
时域信息对健听青年在人工耳蜗模拟声下声调识别的影响
2018-01-25 02:15:54王梅红胡旭君沈晨波
听力学及言语疾病杂志 2018年1期
王梅红 胡旭君 沈晨波
随着人工耳蜗相关研究的不断深入,人工耳蜗植入对提高重度及以上听力损失患者的言语识别能力越来越显著,但多数以汉语为母语的植入者普遍反映难以感知声调[1],这主要是由于当前人工耳蜗技术提供的音调信息有限[2]。人工耳蜗对声信号进行带通滤波,然后将不同频率信号传至耳蜗不同部位,以脉冲波形式刺激神经。人工耳蜗植入者由于电极数量限制,得到的频域信息比正常人少得多,无法感受声调信息中包含的细微频率变化[3,4]。人工耳蜗在编码声音信息时除了频域信息还有时域信息[5],人工耳蜗脉冲波的调制频率中包含重要的时域信息,但是目前通用的言语编码方案所提供的时域信息有限,不足以帮助植入者很好地感知声调。
时域信息按照采样精细程度,可以分为缓慢变化的振幅包络和快速变化的精细结构,如图1所示,图a是汉语 “在不”的时间-振幅曲线图;图b来自于图a,振幅采样精度为50 pps(pps=pulses per second,同Hz,为防止时域信息与频域信息混淆,本文时域信息精度用pps描述),为缓慢变化的振幅曲线,代表振幅包络;图c截取自图a箭头标注处,采样精度大于600 pps,为标注处快速变化的振幅曲线,代表精细结构。

图1 振幅包络与精细结构示意图 a为汉语单词“在不”的时间-振幅曲线图;b为振幅包络;c为a黑色箭头标注处的精细结构
声码器技术早在20世纪20年代提出[6],用于言语声的分析与合成,现成为研发言语编码方案的必备工具之一。声码器通过使用噪声或正弦声来代替各个通道上的原始声信息,保持各个通道的中心频率固定,抽取各个通道上的能量包络并调制相对应的振幅包络,达到模拟人工耳蜗的目的。有研究指出[7],正常人聆听8通道正弦声下的人工耳蜗模拟声,其言语感受情况与人工耳蜗植入者感受情况接近,可代表人工耳蜗植入者最佳聆听效果[8]。本研究通过声码器模拟两种不同时域信息下的人工耳蜗模拟声,获得健听受试者声调识别成绩,探讨理论情况下人工耳蜗时域信息编码对健听青年声调识别的影响,为开发更适合汉语人工耳蜗植入者的编码策略提供新思路。
1 资料与方法
1.1研究对象 以30例健听青年为研究对象,年龄19~22岁,均为高校在读学生,以普通话作为日常交流语言且均排除言语发展障碍,双耳纯音测听各频率阈值≤20 dB HL,鼓室导抗图A型。
1.2人工耳蜗模拟声制作步骤
1.2.1音频录制 在本底噪声小于30 dB A的标准隔声室,用索尼PCM-D50录音笔进行音频录制。播音员平坐在隔声室中,录音笔置于播音员前1米,与头部等高,麦克风设置为X-Y指向(用于独奏或人数少的场合的近距离录音,双麦克风向内交叉呈90°)。由普通话一级甲等水平的播音员以正常语速念出/a/、/o/、/e/、/i/、/u/、/ü/ 6个单韵母的四声,朗读过程保持响度一致,得到共24段录音。
1.2.2音频编辑
1.2.2.1音频文件导入电脑,所有音频以“韵母+声调”的形式重命名,如:/o/的二声音频重命名为o2,使用Adobe Audition 3.0音频编辑软件将所有音频文件由双声道转换为单声道,作为原始音频文件。
1.2.2.2使用Tiger CIS声码器软件(版本1.07.01)对原始音频文件进行8通道正弦波调制修改,如图2所示,其中第1、2通道为500 Hz以下的声信息,可选择不同采样精度(125、250、375、500、625、750、875、1 000、1 125、1 250、1 375和1 500 pps),第3~8通道为500 Hz以上声信息,采样精度固定为50 pps。以/ā/为例,最终一共得到12段音频。
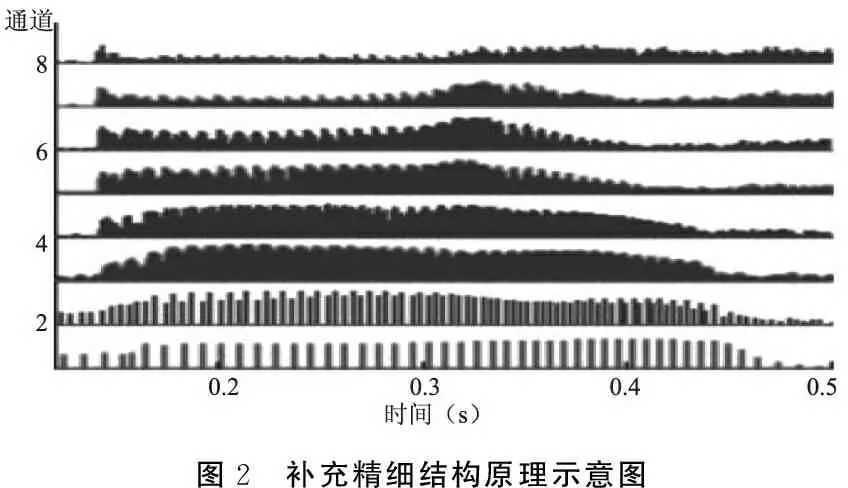
图2 补充精细结构原理示意图
1.2.2.3使用Praat软件进行音频分析,提取各个单韵母音频的基频F0走势曲线。
1.2.2.4使用Adobe Audition 3.0音频编辑软件,调整音频的振幅包络,使音频包络走势曲线接近基频F0曲线。原理如图3所示,图a为单韵母/a/的原始声压曲线图;图b中白色曲线为采样精度50 pps的原始包络曲线,黑色粗点曲线为使用Praat软件提取出的基频曲线;图c代表使用Adobe Audition 3.0软件修改过后的振幅包络曲线,振幅包络更靠近基频曲线。
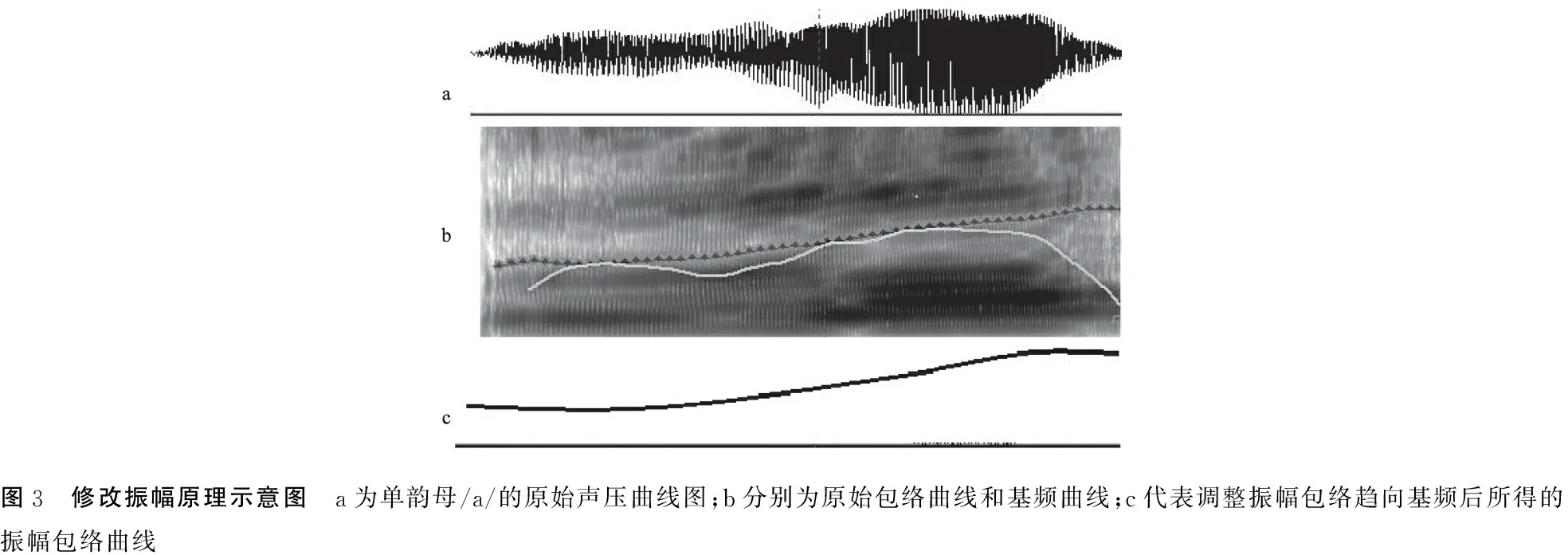
图3 修改振幅原理示意图 a为单韵母/a/的原始声压曲线图;b分别为原始包络曲线和基频曲线;c代表调整振幅包络趋向基频后所得的振幅包络曲线
以/ā/为例,最终一共得到24段音频,其中:①不调整振幅包络组12段音频,即500 Hz以下采样精度分别为125、250、375… …1 375、1 500 pps; ②调整振幅包络组12段音频, 即500 Hz以下采样精度分别为125、250、375… …1 375、1 500 pps,此外,调整振幅包络趋向基频F0曲线。
共6个韵母,4种声调,调整包络前后共2组, 500 Hz以下采样精度共12种,最终一共获得6×4×2×12=576段音频,如表1所示:

表1 500 Hz以下各采样精度不调整及调整振幅包络组音频数
1.3健听青年声调识别测试
1.3.1将笔记本电脑与GSI61听力计相连,完成听力计零级的校准。
1.3.2为受试者讲解测试规则,并随机播放上述5~10段人工耳蜗模拟声,使受试者熟悉实验音频,适应模拟声的特点。
1.3.3受试者进入隔声室,由扬声器0°角给声,强度为舒适阈强度,研究人员在隔声室外通过电脑播放音频,受试者每听到一段音频后都要求回答音频音调,不要求其判断音频代表的韵母。由于测试音频较多(共576段),受试者易产生听觉疲劳和厌烦情绪,故30例受试者中10例聆听125、250、375、500 pps四组音频,10例聆听625、750、875、1 000 pps四组音频,10例聆听1 125、1 250、1 375、1 500 pps四组音频,每人一共聆听:6个韵母×4种声调×修改振幅包络前后2组×4组500 Hz以下不同采样精度=192段音频,最后收集每组10例受试者的数据,计算平均值。
研究人员通过外接耳机记录受试者的回答,记录声调识别正确数,并计算受试者声调识别正确率,正确率=正确回答声调数/192×100%。
1.4统计学方法 采用SPSS19.0统计软件对数据进行检验。首先使用重复测量方差分析(ANOVA) 法分析振幅包络 (不调整、调整)和精细采样 (125、250… …1 500 pps)这两个实验因素对受试者声调识别的影响,然后以 Bonferroni调整多重比较分析每组(不调整振幅包络、调整振幅包络) 12个不同采样精度所得到的声调识别正确率是否有显著性差异,调整后检验水准α=0.05/12=0.004,P<0.004为差异有统计学意义;再以配对样本t检验分析振幅包络和精细采样两个实验因素结合后声调识别正确率是否有差异,P<0.05为差异有统计学意义。
2 结果
2.1调整振幅包络对声调识别的影响 重复测量方差分析显示,调整振幅包络显著影响声调识别[F(1,9)=16.91,P=0.002]:调整振幅包络后声调识别正确率(80.22%±16.32%)大于调整前(74.83%±20.24%),平均相差5.39%,说明调整振幅包络使之趋向F0,有助于提高声调识别正确率。
2.2补充精细结构对声调识别的影响 不同采样精度修改500 Hz以下时域信息后的声调识别成绩见表2、图4。重复测量方差分析显示改变精细结构显著影响声调识别[F(11,99)=38.86,P<0.001]。Bonferroni调整多重比较结果表明,不调整振幅包络时,500 Hz以下12组不同采样精度下的声调识别正确率进行两两比较,在<375 pps的采样精度下,声调识别成绩随采样精度的提高而显著提高 (P<0.004);当采样精度≥375 pps时,采样精度提高时声调识别成绩无显著改变,达到饱和状态;但调整振幅包络后,只有在 <250 pps的采样精度下声调识别成绩才有显著提高 (P<0.004)。

表2 不调整和调整振幅包络时500 Hz以下各采样精度的声调识别率(%)(n=10)
注:*与其余各组两两比较,P<0.004
2.3调整振幅包络和补充精细结构相结合对声调识别的影响 重复测量方差分析显示调整振幅包络和精细采样之间有显著交互作用[F(11,99)=3.78,P<0.001],Bonferroni调整多重比较结果表明,两试验因素相结合的情况下(调整振幅包络后),只有在 <250 pps的采样精度下声调识别成绩才有显著提高(P<0.004)。在每个采样精度下对调整振幅包络与不调整振幅包络之间的声调识别正确率进行配对t检验,结果表明,只有在精细结构≤375 pps时,修改振幅包络前后声调识别正确率差异有显著统计学意义(P<0.05);当精细结构>375 pps,随着时域信息精细程度增高,调整包络前后声调识别正确率的差值趋向于0 (图4)。说明当精细结构≤375 pps时,调整振幅包络促进声调识别;当精细结构>375 pps时,调整振幅包络对声调识别影响不大(P>0.05)。
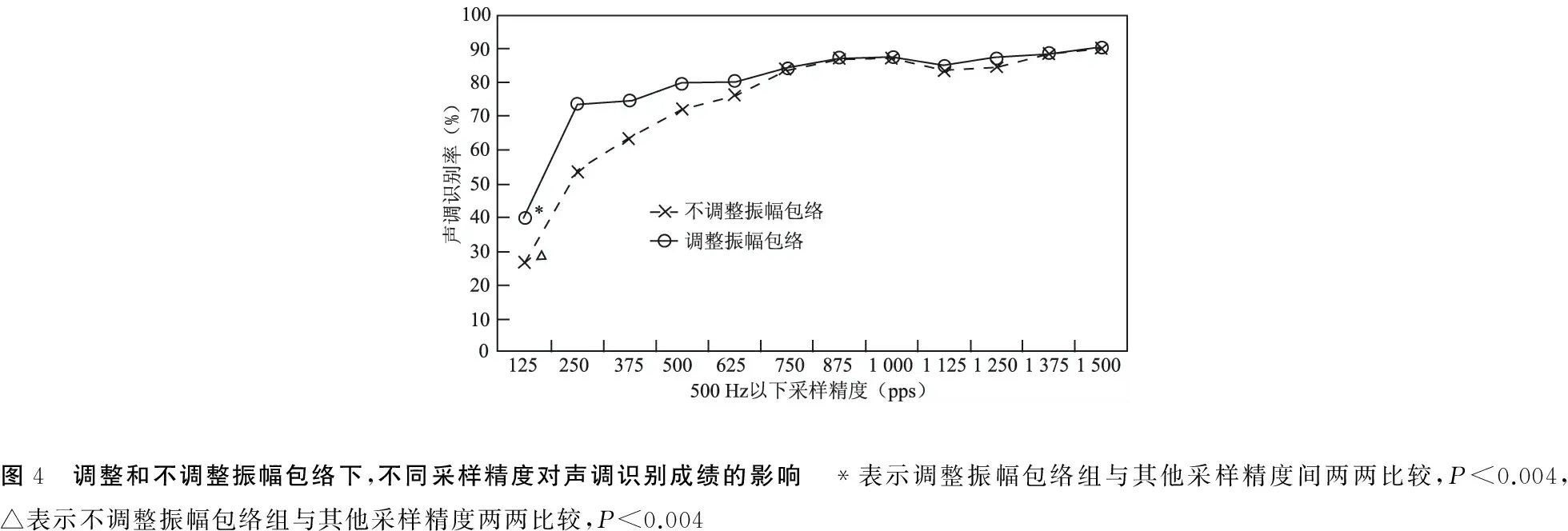
图4 调整和不调整振幅包络下,不同采样精度对声调识别成绩的影响 *表示调整振幅包络组与其他采样精度间两两比较,P<0.004,△表示不调整振幅包络组与其他采样精度两两比较,P<0.004
3 讨论
汉语作为一种典型的声调语言,其声调信息对构词辨义起重要作用。汉语人工耳蜗植入者感受到的声调信号特点直接取决于言语编码策略。连续交替取样(continuous interleaved sampling, CIS)言语编码方案基于英语语言特点研发,仅提供包络信息,非声调语言植入者可以达到良好的言语识别率,但无法感受到音乐的旋律变化,汉语植入者则表现为声调识别较差。现有言语编码方案通过谐波分析获得基频(F0)信息,修改振幅包络使之更接近基频的变化曲线,如浙江诺尔康神经电子科技股份有限公司研发的编码策略etone编码方案;或者提供500 Hz以下频率段的时域精细结构信息,如精细结构编码策略(fine structure processing, FSP)[9],都可在一定程度上提高人工耳蜗植入者声调识别能力。本研究参考上述两种技术思路,并结合两者技术特点,探究调整振幅包络前后声调识别效果。
3.1振幅包络对声调识别的影响 周晓琴等[10]运用软件分别提取单韵母的波形图和包络曲线进行时域分析发现,无论韵母是否相同,只要声调相同其基频包络就具有高度相似性。声调的主要声学信息为基频(F0),因此,在言语编码方案中通过改变振幅包络增加基频信息可能有利于声调识别。本研究结果显示修改振幅包络使之更接近基频的变化曲线确实有利于提高声调识别成绩。Luo等[11]通过修改人工耳蜗植入者编码方案的振幅包络,发现其声调识别能力显著提高,与本研究结果一致。
3.2精细结构对声调识别的影响 Xu等[12]用声嵌合技术研究发现,不同于非声调语言的识别,声调识别的感知模式依赖于声信号中的精细结构,与音乐感知类似。Arnoldner等[13]对14例MED-EL人工耳蜗植入者在CIS和FSP两种不同言语编码策略下进行4、8、12周跟踪调查,结果显示提供更多低频精细结构的FSP更利于声调和音乐识别。上述研究说明,人工耳蜗言语编码方案中增加对时域精细结构线索的提取,有利于提高声调感知能力。
本研究对500 Hz以下的声信号进行不同程度的补充,结果显示受试者声调识别成绩在一定范围内随精细结构增加而升高,并在精细结构达到375 pps之后趋于稳定。亓贝尔等[14]对人工耳蜗植入者进行跟踪研究,发现由CIS更改为FSP编码策略并持续使用6周后,其声调识别成绩显著提高,说明增加精细结构可改善声调识别,与本研究结果一致。汉语声调的主要声学信息为基频和第一共振峰,成人基频在80~350 Hz之间,而单韵母的第一共振峰绝大多数位于500 Hz以下,所以500 Hz以下频率段提供精细结构信息有利于汉语声调识别[15];但声调信息分布范围广,冗余度较大,仅需小部分信息便可确定声调[16],这也可能是大于375 pps补充精细结构后声调识别成绩无显著性差异的原因。徐立[17]发现在≥256 pps采样精度时人工耳蜗植入者声调识别达到75%的最佳成绩;而本研究受试者在≥375 pps采样精度时达到约91.67%的最佳成绩,可能与本研究对象为健听青年,对精细结构的接受能力优于人工耳蜗植入者有关。
3.3修改振幅包络结合增加精细结构对声调识别的影响 本研究结果表明,修改振幅包络和增加精细结构可用于同一言语编码方案中,当精细结构≤375 pps时,可同时调整振幅包络,两者相结合可更好地提高声调识别效果;当精细结构>375 pps时,此时提供的低频信息已足够人工耳蜗植入者声调识别,是否调整振幅包络对声调识别正确率影响不大。本研究基于健听青年对两种时域信息的敏感度,当采样率>375 pps时,修改振幅包略对声调识别的意义不大;但有研究提示[7],重度感音神经性听力损失患者对不同时域信息的敏感度有差异,表现为对振幅包络的感受能力增强,对精细结构的感受能力减弱。因此,对人工耳蜗植入者而言,当精细结构>375 pps时,调整振幅包络提供基频信息是否更有利于声调识别,还有待进一步研究。
3.4言语编码策略的发展与展望 人工耳蜗言语处理方案基本上都在非声调语言基础上开发,可帮助拉丁语系使用者获得较好的言语识别,但难以提高其声调识别和旋律辨别的能力,如果在人工耳蜗言语编码系统中增加时域信息,将有利于人工耳蜗植入者感知声调语言和欣赏音乐。本研究仅以健听青年为受试者,未来将在听障患者中进一步进行相关研究。
1 毛奕韬,伍伟景,谢鼎华.人工耳蜗植入者声调感知能力研究进展[J]. 中华耳科学杂志,2012,10:392.
2 王硕,Mannell R,张华.汉语声调在国内外人工耳蜗相关领域的研究现状[J]. 中华耳鼻咽喉头颈外科杂志,2011,46:164.
3 刘博,董瑞娟,陈雪清,等.诺尔康人工耳蜗植入者的声调识别与生活质量评价[J].临床耳鼻咽喉头颈外科杂志,2014,28:232.
4 亓贝尔,刘博.影响人工耳蜗植入者声调识别的因素[J].听力学及言语疾病杂志,2010,18:512.
5 徐立,周宁.人工耳蜗植入与声调语言[J].中国医学文摘耳鼻咽喉科学,2013,28:196.
6 Shannon RV. Auditory implant research at the house ear institute 1989~2013[J].Hearing Research,2015,322:57.
7 Kale S,Geinz M.Envelope coding in auditory nerve fibers following noise-induced hearing loss[J].Journal of the Association for Research in Otolaryngology, 2010, 25: 657.
8 Friesen LM,Shannon RV,Baskent D,et al.Speech recognition in noise as a function of the number of spectral channels: cmparison of acoustic hearing and cochlea implants[J].J Acoust Soc Am,2001,110:1150.
9 Wouters J, McDermott HJ,Francart T.Sound coding in cochlear implants[J].Iee Signal Processing Magazine,2015,3:67.
10 周晓琴,陈浩,钱宇虹,等.采用Cool Edit Pro 2.0软件分析汉语普通话单音节词四声的时域及频域[J].中国组织工程研究与临床康复,2008,12:6827.
11 Luo X,Fu QJ.Enhancing Chinese tone recognition by manipulating amplitude envelope Implications for cochlear implants[J].Acoustical Society of America, 2004,116:3659.
12 Xu L,Bryan EP.Relative importance of temporal envelope and fine structure in lexical-tone perception[J].J Acoust Soc Am,2003,114:3024.
13 Arnoldner C,Riss D,Brunner M,et a1.Speech and music perceplion with the new fine struclure speech coding strategy:preliminary resuhs[J].Acta Oto1aryngologica,2007,127:1298.
14 亓贝尔,刘博,董瑞娟,等.时域精细结构信息对汉语人工耳蜗使用者言语识别的影响[J].中华耳鼻咽喉头颈外科杂志,2014,49:294.
15 辜萍,郗昕,韩东一,等.人工耳蜗植入者使用精细结构编码策略的音高和言语感知相关研究[J].临床耳鼻咽喉头颈外科杂志,2013,27:481.
16 梁之安.汉语普通话中声调的听觉辨认依据[J].生理学报,1963,26:85.
17 徐立.言语识别中的时域及频域信息[J].中华耳科学杂志,2006,4:335.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
中国听力语言康复科学杂志(2021年6期)2021-12-21 07:21:54
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
山东交通科技(2020年2期)2020-08-13 09:24:06
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
电子制作(2017年20期)2017-04-26 06:57:35
海南医学(2016年8期)2016-06-08 05:43:00
