
基于递归神经网络的火电机组污染物排放研究
2018-01-18 08:09:32李端超黄少雄高夏生高卫恒杨训政
自动化与仪表 2017年10期
梁 肖,李端超,黄少雄,高夏生,高卫恒,杨训政
(1.安徽电力调度控制中心,合肥 230022;2.中国科学技术大学 计算机科学与技术学院,合肥 230027)
我国经济的飞速发展,消耗了大量的能源,而我国的能源主要来源于煤炭,使用方式主要是火力发电,故火电站的建设也在快速增长。但火电站在提供电力的同时,也造成了严重的污染问题。
对于污染物的排放量,电力部门积累了大量的历史数据,但并没有基于这些数据做出决策,一方面主观上传统调度方法是根据人的经验,对于数据的重视不够,缺乏客观科学性;另一方面,过去机器学习、神经网络对于难以提取高质量特征的数据学习处理能力不足,不能够有效解决这类问题。但近年来,机器学习的发展取得了很大进步[1-2],对于过去无法处理的数据,现在可以从中获得大量的知识和信息,在计算机视觉、金融分析、搜索引擎、语音识别[3]、智能机器人等领域都取得了良好的效果。同样,对于电力公司积累的海量数据,如何利用这些数据,达到减少污染物排放的目的也成为了机器学习的研究热点。
但之前的一些方案,没有考虑到实际条件下数据复杂性产生的难以提取有效特征的问题,而深度学习则有不依赖高质量特征的优势[4]。预测问题的实质就是获得与符合特征的曲线,也就是曲线的拟合,但对于机器学习中的一些传统的方法,当特征维度非常大或者难以提取有效特征时,传统的方法难以取得良好的效果[5]。
为解决以上问题,本文采用深度学习技术而不是传统方法对发电机组污染物排放量进行研究,使用RNN对电力公司积累的历史数据进行训练,建立模型,达到预测一段时间内污染物排放量的目的。最后通过试验证明,RNN方法可以克服传统方法依赖高质量特征的问题,并且对模型进行优化后,可以显著提高预测的精度和训练速度。
1 发电功率与污染物排放量的回归模型
1.1 多项式预测模型
机组在稳定运行状态下,污染物排放量F与输出功率P的对应关系,可以表示为

多项式拟合的特点是阶数越高越精确,但成本也会越高。国际电工委员会(IEC)推荐用二次多项式对排污模型进行拟合。但这种拟合方法存在过拟合的问题,即训练时误差很小,测试时误差很大。在深度学习中有很多方法避免这个问题,但传统方法却无能为力。
假设模型为Pi(xi,yi),其中i=1,2,…,m;xi代表发电机组功率;yi代表污染物排放量。拟合一条曲线对数据分布进行逼近,并且使得近似曲线与P的分布偏差最小。按照最小二乘法,即求:

在对多元函数参数求导后可以得到一个系数的对称正定矩阵,该矩阵存在唯一解,求解该矩阵即可得到多元函数系数。
如果数据比较简单,符合多项式特征,多项式预测模型就能够简单高效地对数据进行预测。然而,如果数据样本不足,则容易出现过拟合的现象,且可能会得不到精度符合要求的拟合函数。
1.2 基于SVM的预测模型
出现于1995年的支持向量机SVM是一种强大的机器学习算法,可以用于识别分类和回归预测。SVM能很好地解决样本量不足、非线性及高维度识别等问题,同时也可以将改进的SVM用在拟合曲线等问题上。
由于SVM用于预测的模型是基于结构风险最小化的,对于在多项式拟合中难以克服的问题,比如过拟合等,SVM可以很好地解决。SVM的回归分析方法与分类方法类似,对于样本数据集合(xi,yi),i=1,2,…k,假设 g(x)=(w.x)+b基于结构风险最小的拟合,g(x)应该满足:


支持向量机SVM在实践中运用广泛,如果数据的量比较大,或者数据特征比较明显时能取得很好的效果。然而如果数据特征不是很明显,则需要使用核函数将数据映射到高维空间再进行分析。但是,如果数据过于复杂或者特征在高维空间依旧难以高质量提取时,SVM就会体现出局限性[5]。
1.3 基于RNN的预测模型
1.3.1 RNN
RNN是用来处理序列数据的。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的,如图1所示。但是这种普通的神经网络对于很多问题却无能无力,比如若问题的当前状态和之前的状态相关联时。但RNN不同,RNN的隐含层神经元有一条递归的边,具体的表现形式为网络会对前面的
式中:K为核函数;信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,图2便是一个典型的RNN。

图1 传统的神经网络模型Fig.1 Traditional neural network model

图2 RNN网络模型Fig.2 RNN neural network model
1.3.2 LSTM
RNN相当于根据时间序列展开的一个多层的DNN,由于层数很多,有可能会出现梯度消失的问题[6]。为了解决这个问题,Hochreiter等人提出了一种特殊的RNN模型——LSTM模型[7]。在很多问题上,LSTM都取得了巨大成功。
LSTM基本结构和RNN相同,只是在RNN的隐藏层中增加了一种被称为记忆单元的结构用来记忆过去的信息,同时增加了input、forget、output 3种门来控制历史信息的使用,图3是LSTM神经元的内部结构。

图3 LSTM神经元结构Fig.3 LSTM neuron structure
1.3.3 激活函数
激活函数的作用是增加对非线性模型的表达能力。在神经网络中,如果不加入激活函数,那么每一个节点的输出仅仅是输入的一个线性变换,表达能力比较弱。早期常用的激活函数是Sigmoid和Tanh。
从数学上看,这2个函数都是非线性函数,在中部信号增益较大,在两侧信号增益较小。但对比早期的线性激活函数,比如y=x,表达能力已经大大增强。但Sigmoid等函数仍存在很多缺点,比如激活函数的计算量很大,在反向传播求误差梯度时,也会由于变换过慢,导致梯度趋近于0的问题。
如图4所示,2001年由神经科学家提出的ReLU激活函数,与Sigmoid相比,Relu在反向传播是不容易出现梯度消失现象,同时计算成本较低,网络收敛速度加快。此外,ReLU函数会使一部分神经元输出为0,增加神经网络的稀疏性,提高模型的性能,减少过拟合的情况。目前认为使用ReLU函数在数据量足够大的情况下,即使不用预训练也能将神经网络训练出较好的效果,甚至效果更佳。
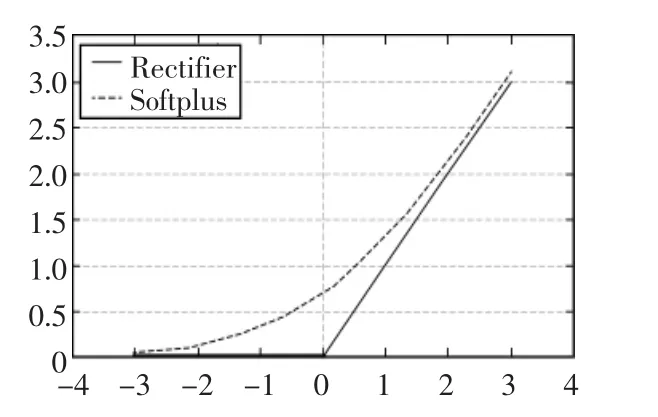
图4 Softplus函数和Rectifier函数Fig.4 Softplus function and Rectifier function
1.3.4 ALSTM-RNN
在ALSTM-RNN中,我们对LSTM-RNN的结构进行了一些改进,使用了配对的遗忘门和输出门,这样就不是只决定遗忘信息和添加信息,而是同时决定两者,只有在需要再输入新信息的时候才需要遗忘,或者早先的信息被遗忘的时候才需要输入。同时我们对计算过程也做了优化,减小了计算所需的时间。
1.3.5 其他性能提升方法
Batch Normalization(BN)方法由谷歌在2015年提出[8],是深度学习领域的一项重大成就,其优点在于可以解决大批量数据导致的参数数据分布不均的问题,从而提高模型的时间性能。在隐含层加入BN处理,可以有效减少训练时间,提高训练精度。
数据归一化,使用如下的公式将数据映射到[0,1]区间:

经过试验验证,这种归一化方法比标准正态分布的方法较优。
2 模型有效性验证
2.1 预测评价指标
最终结果的评价标准主要考虑的因素是目标函数的均方误差。在具体分析模型的性能指标时,会采用一些深度学习研究中普遍的评价标准,比如说收敛速度,误差率等。
均方误差公式如下:
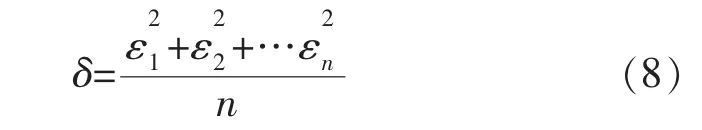
式中:εi为第i个输出的预测值与实际值之差。均方误差MSE的值越小,说明误差越小,反之说明误差越大。
此外,由于深度神经网络的训练时间通常达到数小时甚至数十小时,因此训练时间和收敛速度也是衡量模型性能的重要指标。收敛速度的快慢在很大程度上决定了模型是否具有实用性。
2.2 模型训练效果
试验使用的平台是Win7操作系统,编程语言为python2.79,深度学习框架是Keras。
MSE可以反映模型的训练效果,其值越小说明误差越小,模型的质量越高。
2.3 模型对比试验
试验选择了30台机组的数据作为测试集进行验证,测试集大小约为训练集的5%。LSM模型采用国际电工组织推荐的方案,SVR模型采用SalehC等人的方案[9]。结果如图5所示。
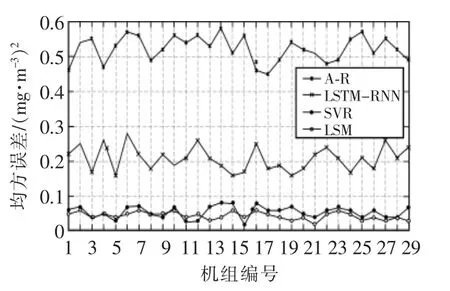
图5 四种拟合方法对比Fig.5 Comparison of four fitting methods
可以看出,LSTM-RNN模型的预测精度远高于LSM和SVR,虽然测试集上的结果和训练集上的相比略有差距,但仍保持了很高的精度。从这里也可以看出来,基于LSM的模型的效果很差。说明了基于最小二乘法的拟合方法并不适合这种不能提取明显特征的数据。SVR具备将低维度的数据映射到高维度上的能力,这样可以使得一些本来不太明显的特征变得明显,但是如果数据比较复杂,可能会出现过拟合的现象,使得模型在测试集上的精度降低。而ALSTM-RNN模型的精度相比于LSTM-RNN相差不大,但其方差更小一些。
总的来说,ALSTM-RNN模型可以比较准确地预测污染物的排放量,相比其他方法,其均方误差是最低的,并且其在不同的机组上测试也都保持了其预测的准确度,具有比较好的鲁棒性。
3 结语
本文提出了一个基于深度学习方法的发电机组排放预测模型,解决了传统的最小二乘法和机器学习方法预测精度不够的问题,证明了该预测方法在实践上的有效性。同时,为了提高模型的训练速度及精度,在模型的训练过程中采用了多种手段来优化模型,比如数据的归一化,Batch Normalization方法等等。
目前来看由于RNN训练的困难性,一次调整训练的时间可能需要数小时到数天不等,而在实际训练中可能还是需要更快的训练速度。同时由于计算资源不足,时间不充裕,模型的时间性能方面还有待改进。下一步工作的目标就是使用更多的计算资源来研究如何提升RNN的性能。
[1] Bengio Y,Delalleau O.On the expressive power of deep architures[C]//Algorithmic Learning Theory.Springer Berlin Heidelberg,2011:18-36.
[2]BASAK D,PAL S,PATRANABIS D C.Support vector regression [J].Neural Information Processing-Letters and Reviews,2007,11(10):203-224.
[3] LEE T,CHING P C,CHAN L W.Recurrent neural networks forspeech modeling and speech recognition[C]//Acoustics,Speech,and Signal Processing,International Conference on.IEEE,1995(5):3319-3322.
[4] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436-444.
[5] SMOLA AJ,SCHOLKOPF B.A tutorial on support vector regression[J].Statistics and Computing,2004,14(3):199-222.
[6] PASCANU R,MIKOLOV T,BENGIO Y.On the difficulty of training recurrent neural networks[C]//Proceedings of the 30th International Conference on Machine Learning(ICML-13),2013:1310-1318.
[7] Hochreiter S,Schmidhuber J.Long short-term momory[J].Neural computation,1997,9(8):1735-1780.
[8] IOFFE S,SZEGEDY C.Batch normalization:accelerating deep network training by reducing internal covariate shift[C]//Proceedings of The 32nd International Conference on Machine Learning,2015:448-456.
[9] Saleh C,Dzakiyullah N R,Nugroho J B.Carbon dioxide emission prediction using support vector machine[C]//IOP Conference Series:Materials Science and Engineering.IOP Publishing,2016,114(1):012148.
[10]HOCHREITER S,SCHMIDHUBER J.Long short-term memory [J].Neural computation,1997,9(8):1735-1780.
猜你喜欢
今日农业(2021年11期)2021-11-27 10:47:17
环境科学研究(2021年6期)2021-06-23 02:39:54
环境科学研究(2021年4期)2021-04-25 02:42:02
少儿科学周刊·儿童版(2021年23期)2021-03-24 01:00:31
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
电子制作(2019年19期)2019-11-23 08:42:00
中国特种设备安全(2019年1期)2019-03-13 01:06:26
重型机械(2016年1期)2016-03-01 03:42:04
山东青年(2016年2期)2016-02-28 14:25:41
