
面向满文字符识别的训练数据增广方法研究
2018-02-05 01:36毕佳晶郑蕊蕊贺建军
大连民族大学学报 2018年1期
毕佳晶,李 敏,郑蕊蕊,许 爽,贺建军,黄 荻,2
(1.大连民族大学 信息与通信工程学院,辽宁 大连, 116605;2. 北方民族大学 数学与信息科学学院,宁夏 银川,750021)
光学字符识别(Optical Character Recognition, OCR)主要采用机器学习方法实现,而深度学习技术的发展为OCR的研究提供了更先进的解决方案[1]。深度学习技术给模式识别领域的很多方面带来了显著的改善[2],但需要海量训练数据才能满足深度学习模型的泛化条件。数据库的采集和整理工作需要消耗大量人力物力来兼顾规模性和准确性[3],仅靠人工收集整理样本效率非常低,难以满足实验对数据规模的要求。特别是在我国少数民族文字识别的研究中,样本数据的匮乏问题尤为突出[4]。原因在于目前能够读写少数民族文字的人数有限,公开的数字化少数民族文献资源短缺。因此亟待解决训练样本数据匮乏的问题。
采用数据增广技术(Data Argumentation)生成数据(Synthetic Data)是目前扩大样本规模,扩展样本多样性的有效途径。M Jaderberg[5]等人通过对原有Google字体库中的样本采用字符间距调整,添加下划线和投影畸变的数据生成方法进行扩展,并使用扩展后的数据集研究自然场景下的文本识别,达到了90.8%的识别率。PatricceY.Simard[6]等人使用镜像、旋转、仿射变换和扭曲等数据生成方法对MNIST数据集进行扩展,使用扩展后的数据集研究手写数字识别,达到了99.6%的识别率。采用上述几何变形方法扩展少数民族文字数据是一种很好的借鉴[7]。本文以满文字符识别为研究背景,针对满文文档的特点,提出一种融合字体几何结构形变与图像质量变换的数据增广技术框架。
1 满文数据增广技术框架
在满文字符识别的研究中以《满语365句》为蓝本初步构建印刷体满文单词数据集,包含671类共2130个规范的印刷体满文单词图像样本[8],因此样本数据集字体单一,且数量难以满足训练深度学习模型的要求。
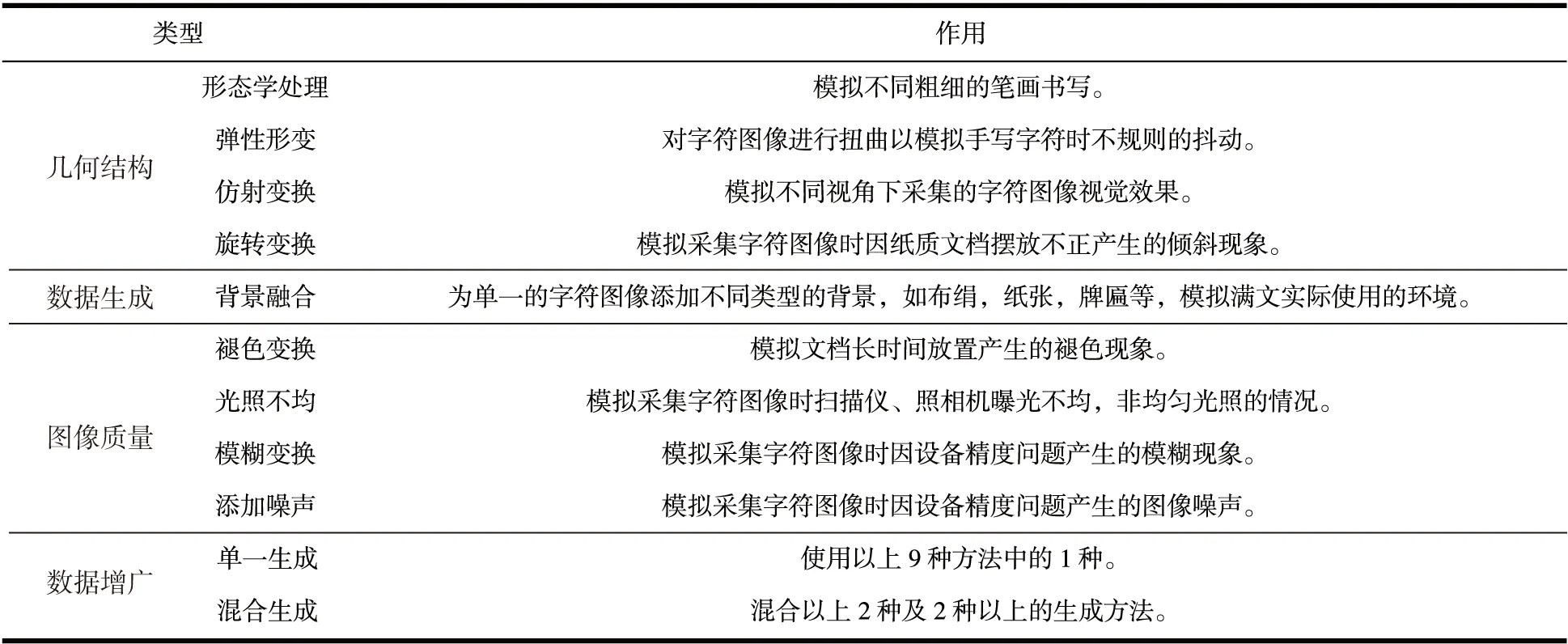
本文提出一种满文单词图像数据增广技术框架,由字体几何结构变形和图像质量变换两个模块组成,分别采用9种基本的数据生成方法,模拟满文文档采集时的常见情况见表1。除使用单一数据生成方法外,对同一训练样本混合2种及2种以上的数据生成方法以进一步增加训练样本的数量和形式。
表1数据增广技术框架
2 字符几何结构变换
2.1 形态学处理
满文文字的印刷体,具有字体规整且字符笔画的粗细较为一致的特点。利用图像形态学处理中的膨胀和腐蚀对字符图像进行处理以改变其笔画的粗细,模拟不同粗细的笔触[9]。对字符图像进行腐蚀和膨胀处理时,核的大小和形状都对结果有影响。首先固定核大小为4×4,以常用的3种形状的核(十字交叉型、矩形和圆形)分别进行膨胀和腐蚀处理的结果如图1。综合考虑处理效果和运算复杂度,选择矩形核。
因为所处理字符的类别、形状、笔画粗细等差异较大,核的大小无法用一个统一的适用标准定义,只能通过实验获得适用范围。以不同大小的矩形内核处理一张满文字符图像结果如图1(c):当核大小为2×2像素时(像素为单位)的效果和原图几乎无差别,而核大小为7×7和8×8时处理结果所包含的字符信息已有丢失。因此合适的处理内核大小应为kernel∈{3,4,5,6},即形态学变换核大小的经验值为kernel∈{1/3w, 1/2w}的整数,其中w表示满文中轴线宽度。

图1 采用不同形状及大小内核的形态学变换结果
2.2 弹性形变
James McCaffrey在对MNIST数据库的数据增广研究中提出弹性形变法模拟手写数字扭曲的形状[9]。对图像进行弹性形变的关键是如何对每一个像素进行移动,使得相邻像素的移动距离和方向相似的同时在全局表现出一定的随机性。弹性形变算法的伪代码如下:
(1)输入:源图像M;
(2)以源图像M的尺寸(w,h),定义大小为(w,h)维度的两个偏移矩阵MatX,MatY分别对应图片像素的x和y方向的偏移对MatX、MatY的每一元素随机生成-1到1的偏移值,生成所需目标数量的偏移矩阵;
(3)将高斯矩阵分别和MatX和MatY进行卷积,使相邻随机的偏移值获得一定的相关性;
(4)将自定义扭曲幅度a 与MatX和MatY的每一元素相乘,得到调整后的偏移矩阵;
(5)利用MatX和MatY矩阵作为偏移矩阵生成扭曲后的图像R;
(6)输出:结果图像R。
使用弹性形变法,可在一定程度上模拟手写满文时因手部不规则的抖动而引起的字体形变现象。其结果如图2。

图2 弹性形变变换结果
2.3 仿射变换
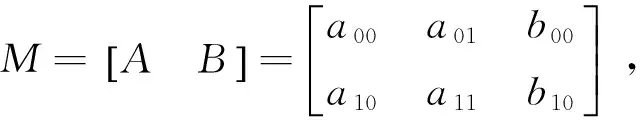

(1)
在源图像和结果图像中预设3组对应点来构建映射关系,仿射变换的流程如图3。
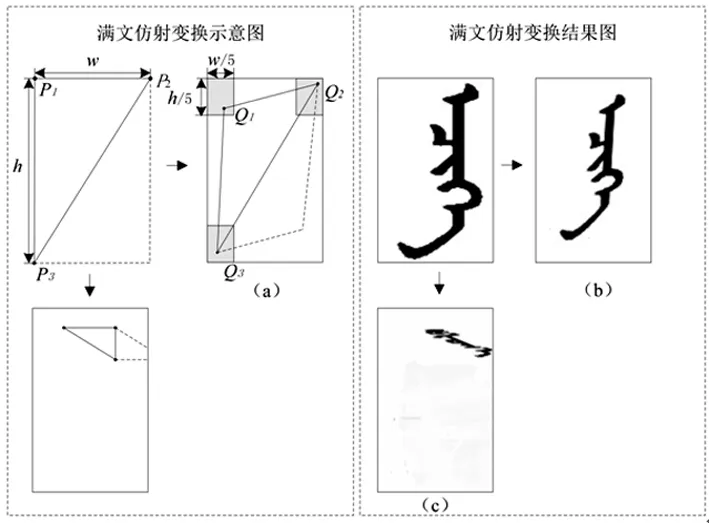
图3 仿射变换流程及结果
在原图像中选取3个固定点P1、P2和P3;在结果图像中的对应点分别是Q1、Q2和Q3。如果采用无限制随机法选取Q点,则有极大概率产生类似于图3(c)所示的结果,出现字符信息严重缺失的现象。为解决该问题,本文提出在特定区域内随机选取Q1、Q2和Q3的方法:设原图像的高为h宽为w,则特定区域的高h1= 0.2 ×h,宽w1= 0.2 ×w,其中0.2是通过大量实验获得的经验值。采用上述规则标定的特定区域位置即图3(a)中点Q1、Q2和Q3所处的阴影区域。采用特定区域内的仿射变换结果如图3(b)所示,在保持原有仿射变换随机性的同时,避免了结果图像字符信息缺失的现象。
3 字符图像质量变换
3.1 自定义背景融合
造成印刷体满文样本数据单一的另一原因是样本数据均为黑色字体衬以白色背景,而真实场景下的满文大多具有复杂的背景。本文中采用将字符图像与各种采集自真实场景下的背景图像进行融合的方法来更好的模拟真实场景下的字符图像。此方法可以进一步扩展样本数据的多样性。设背景图像为n×m阶矩阵Ib ,其中第i行j列处点的值表示为bi,j(i≤n,j≤m),字符图像二值化后为n×m阶矩阵It,其中第i行j列处点的值表示为ti,j(i≤n,j≤m),则融合结果图像Ir可以由矩阵Ib与矩阵It求哈达玛乘积所得,即Ir=bij*tij,其中*表示哈达玛乘积。同一满文字符与采自不同真实场景下的背景相融合的效果图如图4。
3.2 褪色变换
现存的满文文档大多已产生不同程度的褪色现象。因此本文中采用将单词图像与背景进行线性混合操作的方法来模拟真实情况下的文档褪色现象。线性混合操作是一种二元的像素操作,其原理为
dst=(1-a)*src+a*srd。
(2)
式中:α∈(0,1),表示背景图像在结果图像中所占的比例;dst表示结果图像;src表示字符图像;srd表示背景图像。在实际应用中调整α的值可以实现不用程度的褪色模拟。以α值为0.5进行模拟的结果如图5。
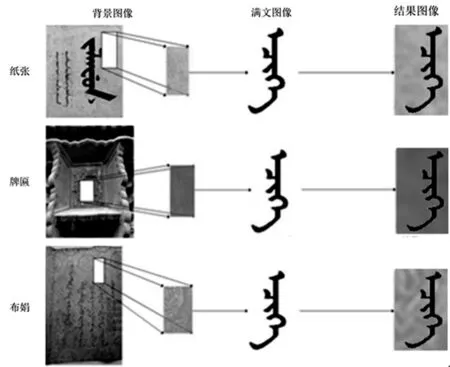
图4 满文单词图像背景融合示例

图5 满文图像褪色现象模拟
3.3 光照不均模拟
字符图像模拟光照不均可以简化为在字符图像上叠加白色光斑,光斑的亮度从光斑中心向周围逐渐减小。由于字符图像样本的底色多为白色,字体多为黑色,因此对光斑的叠加可表示为
y=Ro+I*W,
(3)
式中:Rb为一点经过混色后的颜色;Ro为该点原始的像素值;W为RGB表示纯白色。I为当前点处的光斑亮度,取值随位置变化:设虚拟的光斑中心在图像的(Ox,Oy) 处,光斑的半径为R像素,则图像任意点(x,y)处的混合I值为
(4)
通过设置光斑的中心坐标和半径即可实现字符图像的模拟光照不均效果。设置光斑中心坐标(Ox,Oy)为(w/2,h/2),光斑半径R=w/2其光照不均模拟效果如图6。
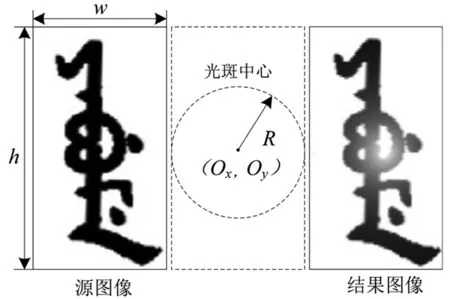
图6 光照不均现象模拟
4 实验结果分析
实验以采集自《满语365句》的真实图像为基本数据,在此基础上分别采用9种字符数据生成方法之一获得初步图像样本,然后以这些图像样本为基础对其使用另外的8种方法进一步扩展数据的多样性和数量,部分混合生成结果如图7。数据生成过程由一个小组独立完成,组员之间所采用的方法也保持相对独立,每位组员对每种字符的生成都采用了随机机制,以确保生成的样本数据间有较大的差异,进一步降低了生成的样本数据在特征空间上的重复率。在训练集和测试集划分上,采用随机置乱的方法进一步消除主观因素的影响。

图7 部分混合生成结果示意图
分别采用支持向量机和卷积神经网络模型对印刷体满文单词进行识别。在进行支持向量机实验时所用的数据集中每类满文单词共有300个样本,其中200个样本用于训练,100个样本用于测试,在对40类满文单词的识别中达到了90%的识别率。在进行卷积神经网络实验时所用的数据集中每类满文单词共有70 000个样本,其中60 000个样本用于训练,10 000个样本用于测试,在对671类满文单词的识别中达到了97.83%的识别率。实验结果表明本文提出的数据增广技术框架是一种扩充机器学习训练样本数据量的有效方法,能够提供多样化的训练样本。
5 结 论
为了解决满文识别研究中遇到的样本缺乏问题,本文提出了使用人工数据生成方法扩展样本数据的技术框架,该框架由字体几何结构变形和字符图像质量变换两个模块构成,共包含9种基本数据生成方法。实验证明采用本文提出的数据增广方法生成的训练样本能够满足机器学习方法对训练样本规模和多样性的需求,是一种扩充光学字符识别数据规模的有效方法。
[1] FEDOROVICI L O, PRECUP R E, DRAGAN F, et al. Evolutionary optimization-based training of convolutional neural networks for OCR applications[C].tem Theory: Control and Computing, 2013:207-212.
[2] LECUN Y, BENGIO Y, HINTON G. Deep learning.[J]. Nature, 2015, 521(7553):436-44.
[3] 金连文,钟卓耀,杨钊,等. 深度学习在手写汉字识别中的应用综述[J]. 自动化学报,2016 (8):1125-1141.
[4] 郑蕊蕊,李敏,吴宝春. 基于MATLAB GUI的少数民族文字手写体采集系统——以满文为例[J].大连民族学院学报,2014(3):306-309.
[5] JADERBERG M, SIMONYAN K, VEDALDI A, et al. Synthetic data and artificial neural networks for natural scene text recognition[J]. EprintArxiv, 2014(1):1-8.
[6] SIMARD P Y, STEINKRAUS D, PLATT J C. Best practices for convolutional neural networks applied to visual document analysis[C]// International Conference on Document Analysis and Recognition. IEEE Computer Society, 2003:958-963.
[7] 王会靖. 基于局部特征的复杂背景图像内文本识别研究与实现[D].上海:上海交通大学,2010.
[8] 周兴华,李敏,郑蕊蕊,等. 印刷体满文文字数据库的构建与实现[J].大连民族学院学报,2015(3):270-273.
[9] JAMES M C. Distorting the MNIST Image Data Set[EB/OL] (2014-07)[2016-12-13].https://msdn.microsoft.com/en-us/magazine/dn754573.aspx.
[10] RAFAEL C G, RICHARD E W . 数字图像处理[M].阮秋琦,译.北京:电子工业出版社,2011.
猜你喜欢
诗歌月刊(2023年1期)2023-03-22
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
阅读(高年级)(2019年9期)2019-11-15
阅读与作文(小学高年级版)(2019年8期)2019-10-16
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
中国医疗美容(2015年1期)2015-07-12
民族古籍研究(2014年0期)2014-10-27
民族古籍研究(2014年0期)2014-10-27
