
基于随机游走的个性化电影推荐系统研究
2018-01-31 09:17:20张中一
滁州职业技术学院学报 2017年4期
张中一
(山东大学,山东 济南 250061)
引言
电影推荐系统被用来向目标用户推荐其可能感兴趣的电影。个性化推荐系统考虑到用户之间的兴趣差异性为用户进行推荐,是一种个性化的信息过滤技术。推荐系统的概念在上个世纪七十年就曾在Negroponte的文章中被提到[1],直到二十世纪末期关于推荐系统的研究开始被研究人员广泛关注。施乐帕克研究中心 (Xerox PARC)的David Goldberg在1992年,发表的论文中第一次使用了术语“协同过滤(collaborativefiltering)”[2],其利用协同过滤技术帮助用户筛选有趣的信息,开启了关于协同过滤的研究先河;GroupLens监测Usenet新闻系统上的读者,并且将相似的文章建议给相似的用户[3]。
相比而言,国内关于个性化推荐算法的研究起步较晚,主要关注点包括电子商务、关联规则、协同过滤的改进、Web挖掘等方向,邓爱林等通过在聚类项目中搜索相似项目提高了系统的实时响应速度[4];宋淑彩等利用网页之间的关联性,挖掘关联规则,为浏览者提供个性化推荐以改良网站[5]。
目前主要有以下两个关键问题需要研究:稀疏性问题:随着网络上资源越来越多,用户之间历史观看记录中共有的观看过的电影的比例越来越小,在利用协同过滤的思想的方法中,给查找相似用户带来困难;冷启动问题:这是新系统建立初期,新用户或新电影加入时,常面临的历史信息不足的问题,是稀疏性问题的一种极端情况。
本文针对现有推荐方法中面临的稀疏性和冷启动问题,提出了一种基于电影标签,通过随机游走生成的电影推荐方法。本方法首先通过电影评分网站和电影宣传网站的基于python的评论数据挖掘,提取电影的标签属性,然后利用标签的相似性,再聚合网络资源,计算出电影的标签邻接矩阵。利用电影的标签邻接矩阵和目标用户有明确倾向的初始向量进行迭代,再辅以票房,评分,观影人数等权重,利用随机游走算法,最终根据可能性大小,利用基于MVC模式的java web技术列出目标用户可能喜欢的电影。
一、随机游走算法的原理
随机游走模型的基本思想是,从一个或一系列顶点开始遍历一张图。在任意一个顶点,遍历者将以概率1-r的概率游走到这个顶点的邻居顶点,以概率r随机跳跃到图中的任何一个顶点,称r为跳跃发生概率。每次游走后得出一个概率分布,该概率分布刻画了图中每一个顶点被访问到的概率,用这个概率分布作为下一次游走的输入并反复迭代这一过程。当满足一定前提条件时,这个概率分布会趋于收敛[6]。收敛后,即可以得到一个稳定的概率分布。本文使用收敛后的概率分布来显示用户对于未知电影的倾向程度。
p(t+1)=(1-r)Wp(t)+rp(0)
在电影推荐算法的具体实现:邻接矩阵W代表具有权重的邻居顶点图中的元素即电影之间的相似程度,由电影标签的相似性求出。P(0)为初始概率分布向量,r为跳转发生概率,一般取0.15[7],P(t+1)为游走过程后的输出概率。反复迭代此式直至p(t+1)与p(t)任一元素相差最大不过0.00001,即认为P矩阵收敛,输出概率分布向量。下面以四部电影为例,展示公式属性以及算法流程:
W邻接矩阵如图,矩阵的元素值代表某两部电影的标签相似性如表1:
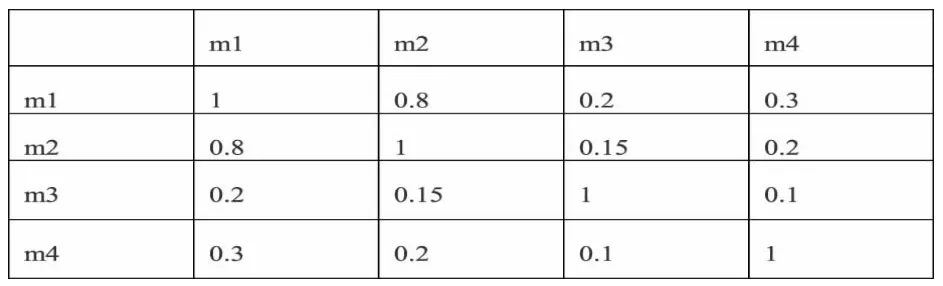
表1:电影之间的标签相似性邻接矩阵
P(0)表示用户已确定的兴趣,例如已知某用户对于电影1特别喜欢,但是对于电影2和电影3没有数据,那么初始概率分布为图中的第二列数字向量。
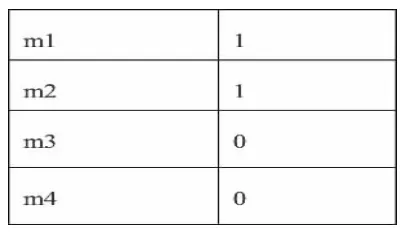
表2:针对电影的初始概率分布
二、算法实现过程
(一)数据准备
利用python写出爬虫[8],抓取电影评论网站的官方介绍和用户评论,进行词频统计,抓取词频最高频率的前30个作为电影的私有标签。统计所有电影的标签,列取频率最高的100个作为待推荐的公有标签。因为社交网站数据量过大,本文以中国票房TOP250电影为例,展示算法效果,部分电影名称如下,以票房排名为编号,作为电影的数字代称:
战狼2:001;复仇者联盟2:014;智取威虎山044;钢铁侠 053。
以战狼2为例,本文抓取了豆瓣全部197033条评论和新浪1000条涉及战狼2的微博。抓取豆瓣网站的评论时需要注意三个问题:模拟登陆、抓取频率和标签意义。其中的标签意义问题,即针对抓取到的标签要进行数据清洗,除去无意义的虚词—停止词,如:在、里面、也、的、他等;还要除去对于电影评论无意义的实词,例如:很、不、上、挺、人、一个、不错、那段、好、真是、确实、不会、已经、个人、结尾等;最后还有贬义词:意淫、烂、无语、炒作、失望等,还有电影名称以及电影中的主角名称等等。依据前人工作,这些词组对于电影的标签鉴别毫无意义。这方面可以进行机器学习的识别,进行逻辑回归处理,但是本文是人工筛选出有意义的标签。
除了数据挖掘影评生成的标签之外,本文还抓取了电影的官方介绍中提到了标签,例如:动作、爱情、战争、历史等,作为官方的介绍标签.这种标签准确度不高,但是比较普遍,容易获取,很大程度上解决了数据的稀疏性和冷启动问题。
战狼2官方标签:动作,军事,战争;影评标签:吴京,动作,主旋律,非洲,好莱坞,场面,坦克,战狼,美国,大片,英雄主义,戏,故事,动作片,剧情,镜头,拯救,逻辑。
通过词云展示如图:(余下电影皆同,故不一一展示)

智取威虎山官方标签:战争,动作,历史,冒险;影评标签:徐克,韩庚,经典,杨子荣,座山雕,主旋律,梁家辉,红色,样板戏,故事,剧情,张涵予,好莱坞,特效。
复仇者联盟2官方标签:科幻,动作,冒险;影评标签:英雄,漫威,绿巨人,剧情,场面,反派,人物,超级,角色,感情,彩蛋,打斗。
钢铁侠官方标签:动作,冒险,科幻;影评标签:英雄,装备,美国,蝙蝠侠,情节,爆米花,漫威,幽默,魅力,蜘蛛侠,铁臂,身材。
(二)邻接矩阵
通过标签相似性,计算出电影之间的标签邻接矩阵。通过电影之间的私有标签、共有标签和官方标签的相关度,计算出相似矩阵。以战狼2,智取威虎山,复仇者联盟2,钢铁侠四者为例,展示相似矩阵的算法。相关度:1/标签在A电影的次序*1/在B电影的次序,依次加和,作为最终相关度。最终对相关性矩阵做正则化处理。

表3:战狼2、智取威虎山、复仇者联盟2、钢铁侠的邻接矩阵
(三)初始概率分布
一般来说,个性化电影推荐系统是通过用户的历史记录,例如对视频的评分、评论、收藏、分享和观看记录,生成推荐内容的。种子向量就是收集了用户的历史记录中所记录的嗜好,从而形成的一维矩阵。例如:用户对战狼2打了5分,那么在种子向量中该电影的元素值为1,对复仇者联盟打了4分,那么种子向量中对应位置的元素值为0.8.。初步生成的种子向量再乘以票房、观影人数的权重。例如战狼2有50亿票房,豆瓣评分7.4,那么战狼2的权重为50*7.4.最终算出的种子向量作为随机游走的初始向量。
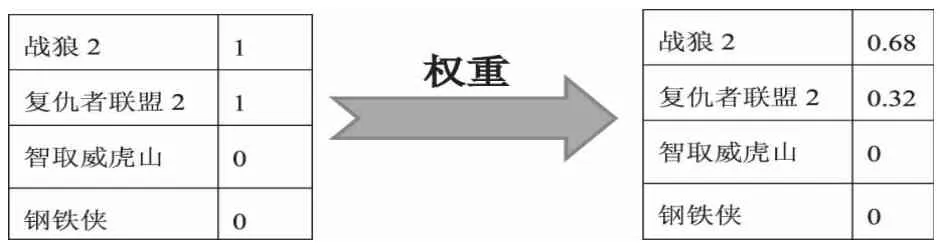
表4:初始概率分布 表5:权重处理后的初始概率分布
三、页面展示和数据储存
页面展示方面,本文采取java web技术建立一个网站,基于MVC模式完成网页的设计。MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写。Model(模型)是应用程序中用于处理应用程序数据逻辑的部分,负责在数据库中存取数据;View(视图)是应用程序中处理数据显示的部分,是依据模型数据创建的;Controller(控制器)是应用程序中处理用户交互的部分。负责从视图读取数据,控制用户输入,并向模型发送数据。MVC的核心思想是业务数据抽取同业务数据呈现相分离;分离有利于程序简化,方便编程,如图:
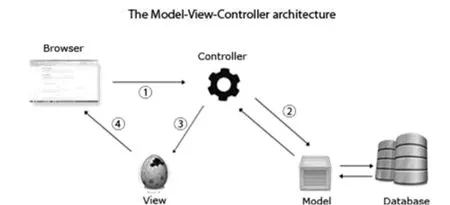
图2:MVC网页设计模式
另外利用java操作mysql数据库进行了数据储存。Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。利用mysql数据库将海量的现有电影,各个电影的标签、评分、票房,电影之间的标签相似矩阵全部存储起来,生成电影结果时只需一次矩阵迭代计算便可得出推荐结果。推荐结果:根据可能性大小显示最可能喜欢的5部电影。推荐结果如图:

图3:推荐结果展示
四、总结
解决了冷启动问题:采用电影评论的词频最高的词组和宣传媒体的重点作为标签,电影刚出现时,各大媒体肯定会有相关的宣传内容,从中可以提取标签,解决了电影发行初期数据不足的冷启动问题。解决了数据稀疏性问题:采用电影的官方标签,很大程度上解决了这一问题。
本算法的创新性:采用
票房,观影人数等作为权重,如果一个电影在某一时间段内能被大众认可,那么极有可能被目标用户认可,并且这两个权重某种程度上可以作为基于用户的协同过滤的体现,同时大幅度降低了计算复杂度;解决了多标签排序问题,优于之前的单标签推荐;
本算法的不足:数据抓取不足,因为时间和能力有限;随机游走只采用了局部网络,没有采用全局网络;电影评分网站的评分可能不够准确,将其作为权重可能降低准确度;数据清洗阶段不够智能化,只能依靠人工进行筛选。可研究方向:增加数据源;采用全局网络的随机游走;将机器学习的逻辑回归应用于数据清洗。
[1]Negroponte N.The architecture machine:towards a more human environment[M].MIT pressCambridge,MA,1970.
[2]Goldberg D,Nichols D,Oki B M,et a1.Using collaborative filtering to weave an informationtapestry[J].Communications of the ACM,1992,35(12):61-70
[3]Resnick P,Iacovou N,SuchakM,eta1.GronpLens:an open architecture for collaborativefiltering of netnews[C].ProceedingsoftheProceedingsofthe1994 ACM conference on Computer supported cooperative work,ACM,1994:175.86.
[4]武慧娟,周兰萍,辛跃.基于知识图谱的国内外个性化推荐比较研究[J].东北电力大学学报,2012,32(5):124-8.
[5]宋淑彩,祁爱华,王剑雄.面向web的数据挖掘技术在网站优化中的个性化推荐方法的研究与应用 [J].科技通报,2012,28(2):117-9.
[6]郑伟,王朝坤,刘璋等.一种基于随机游走模型的多标签分类算法[J].计算机学报,2010,33(8):1418-1426.
[7]Zhang L,Wu J,Zhuang Y,Zhang Y,Yang C.Reviewoff—ented metadata enrichment: A case study//Proceedings of JCDL.Austin,TX,USA,2009:173—182.
[8]Hang.python爬虫实战一:分析豆瓣中最新电影的影评[2017-8-2]https://segmentfault.com/a/1190000010473819.
[9]周文乐.基于多策略的电影推荐方法研究[D].合肥:中国科技大学,2015.
[10]陈天昊.互联网电影推荐方法的研究与实现[D].合肥:中国科技大学,2014.
[11]Chen,X.;Liu,M.-X.d;Yan,G.-Y. RWRMDA:Predicting novel human microRNA-disease associations[J]Molecular bioSystems,2012,8(10):225-235.
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13 11:41:32
装备制造技术(2020年3期)2020-12-25 05:22:02
新闻传播(2018年2期)2018-12-07 00:55:52
少儿美术(快乐历史地理)(2018年1期)2018-09-25 02:50:58
海峡姐妹(2017年10期)2017-12-19 12:26:12
意林(绘英语)(2017年10期)2017-06-21 10:02:26
科技视界(2016年19期)2017-05-18 10:18:46
中国工程咨询(2017年3期)2017-01-31 05:29:50
网络空间安全(2016年3期)2016-06-15 20:27:07
读写算·教研版(2015年13期)2015-07-28 07:13:11
