
生成式对抗网络的图像域转换
2018-02-13 06:38:14白猛猛赵亚欣
西安工业大学学报 2018年6期
赵 莉,白猛猛,赵亚欣,肖 锋
(西安工业大学 计算机科学与工程学院,西安 710021)
图像域转换是计算机视觉里一个重要的新研究方向,具有广阔的应用前景,如卫星遥感影像图像转换电子地图图像,残缺图像转换补全后完整图像等领域.以往的图像域转换基于人工设计的方式进行,包含颜色空间域转换,小波变换等操作.这些域转换算法需进行大量人工优化参数才能满足特定任务的需要.现今随着深度学习的发展,生成式对抗网络(Generative Adversarial Networks,GAN)被提出用来学习特定目标数据类型的数据分布规律,从而生成新的目标数据类型中的数据.
GAN是深度学习发展的一个新的分支,是基于博弈论的一种深度学习网络.GAN包含两类网络一种是含有反卷积层的生成式网络用于生产数据,另一类为起鉴别作用的鉴别器网络,同生成网络产生博弈.2014年文献[1]首次提出GAN,此时的GAN通过对其输入一个随机噪音信号,可随机生成不同目标类型数据的样本,此时的GAN只用于学习目标数据类型的数据分布.在原始的GAN上通过改进鉴别网络[2]产生的Conditional GAN能够根据输入带有限制条件的信号生成特定的目标类型数据,如文献[3]可根据输入的条件不一样产生不同角度的带有窗户的室内图像,文献[4]可根据输入的描述性文字经处理后输入GAN产生与文字描述相对应的图像等.Conditional GAN的产生为图像域的转换成带来了新的解决思路,即将原始域的图像作为输入GAN的条件信号,目标域的图像作为GAN产生的对象.基于该思路的图像域转换,如文献[5]利用文献[6]设计的生成网络结合真假鉴别网络,对输入的人脸图像实现了卡通风格的转换,并且为无监督的训练方式;文献[7]利用U-net[8]以及配对鉴别网络实现了多种应用的图像域转换,然而其训练方式变成了有监督的训练方式;文献[9]基于原始图像转换到目标域图像再转换回原始图像的训练思路,在多种评价指标略差于pix2pix网络的情况下实现了网络的无监督训练.
图像域转换问题是将一副图像从一个域转换到另一个域,对于该问题可利用GAN先对输入的原始域图像进行处理,再根据目标域图像产生的内部规律生成与之对应的图像.为了使图像域转换后的结果更加真实,深入分析以上文献的优缺点,文中拟针对图像域转换特点提出新的生成网络、鉴别网络和损失函数,使生成网络能够更好的学习到目标域图像数据的分布,提高图像域转换的准确率.
1 图像域转换网络结构
GAN网络由生成网络和鉴别网络两类网络组成[10-11],文中的设计的网络亦遵循该基本原则,如图1所示.Input source为输入的原始域图像,Output为生成的目标域图像,Target为真实的目标域图像.F-net和G-net是U-net中的两部分,前者包含大量的卷积操作用于提取输入图像的高维特征,后者则含有大量的反卷积操作用于生成图像.Pair-net用于判断输入的原始域图像与生成的目标域图像是否一致,并且同G-net产生博弈产生Pair-loss损失用于更新G-net.图1中出现的2处F-net为共享权重相同结构的网络,由于原始域和目标域图像表现形式不同但拥有本质的共同特征,对原始域图像以及生成的目标域图像输入F-net产生的特征图,利用多层特征图之间的F-loss损失可用于更新G-net确保其生成的目标域图像是对应原始域图像.

图1 网络结构图
文中设计的GAN的整体损失函数如下:
(1)
式中:LGAN为网络整体损失函数;α为设置的参数,在最小化LG生成网络损失函数时需要最大化配对鉴别网络LPair的损失,即使生成的图像尽量骗过配对鉴别网络,又由于LG中包含LPair故在训练的过程中需不断的训练Pair-net使其鉴别原始域图像与生成的目标域图像的能力等到提升,使得两个网络交替更新权重相互博弈最终使得彼此的能力都得到提升.式1中LPair损失部分如下:
LPair=Ex,y∈Pdata(x,y)[logPair(x,y)]+
Ex∈Pdata(x,y)[log(1-Pair(x,G(x)))]
(2)
式中:Pdata(x,y)为配对的数据集;x为原始域图像;y为真实的目标域图像;Pair(x,y)输入x原始域图像和其配对的真实目标域图像y输出是否配对的预测值;G(x)为输入x原始域图像输出生成的目标域图像.该部分损失函数基于交叉熵损失函数改写,输出的值越大表示输入的目标域图像越是真实.式(1)中LG损失函数部分具体如下:
LG=Lpair+aLf1+bLf2+cLf3+dL1
(3)
式中:Lpair为式2中的损失函数;a,b,c,d为参数,L1为真实目标域图像与G生成的目标域图像的正则项,公式为
L1=Ey∈Pdata(x,y)(‖y-G(x))‖1)
(4)
对于Lf1、Lf2和Lf3其损失的计算同Lf*一致,如下:
Lf*=Ex∈Pdata(x,y)(d(f*(x)
f*(G(x))))
(5)
其中d( )采用平均平方差(Mean Squared Error,MSE)计算输入数据的损失.Lf1、Lf2和Lf3之间的不同在于f*(x)所选F-net提取的不同层次的图像高维特征.
2 网络的训练
文中设计的网络进行的是SVHN到MNIST数据集图像域转换,输入的是SVHN数据集输出其对应的MNIST数据集,SVHN和MNIST数据集均为0~9数字,前者是各种街道门牌号数字后者是手写数字.文中将U-net拆分成F-net和G-net如图1所示,在网络训练阶段单独提取F-net部分并在其之后添加softmax层令该层的输出为0~9,将带有0~9标签的SVHN数据集输入F-net进行有监督的训练,保存F-net网络部分的权重.共享F-net的权重到生成网络中,即F-net的初始权重为在SVHN数据集上已训练的权重,G-net为随即初始化权重,Pair-net亦为随即初始化权重.在进行本文设计的GAN训练时,采用一次训练生成网络多次训练配对鉴别网络的方式进行.
2.1 F-net的初始化训练
U-net的结构如图2所示,文中将U-net划分为F-net和G-net两部分网络.图2中F-net的每层由卷积层、Bacth Normalization层以及ReLU激活层组成,第一层输入的为32*32*3的SVHN数据,输出的特征图大小为16*16数量为64张,采用的卷积核大小为3*3,F-net之后的每层结构均采用该设计,最后一层的卷积核大小为4*4.图2中G-net输入的数据张量为1*1*512,前三层包括反卷积层、Bacth Normalization层和ReLU激活层,且第一层的反卷积层的卷积核大小为4*4其余为3*3,最后一层网络将ReLU激活层换成tanh激活层用于输出生成的32*32*1数据类型的MNIST图像.
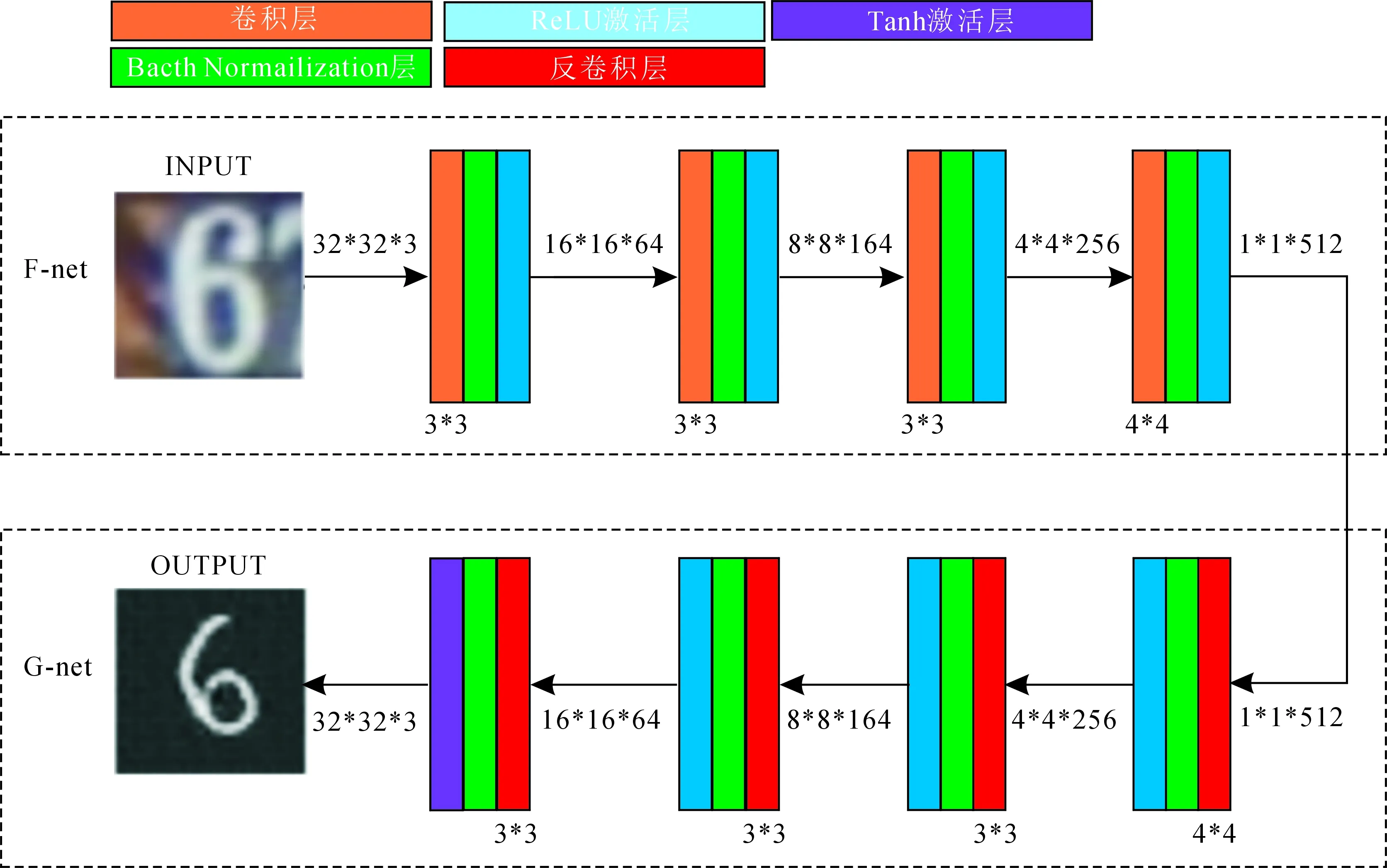
图2 生成网络结构图
数据在GAN网路训练开始时需对于F-net进行预训练,提取出F-net进行修改后的网络如图3所示.图3中在原有的F-net基础上增加了softmax层输出为预测的0~9数值.F-net的预训练输入的是带有0~9标签的SVHN数据集且每个样本的像素为32*32,在训练阶段使用的损失函数为交叉熵损失函数,如下:

(6)
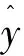
G-net主要由反卷积组成用于数据生成,学习的是训练数据集的数据分布,根据F-net提取的图像高维特征生成目标数据.F-net的预训练主要是为了更好的获取原数据集的语义特征,以使得G-net能够更好的学习数据转化中目标数据的分布.而G-net的训练依赖对抗网络pair-net,即在对抗训练的过程中G-net网络才能有效学习数据的分布,因此,无需对G-net进行预训练.
2.2 Pair-net的训练
Pair-net的结构如图4所示,网络的输入为INPUT1和INPUT2,其中INPUT1为32*32*3的SVHN数据集的图像,INPUT2输入的为32*32*1的MNIST数据集图像或者由生成网络生成的MNIST数据集图像.Pair-net的输出为0~1之间的数值反映两幅图像配对的程度,输出值为1时表示图像为完全真实的配对,0表示图像完全不配对.Pair-net的第一层网络为Concat层用于合并输入的图像数据生成32*32*4的张量,之后的三层网络采用3*3大小的卷积核,且每层包含Bacth Normalization层和ReLU层,最后一层将ReLU层置换成Sigmoid层并且卷积核大小改为4*4.Pair-net训练时将SVHN数据集及与其数字对应的MNIST数据集作为完全真实配对的正样本,将SVHN数据集以及由生成网络产生的与其对应数字的图像作为负样本,Pair-net的损失函数如式2所示.对于损失函数的优化采用adam方法,Pair-net的初始化同F-net一样采用哈维尔初始化.
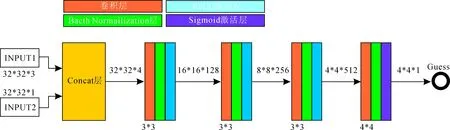
图4 Pair-net结构图
2.3 生成网络的训练
生成网络包含F-net和G-ne两部分,训练过程如图5所示.其中,F-net部分权重的初始化采用在SVHN数据集已训练的权重,G-net含有反卷积层权重采用随机初始化方法.输入SVHN数据集经F-net提取高维特征,再经过G-net生成目标域图像,将生成的图像再次输入F-net提取其特征,采用用均值平方差的方法获得两个F-net的2,3,4特征图之间的Lf*损失.G-net产生的MNIST数据输入同其输入的SVHN数据一起输入Pair-net,产生LPair配对损失.生成的MNIST数据同真实对应的MNIST数据,使用式4计算其L1损失.结合以上损失采用adam的方式进行损失函数的优化,更新G-net网络的权重.
鉴别网络pairnet产生的损失pair_loss作用有:
① 确保输入的数据与转换后的数据在语义上一一对应;② 确保转换后的数据能符合目标数据的分部.
f1_loss,f2_loo,f3_loss的作用有:
① 在网络训练的初期,弥补鉴别网络不能有效返回gnet学习损失的问题;② 对损失函数起到正则化的作用,防止过拟合.

图5 生成网络训练图
3 实验结果及分析
试验环境的GPU为GTX1080 8G显存,CPU为Xeon E5-2698 v3 16核主频2.3 GHz,CUDA 8.0,cudnn v5,采用tensorflow深度学习框架,原始域数据集为SVHN,目标域数据集为MNIST,图像转换的结果如图6所示.其中,转换的图像为截取自SVHN门牌图像中的数字,并按其对应数字转成MNIST数据类型图像.
由于,SVHN数据集转换MNIST数据集为一一对应,为了验证是否正确转换对转换后的MNIST数据集进行识别.文中使用文献[12]中的图像识别网络对MNIST数据集进行分类训练,在MNIST测试集上的误差率为0.23%,用该网络识别转换后的MNIST正确性.令配对鉴别网络α=2,即训练一次G-net,训练2次Pair-net,网络迭代10万次,设置文中方案不同权重的试验对比结果见表1.其中方案一选择的G-net损失函数为Pair-net反馈回来的配对损失和F-net第2层提取特征图像的均值平方误差,SVHN转换MNIST数据后的一一对应的准确率为78.32%.方案二则增加了F-net第3层的特征图形的均值平方误差损失,准确率达到81.12%,方案三增加了F-net第4层特征图像的均值平方误差损失,准确率达到84.56%.方案四在方案三的基础上增加了正则项L1损失最终的准确率为86.73%.
输入相同的SVHN数据转换成MNIST数据集,对比可见方案四的转换结果以及转换准确率要优于其他三种方案.

图6 试验结果

表1 试验对比结果
文中在相同的数据集以及使用相同的图像识别网络的条件下,文与其他图像域转换算法做了实验对比,结果见表2.选择3种图像域转换方案进行对比,其中第一种方法和和第二种方法并非单纯使用GAN算法,转换效果明显低于文中方案,第三种使用了GAN但是通过结果可见文中方案亦优于该算法.

表2 试验对比图
4 结 论
文中基于GAN生成式对抗网络相互博弈的原则,通过使用Pair-net配对鉴别网络,F-net产生特征图像的均值平方误差损失以及添加的L1正则项,提升了网络在图像域转换的能力.使用SVHN数据集作为原始域数据,MNIST数据集作为目标域数据进行图像域的转换.为了评价转换效果,利用MNIST数据集训练的识别网络对转换后的网络进行了识别,文中算法的转换准确率为86.73%,均高于其他三种算法.传统的深度学习网络,其网络权重是训练学习获得的,网络的损失函数是固定的、人工设计的,需要针对特定目标任务制定损失函数.而生成式对抗网络利用对抗机制,使得的网络的损失函数定义不再固定,而是在网络训练的过程中,以黑盒的形式用鉴别网络不断的拟合符合当前任务的损失函数.这种机制虽然实现了网络权重的学习,损失函数的学习,但是这也使得模型有效训练成为难点,因此,目前需额外增加固定的损失函数,确保模型训练的稳定性,在后续工作中完善网络转换能力,提高转换效果.
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
当代陕西(2020年17期)2020-10-28 08:18:18
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
人大建设(2018年5期)2018-08-16 07:09:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电信科学(2017年6期)2017-07-01 15:44:57
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
