
基于Hadoop的煤矿图像PCA SIFT 特征提取算法研究
2018-02-12 12:24米向荣曹建芳史昊
软件导刊 2018年12期
米向荣 曹建芳 史昊


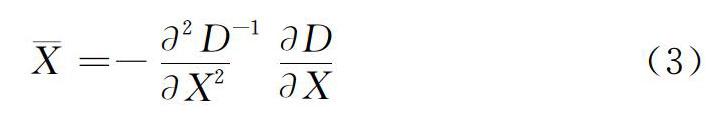
摘要:大数据技术已经成为当下热点问题,Hadoop技术在煤矿领域运用也引起了广泛关注。针对传统监控模式下煤矿视频监控系统图像采集点多、历史留存数据量大、不利于后续查找特征图像等问题,提出一种Hadoop平台下PCA-SIFT算子的图像特征提取算法,研究并改进了MapReduce并行编程模型的任务设计,对传统尺度不变特征转换算法进行了并行化设计,在Hadoop集群下实现了海量煤矿图像的PCA SIFT并行特征提取。使用汾西矿务局煤矿图像井下数据集进行实验,算法SIFT特征点检测效果好,运行耗时少。在图像数量庞大时,系统加速比几乎呈线性增长趋势,验证了算法处理大规模煤矿图像数据的有效性。
关键词:SIFT算子;尺度不变特征;Hadoop平台;MapReduce并行编程模型
PCA SIFT Feature Extraction Algorithm of Coal Mine Image in Hadoop Platform
MI Xiang rong CAO Jian fang SHI Hao 2
(1.Computer Department, Xinzhou Teachers University, Xinzhou 034000, China;
2.College of Computer Science and Technology, Taiyuan University of Science and Technology, Taiyuan 030024, China)
Abstract:Large data technology has become a hot issue at present, and Hadoop technology has also attracted widespread attention in the field of coal mining. Aiming at multiple the image acquisition points of traditional video monitoring system of coal mine monitoring mode and the huge historical data which are not conducive to the subsequent search features of images and other issues, this paper presents an image feature of a Hadoop platform for the optimization of SIFT operator algorithm. We studied and improved design of MapReduce parallel programming model and the traditional scale invariant feature conversion algorithm for parallel design in the Hadoop cluster and implemented parallel SIFT image feature extraction of massive coal mine. By using the Pascal VOC2012 data set for experiment, the effect of the SIFT feature point detection algorithm is proposed and the operation is less time consuming. When dealing with a large number of images, the system speedup is almost linearly, which verifies the validity of data processing algorithm of large scale coal mine image.
Key Words:SIFT operator; scale invariant feature; hadoop platform; MapReduce parallel programming model
0 引言
煤炭資源一直是我国较为丰富的资源,煤矿产业也是我国发达产业,但由于特殊地理环境,井下事故时有发生,严重影响安全生产。为了实现安全生产,多数矿区安装井下监控系统实现对井下视频信号的监控,产生大量监控数据,为大数据应用于煤矿奠定了基础[1 2]。通过对多机位煤矿场景图像提取目标特征,可以实时观测、及时匹配井下运动目标,同时针对井下机位角度有限等问题,可根据匹配特征点建立投影模型实现拼接[4]。
近年来,目标特征提取技术一直都是国内外学者研究的热点。Morioka等[5]提出了使用颜色直方图作为区域特征,Mittal等[6]通过使用高斯颜色模型解决了多个摄像机之间的匹配问题。然而颜色特征易受光线强度和视角变化影响,加上煤矿井下工人制服颜色近似,易产生误匹配。煤矿井下光线差、粉尘多、噪声大,环境复杂,使得煤矿井下图像特征匹配难度较大[7]。SUSAN[8]、MIC[9]等角点检测算子虽具有一定程度的不变性,但由于关键点只集中在某些区域,信息量单一,不适合煤矿井下环境[10]。David [11]于 2004 年提出了基于尺度不变特征变换(Scale Invariant Feature Transform,SIFT) 的特征提取算法,对于不同场景、光照、几何形状变换都具有较强稳定性,提高了匹配精确度。因此,相对于其它图像局部特征提取算法,SIFT更适用于煤矿领域[11 12]。贾世杰等[13]对SIFT算法在图像尺度、视角变化、目标遮挡、噪声影响等方面的鲁棒性进行了验证;厉丹等[14]将SIFT算法应用于煤矿目标,匹配准确率高于其它算法;梁玉等[15]采用RANSAC随机抽样一致性优化的SIFT算法解决误匹配问题;姜代红等[16]将SIFT特征点提取算法中多尺度理论和特征点描述符引入传统Harris算法。然而,SIFT算法本身仍然存在一些不足,比如特征描述符的维数过大、耗时过长,而且随着煤矿监控系统的逐步完善,煤矿场景图像数据集越来越庞大,SIFT算法在处理海量煤矿领域场景图像时问题更加明显。
本文针对大数据量下SIFT计算量急剧增大、时间性能骤然下降问题,提出一种新的基于Hadoop平台的融合PCA(Principal Component Analysis)降维SIFT算法[17 18]。该方法将原始 SIFT 特征提取算法与主成分分析法(PCA)融入,既不改变算法的稳定性,又降低了SIFT特征向量的维数。通过改进OpenCV函数库中SIFT算法规范MapReduce代码框架,利用Hadoop平台MapReduce并行编程模型实现了在集群环境下并行PCA SIFT算法,对煤矿领域场景图像局部特征提取任务进行并行处理,将其结果与传统SIFT算法对比。将Haddop平台下不同数量图片的运行时间和加速比进行比较,大大加快了对海量煤矿领域图像局部特征提取的速度,对优化煤矿监控视频提取目标特征有积极意义。
1 PCA SIFT特征提取算法
1.1 SIFT算法原理
SIFT即尺度不变特征变换算法,是一种利用尺度空间性质提出的局部特征检测方法,利用图像关键点的SIFT特征向量进行匹配,提取出的特征点具有尺度和旋转不变性等特点,因此对视角变化、仿射变换及噪声变化具有较好鲁棒性。传统SIFT算法通过分步处理对图像局部特征进行提取,主要包括以下步骤[11]:
(1)生成不同尺度空间,检测极值点。高斯核是唯一一个能够实现尺度变换的变换核,通过高斯微分函数与图像卷积,识别潜在特征点。
其中, σ 0是基准层尺度,o 为组Octave的索引, s 为组里图像的层索引。
(2)删去一些无效点和关键点定位。抹掉低对比度点,在每个可能候选位置上,通过一个拟合精细的模型确定关键点位置和尺度。关键点的精确定位需要对尺度空间DoG函数进行曲线拟合。利用DoG函数在尺度空间的Taylor展开式(拟合函数)为:
其中, X=(x,y,σ) T。求导并令方程等于0,可以得到极值点的偏移量为:
对应极值点,方程取值为:
其中, =(x,y,σ) T代表相对插值中心的偏移量,当它在任一维度上大于0.5时(即 x或y或σ ),意味着插值中心已经偏移到其邻近点上,所以必须改变当前关键点位置。
(3)提取关键点方向,保证旋转不变性。根据图像局部梯度方向,算法自动分配给每个关键点位置一个或多个方向。
(4)关键点描述。按照以上步骤,考虑到每一个关键点有3个信息:位置、尺度以及方向,接下来为每个关键点建立一个描述符,用一组向量将该关键点描述出来,使其不随各种变化而改变,比如光照变化、视角变化等。该描述子不但包括关键点,也包含关键点周围对其有贡献的像素点,并且描述较有独特性,以提高特征点正确匹配的概率。
1.2 PCA SIFT降维
主成分分析算法即PCA是最常用的线性降维方法,用于降低数据复杂性,识别最重要的多个特征。它将高维数据映射到低维空间中表示,以此使用较少数据维度,而且数据在较少维度上的方差最大。这是原始数据信息丢失最少的一种线性降维方式。
PCA SIFT压缩了SIFT描述子數据。首先收集数据所有特征,通过变换数据,观察数据的重要成分并进行分类以减少数据。如想表达某一种物体,而物体有很多个属性,通过变换数据,可以观察到每个属性的重要性,从而选择几种重要属性描述该物体,就起到了压缩数据的作用。具体步骤如下:
(1)构建描述子区域选定为以特征点为中心的41×41矩形(已与特征点主方向对齐)。
(2)由于最外层像素不计算偏导数,计算39×39矩阵每个像素水平、垂直方向的偏导数,得到一个39×39×2=3 042维的向量,并将其归一化。
(3)假设有N个特征点,则所有特征点描述子向量构成一个N×3 024的矩阵,然后计算N个向量的协方差矩阵。
(4)计算N×N协方差矩阵前m个最大特征值对应的特征向量,该 m个向量组成一个3 042×m的投影矩阵。
(5)将N×3 024描述子矩阵与3 024×m投影矩阵相乘,得到降维描述子向量组成的N×m矩阵。此时N个特征点的描述子向量均为m维,也就将数据转换到上述m个特征向量构建的新空间中了。
2 海量煤矿场景图像特征提取PCA SIFT算法并行化
2.1 Hadoop平台
Hadoop是一个能够对大规模数据进行分布式处理的软件框架, 以一种可靠、高效、可伸缩方式进行数据处理[19]。HDFS(Hadoop Distributed File System)和MapReduce 是Hadoop框架最核心的两个设计,前者为海量数据提供存储,而海量数据计算由后者提供 。HDFS是一种在通用硬件上运行的分布式文件系统,采用主/从模式体系结构,提供了高吞吐量数据访问,很适合大规模数据集的应用。MapReduce是一种并行编程模型且用于大规模数据集的并行运算[20]。它能够将计算任务和数据分配到Hadoop集群的各个节点,由各节点并行执行任务得到中间结果,然后进行汇总并再次向各节点分配计算,以获得最终结果。MapReduce的Map函数和Reduce函数定义了任务本身,交给用户实现,通过定义mapper()和reducer()函数实现一个键值对到另一个键值对的映射,其处理流程如图1所示。
2.2 总体框架
Hadoop平台上SIFT算法煤矿图像特征提取过程如图2所示。系统架构共3层。
(1)表现层。使用者通过网络接受服务,提交煤矿图像或接收检测结果。
(2)业务逻辑层。Web服务器根据使用者的请求执行对应业务处理。
(3)数据处理层。其是整个系统的核心部分,主要进行海量煤矿图像的存储和管理,负责并行PCA—SIFT特征提取、输出结果等。使用者将煤矿图像数据通过网络提交给Hadoop分布式系统,经过MapReduce计算模型进行算法优化和特征提取,最后输出结果。
本文对MapReduce框架的处理模型进行了改进,将Reduce任务数设置为0,全程通过mapper()函数完成所有处理任务,Map阶段结束后直接将实验结果输出。避免Reduce任务处理需大量时间,减少Map任务与Reduce任务中间操作消耗时间,使得集群节点之间传输数据的时间消耗降低,提高时间性能。
具体步骤如下:①将海量煤矿图像库中的图像处理成Hadoop作业的输入格式SequenceFile;②Map 任务按照Hadoop默认的切片大小(128M Byte)对图像文件进行分片,每个分片包含多个图像文件;③以<图像文件名,图像源文件>键值对形式,利用MapReduce框架对图像的PCA SIFT特征并行提取;④最后生成<图像文件名,图像PCA SIFT特征>形式的键值对,写入Hadoop平台的分布式文件系统HDFS中。
2.3 算法设计与实现
OpenCV提供大量Java接口,实现了图像处理和计算机视觉方面的很多算法。因此,实验使用OpenCV函数库,对其中SIFT算法进行改进,在Hadoop平台下用Java语言编程,实现基于并行PCA SIFT的煤矿场景图像特征提取算法。
2.3.1 图像数据类型定义
由于Hadoop本身没有定义与图像相关的类,作为键值对<key, value>的数据类型,而Hadoop规定用户自定义类型只有通过实现Writable接口才能使用。因此,本文自定义了数据类型RawImage,重写了Hadoop中Writable定义的基本输入输出方法。与其它类型不同,该类型在实现图像读取、存储等基础功能时,增加了将图像转换为单通道或者三通道的Mat类型以及将Mat类型编码为图像文件的功能,使其与OpenCV结合更加方便。
2.3.2 作业输入/输出格式设计
在Hadoop平台下,一张图像若被分片进行分布式存储并处理,则会破坏像素信息。因此,本文将整张图像作为键值对中的value值进行处理。
(1)图像文件输入格式类定义。本文采用Hadoop内置的SequenceFileInputFormat输入格式,它以SequenceFile文件作为输入,把大的SequencFile文件切成分片,交给Map任务处理,而一个分片里包含多条记录,每一条记录就是一张图像,key为图像文件名,value为其值,很好地解决了由于小文件太多导致启动Map任务数量过多的问题。
(2)图像文件输出格式类定义。FileOutputFormat类主要用于描述输出数据格式,本文设计了ImageOutputFormat类,继承自FileOutputFormat实现,用于将用户提供的<key, value>对写入特定格式文件中。ImageRecordWriter类继承自RecordWriter<Text, RawImage>類的实现,将图像文件名作为键名、RawImage类型的实例作为值存入HDFS文件系统中。
2.3.3 mapper()函数设计与实现
mapper()函数的主要功能包括读取图像、处理图像、转换数据等操作。实现伪代码如下:
Mat mat = Highgui.imread(files[i].toString());
Mat SIFTMat=new Mat();
FeatureDetector fd = FeatureDetector.create(FeatureDetector.
SIFT);
MatOfKeyPoint mkp =new MatOfKeyPoint();
fd.detect(mat, mkp);
//Features2d.drawKeypoints(mat, mkp, SIFTMat);
DescriptorExtractor de = DescriptorExtractor.create(Descri
ptorExtractor. SIFT);
de.compute(mat,mkp,SIFTMat );//提取SIFT特征
2.3.4 图像特征提取结果输出
由于Hadoop默认输出文件名是name r(m) nnnnn形式,其中name是由用户设定的名字,r表示reduce输出,m表示map输出,nnnnn是一个指明块号的整数。但为了便于后续方便处理和显示图像,能够使输出文件以文件名.jpg的形式输出,本文重写了FileOutputFormat类的getDefaultWorkFile()方法,实现伪代码如下:
getDefaultWorkFile(TaskAttemptContext
context,String extension) throws IOException{
FileOutputCommitter committer =
(FileOutputCommitter) getOutputCommitter(context);
return new Path(committer.getWorkPath(),
getUniqueFile(context,getOutputName(context),extension));
} //获得一个任务提交器
本文使用hadoop中的 MultipleOutputs多文件输出格式,将每个图像的文件名作为key值,图像文件作为Value值以一条记录的方式写入文件系统。实现伪代码如下:
ImageRecordWriter extends RecordWriter<Text, RawImage>
{
write(Text fileName, RawImage img)
{
FSDataOutputStream out = fs.create(outputPath);
out.write(img.getRawData());
}
//把图像写入到输出路径,且文件名为图像原文件名
}
2.3.5 PCA SIFT并行化降维
单幅煤矿场景图像每个SIFT特征点有128维,海量图像数据集维度过于庞大,而PCA可以在尽可能保留原始数据信息的情况下,把可能具有相关性的高维变量合成线性无关的低维变量。伪代码如下:
//用pca降维
Mat mean = new Mat();
Mat vectors = new Mat();
Mat result=new Mat();
Mat SIFTMat_r=new Mat();
Core.normalize(SIFTMat, SIFTMat_r,-1.0, 1.0, Core.NORM_MINMAX);
Core.PCACompute(SIFTMat_r, mean, vectors,64);
Core.PCAProject(SIFTMat_r, mean, vectors, result);
//第二轮降维
Mat mean_2 = new Mat();
Mat vectors_2 = new Mat();
Mat result_2=new Mat();
Core.PCACompute(result.t(), mean_2, vectors_2,64);
Core.PCAProject(result.t(), mean_2, mean_2, result_2);
3 实验结果及分析
3.1 实验环境与数据来源
本文采用6台计算机搭建Hadoop集群,1台为Master节点,其余5台为Slave节点。所有节点计算机硬件配置:酷睿i7四核八线程4.2G处理器,8G内存,4T硬盘;软件配置:操作系统为64位Ubuntu 14.04,Java环境为jdk1.7.0_79,Hadoop为Hadoop 2.5.1(64位编译)版本。
本文使用的实验数据来源于汾西矿务局煤矿图像井下数据集,涉及人物、开采工具、井下隧道场景等多种类别。数据集共包含2万张图像、14个类别,为验证提出算法在处理海量图像时的性能,本文采用复制方法构建了海量图像库。
3.2 煤矿图像SIFT特征点检测效果
为了验证SIFT特征点检测效果,本文对传统SIFT算子与提出的算法在汾西矿务局煤矿图像井下数据集进行实验对比,图3 是部分图像的PCA SIFT特征检测效果。
从图3结果可清晰看到,相对于传统SIFT算法的特征提取效果,并行PCA SIFT算法特征提取效果更加明显。并行PCA SIFT所获取的描述子在旋转、尺度变换、透视变换、添加噪声匹配和亮度变换等条件下,匹配均大幅领先于SIFT。虽然提取特征点没有传统SIFT多,但所得正确特征点远远多于传统SIFT。由此可见,并行PCA SIFT生成的描述子质量很高。并行PCA SIFT在特征点提取、描述子计算中运行时间稍少于SIFT,速度稍快,但在随后描述子匹配过程中,运行时间远远低于SIFT算法,速度远远超过SIFT算法。
3.2.2 运行时间
为进一步验证并行化算法的时间性能,同时为了公平比较,本文采用复制方法构建不同数量级规模的数据集,对单一节点和多节点算法的运行耗时进行了实验比较,结果如图4所示。
图4结果表明,在图像数量小于8 000时,节点数目不同对煤矿图像SIFT特征提取的运行耗时影响不是很明显。多节点集群架构运行耗时有时可能会比单节点计算机处理时间长,原因是多节点架构在处理小量图像数据集时增加了节点计算机之间的通信联系开销,而煤矿场景图像数量急剧增大时,多节点架构的Hadoop集群计算机系统优势就慢慢体现出来。虽然不同节点情况下,算法运行时间均会随煤矿场景图像数量增加而增加,但单一节点计算机运行耗时线性增长,而多节点集群架构的计算机系统运行耗时增加比较平缓,并且随着节点计算机数量愈多,所需处理的运行时间曲线上升愈平缓。因此,本实验充分证明了Hadoop集群架构在处理海量图像数据时的优越性。
3.3 加速比
加速比是指同一任務在单节点环境下与多节点环境下运行时间的比值,是衡量Hadoop平台下并行算法效率的一个重要指标[21]。为验证算法在Hadoop平台下的性能,本文从汾西矿务局煤矿图像井下数据集上复制并构建了包含8 000、20 000、60 000张不同类别图像的3个数据集,进行加速比测试,结果如图5所示。
理想状态下,系统加速比应随着节点计算机增加而呈线性增长,但由于受通信开销、负载平衡影响,实际上加速比并不能呈线性增长。从图5可以看到,在图像数量不多时,系统的加速比随着节点计算机增多而增大,但增长幅度并不大,而随着图像数量增多,系统加速比增长幅度会变大,图像数量达到60 000张时,系统加速比几乎呈线性增长趋势,进一步充分说明了Hadoop集群在处理大规模数据集时更能体现其优越性。
4 结语
本文对Hadoop平台下基于PCA SIFT算子的煤矿图像特征提取算法进行了深入探讨,并研究如何将MapReduce并行编程模型应用于传统SIFT特征提取算法中,实现海量图像的SIFT特征提取。实验结果表明,算法的SIFT特征提取效果好,处理大规模图像数据集运行耗时少,搭建的Hadoop集群能够充分利用各节点计算机资源,相对于单节点计算机,系统获得了很好的加速比,充分体现了Hadoop集群分布式并行处理的强大运算能力。
随着大数据时代到来,各类大数据分析处理已成为新的研究热点。下一步研究工作主要有:①扩展Hadoop集群的节点数、调节参数,提高分布式并行处理效率;②将提取的并行PCA SIFT特征应用于煤矿场景图像分类中,以提高数字图像理解的智能性。
参考文献:
[1] 李波, 巨广刚, 王珂,等.2005 2014年我国煤矿灾害事故特征及规律研究[J].矿业安全与环保, 2016,43(3):111 114.
[2] 贾世奎,李臻,李鑫,等.煤矿井下用夜视摄像系统研制[J].机械研究与应用,2016,29(6):147 149.
[3] 马小平,胡延军,缪燕子.物联网、大数据及云计算技术在煤矿安全生产中的应用研究[J].工矿自动化, 2014,40(4):5 9.
[4] 王蓓蓓,李玉良,胡浩.基于Matlab的煤矿井下运动目标检测的研究[C].厦门:煤矿机电一体化新技术2011学术年会,2011.
[5] MORIOKA K, MAO X, HASHIMOTO H. Global color model based object matching in the multi camera environment[C].International Conference on Intelligent Robots and Systems, 2006:2644 2649.
[6] MITTAL A, DAVIS L S.M2 tracker: a multi view approach to segmenting and tracking people in a cluttered scene[J].International Journal of Computer Vision, 2003,51(3):189 203.
[7] 高翔,徐柱.基于多尺度模型的数据库影像特征匹配[J].测绘科学,2016,41(2):121 125.
[8] WENG M, HE M. Image feature detection and matching based on SUSAN method[C]. International Conference on Innovative Computing, Information and Control, 2006:322 325.
[9] TANG L, WANG K, LI Y, et al. The application of the MIC and improved snake algorithm on the image segmentation[C].Industrial Electronics and Applications,2007:1898 1902.
[10] 厉丹,钱建生,柴艳莉.井下危险区域目标检测[J].煤炭学报,2011,36(3):527 532.
[11] LOWE D G. Distinctive image features from Scale Invariant keypoints[M].Kluwer:Kluwer Academic Publishers,2004.
[12] FROMMEL A Y, MANEJA R, LOWE D, et al. Severe tissue damage in Atlantic cod larvae under increasing ocean acidification[J]. Nature Climate Change, 2012,2(1):42 46.
[13] JIA S J, WANG P X, JIANG H Y, et al. Study of image matching algorithm based on SIFT[J]. Journal of Dalian Jiaotong University, 2010,31(4):17 21.
[14] DAN L, QIAN J S. SIFT based object matching and tracking of coal mine[C].International Conference on Wireless, Mobile and Multimedia Networks,2011:327 330.
[15] 梁玉,厲丹,牛翠溪,等.基于井下环境的SIFT算法研究[J].工矿自动化,2011(2):55 58.
[16] 姜代红,华钢,王永星.矿井监控图像自动快速拼接算法研究[J].工矿自动化,2015,41(4):78 82.
[17] WHITE T. Hadoop: the definitive guide[M]. 2nd edition. Hadoop: The Definitive Guide Yahoo Press, 2010.
[18] LUO J, GWUN O. A comparison of SIFT, PCA SIFT and SURF[J]. International Journal of Image Processing, 2013,3(4):143 152.
[19] 顾荣,严金双,杨晓亮,等.Hadoop MapReduce短作业执行性能优化[J].计算机研究与发展,2014(6):1270 1280.
[20] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635 2642.
[21] 林宇晗,孔繁鑫,徐惠婷,等.线性加速比并行实时任务的节能研究[J].计算机学报,2013,36(2):384 392.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年8期)2021-11-28
当代陕西(2019年14期)2019-08-26
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中学数学杂志(初中版)(2016年5期)2016-11-01
噪声与振动控制(2015年4期)2015-01-01
中国卫生(2014年2期)2014-11-12
语文知识(2014年7期)2014-02-28
测绘科学与工程(2014年2期)2014-02-27
