
机器学习算法原理及效率分析
2018-01-26 04:58中国人民大学附属中学葛恭豪
电子世界 2018年1期
中国人民大学附属中学 葛恭豪
一、引言
上个世纪五十年代,人工智能的概念首先在Dartmouth学会上被提出,之后却由于众多技术的限制而未能得到很好的发展。自进入21世纪,人工智能进展飞速。Siri、AlphaGo等众多新事物进入了人们的生活,人工智能也逐渐成为普通人生活的一部分。
二、常用算法及原理简介
1.朴素贝叶斯(Naive Bayes classifier,NB)
NB分类器是线性分类器,它以贝叶斯定理为依据,时间效率高,常用于大规模数据处理。贝叶斯定理即根据先验概率求后验概率,表达式为:

可预测未知样本x所属类别的可能性,选择其中可能性大的作为x的类。
2.k-近邻(k-Nearest Neighbors,KNN)
KNN是线性分类方法,简单高效。它找出未知样本x周围最近的k个样本作为近邻,针对这k个样本,将x归类为多于k/2数量样本的类。
3.逻辑回归(Logistic Regression)
LR是一种十分强大的线性分类算法,它根据LR模型对数据进行处理,它可以处理有多个解释变量的数据。LR处理数据时先建立二项式模型,再进行概率估计。
4.决策树(Decision Tree,DT)
DT可用于回归预测,处理数据时,它会构建一种非常直观的树状结构对样本进行分类,依特征对样本分类,目标是构建最优的决策树。DT算法系统化、结构化,可找出属性和类别之间的关系,并预测出未知类别。
5.随机森林(Random Forest,RF)
RF处理数据时,会通过矩阵创建多棵决策树,将数据投入决策树中。决策树分类后,依据被预测最多的类属决定最终分类结果。
6.梯度提升决策树(Gradient Boosting Decision Tree,GBDT)
GBDT是基于决策树的线性回归算法,与随机森林类似,由多棵决策树组成,处理结果为多棵决策树结果。GBDT中的决策树是回归树,因此常被用于回归预测方面。
7.支持向量机(Support Vector Machine,SVM)
SVM是一种非线性的机器学习算法,它旨在寻找一个超平面,将训练数据分开。根据结构风险最小化准则计算,使两类数据边缘部分垂直于超平面的距离最大时,成为最优超平面。通过构造最优超平面,SVM能够高精度地处理数据。
8.人工神经网络(Artificial Neural Networks,ANN)
ANN是近年的研究热点,它是一种类似于生物神经网络的非线性算法,由多个类似于神经元的单元组成。ANN基于风险最小化原则,所以有些缺陷,比如易陷入局部极小等。
三、机器学习评价指标
1.分类算法的指标
(1)精确率与召回率

(3)ROC曲线和AUC
ROC曲线适用于二分类问题,它描述了分类器分类正确的正样本个数占总正样本个数的比例。ROC曲线下的面积越大则分类器效果越好。AUC指的是ROC曲线下的面积,AUC的值就是ROC曲线下部分的面积大小。
(4)支持度和置信度

四、实验
1.数据集
数据集选用MNIST手写数字数据集,数据集分训练集和测试集,用于训练模型和检测结果。其中训练集有60000样本,测试集为10000样本,维度为784。
MNIST训练集由SD-3的30,000个模式和来自SD-1的30,000个模式组成。这60,000个模式训练集包含大约250位作家的手写用例。
2.实验目的及方案
常用的机器学习分类算法中,属于线性的有NB、LR,非线性的有DT、RF。实验的目的是对比它们的时间效率、准确率的情况,得出相应的结论。
基于MNIST数据集,选用pycarm和anaconda平台,调用python的sklearn包里的机器学习算法作测试,然后对比分析。
3.实验结果
kNN、LR、RF、SVM、GBDT准确率都相对较高,从时间效率看,SVM、GBDT时间成本大,这样就显示出kNN、LR和RF的轻便。而NB时间效率最高,但准确率83.69%较低。
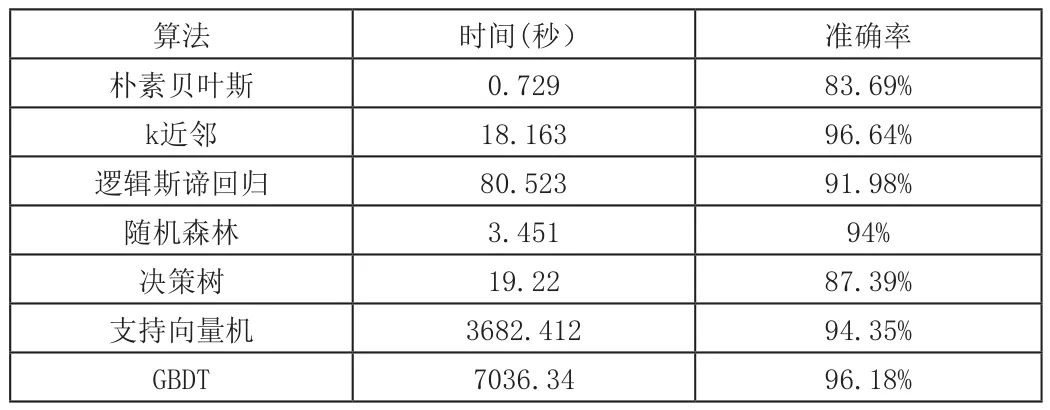
表1 时间和准确率对比
RF的时间效率高,准确率也高;DT结构简单,但处理数据的准确率和时间效率都不高;SVM和GBDT准确率都高,说明非线性算法拟合数据后处理效果好,处理时间分别是3682.412秒和7036.34秒。
原理上,NB算法简单,基于贝叶斯定理对样本的类别进行预测,时间效率高,快过其它,但准确度不高。kNN是寻找未知样本周围的样本,并依据周围样本的分类对未知样本进行分类。因而它比NB计算量大,时间效率低。kNN相比它非线性算法较快,准确率高。
LR算法的准确率为91.98%,比NB、DT高,但比其它算法低。它运行时间为80.523秒,因为计算量较大,比其它线性分类算法慢,但比SVM和GBDT快。综合分析,线性分类算法优势在于时间效率高,非线性的结果更好,能更好地拟合数据。究其原因,在于线性分类算法对特征的依赖较多,它要求数据的特征线性可分,线性分类算法时间效率高。
线性分类算法需要更多的数据预处理工作,预先选择特征、变换特征或者组合特征,使得特征可区分。而非线性分类算法相当于集成了数据的预处理工作,通过自身的建模,对非线性数据也能展示良好的处理性能。
五、总结与展望
本文介绍了8种常用的机器学习算法和11种效果评估指标。不同算法在相同的环境内的效果也都不一样。用来评价算法效果的方法有很多种,各种方法反映出各种算法的优缺点也各不相同。
通过实验对比不同的算法在基于MNIST数据集的情况下的准确度和时间效率。如果继续研究,可以选取更多的算法,并使其基于更多的数据集,例如Car Evaluation、Wine、Adult等。如果想要获得更全面的实验结果,可以用更多的机器学习评价指标对实验进行评估。
[1]张晓芳,张磊.论机器学习及其在教育中的应用[J].信息与电脑:理论版,2015(24):165-166.
猜你喜欢
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
成都信息工程大学学报(2019年3期)2019-09-25
数学物理学报(2019年1期)2019-03-21
电子制作(2018年16期)2018-09-26
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
数学年刊A辑(中文版)(2015年1期)2015-10-30
