爬虫规则、管理关键字、密码修改、数据导出、退出系统等功能。后台主要用于系统管理员对数据采集员的账户管理,系统设置,等功能。
本系统前台可划分为三大功能模块,具体为:
1)系统操作模块:包括登录、密码修改和退出系统功能。
2)爬虫管理模块:包括配置爬虫规则、管理关键字功能。
3)数据管理模块:包括启动数据抓取、启动数据解析和数据导出功能。
3.1.2 后台的主要功能模块
本系统后台可划分为两大功能模块,具体为:
1)用户管理模块:包括建新的用户、修改信息、修改用户密码和删除用户等功能。
2)查询模块:主要是查看用户操作日志功能。
3.2 数据库设计
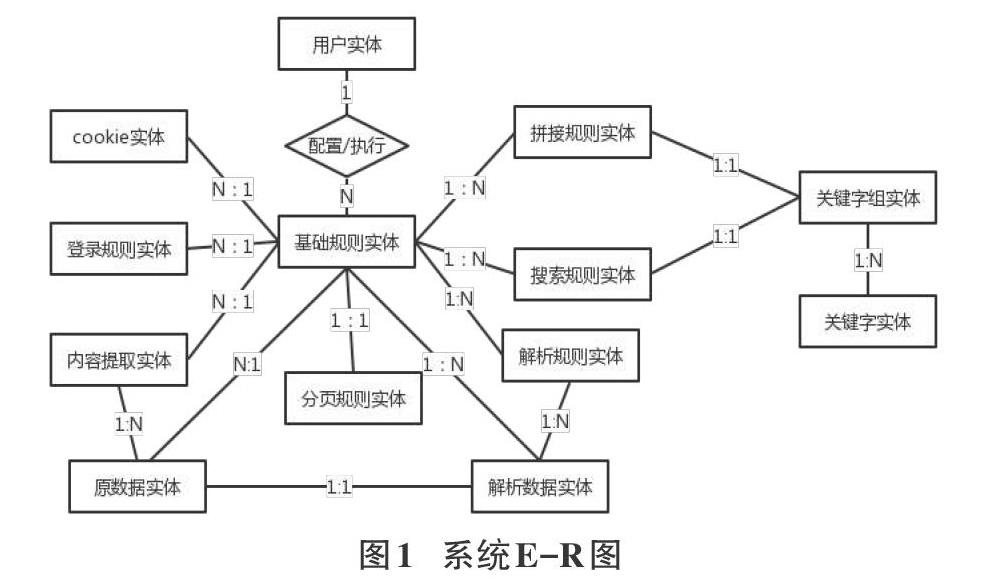
3.2.1 系统E-R图
经过分析,本系统主要有十三个实体,分别是用户、基础规则实体、登录规则实体、cookie实体、内容提取规则实体、分页规则实体、拼接规则实体、搜索规则实体、关键字组实体、关键字实体、原数据实体、解析数据实体。系统E-R图如图1所示:
3.2.2 数据库表设计
1)用户表结构:用户表-tuser用来存储用户信息,用于实现用户信息的增、删、改、查。在登录时,会使用登录信息与表内信息进行匹配,以验证登录。为确保安全,验证前,用户的密码会进行一次MD5加密再和用户表的密码进行比对。
2)爬虫基础规则表结构:爬虫基础规则表-tcrawler_rule用来存储爬虫配置的基本规则,用户标识一个爬虫配置信息的最基本配置。该表记录了目标网站的网站名,域名,爬虫运行模式,网站首页,网站过滤字段,默认模式用到的层级,进行爬虫前是否需要登录网站,当前一共有多少原数据,多少提取数据,当前运行状态等信息。
3)登录配置表结构:登录配置表-taccount_msg用来存储网站登录配置信息的,有些网站在浏览某些数据时,可能需要处于登录状态才能浏览。那么配置如何登录这些网站,显然是必须的。该表就是记录如登录页面的URL,登录相关标签的标签,标签唯一属性名,标签的唯一属性值,和标签的类型。之所以只设置一套用于查找的标签的配置,是因为一般登录的输入框和提交按钮都给了id作为唯一标识,为了简化配置,这里就只给出一套配置。
4)cookie信息表结构:Cookie信息表-tcookie_msg用来存储Cookie信息。有些的登录可能会比较复杂,,简单的配置可能无法满足,因此这里提供了Cookie配置来冒充登录,目前大部分网站为了方便用户,都会将Sessionid写入Cookie,让用户重新进入网站时免登录,这样我们就可以利用这一点,将这些可以登录网站的Cookie记下来,让爬虫系统去浏览这些网站时带上Cookie,就可以实现免登录了。
5)搜索信息表结构:搜索信息表-tsearch_msg用来存储搜索信息。有时候,我们的需求不是从某个网站逐层查找数据,而是获取某个网页的搜索结果,因此需要配置一个规则,来让爬虫“知道”如何进行搜索。配置信息有,搜索页的Url,搜索的标签,标签名称,标签属性名,标签属性值,填充关键字组的组id,标签的作用类型(是提交按钮还是输入框)。
6)拼接信息表结构:拼接信息表-tconcat_msg用来存储拼接信息。现在很多网站已经用上Restful风格的Url,来强调一个Uri代表一个资源的HtmlGet请求的原定义。因此我们可以以Url中的某一段或多段多为关键字拼接点,拼接出Url来请求我们需要的志愿。拼接信息表的记录包括拼接位置,拼接用的单字串,拼接用的关键字组Id(单字串优先级高于关键字组)。
7)内容提取配置信息表结构:内容提取配置信息表-tcontent_index_rule用来存储内容提取配置信息。用于记录爬虫直接挖去用于进行解析数据的Html部分,相当于在浏览器中查找进行OuterHtml操作的Domcument标签,因为目标可能在不同网页层,也可能在同层有多个的关系,因此最复杂的配置会呈一个多叉树森林的结构,因此与其他配置的属性相比,多了是否深入查找的标识,还有上层节点id(处于首层的节点ID为0)。
8)分页配置信息表结构:分页配置信息表-tpaging_index用来存储分页配置信息。有些时候,用户要的数据不止目标第一页,而是所有分页。因此我们需要提供下一页的获取按钮配置提供给用户。这些信息包括父标签配置,目标标签配置,标签倒数位置(因为有时候下一页的按钮没有被做严格的属性区分,因此需要这个来提高获取目标的准确度)。
9)解析规则配置信息表结构:解析规则配置信息表-textract_content_rule用來存储解析规则配置信息。内容提取规则拿到的数据是带Html代码的粗糙数据,不可直接使用的。因此,需要提供解析规则来将数据与Html代码分离,并设置在导出时的排列规则。
10)关键字组信息表结构:关键字组信息表-tkeyword_group用来存储关键字分组信息。这个表用于存放用于搜索模式和拼接模式所用到的关键字组的信息。
11)关键字信息表结构:关键字信息表-tkeyword用来存储关键字信息。这个表用于存放用于搜索模式和拼接模式所用到的关键字组所包含的关键字。
12)原数据集合结构:原数据集合-SourceDataBean用来存储爬虫原数据的Mongo集合。原数据集合就是用于存放原数据的,在uuid相等的情况下,判断多个原数据集合构成一条完整的数据。
13)解析数据集合结构:解析数据集合-ExtractDataBean用来存储爬虫解析数据的Mongo集合。解析数据集合就是用于存放数据的。其中的Map为<Integer,String>结构,Key值为数据的导出位置,Value为字段具体值。
4 系统功能实现
4.1 系统前台功能实现
4.1.1 管理员登录及数据采集员创建
系统部署时,会预先创建一个管理员账户。登录功能是通过Spring Boot的拦截器实现的。当用户请求网站时,拦截器会获取Request对象来获取Session对象,取SessionId去Redis查找是否存在用户信息,存在则放行,不存在则跳转到登录页面。登录验证成功后,系统会以SessionId为Key,用户信息为Value存入Redis中。管理员可在登录后浏览系统。
4.1.2 修改密码实现
已经成功登录的用户可点击导航栏右上角的修改密码按钮打开修改密码界面。修改密码时,系统会先取得页面数据进入数据库进行校验,通过则允许修改密码。输入原密码时会与原密码进行校验,并会对新密码的长度和重复密码进行校验。
4.1.3 关键字管理实现
用户成功登录系统后可进行关键字管理,关键字管理的实现步骤如下:
1)点击导航栏的关键字管理,打开关键字组列表。
2)点击导入,弹出导入界面。
3)输入组名并选择好上传文件后,上传组名和文件选择会有非空校验,点击确定即可上传文件。在导入成功创建数据后,用户可以选中条目点击确定按钮进行删除,也可以单独点击条目的删除按钮进行删除。
4)导入成功后,点击组名,可以查询里面的详细关键字,其中点击添加可以单独添加一个数字,也可以点击条目的修改按钮进行修改。用户可以选中条目点击确定按钮进行删除,也可以单独点击条目的删除按钮进行删除。
4.1.4 爬虫规则管理实现
爬虫规则会存储在Mysql数据库中,实现规则查询功能,当用户查询规则时,把存储在数据库中该用户添加的规则的基础规则列到前台显示。此外,用户还可以选中规则,进行修改,删除,查看原数据,查看提取数据。
4.1.5 添加爬虫规则实现
用户可以为自己添加爬虫规则。添加规则的第一步是点击爬虫规则列表的添加按钮打开基础规则添加页面,这里由于爬虫分三个模式,而三个模式的第一步,第二步配置均不同,因此这里会取三个例子进行配置。 基本规则添加完成并保存后,进入第二步添加抓取规则。通过第一步配置的工作模式,使用JSTL对第二步的页面进行渲染。这一环,我们主要配置数据抓取的位置规则,这里的配置,我们必须确保准确。此外,本数据采集系统的爬虫功能还支持搜索模式和Url拼接模式,它們三者之间的提取规则有少许不同,这里将展示搜索模式和Url拼接模式下的配置界面。第三步,添加数据提取(解析)规则。用于将爬虫根据前面配置的规则抓出来的。添加数据提取(解析)规则完成后,系统将会跳转到配置完成页面,并于10秒后自动返回爬虫配置列表页面。
4.2 系统后台功能实现
4.2.1 用户管理实现
系统管理员账号在这本数据采集系统内有权控制所有用户。管理员根据用户名和密码登录系统。登录后,主界面导航会比数据采集员多出一个设置导航。这一点通过JSTL实现,通过获取用户类型,判断是否渲染设置中心模块。管理员将鼠标移动到设置导航上会出现下拉菜单,其中一个就是账户管理,点击该菜单即可进入账户管理界面。在这里,管理员可以进行与所有用户相关的,包括创建新的用户,修改信息,修改用户密码,删除用户。
4.2.2 操作日志实现
系统管理员账号在这本数据采集系统内有权查看所有用户的操作记录。管理员根据用户名和密码登录系统。登录后点击设置中心下拉菜单中的操作日志即可查看所有用户的操作日志。用户在请求时,系统会通过反射机制,获取传入参数和预设的操作类型,将参数和类型按预设的规则进行拼接后,存入操作记录表,就能实现操作日志。
4.2.3 爬虫自动启动实现
系统管理员登录本数据采集系统后,点击数据采集进入爬虫规则列表页面会多出一个更改自动启动状态的按钮。系统部署前,使用Quartz任务调度框架设定一个定时执行爬虫的任务,并在任务前加上一个Boolean型的静态变量进行判断。自动启动按钮就是通过修改这个静态变量的值来实现开启、关闭自动启动功能的。
5 结论
本系统基于SSM框架的数据采集系统,前台采用的是SpringBoot框架和JSP技术进行开发,后台采用HtmlUnit框架进行爬虫业务的开发,采用MySQL 数据库及MongoDB进行数据的存储和支撑,开发模式采用的是B/S模式的Web应用程序。实现了功能需求里面拟定的功能,各项功能都可以正常运行。
参考文献:
[1] 于娟,刘强.主题网络爬虫研究综述[J].计算机工程与科学,2015,37(2):231-237.
[2] 李朝奎,杨武,殷智慧,等.MongoDB的遥感影像分布式存储策略研究[J].测绘通报,2014(5):70-72.
[3] 张树新,吴海斌,蒙辉,汤麦伦.基于SpringCloud的航运EDI平台IT生态环境设计[J]. 中国储运, 2018(2):100-103.
[4] 朱亚兴,余爱民.王夷.基于Redis+MySQL+MongoDB存储架构应用[J].微型机与应用,2014,33(13):3-5.
[5] 肖毅,张林,聂笑一.基于WEB挖掘的网络爬虫设计与实现[J].计算机系统应用,2013(9):60-63.
[6] 王芳,陈海建.深入解析Web主题爬虫的关键性原理[J].微型电脑应用,2011(7):76-78.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
网络安全和信息化(2020年5期)2020-12-29
计算机与数字工程(2020年10期)2020-12-07
数码设计(2019年5期)2019-12-20
计算机与网络(2018年10期)2018-06-14
电脑知识与技术·经验技巧(2018年1期)2018-05-30
电子测试(2018年1期)2018-04-18
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
