
基于敏感性分级的(k, δ, ai)-匿名模型
2018-01-29 00:59祝永志迟玉良
网络安全与数据管理 2018年1期
刘 阳,祝永志,迟玉良
(曲阜师范大学 信息科学与工程学院,山东 日照 276800)
0 引言
近年来,移动社交网络的快速发展为人们的生活带来便利的同时也产生了大量的轨迹数据[1]。这些轨迹数据中包含了大量的个人信息。通过对这些数据的挖掘、分析,就能够获取个人隐私信息,如单位地址、居住地址、经常去的场所等,直接对这些数据进行发布将会造成个人隐私信息的披露,甚至对人身安全造成威胁[2-3]。所以,如何在共享这些轨迹数据的同时,有效地保护个人隐私以及防止敏感信息的披露,已成为隐私保护领域研究的重点。
目前移动用户隐私保护方法大致可以分成三类[4-6]:(1)假数据法,是指用假轨迹替代真实轨迹或在真实轨据中加入假轨迹,以达到不能唯一标识出真实轨迹的目的;(2)抑制法,是指有限制地发布原始轨迹数据,即直接发布一般数据,而对敏感数据要限制其发布或经过扰乱后再发布;(3)泛化法,是指对轨迹数据进行抽象化处理,将线扩展为体,从而达到降低攻击者标识出用户概率的目的。其中,轨迹k-匿名是实现轨迹隐私保护的重要方法[7-9],该方法要求匿名轨迹数据库中只能以不大于1/k的概率重新确定一条轨迹,即要求任一轨迹在匿名数据库中存在至少k-1条与其相同的副本轨迹,从而使攻击者无法确定该轨迹属于哪个个体,进而达到保护用户隐私信息的目的[10]。
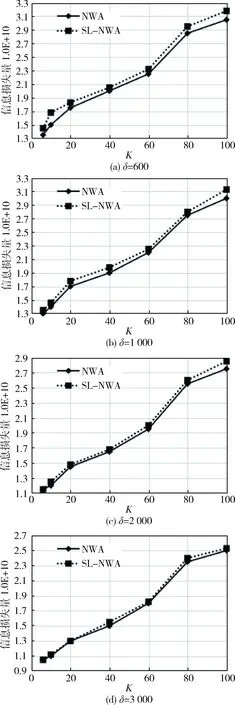
但是,由于轨迹数据收集时GPS的不确定性及网络的延时性等问题[11-12],使得获取的轨迹位置存在一定范围的误差。因此,ABUL O等人基于轨迹k-匿名提出了(k, δ)-匿名模型[13],以及实现该方法的NWA (Never Walk Along)算法,该方法要求对于任意一条轨迹,能够找出离该轨迹最近的n(k-2 (k δ)-匿名模型在实现k-匿名分组时,没有考虑位置点的语义敏感性[14]。如表1所示,坐标不同所对应的实际位置不同,而不同位置的语义敏感性也不同。如果不考虑位置点的敏感性就有可能会造成发布的轨迹数据在某一时刻经过高敏感区域。如表2所示,发布的匿名数据集满足(4, 3)-匿名模型,但是轨迹1、4在时刻7经过赌场,轨迹2、3在时刻7经过酒吧,即这4条轨迹在时刻7都经过高敏感区域。如果攻击者根据背景知识得到Tom的运动轨迹处于该等价类,虽然他不能确定哪条轨迹是Tom的运动轨迹,但是可以得出Tom去了不良场所。因此,仍有隐私泄露的危险。 表1 敏感位置信息表 为此,本文提出了(k,δ,ai)-匿名模型,该模型首先要求满足(k, δ)-匿名模型,其次还应满足任一聚类中同一时刻处于同一敏感级别的位置点不超过k/l(本文取l=2),由于轨迹数据获取的不确定性,假设当两点距离小于β(本文取β=50)时为同一点。 定义1 (轨迹)轨迹表示移动物体(个人、公共汽车、出租车等)访问这些位置的位置和顺序。 也就是说,轨迹Tr由一组有序位置集组成,记为Tr=(l1,l2,…,ln),li∈L,1≤i≤n。其中lk=(xk,yk,tk)表示轨迹Tr在时刻tk的位置为(xk,yk),t1 定义2 (k-匿名轨迹)在发布的轨迹数据集中,对任意一条轨迹满足至少存在其他k-1条轨迹与其不能区分彼此。 定义3 (轨迹的不确定性模型)给定在时间t1和tn之间的轨迹Tr和不确定阈值δ,对于Tr上的每一个点(x,y,t),其不确定区域是以(x,y,t)为圆心,以δ为半径的水平圆盘,其中(x,y)为Tr在时间t∈[t1,tn]的期望位置。将轨迹Tr关于δ的不确定性模型Trp=Vol(Tr,δ),表示在时间t∈[t1,tn]内所有圆盘的集合。 定义4 (轨迹之间的距离)轨迹Tr1和Tr2在t时刻的距离为: Dist(Tr1[t],Tr2[t])= (1) 则在时间范围[t1,tn]内,轨迹Tr1和Tr2的距离为: (2) 定义5 (轨迹相似性)在时间范围[t1,tn]内,称轨迹Tr1和Tr2为相似轨迹当且仅当对于∀t∈[t1,tm],都有Dist((x1,y1),(x2,y2))≤δ。其中Dist表示轨迹Tr1、Tr2距离,(x1,y1)、(x2,y2)分别表示t时刻Tr1和Tr2上的位置。 轨迹δ同位:设Tr1、Tr2为定义在时间区间[t1,tn]内的两条轨迹,当且仅当Tr1上的每个点(x1i,y1i,ti)(1≤i≤n)和Tr2上的每个点(x2i,y2i,ti)(1≤i≤n)均满足Dist((x1i,y1i),(x2i,y2i))≤δ,则称Tr1、Tr2关于δ同位,记为Colocδ(Tr1,Tr2)。 定义6 ((k,δ)-匿名模型)给定不确定性阈值δ和匿名阈值k,轨迹集合D满足(k,δ)-匿名当且仅当|D|≥k,且D中任意两条轨迹Tr1、Tr2均满足Colocδ(Tr1,Tr2)。 本文提出基于敏感性分级的(k, δ, ai)-匿名模型。对个人隐私而言,不同的位置往往具有不同的敏感性。例如:赌场这类位置的敏感性远高于商场这类一般的位置。因此,要实现更好地隐私保护,就需要对敏感位置进行敏感性分级。根据其语义敏感性由高到低分为分为L1,L2,…,L5,敏感位置等级分类如表3所示。在实现(k, δ, ai)-匿名分组时,首先应该避免具有相同级别敏感值的记录分在同一组。 (1)轨迹同步化处理(预处理) 将原始轨迹数据库D划分为若干轨迹数据集合,使得任意集合中的轨迹具有相同的起点、终点及相同的时间间隔,同步化处理后的轨迹数据库记为Dt。 算法1:Pre⁃proc(D,π)输入:原始数据库D,整形参数π输出:同步轨迹数据库DtStep1.for∀Tr∈D{Step2. Let[tb,te]bethetimespanofπ;Step3. i=min{t|t≥tb∧tmodπ=0};Step4. j=max{t|t≤te∧tmodπ=0};Step5. ifi£j{Step6. Tr′=Tr[i,j];Step7. insertTr′inD[i,j];Step8. }Step9.}Step10.Dt=∪{D[i,j]|imodπ=0∧jmodπ=0};Step11.returnDt; (2)同步轨迹聚类处理 将Dt中的轨迹划分为若干等价类,使得每个等价类中至少包含k条轨迹,并且类半径小于max_radius。同步轨迹聚类后的轨迹数据库记为Dc。 算法2:SL⁃NWAclust输入:同步轨迹数据Dt,匿名阈值k,参数Trashmax输出:各聚类组CStep1.Initialize(max_radius);Step2.While(|Trash|>Trashmax){Step3. Active=Dt;Cluster=ϕ; Pivots=ϕ;Trash=ϕ;Step4. Trp=averagetrajectoryofDt;Step5. While(Active≠ϕ){Step6. Trp=argmaxTr∈ActiveDist(Trp,Tr);Step7. CTrp={Trp}∪{2k-1nearestneighborsofTrpinDCluster};Step8. While(k≠0){Step9. if|sensitivedata| Step22. CTrp=Step23. argminTr′∈PiontsDist(Tr′,Tr)Step24. if(Dist(Tr′,Tr)≤max_radius)Step25. CTrp=CTrp∪{Tr};Step26. elseTrash=Trash∪{Tr};Step27.}Step28. increase(max_radius);Step29.}Step30.return{CTrp|Trp∈Pivots}; (3)轨迹空间平移处理 将不在以类中心为圆心,δ为半径的圆柱内的轨迹平移到圆柱的边缘,空间平移处理后的轨迹数据库记为D′。 数据匿名化处理会造成原始数据的信息损失,使得数据的可用性降低,因此,匿名化算法的研究目标是在保证数据安全的前提下,尽可能地减少数据的信息损失。目前,可以从两个方面——安全性和可用性对数据质量进行评估。其中,匿名数据对信息的保护能力可用安全性进行评估;匿名轨迹所包含原始轨迹的信息程度可以用可用性进行评估。 由于同一敏感级别位置之间的关联性比较大,如果将隐私级别相同的轨迹聚类在同一等价类中,将导致敏感信息的披露,从而导致匿名数据安全性降低。因此,轨迹匿名化算法需要尽可能地将不同级别的位置点聚类在同一等价类中。 设等价类中含有n条轨迹,则同一等价类中时刻t的敏感性差异可以表示为: (3) 其中,Wai表示第i条轨迹和第j条轨迹之间级别距离的权重,ai=max(Li,Lj),设Wai={0.85, 0.9, 0.95, 1},即级别5到级别1,2,3,4的权重都为1;级别4到级别1, 2,3的权重都为0.95;级别3到级别1, 2的权重都为0.9,级别2到级别1的权重为0.85;Cij=|Li-Lj|。 那么,同一等价类中的敏感性差异可以表示为: (4) 其中,|CTrp|=n表示等价类中的轨迹数,则匿名数据库D′的敏感性差异为: (5) 其中,|D′|表示匿名数据库中等价类个数,并且敏感性差异(Ds)的值越大,安全性越好。 本文主要用信息失真来评估匿名数据的可用性。 定义7 (信息损失量)原始轨迹Tr在时刻t的三元组为(x,y,t),匿名化处理后形成的匿名轨迹Tr′在相应的时间t的三元组为(x′,y′,t),则此匿名产生的时空信息损失量可以表示为: IDt(Tr[t],Tr′[t])= 其中,(x,y)、(x′,y′)分别为轨迹Tr和Tr′在t时刻的位置;Ω是一个常数,是对删除位置的信息损失的惩罚。那么,整条匿名轨迹Tr′关于其原始轨迹Tr的信息损失量为: ID(Tr,Tr′)= 其中,T是轨迹Tr中包含的所有时间点集。n=|T|表示轨迹Tr的位置数。 那么,匿名轨迹数据库D′相对于原始数据库D的总信息损失量为: 实验采用的数据集由Brinkhoff移动对象数据生成器[15]基于德国奥尔登堡(Oldenburg)市地图产生。该数据集表示奥尔登堡一天的移动数据,Brinkhoff移动对象数据生成器可以在http://www.fh-oow.de/institute/iapg/personen/brinkhoff/generator/中下载。表4为数据集的统计信息。其中,|D|表示轨迹条数,|Points|表示采样点个数,|Dt|表示预处理后等价类个数,MBB(Minimum Bounding Box)radius表示数据库D中最小覆盖矩形对角线的一半,File_size表示数据文件大小。 表4 实验数据集信息 实验环境为:Intel(R) Core(TM) i5-5200U CPU @ 2.20 GHz;4 GB内存;Windows 8操作系统;算法由C编写,所涉及的代码在VMware Workstation10.0下的Ubuntu中实现。 敏感性差异值是基于3.1节敏感性差异公式计算得到的,NWA算法将离聚类中心最近的k-1条轨迹加入到同一等价类中,而本文提出的SL-NWA算法需要考虑敏感位置的级别,使得同一时刻处于同一敏感级别的位置点的概率不大于1/l,从而提高隐私保护的有效性。图1分别是δ=600和δ=2 000时两种算法的敏感性差异值,实验结果表明SL-NWA算法比NWA算法的敏感性差异更大,即SL-NWA算法更安全。 图1 敏感性差异 基于3.2节信息失真标准,本文将(k, δ, ai)-匿名模型提出的SL-NWA算法与(k, δ)-匿名模型提出的NWA算法进行对比,图2是δ=600、δ=1 000,δ=2 000和δ=3 000时,两种算法的总信息损失量。实验结果表明两种算法的总信息损失量均随k值的增大而增大,随δ值的增大而减小。并且随着δ的增大,SL-NWA算法的信息损失与NWA算法的信息损失越来越接近。 本文提出基于敏感性分级的(k, δ, ai)-匿名模型,通过划分敏感性等级来描述它们的敏感性差异,该模型需要满足所发布的轨迹数据库中任意轨迹在其半径为δ的圆柱内被重新标识出的概率不大于1/k,并且同一时刻处于同一敏感级别的位置点不超过k/l。但是该算法并不能总是把敏感属性值级别差异较大的轨迹聚类在同一等价类中。下一步要尽可能把敏感属性值级别差异较大的轨迹聚类在同一等价类中,进一步提高匿名数据的安全性。 图2 总信息损失量 [1] 郑永星.轨迹发布中的隐私保护研究[D].福州:福建师范大学,2016. [2] 霍峥,孟小峰.轨迹隐私保护技术研究[J].计算机学报,2011,34(10):1820-1830. [3] 郑路倩,韩建民,鲁剑锋,等.抵制时空位置点链接攻击的(k,δ,l)-匿名模型[J].计算机科学与探索,2015,9(9):1108-1121. [4] TERROVITIS M, POULIS G, MAMOULIS N, et al. Local suppression and splitting techniques for privacy preserving publication of trajectories[J]. IEEE Transactions on Knowledge & Data Engineering, 2017, 29(7):1466-1479. [5] 翁国庆.隐私敏感轨迹数据发布技术研究[D].南京:东南大学,2014. [6] 贾明正.面向数据发布的轨迹隐私保护技术研究[D].成都:西南交通大学,2016. [7] 许志凯,张宏莉,余翔湛.轨迹隐私保护研究综述[J].智能计算机与应用,2017,7(1): 125-127. [8] 胡兆玮,杨静.轨迹隐私保护技术研究进展分析[J].计算机科学,2016,43(4):16-23. [9] TERROVITIS M, POULIS G, MAMOULIS N, et al. Local suppression and splitting techniques for privacy preserving publication of trajectories[J]. IEEE Transactions on Knowledge & Data Engineering, 2017, 29(7):1466-1479. [10] Li Meng, Zhu Liehuang, Zhang Zijian, et al. Differentially private publication scheme for trajectory data[C].IEEE International Conference on Data Science in Cyberspace. IEEE, 2017:596-601. [11] 王爽,周福才,吴丽娜,等.移动对象不确定轨迹隐私保护算法研究[J].通信学报,2015, 36(s1):94-102. [12] 朱麟,黄胜波.不确定环境下轨迹k-匿名隐私保护[J].计算机应用,2015, 35(12):3437-3441. [13] ABUL O, BONCHI F, NANNI M. Never walk alone: uncertainty for anonymity in moving objects databases[C].IEEE International Conference on Data Engineering. IEEE Computer Society, 2008:376-385. [14] 金华,张志祥,刘善成,等.基于敏感性分级的(ai,k) -匿名隐私保护[J].计算机工程, 2011,37(14):12-17. [15] BRINKHOFF T.Generating traffic data[J].Bulletin of the Technical Committee on Data Engineering IEEE Computer Society,2003,26:2003.
1 相关定义
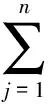
2 (k, δ, ai)-匿名模型及算法
2.1 (k, δ, ai)-匿名模型
2.2 (k, δ, ai)-匿名算法



3 匿名轨迹的质量评估
3.1 安全性评估
3.2 可用性评估


4 实验与分析
4.1 实验数据与环境

4.2 隐私保护有效性分析

4.3 信息损失量分析
5 结论
 猜你喜欢
中国水土保持科学(2022年2期)2022-05-07新高考·高三数学(2022年3期)2022-04-28科技创新与应用(2021年36期)2021-12-11中国煤层气(2020年2期)2020-06-28晚晴(2018年3期)2018-12-06家庭影院技术(2018年5期)2018-06-29家庭影院技术(2018年3期)2018-05-09中文信息(2017年12期)2018-01-27中学生(2017年13期)2017-06-15现代食品(2016年14期)2016-04-28
猜你喜欢
中国水土保持科学(2022年2期)2022-05-07新高考·高三数学(2022年3期)2022-04-28科技创新与应用(2021年36期)2021-12-11中国煤层气(2020年2期)2020-06-28晚晴(2018年3期)2018-12-06家庭影院技术(2018年5期)2018-06-29家庭影院技术(2018年3期)2018-05-09中文信息(2017年12期)2018-01-27中学生(2017年13期)2017-06-15现代食品(2016年14期)2016-04-28
