
基于Apriori改进算法的旅游个性化推荐
2018-01-26 07:32:14徐宏陈焰支艳利张金鹏
微型电脑应用 2018年1期
徐宏, 陈焰*, 支艳利, 张金鹏
(1.昆明理工大学 信息工程与自动化学院, 昆明 650504;2. 云南财经大学 信息管理中心, 昆明 650221)
0 引言
随着互联网的普及发展以及电子商务网站的兴起,利用网络进行在线信息的搜索已经成为旅游者在旅游前获取信息的主要渠道,但是严重的信息过载使得旅游者常常淹没于大量的信息搜索和产品选择当中。旅游个性化推荐系统正是解决这一问题的有效方法,其不仅能为旅游者搜索到符合其需求和偏好的旅游信息,做出旅游决策,也能减少旅游企业的成本,帮助企业盈利[1]。但是旅游推荐系统具有相对于其他推荐项目的特殊性。从四个方面分析,第一,用户的旅游数据信息更复杂;第二,用户在网站进行搜索时,很难准确表达自己的需求;第三,开发者很难获取用户的旅游偏好信息[2];第四,用户的旅游数据更稀疏。Ricci,et[3]也指出,相对于书、电影等低复杂度的推荐系统,保险、金融、旅游等是最为复杂的推荐项目。从四大著名的外文数据库ProQuest、ScienceDirect、Ingenta、Springer中进行相关搜索发现,由于旅游推荐系统的特殊性与重要性,旅游个性化推荐正在成为学术界和产业界研究的热点。
本文通过对国内外推荐系统在旅游领域的应用文献整理,总结了旅游推荐系统相对应其他推荐产品的特殊性;分析了传统旅游推荐系统的一般框架;并针对传统推荐方法在面对这些特殊性时存在的缺陷,提出了一种基MC-Apriori算法的旅游个性化推荐模型,该方法通过MC-Apriori算法对用户搜索和阅览的历史关键词进行频繁集挖掘并向用户推荐符合其兴趣倾向的旅游信息,通过利用收集的康辉旅行社的语料数据测试,证明了本文的推荐方法比传统推荐系统更具有使用价值,并且在此基础上,论证了MC-Apriori算法不仅减少了每次扫描全部数据所需要的开销,而且提高了效率。
1 传统旅游推荐系统
旅游推荐的内容包括游、娱、购、食、住、行六方面的旅游产品。若向用户推荐准确、多样和个性化的旅游产品,需要通过四方面的数据信息:用户需求、用户偏好、约束条件及旅游资源库。用户需求是用户对当前旅游产品的要求,属主观条件,如:用户对住宿条件等要求。用户偏好可以通过分析该用户的历史旅游数据,如用户对旅游产品的评论内容[4]。约束条件值是指影响用户决策的一些外部客观条件,如用户的性别或收入[5]。旅游资源库是旅游领域中的包含属性值[6]的旅游产品,它是分析、产生推荐系统的重要数据之一,如推荐景点可采集景点名称和类别、门票、评分等信息。
在推荐时,有时还要考虑多个产品之间复杂的时空关系[7],因此相比其他产品,旅游数据更复杂,用户更难准确表述自己的需求。而对于开发者来说,很难获取用户旅游偏好信息。而受时间和消费支出等约束条件,用户一年之内实际旅游过的景点屈指可数,用户之间共同旅游的景点更是很少,所以旅游数据更稀疏。而如何挖掘用户的隐藏信息变得更重要。
通过对当前推荐系统在旅游领域的应用文献分析,总结出了旅游推荐系统的一个通用框架。其主要包含4个步骤:旅游产品建模、用户建模、推荐计算,产品展示。通常的推荐方法有基于内容的推荐[8],基于协同过滤的推荐[9],基于知识的推荐[10]和基于社会媒体的推荐[11],并且时间复杂性大于O(m2×n)。如Majid等[12]根据构建的景点库,建立了用户知识偏好矩阵,通过基于协同过滤的方法实现了个性化推荐。而推荐算法的使用存在一些弊端,基于内容的方法推荐的信息范围过于狭窄;对于协同过滤方法,如用户评分数据少,产生数据稀疏性问题;而基于知识的推荐需要挖掘难以获取的领域知识和推理技术;基于社会媒体的技术是将用户的社会关系和其他社会媒体数据运用到旅游推荐当中,但是获取社会信任关系还是当前社会推荐需要解决的问题。相对于其他三种方法,基于协同推荐的方法使用更普遍,本文将此方法和改进的算法进行对比。
根据上述分析,本文提出一种新的面向旅游用户的个性化搜索推荐模型。因为用户需求、产品偏好,以及约束条件可以在用户阅览的旅游信息中反映,所以通过TextRank方法对用户搜索和阅览的历史关键词进行频繁集挖掘,生成用户倾向性词典;然后根据用户当前搜索关键词,利用MC-Apriori算法关联挖掘用户倾向性词典,从而向用户推荐满足其当前兴趣倾向的旅游信息。该模型在保障推荐结果准确、多样和个性的基础上,还解决了旅游个性化推荐面临的特殊问题,提高了效率。
2 相关知识
2.1 TextRank算法抽取文本关键词
TextRank[13]是比较常用的文本关键词抽取方法,该方法实质是一种基于图的排序算法。同一文本中大多数词语都是为表达同一主题,词语与词语之间也存在一定的语义关系,将词语看做图中的顶点,顶点之间通过有向边反映它们之间的关系。基于图的排序算法的基本理论,在具有语义关系的词语之间建立连线构建TextRank模型,根据词语之间的相互“投票”递归计算词语的值,而每个词语值的大小取决于其词语投票分数和投票词自身的值大小,值较大的词语视为重要词语。其中不和任何词语有连线的词语为孤立点。本文通过TextRank方法对用户搜索内容和阅览文本信息进行关键词挖掘。递归计算公式如式(1)。
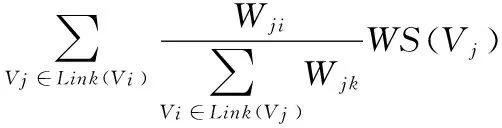
其中,d为阻尼系数,代表从图中某一特定点指向其他任意点的概率,WS(Vi)为顶点Vj即词j的得分,Link(Vi)为与点Vi有连线的点的集合。
2.2 利用word2vec查找语义相似词语
Word2vec[14]是Google于2013年开源的一款将词语表征为实数值向量的高效工具,其利用深度学习(Deep Learning)的思想,通过训练,把文本内容的处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。Word2vec已经被广泛的应用于很多NLP(Nature Language Processing)相关的工作中,如情感分析、词性分析和聚类等。
鉴于此,本文采用word2vec将用户倾向性词典中的每个关键词生成一个200维的向量,然后通过向量与向量之间的余弦距离来计算词语之间的相似度,计算公式如式(2)。
(2)
其中,公式2中ei是语料句子中第i个词,fj是目标句子中第j个词,第i个词和第j个词之间的相似度用Sim(ei,fj)表示,分子表示ei与fj的200维向量的乘积,当cos相似度大于0.6时,表示两个词相似。
word2vec查找语义相似词语的具体操作如下:
(1)配置word2vec工具;
(2)挖掘康辉旅行社的文本语料;
(3)使用NLPIR2013工具(http://ictclas.nlpir.org/)?对每个语料进行分词;
(4)将分好的语料进行训练。
(5)得到模型文件。文件中存储着文档中的词语和其对应的向量。
(6)利用公式2计算,比较词语的相似性,若cos大于0.6时,表示两个词相似,否则不相似。
2.3 Apriori算法及矩阵聚类改进算法
2.3.1 Apriori算法
Apriori算法[15]是一种挖掘布尔型关联规则频繁集项的算法,在数据挖掘中具有里程碑的作用。它的结构简单,没有复杂的推导,易于理解。项集(Itemset)简单地说就是项的集合,包含k个项的集合称为k-项集,譬如3-项集{l1,l2,l3}。一个项集的支持度(Support Count)为该项集出现频度,即整个数据集中包含该项集的记录个数。若某项集出现的频度大于一定的频度阈值则成为频繁项集。频繁k-项集集合计作Lk,其频度记support_count(Lk)。通过逐层搜索迭代的方法来完成频繁项集的挖掘工作。即利用k-项集探察(k+1)-项集,来穷尽数据集中所有频繁项集,直到不能再找到任何频繁k-项集。最后在所有的频繁集中找出强规则,即产生用户感兴趣的关联规则。
但随着挖掘数据库的不断增大,应用Apriori算法时每次迭代产生候选项目集以及统计其支持度非常耗时。为了提高效率,Apriori算法的一系列改进算法主要在以下方面进行优化:1)减少扫描数据库的次数;2)减少生成候选项目及的数目。
Apriori算法的流程图,如图1所示。

图1 Apriori算法流程图
2.3.2 MC-Apriori 算法
针对旅游数据稀疏、复杂且庞大的特点,以及Apriori算法的不足,提出了一种MC-Apriori算法,该算法以减少扫描数据库的次数和数据库规模为目的,只需扫描数据库一次,生成聚类矩阵来代替原来的事务数据库,在生成频繁项集时,也只需对部分聚类矩阵进行相应运算,因而可以大大提高算法的运算效率,最后在生成的所有频繁项集中去挖掘包含用户当前搜索关键词的最大项集。
定义1:每个项Ij的向量定义为:
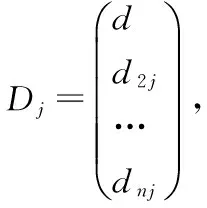
定义2:2-项集{IiIj}的向量定义为:
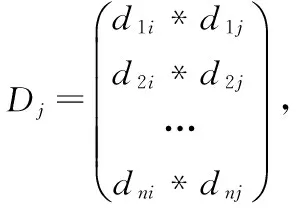
定义3:k-项集{I1I2…Ik}的支持度计数为:

定义4 项集I的矩阵D:
项集I转换为D’的表示如下:
为提高Apriori算法在旅游推荐系统中的效率,将相似的事务在数据库中进行标记(本文中称“相似记录个数”记为(α1,α2,…,p)-1,p为矩阵的行数,根据该事务在D中对于的某行加上出现的“相似记录个数”。从而获得数据的矩阵D″:
将D″中的值与D矩阵进行比较,若D中的项为0,则将D″相同位置也标记为0,否则,不改变。最后获得D矩阵。
算法过程如下:

②通过Lk-1与自己自然连接产生候选k-项集的集合Ck。当k=2时,对于候选项集合C2,直接根据定义2算出个各项集的支持度计数,然后转③。
③分别取候选k-项集Ck中的每个项集与L2中的元素进行比较,如果不在L2中,则该候选项集是非频繁的,将其从Ck中删除从而达到初步剪枝。因为候选k-项集Ck的集合中每个项集的长度为k,所以不必考虑小于k的聚类矩阵。先在聚类矩阵MC(k)中利用列向量间的*运算求出Ck中每个候选项集对应的列向量,再通过列元素求和来计算器支持度计数。如果大于等于min_sup,则将该候选k-项集放到频繁k-项集Lk中,否则继续在聚类矩阵MC(k+1)中统计此项集的支持度计数,并将其累加到前次的计数中,直到大于或等于min_sup,或者到达了最后聚类矩阵MC(n)而终止。
④循环②③步,直到候选集Ck为空而停止。得到所有的频繁项集。
⑤若最大频繁集中的项数个数小于当前搜索关键词KEY的个数,则向用户推荐以“KEY为关键词的文本”;否则遍历所有频集,找出以KEY为真子集且频度最大的项集,向用户推荐以该频繁集为关键词的旅游信息,否则,若遍历结果为空时,则向用户推荐以“KEY为关键词的文本”。
根据以上思想,基于MC-Apriori算法推荐的伪代码描述如下:
输入:用户当前搜索关键词集KEY={k1,k2,…,kq}(q为关键词的个数);用户倾向性词典I;最小支持度阈值min_sup。
输出: L: 推荐给用户的关键词集GEN_KEY。
方法:
1)D=Cluster_Matrix_Create(I,min_sup);
//Cluster_Matrix_Create(k)此为生成聚类矩阵算法。
2)for(k=2;Lk-1≠;k++){
Ck=Candidate_Itemset_Gen(Lk-1);
Lk=Large_Itemset_Gen(Ck);}
3)if q≥p(p为最大频繁集项数) then GEN_KEY=“以KEY为关键词的文本”。
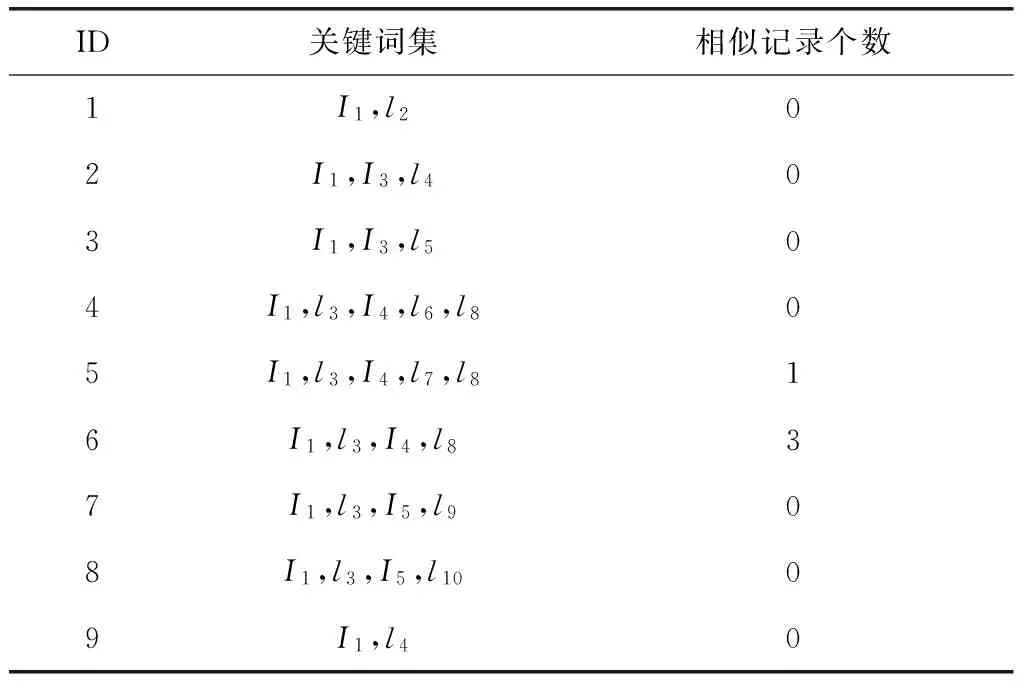
4)temp_L=max_key_frequent(Lk);//遍历所有频繁集Lk。q End 改进的Apriori算法结构图如图2所示。 图2 改进的Apriori算法结构图 目前,基于Apriori的改进算法层出不穷,此算法不仅可以满足对用户倾向性词典的挖掘,而且可以很友好的处理庞大,稀疏复杂的旅游领域数据,本算法的时间复杂度为O(n)~O(n2)。 在旅游网站中的搜索时,用户输入的关键词往往会比较集中,且和当前主题相关;考虑用户的个性习惯,输入的关键词分布应该不会太广泛。针对用户特定的行为习惯,利用MC-Apriori可以比较容易准确地搜索出用户倾向性词典中达到一定频度阈值的关键词频繁集。 本文引入了用户的阅览文本内容,在用户模糊交互且旅游数据庞大、复杂、稀疏的情况下,用户阅览文本内容可以反映出用户当前的兴趣倾向,并且确保推荐内容的准确、多样;且每个用户会产生个自的用户倾向性词典,则保证了推荐信息的个性化。同时利用MC-Apriori算法,不仅可以减少工作量,而且提高了运算效率。基于MC-Apriori算法的旅游个性化推荐模型,如图3所示。 图3 基于MC-Apriori算法的旅游个性化推荐模型 如图3所示,首先借助TextRank算法对用户的搜索关键词进行挖掘并按时间排序,存储在用户个性化词典中;同理利用TextRank算法挖掘用户搜索后浏览文本内容的前1/8个旅游领域的关键词;将此内容关键词集和用户个性化词典进行合并且按时间排序,通过word2vec工具比较每两行记录,将语义相似且ID小的记录删除并标记,存储在容量固定的用户倾向性词典中;最后通过MC-Apriori算法对用户倾向性词典进行挖掘,得到推荐信息。 3.1 用户倾向性词典模块设计 本文提出的旅游推荐模型,关键是对用户的倾向性词典进行挖掘分析并记录。如图4所示,模型中为每用户建立一个用户个性化词典、内容关键词集和用户倾向性词典数据模块,各模块中的记录按照用户的搜索时间升序排列,ID越大表示用户搜索的时间越靠近当前,并且定义用户倾向性词典的容量为用户个性化词典和内容关键词集容量的和,固定的容量不仅可以使记录都是用户近期感兴趣的信息,而且也节约了存储空间,提高了MC-Apriori运算效率。当用户进行搜索查看时,将挖掘的关键词记录到对应的表中,随着记录不断增加,当记录达到一定的容量,按照LRU(最近最久未使用)算法存储记录。此外,通过word2vec工具对比用户倾向性词典中每两行记录,将语义相似且ID小的记录删除并在“相似记录个数”中加1。 图4 用户存储模块结构 3.2 评测指标 推荐系统效果评估是一个困难的问题,常见的评估指标可以分为准确度、多样性、新颖性和覆盖率四大类。针对旅游领域的特殊性和复杂性,根据传统的推荐系统性能评测指标,本文采用以下指标对算法性能评估。 1)综合评价指标(F-Measure) 2)效率 将本算法在对收集的康辉旅行社的语料数据上测试。对于某一个用户,当前用户倾向性词典表,如表1所示。 表1 用户倾向性词典表 如表1所示,该用户到目前为止搜索和阅览文本总数为13次,设置用户倾向性词典的容量为120条记录,其中I1到I10分别代表昆明、景点、黑龙潭、梅花、门票、道馆、泉眼、公园、保险、团购这10个关键词,当前与ID=5的记录{I1,l3,I4,I7,I8}语义相似的个数为1,与ID的记录{I1,l3,I4,I8}语义相似的个数为3,用户当前搜索关键词(ID=9)为{I1,I4}。 当前用户在搜索框中输入关键词{昆明,梅花}时,首先将搜索关键词经过word2vec更新用户倾向性词典表,然后采用MC-Apriori算法进行频繁项集的挖掘,令min_sup为2。过程如下: 1)扫描事务数据库一次,获得项集I的矩阵D。生成聚类矩阵CM(k),k为2,3,4,5,10,16。 CM(5)=(1011010100) CM(10)=(2022002200) CM(16)=(4044000400) 同法可计算出:I3,I4,I5,I6,I7,I8,I9,I10与2相比的大小,所以生成频繁1-项集L1={I1,I3,I4,I5,I8},由此可直接排除I2,I6,I7,I9,I10。 2)L1=与自己自然连接产生候选2-项集的集合 C2={I1I3,I1I4,I1I5,I1I8,I3I4,I3I5,I3I8,I4I5,I4I8,I5I8}。在CM(2)中,因为 3)L2与自己自然连接产生候选3-项集的集合C3={I1I3I4,I1I3I5,I1I3I8,I1I4I5,I1I4I8,I1I5I8,I3I4I5,I3I4I8,I3I5I8},由于{I4I5,I5I8}是非频繁2-项集,所以{I1I4I5,I1I5I8,I3I4I5,I3I5I8}从C3中删除,因此只需考{I1I3I4,I1I3I5,I1I3I8,I1I4I8,I3I4I8}的支持度计数。由于k=3>2,所以只需从聚类矩阵MC(3)考虑, 1+0+1=2≥2 同理,可以计算其他候选集的支持度,得到的频繁3-项集L3={I1I3I4,I1I3I5,I1I3I8,I1I4I8,I3I4I8}。 4)L3与自己自然连接产生候选4-项集的集合C4={I1I3I4I5,I1I3I4I8,I1I3I5I8},由于{I4I5,I5I8}是非频繁2-项集,所以将{I1I3I4I5,I1I3I5I8},从C4中删除,实现剪枝,同3),计算出{I1I3I4I8}的支持度,得L4={I1I3I4I8},算法终止,找出了所有的频繁项集。 5) 因为最大项集的项数为4≥2(2为当前搜索关键词的个数),则在所有频繁项集中找出以{昆明,梅花}为真子集的项数最大的频繁集,即{昆明、黑龙潭、梅花、公园}。 6)向用户推荐以该频繁集为关键词的旅游信息。 MC-Apriori算法、Apriori算法以及协同过滤算法在收集的康辉旅行社的语料数据中多次试验所花费时间的平均值如表2所示。 表2 不同方法在多次试验下的所需时间评均值 /毫秒 MC-Apriori算法以及协同过滤算法随着语料的递增F值大小变化,如图5所示。 图5 二种算法随着语料的递增F值大小变化 从表2中可以观察得到,测试中MC-Apriori算法所需的平均时间小于Apriori算法与基于协同过滤的算法。图5中,随着语料的增加,F值增大,且MC-Apriori的F值大于于协同过滤的算法。当语料增加到一定程度上,F值趋于稳定。 MC-Apriori算法在第一次对数据库扫描的同时根据事务中项的和生成不同的聚类矩阵,只需对部分聚类矩阵计算就可以产生频繁项集,减少了每次扫描全部数据库所需要的开销,提高了算法的效率。因为旅游数据复杂,基于协同过滤算法的推荐模型中很难准确描述这些数据,而用户的阅览信息可以很好的反映用户的旅游需求和对旅游产品的偏好,以及约束条件,所以本文提出的模型提高了准确率。且MC-Apriori算法时间复杂度为O(n)~O(n2),基于协同过滤算法为O(m2*n),Apriori算法为O(m*n2),所以效率也提高了。通过对收集的康辉旅行社的语料数据测试,F值提升了5%。 本文针对个性化推荐在旅游领域面临的特殊问题,提出了一种通过矩阵聚类的Apriori改进的方法,该算法只需对数据库扫描一次并生成一系列不同的聚类矩阵,而只需要对部分聚类矩阵计算就可以产生频繁项集。引入用户的阅览内容,不仅反映用户当前的兴趣倾向,且保证推荐内容的准确、多样及个性,同时利用改进Apriori算法提高了搜索效率,减少了工作量。通过对收集的康辉旅行社的语料数据大量测试,论证了本文提出的旅游推荐模型相比较传统的推荐模型具有一定的应用价值。为了更好的推荐结果,推荐算法有待进一步研究。 [1] 乔向杰,张凌云.近十年国外旅游推荐系统的应用研究[J].旅游学刊.2014(08). [2] JANNACH D,ZANKER M, FUCHS M.Constraint-based recommendation in tourism:a multi-perspective case study[J]. Journal of Information Technology and Tourism, 2009, 11(2):139- 155. [3] Ricci F, Rokach L, Shapira B.Introduction to recommender systems handbook[A].//:Recommender Systems Handbook[M]. New York: Springer, 2011:1-35. [4] 张晗,潘正运,张燕玲.旅游服务智能推荐系统的研究与设计[J].微计算机信息, 2006,22(5-3):170-171. [5] FENZA G, FISCHETTI E, FURNO D, et al. A hybrid context aware system for tourist guidance based on collaborative filtering[A].FENZA G.The IEEE International Conference on Fuzzy Systems[C].New Jersey: IEEE Press, 2004:259-262. [6] 文益民,史一帆,蔡国永,缪裕青,龙刚.个性化旅游推荐研究综述[A].2015中国旅游科学年会论文集[C]. 2015. [7] GE Y, LIU Q, XIONG H, et al. Cost-aware travel tour recommendation[A].GE Y.ACM SIGKDD Conference[C]. New York: ACM Press, 2011:983-991. [8] RICCI F. Travel recommender systems[J].IEEE Intelligent systems, 2002:55-57. [9] JIANG K, WANG P, YU N H. ContextRank:personalized tourism recommendation by exploiting context information of geotagged web photos[A]. The 6th International Conference on Image and Graphics[C]. New Jersey: IEEE Press, 2011: 931-937. [10] 王显飞,陈梅,李小天.基于约束的旅游推荐系统的研究与设计[J]. 计算机技术与发展,2012:141-145. [11] BUSTOS F, LOPEZ J, JULIAN V, et al. STRS: Social network based recommender system for tourism Enhanced with trust[A]. BUSTOS F. Distributed Computing and Artificial Intelligence[C]. Berlin: Springer, 2008: 71-79. [12] MAJID A, CHEN L, CHEN G, et al.A context-aware personalized travel recommendation system based on geotagged socialmedia datamining[J].International Journal of Geographical Information Science. 2012,27(4): 662-684. [13] 杨洁,季铎,蔡东风,代翠.基于TextRank的多文档关键词抽取技术[A]. 第四届全国信息检索与内容安全学术会议论文集(上)[C]. 2008. [14] 罗杰.王庆林.李原基于word2vec与语义相似度的领域词语聚类[C]. 2014. [15] TANG J, HU X, LIU H. Social recommendation:a review[J]. Social Network Analysis and Mining, 2013,3(4): 1113-1133.
3 基于MC-Apriori算法的旅游个性化推荐模型


4 实验举例




5 总结
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
新闻研究导刊(2015年17期)2015-12-25 12:36:42
语言与翻译(2015年4期)2015-07-18 11:07:43
卷宗(2014年5期)2014-07-15 07:47:08
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
计算机工程(2014年6期)2014-02-28 01:26:12
当代修辞学(2013年4期)2013-01-23 06:43:10
