
Python教学中实用型词频统计案例展示
2018-01-27 05:58:51邓擎琼彭炜明赵世凤王学松
计算机教育 2017年12期
邓擎琼,彭炜明,尹 乾,赵世凤,王学松
(北京师范大学信息科学与技术学院,北京100875)
1 背景
Python语言已经成为国际最受欢迎的程序设计语言,国外众多大学从2009年开始针对该语言广泛开设相关课程。然而国内起步较晚,直到2016年,教育部高等学校大学计算机课程教学指导委员会才首次建议将Python语言作为程序设计入门课程的教学语言[1],近2年来,国内一批高校逐步开设了Python语言教学。由于教学实践时间尚短,国内Python教学中多沿用国外的教学案例或其他程序设计语言的教学案例,其中前者导致教学案例缺乏中国特色,后者导致教学案例缺乏Python特色。例如针对文本词频统计这一问题,国内高校往往使用国外教材或教学中的案例,对莎士比亚的经典作品《哈姆雷特》[2]、古腾堡文学作品[3]、美国总统就职演说等进行词频统计和分析,显然这样的教学案例远离中国大学生的学习和生活,因此缺乏吸引力。再如在Python循环结构的教学中,国内高校往往还以闰年判断、打印水仙花数等问题作为案例[4],这些问题既不是学生关心的问题,也不是热点问题,因此也很难给学生留下深刻印象。
而另一方面,Python有强大的计算生态环境,全球有超过十万个第三方库,几乎覆盖所有技术领域[5]。依托这样的生态圈,国内高校中从事Python教学的老师可以便捷高效地创建出新的教学案例。什么样的教学案例能引起学生的共鸣,这是一个值得思考的问题。针对上述国内Python教学案例中的问题,依托Python强大的计算生态环境,我们提出了Python实用型案例教学方法。一是通过分析大学生在学习和生活中遇到的实际问题,构建相应的教学案例;二是针对热点问题、热点资讯构造教学案例。这些案例不仅能让学生感知Python计算生态圈的功能之强大和多样,更能增强学生程序设计学习兴趣,激发学生自主学习和运用Python计算生态,最终提高实际解决问题的能力。
本文具体针对词频统计问题,给出了两个教学案例。一是针对大学英语四、六级考试,通过对历年试题分析获得其中的高频词,辅助学生进行英语复习;二是在中央电视台科教频道大型文化益智节目《中国诗词大会》的引领下,带动学生对不同诗人、不同朝代以及不同风格的诗词进行比较,从中分享诗词之美,感受诗词之趣。
2 大学英语四、六级考试高频词分析
我们对大学英语四、六级历年考试真题进行分析,从中挖掘出常考词。这一案例对学生吸引力非常大,且案例运行结果实用性强,能辅助学生进行复习,提高考试成绩。
该案例是一项综合性案例,展示了Python多个知识点的运用,包括:首先利用Reqests和Beatifulsoup两个Python第三方库爬取相关网页获得英语考试历年考题以及四、六级词汇表;然后对试题文本进行规范化处理,得到其中的四级或六级单词,并进行词频统计;最后把词频统计结果保存为CSV文件,并利用Matplotlib库对高频词及每年出现次数进行直观显示。下面以英语六级考试为例,详细介绍该案例的具体实现过程及结果。
2.1 历年试题及词汇表的获取
很多英语学习网站,如新东方在线、沪江英语等都提供历年考试真题和单词词汇表。通过比较这些网站,最终我们选择在http://www.233.com/cet4/zhuanti/linianzhenti/上爬取2014年6月至2016年12月的考试真题,以及在http://cet6.koolearn.com/20160210/796642.html上爬取词汇表。原因是上述两个网站资料相对齐全且分类整齐,利于进行网络数据获取。在获取过程中主要用到requests.get()和BeautifulSoup中的find()方法。其中前者用于得到网页内容,后者用于从网页内容中解析和获取需要的数据。为便于后续分析,在爬取每一年的试题数据后,把该数据保存为txt文件,存在本地磁盘。单词词汇表数据做同样处理。
2.2 试题中的六级单词提取
通过上述步骤获得的试题书写很不规范,里面含有很多中英文标点符号、中文字符等,且不同句子间经常无空格分开,因此需要对这些文本进行规范化处理。此外,英语单词存在各种形态变化:动词的多种时态(过去时、过去完成时、一般现在时和现在进行时)、名词复数形式、形容词比较级等。而六级词汇表中保存的都是单词原型,如动词为一般现在时态、名词为单数形式等。因此,单词提取还包括一个“词形还原”的过程,即对不同时态变化的动词、复数名词、比较级形容词等进行还原处理,得到原型单词(即词元)。之后再判断该单词是否为六级单词,如果是则保存至一个列表;不是则摒弃。词形还原在自然语言处理中非常常见。常用第三方模块NLTK来处理。处理过程一般为:首先用字符串的split()方法或NLTK提供的分句工具(例如punktsentencesegmenter)把整套试题分解成一个一个的句子,然后对每一个句子用NLTK提供的工具(例如word_tokenize和pos_tag)对其进行分词和词性标注,得到该句子中的每一个单词和它的词性,之后对每个单词根据其词性采用NLTK提供的词性还原工具(例如WordNetLemmatizer)得到对应的词元。这样得到的词元很准确,但国内大多数高校将Python是作为入门语言进行教学,上述NLTK模块的实现有些难度,因此可根据教学情况采用简化方法。例如,可采用字符串的方法对一般化变形的动词和名词实现词形还原,具体代码如下:
importstring
defloadExamp(fname):#fname为一套txt试题文件
withopen(fname,'rt',encoding='UTF-8')asf:
text=f.read().lower()
lst=[]#lst保存试题中包含的六级单词
text=text.replace('--','')
text=text.replace('(','')
text=text.replace(')','')
text=text.replace('?','')#去除无空格分割的标点符号
wordlist=text.split()
forwordinwordlist:
word=word.strip(',。:、!“”‘’{}【】()')#去除中文标点符号
word=word.strip(string.punctuation)#去除英文标点符号
ifwordincet6:
#cet6为六级单词列表,下面为词形还原过程
lst.append(word)
elifword.endswith(('s','ed'))andword[0:-1]incet6:#例works→work、liked→like
lst.append(word[0:-1])
elifword.endswith(('es','ed'))andword[0:-2]in cet6:#例boxes→box、worked→work
lst.append(word[0:-2])
elifword.endswith('ing'):
ifword[0:-3]incet6:lst.append(word[0:-3])#例:working→work
elifword[0:-3]+'e'incet6:lst.append(word[0:-3]+'e')#例:liking→like
elifword.endswith(('ies','ied'))andword[0:-3]+'y'incet6:
lst.append(word[0:-3]+'y')#例:studies、studied→study
returnlst
该过程也可采用Python中的标准模块——re模块来实现,这样会更简洁,具体代码如下:
importre
defloadExamp(fname):#fname为一套txt试题文件
withopen(fname,'rt',encoding='UTF-8')asf:
text=f.read()
lst=[]#lst保存试题中包含的六级单词
forwordinre.findall('[A-Z]?[a-z]+',text):
#提取英语单词
word=word.lower()
ifwordincet6:#cet6为六级单词列表
lst.append(word)
else:#词形还原后再判断是否为六级单词
forrulein[('(s|e[ds]|ing)$',''),('(e[ds]|ing)$','e'),('ie[sd]$','y')]:
stem=re.sub(rule[0],rule[1],word)
ifstemincet6:
lst.append(stem)
break
returnlst
2.3 六级单词词频统计
在得到每一年试题中所出现的六级单词列表之后,统计单词频率就变成很简单。同样,有多种实现方式,具体代码如下所示:
#wordDec保存词频统计结果,examList为每份试题中出现的六级单词列表,cet6为六级单词列表
#方法1
wordDec={}
forwincet6:
wordDec[w]=examList.count(w)
#方法2
wordDct=dict.fromkeys(cet6,0)
forwinexamList:
wordDct[w]+=1
#方法3
fromcollectionsimportCounter
wordDct=Counter(examList)
其中方法1和方法2采用字典和列表实现,方法3则采用标准库collections中的Counter类实现。相比之下,方法1效率低,不推荐使用。在每一年试题的六级单词词频的基础上,进一步计算平均词频,然后采用Python内置函数sorted()根据平均词频从高到低进行排序,排在前面的单词即为近几年考试中的高频词。当然,实现方法不限于上述3种,例如还可采用Python第三方模块Pandas,把每一年试题所用的六级单词列表作为一个Series对象,然后采用value_counts()方法可得到词频,并把所有年份的词频结果制成一张表格,即一个DataFrame对象,之后采用其apply()方法作用到表格的每一行得到平均词频,最后采用sort_values()方法根据平均词频对所有行进行逆序排序,具体代码如下:
importpandasaspd
examPd=pd.DataFrame(meanList,columns=['词义',],index=cet6)#meanList为词义列表
examPd.index.name='单词'
fori,examListinenumerate(examLists):
#对历年试题做词频统计,统计结果保存为表格中的一列
tempPd=pd.Series(examList)statistic=tempPd.value_counts()
examPd[examFileName[i]]=statistic
#examFileName为历年试题对应的文件名列表
filledExamPd=examPd.fillna(value=0)
iflledExamPd['平均次数']=filledExamPd.iloc[:,1:].apply(lambdax:x.sum()/fileNum,axis=1)
sortedExamPd=filledExamPd.sort_values(by='平均次数',ascending=False)
2.4 词频统计结果保存和展示
把根据平均词频逆序排序后的历年词频统计结果和平均词频以csv文件格式保存在本地磁盘中。csv是逗号分隔符文本格式,常用于Excel和数据库的数据导入和导出。Python标准库中的csv模块提供了读取和写入csv格式文件的两个对象:csv.reader和csv.writer。在本案例中,可利用csv.writer对象中的writerow()和writerows()方法分别写入一行或多行数据。也可直接采用第三方模块Pandas的DataFrame对象的to_csv()方法,更便捷地保存表格数据。文件保存结果如图1所示,文件中的第一列是单词,第二列是词义,中间列是历年试题的词频统计结果,最后一列是平均词频。
为更直观地呈现结果,本案例通过第三方模块Matplotlib采用柱状图的方式对高频词及每年出现次数进行展示。如果统计结果表示成一个Pandas的DataFrame对象,则直接用该对象的plot(kind='bar')方法进行柱状图绘制,因为Pandas整合了matplotlib的pyplot模块中的函数,提供了专门用于Series和DataFrame对象的绘图功能。图2展示了平均词频最大的三个单词近年来的各自使用次数。进一步,经过统计得到:在所有试题中都出现了的单词只有两个:correspond和given,而近年来在试题中出现过的六级单词,即平均词频不为0的单词有855个。

图1 六级单词词频统计保存结果
3 古诗字频统计及可视化展示
随着央视首档全民参与的诗词节目《中国诗词大会》的热播,高校重新刮起了一股文化清风,学生对各诗人们的诗词和风格、古人行酒令时的文字游戏“飞花令”等产生了浓厚的兴趣。为此,我们设计了古诗字频统计及可视化展示案例。中国古诗,无论篇幅短长,用字的凝练都是非常讲究的。诗人在择取意象、推敲用字时,由于其时代背景、生活经历的不同,通常会表现出特定的偏好,形成不同的风格。因此,可以通过对不同诗人用字情况的对比分析来窥探诗人的诗风。对于计算机专业背景的大学生来说,这是以理科方法来研究文科内容的尝试,文理交叉,学以致用。下面以李白、杜甫为例,详细介绍古诗字频统计及其可视化展示的案例实施过程。
3.1 古诗获取及文本预处理
中国古诗浩如烟海,能够浏览和下载古诗文本的网站也很多。采用类似2.1节的方法,我们可以得到大量分类整理的古诗文本,将其按作者姓名分别存放在不同的文件目录中。爬取后网页文件后除了需要进行一般的文本化处理(去除HTML标签)外,还应注意文本中可能存在的一些注释内容。例如,在李白《将进酒》的文本中混有“与君歌一曲,请君为我倾耳听。(倾耳听一作:侧耳听)”,括号中内容即为字频统计的噪声,可利用re模块对此噪声进行删除。处理后的各诗人的作品分别保存为CSV文件。其中文件内容包括诗词名、朝代、作者、诗词内容以及诗词风格标签,如图3所示。

图3 李白诗集保存结果
3.2 古诗字频统计和词云展示
相对于四、六级单词词频统计,古诗字频统计更为简单。对每一位诗人,首先把他(她)的每一首诗词内容中的每一个汉字添加至一个汉字列表,然后把该汉字列表通过转化成字典等方法得到不重复汉字集合,最后再通过2.3节中介绍的词频统计方法得到该诗人的字频统计结果。值得注意的是,不同诗人的作品数量差别较大,因此我们对词频统计结果进行了归一化处理,即除以诗人的作品数量。图4分别显示了李白和杜甫的前十个使用最频繁的字及归一化后的字频。
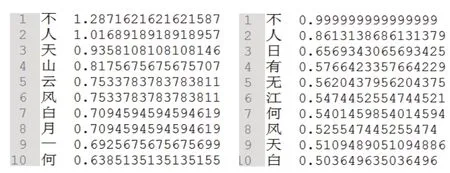
图4 李白(左)和杜甫(右)的前十个高频字和对应的字频

图5 李白(左)和杜甫(右)的词云绘制结果
为更进一步对高频词予以视觉上的突出,我们利用Python第三方库wordcloud构建了词云。wordcloud库功能强大,且简单易用。首先构建一个WordCloud对象,注意由于显示的是中文,因此需要在构建该对象时,设置font_path为支持中文的字体的路径,例如在Windows系统下,font_path可以为'C:WindowsFontssimsun.ttc';然后把上节中得到的词频统计结果作为参数传递给WordCloud对象的fit_words()方法;最后采用matplotlib.pyplot.imshow()函数进行显示即可。李白和杜甫的词云绘制结果如图5所示。
3.3 李、杜用字习惯比较
可把李白和杜甫两位诗人的诗词中的高频字分别用一个Python集合类型表示,然后采用集合操作对两位诗人的用字习惯进行比较:两个集合的交即为两位诗人都爱用的字;两个集合的差即为其中一位诗人爱用而另一位诗人不爱用的字。
为进一步比较两位诗人的诗风,可求解两人字频差异最大的一些字。首先通过两个集合的交集得到两位诗人总共喜欢的字,然后对其中的每一个字,求两位诗人的字频差异的绝对值,最后根据该值进行逆序排序,排在前面的即为两位诗人用字习惯差异最大的字。为直观地显示这些字以及对应的字频,可采用Matplotlib柱状图的方式进行绘制,其中差异最大的前10个字的结果如图6所示。
3.4 扩展
为了更加有效地统计、比较并直观显示不同诗人的用字习惯,同时如“飞花令”游戏中那样对特定汉字实现诗句链接,我们对上述教学案例做了进一步的扩展。首先,词云的可视化展示改用基于Web的网页形式,这样可以对其中的汉字添加HTML链接。此外,为了方便程序模块的升级,把图3所示的表格数据都导入sqlite3数据库(数据库名:peoms.db,表名:gushi),通过数据库查询来实现可以提高程序的可扩展性,具体实施步骤如下。
3.4 .1可视化环境布置与工具介绍
可视化页面采用标签云插件jQCloud(https://github.com/lucaong/jQCloud)作为呈现工具,首先设置一个top-left-right的三分屏框架主页面index.htm,分别链接top.htm(作为标题显示对比诗人的姓名)、left.htm(用于显示左侧诗人的用字情况)和right.htm(用于显示右侧诗人的用字情况),如图7所示。为了使Python程序逻辑与页面显示逻辑分离,将诗词用字统计的结果数据写入单独的两个js文件(data-left.js和dataright.js),在left.htm和right.htm两个页面中分别导入。
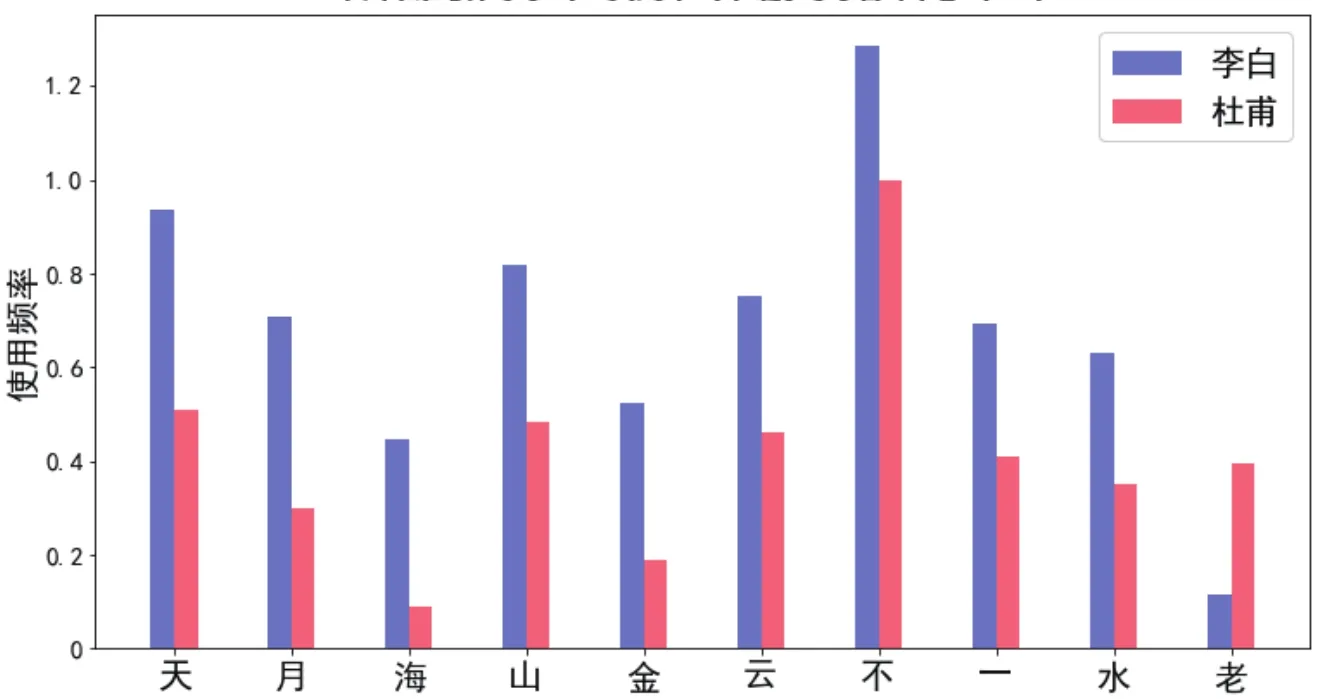
图6 李白和杜甫字频差异最大的10个字

图7 李白/杜甫诗词的用字对比
以left.htm为例,其HTML代码如下:
lt;htmlgt;
lt;headgt;lt;metahttpequiv="Content-Type"content="text/html;charset=utf8"/gt;
lt;linkrel="stylesheet"type="text/css"href="css/jqcloud.css"/gt;
lt;scripttype="text/javascript"src="js/jquery-1.4.4.js"gt;lt;/scriptgt;
lt;scripttype="text/javascript"src="js/jqcloud-1.0.4.js"gt;lt;/scriptgt;
lt;scripttype="text/javascript"src="data-left.js"gt;lt;/scriptgt;
lt;scripttype="text/javascript"gt;
$(function(){$("#chars").jQCloud(char_list);});
lt;/scriptgt;
lt;/headgt;
lt;bodygt;
lt;centergt;lt;divid="chars"style="width:480px;height:
64 0px;border:1pxsolid;"gt;lt;/divgt;lt;/centergt;
lt;/bodygt;
lt;/htmlgt;
3.4 .2字频统计与格式化输出
数据文件格式需求如下:以上节HTML中的data-left.js为例,即按JSON格式列出李白诗字频率相比杜甫诗字频率偏高的部分。其中每行属性说明如下:text为诗中用字,weight为字频差(Freq(李白)-Freq(杜甫)),link为该字具体诗句的链接页面。
varchar_list=[
{text:"月",weight:0.00353834280190,link:{href:"poem/李白-月.htm",target:"_blank"}},
{text:"天",weight:0.00344150700915,link:{href:"poem/李白-天.htm",target:"_blank"}},
{text:"海",weight:0.003176168221019,link:{href:"poem/李白-海.htm",target:"_blank"}},
{text:"金",weight:0.00287300721580,link:{href:"poem/李白-金.htm",target:"_blank"}},
{text:"山",weight:0.002688791184576,link:{href:"poem/李白-山.htm",target:"_blank"}},
……(此处省略更多)
];
生成该数据文件的Python代码及相关注释如下:
importre
importsqlite3
fromcollectionsimportCounter
cxn=sqlite3.connect("./peoms.db")
defcharfreq(poet):#统计某位诗人的所有诗中汉字分布的频率,poet为诗人名字
counter=Counter()
regex_han=re.compile(r'[u3400-u9fff]')#匹配汉字的正则表达式
cur=cxn.cursor()
cur.execute("selectbodyfromgushiwhere authorname=?",(poet,))forrowincur:
counter.update(regex_han.findall(row[0]))#Counter.update()实现动态更新频次计数
freqsum=sum(counter.values())#总频次
forcharincounter.keys():counter[char]/=freqsum#计算字的分布频率
returncounter defcharcloud(poet_left,poet_right):#求词频差,并生成词云
cnter_left=charfreq(poet_left)
cnter_right=charfreq(poet_right)
withopen('data-left.js','w',encoding='utf8')asf_left:
f_left.write('varword_list=[ ')
forchar,freqin(cnter_left-cnter_right).most_
common(200):#Counter对象支持求差运算,只取前200个相对频率差高的,为诗人偏好用字。f_left.write('{{text:"{}",weight:{}}}, '.format(char,freq))
f_left.write(']; ')
withopen('data-right.js','w',encoding='utf8')asf_left:
f_right.write('varword_list=[ ')
forchar,freqin(cnter_right-cnter_left).most_common(200):f_right.write('{{text:"{}",weight:{}}}, '.format(char,freq))
f_right.write(']; ')
charcloud('李白','杜甫')
程序实现模块化后,可以很方便地比较任意两个诗人的用字,李白、杜甫的比较页面如图7所示。
3.4 .3生成特定汉字的诗句链接页面(“飞花令”效果)
最后一步,为标签云中的每个用字添加链接,点击后可以查看诗人使用该字的具体诗句及出处。因此,修订函数charcloud()中的部分代码,此处仅展示data-left.js文件的生成部分,如下:
forchar,freqin(cnter_left-cnter_right).most_common(200):
f_left.write('{{text:"{0}",weight:{1},link:{{href:"poem/left-{0}.htm",target:"_blank"}}, '.format(char,freq))#输出数据中增加链接
gen_verse(poet_left,char)
#调用函数,生成诗人特定用字的诗句列表,详下#函数gen_verse()定义如下:defgen_verse(poet,char):
withopen('poem/{}-{}'.format(poet,char),'w',encoding='utf8')asfout:
cur=cxn.cursor()
forrowincur.execute("selectbodyfromgushi
whereauthorname=?andbodylike?",(poet,'%{}%'.format(char))):
forlinein[xforxinre.split(r'[ 。?!]',row[0])ifcharinx]:
fout.write('lt;pgt;{}lt;/pgt; '.format(line).replace(char,'lt;spancolor="blue"gt;{}lt;/spangt;'.format(char))+'lt;palign="right"gt;——{}《{}》lt;/pgt;lt;/divgt; '.format(poet,fname[0:-4]))
#诗句(高亮显示汉字char)——诗人《出处》
以李白诗中的“海”字为例,具体显示效果如图8所示。
3.4 .4不同朝代及不同风格诗词比较
由于我们的诗词数据采用sqlite3数据库进行保存,同时每一条数据还包含朝代和诗词风格标签信息,因此,采用类似2.4.2的方法,我们很容易提取出不同朝代或不同风格的诗词数据,然后生成对应的标签云,如图9和图10所示,从而对不同朝代或风格的诗词进行比较。
4 案例的灵活运用
本文给出的两个案例均为综合性案例,涉及Python教学中的多个知识点以及多个标准模块和第三方模块,且有些功能有多种实现方式。因此,可以作为学期末大作业示范案例,也可在学期中根据教学进度进行灵活拆分和运用。例如,在学习字符串、字典等Python内置数据结构时,可把某一年的试题或李白、杜甫若干首诗作为一个长字符串进行词频统计练习;在学习文件读写时,可把每一年的试题或李白、杜甫诗集作为一个文本文件进行读操作练习,并通过保存词频统计结果进行写操作练习;在学习网络爬虫时,可练习从相关网站上爬取这些内容等。
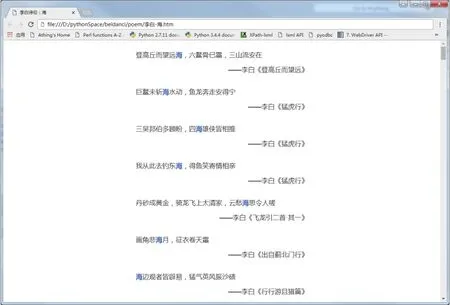
图8 “海”字的诗句链接页面

图9 不同朝代诗词的用字对比

图10 不同风格诗词的用字对比
5 结语
基于Python强大的计算生态环境,本文提出“Python实用型案例教学”的观点,并具体针对词频统计问题,给出了大学英语四、六级考试高频词求解和可视化展示案例以及古诗词字频统计及可视化展示案例。这两个案例都贴近大学生的学习和生活,不仅能让学生感知Python计算生态圈的功能之强大和多样,更能增强学生程序设计学习兴趣,引导学生自主学习和运用Python计算生态,把解决实际生活和学习中的具体任务作为学习的最终目标,最终提高解决实际问题的能力。上述教学理念和案例在北京师范大学计算机专业2个学期课堂教学实践中运用,取得了良好的教学效果。后续工作中,如何针对其他不同专业的应用需求,设计实用性和个性化并存的教学案例将是下一步Python教改重点。
[1]教育部高等学校大学计算机课程教学指导委员会.大学计算机基础课程教学基本要求[M].北京:高等教育出版社,2017.
[2]嵩天,礼欣,黄天羽.Python语言程序设计基础[M].2版.北京:高等教育出版社,2017:171-174.
[3]中国大学MOOC.用Python玩转数据[EB/OL].[2017-10-05].http://www.icourse163.org/course/NJU-1001571005.
[4]江红,余青松.Python程序设计教程[M].北京:清华大学出版社、北京交通大学出版社,2014:44,61.
[5]嵩天,黄天羽,礼欣.面向计算生态的Python语言入门课程教学方案[J].计算机教育,2017(8):7-12.
猜你喜欢
国际医药卫生导报(2022年5期)2022-03-18 08:40:02
园林科技(2021年3期)2022-01-19 03:17:48
汉字汉语研究(2021年1期)2021-06-11 01:15:02
蚌埠医学院学报(2020年1期)2020-12-11 23:11:44
文苑(2018年22期)2018-11-19 02:54:38
文苑(2018年18期)2018-11-08 11:12:44
戏剧之家(2016年5期)2016-04-05 16:24:41
辽金历史与考古(2016年0期)2016-02-02 01:34:22
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
