
互联网隐式文本特征的提取
2018-01-17 09:26陈君
电子技术与软件工程 2017年23期
关键词:聚类算法
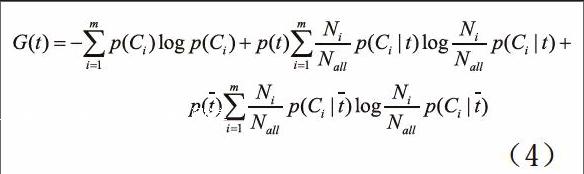

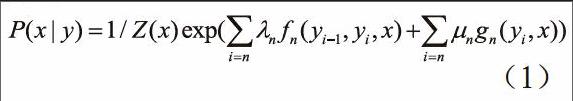
摘 要 随着互联网环境下大数据的极速膨胀,其文本信息也变得越发复杂,同时存在大量的隐式文本,针对隐式文本信息,当前缺乏有效的特征数据提取方法,为了解决该问题,提出了扩充CRFs模型的聚类提取方法。首先采用CRFs模型对候选文本对象进行建模,根据知识库扩充候选文本的特征词集合;然后利用聚类算法提取隐式文本对象集,经过迭代计算,得到特征词的匹配程度,并据此进行文本对象的分类;提出改进的特征去噪方法,结合权重计算提取得到目标文本对象。通过实验数据的分析,验证了本文提出的方法可以有效应用于隐式文本对象的特征数据提取上,提高了隐式文本特征提取的查全率和准确率。
【关键词】隐式文本 特征数据 CRFs模型 聚类算法
1 引言
当下人们大部分的信息数据都是来自互联网,个人用户可以通过评价对比某商品是否值得购买,企业可以通过搜集个人用户的评价和访问等行为指导企业发展方向。但是随着大数据的急速膨胀,如何从中提取出目标数据,成为了行业内亟待解决的难题。目前针对显式特征数据提取的研究比较众多,且较为完善,而对于隐式特征数据提取的研究,则寥寥无几。
为了更好地实现隐式特征数据的提取,本文提出了扩充CRFs模型的聚类提取方法。该方法适用于互联网环境下,中文隐式文本特征的提取,下面将对方法进行具体说明。
2 互联网隐式文本提取
2.1 候选对象CRFs模型
隐式文本对象的特征集具有不确定性,考虑到实际情况的复杂程度,结合CRFs模型进行互联网环境下的隐式文本的分析,其公式表示如下:
结合该模型分析隐式文本对象的优点是无需知道特征集的相互关系,并且可以在不改变模型本身的情况下,向模型中添加其它的新特征。在对隐式文本对象识别时,根据文本语句的语义和句式,将包含的名词、动词与形容词分别用np,vp,ap进行表示,于是,vp和ap可以用来表示候选隐式文本对象的特征词,而np则代表了文本语句包含的候选文本对象。根据np与vp,np与ap关系又可以构造得到二元组C(np,vp)与C(np,ap),通过得到的二元组信息便可以很好的反映出文本语句的主干。
2.2 特征词扩充
利用相似词汇以及相似短语对C(np,vp)与C(np,ap)构成的候选文本对象模型进行相应的合理扩充。扩充的方法采用HowNet知识库,该知识库不仅支持英语,对中文汉语也有很好的支持,采用将汉语文本词汇分割成最小语义的方法,实现对汉语文本词汇的识别。基于np,vp,ap属性文本词汇,利用HowNet知识库分割出最小语义npi,npj,vpk,并将它们放入特征词集合T,实现扩充,扩充后集合表示为T=(ap,N,A)或者T=(vp,N,V),N表示np的集合,A表示ap的集合,V表示vp的集合。至此,候选文本对象的模型可以表示为:C(np,T)。
2.3 候选文本对象的聚类
为了可以清晰引导文本语义,使用Kmeans对模型C(np,T)进行聚类计算。设定Kmeans算法的输入参数分别为聚类数与候选文本对象集,并依次表示为k、D,算法输出为聚类的结果。聚类处理的过程中,首先选定原始聚类中心Ki,选定的方法是在候选文本对象集中,任意抽取k数量的对象;然后通过迭代计算得到候选对象Cj和其它任何一个候选对象的匹配程度,并根据匹配程度把Cj放入匹配度最高的聚类里;再次计算得到新的Ki;最后判断算法是否达到成熟,如果没有成熟,重新返回迭代循环,相反则计算结束,结束的判断依据是:不再有新的Ki产生;Cj的聚类趋于稳定,不再发生变化。
在计算C(np,T)匹配程度的过程中,是通过集合T内部各元素间匹配程度的平均值计算而来,对于候选文本对象集中的任意两个元素Ci和Cj,它们的匹配程度计算如下:
2.4 隐式文本特征数据的识别
根据IG算法,对于某个特征项t,它对应C的增益计算公式为:
其中Ci是候选特征数据的类别集,p表示概率。利用IG可以对特征存在与否进行分析,特征不存在的分析对于隐式文本对象提取是很重要的,可是这种分析在文本的分类同时也增加了噪声的干扰,为了避免该问题的出现,采用改进IG算法,公式如下:
对于低频特征词或者稀疏特征词,该方法能够避免其权重的失效,因此结合权重计算有助于提高特征数据提取的准确度。
3 实验数据与结果分析
利用租房平台网页上下载的房源评论作为实验数据,来分析验证本文所提方法的性能。
3.1 扩展CRFs模型聚类结果
首先对基于扩展CRFs模型聚类的结果与常规聚类结果进行实验对比。由于租房人的需求不同,他们所关注房源的特征也有所差别,大部分租户关注的评价对象主要包括:租金、交通、地段、户型、面积、楼层、朝向、装修、租住方式、房屋配套设施、小区配套设施、周边配套设施。因此,根据列出的12项主要评价对象,实验中采用的聚类数取值为[5,12],并计算得到每种数量聚类的平均纯度,以此作为评价标准,实验结果如表1所示。
表1所示为扩展CRFs模型聚类的结果与常规聚类结果的数据对比,从表中数据分析能够看出,扩展CRFs模型聚类后的平均纯度更高,表明其聚类中,任意聚类只对应单个类别的成分更大。
3.2 隐式特征提取结果
实验中,是对隐式文本特征进行提取,因此,采用召回率和准确率来评价隐式特征提取的性能。针对不同聚类数,依次进行特征提取,同时,为了验证本文方法中改进IG去噪的性能,首先在不加入IG去噪时进行一次特征提取实验,实验结果如表2所示,然后加入IG去噪,使用本文提出的完整方法重新进行实验,实验结果如表3所示。
通过表2和表3的结果对比,清晰看出加入改进IG去噪方法后,准確率得到提高,说明该方法有效克服了特征数据的不均衡,滤除了模型建立过程中产生的噪声。
根据表3数据显示,本文提出的方法在聚类增加的时候,其召回率呈上升趋势,准确率也得到提高,当聚类达到一定程度的时候,准确率就会趋于稳定,通过实验结果,证明了所提方法在隐式特征数据提取中的有效性,并且具有良好的提取性能。
4 结束语
目前针对互联网环境下隐式特征数据提取问题的研究还有待于深入,尤其对中文文本的特征提取,缺乏有效方法,为此,本文提出一种隐式中文文本特征的提取方法。该方法首先通过CRFs模型获得特征词集,扩展后利用聚类算法得到隐式文本对象分类,再通过去噪处理,结合权重计算提取出隐式特征。通过实验对提出的方法进行验证,分别验证了扩展CRFs模型聚类的有效性,以及改进IG去噪的有效性,证明了所提方法提高了隐式文本特征提取的准确性和完整性。
参考文献
[1]胡海斌.引入特征倾向性的高仿网络文本数据挖掘[J].计算机仿真,2015,32(05):436-440.
[2]王晶晶,李寿山,黄磊.中文微博用户性别分类方法研究[J].中文信息学报,2014,28(06):150-155.
[3]甘丽新,万常选,刘德喜等.基于句法语义特征的中文实体关系抽取[J].计算机研究与发展,2016,53(02):284-302.
[4]李国,张春杰,张志远.一种基于加权LDA模型的文本聚类方法[J].中国民航大学学报,2016,34(02):46-51.
[5]ZHAO J,LIU K,WANG G.Adding redundant features for CRFs-based sentence sentiment classification[C].Proceedings of the Conference on Empirical Methods in Natural Language Processing,2008:117-126.
作者简介
陈君(1977-),女,湖北省汉川县人。硕士研究生。讲师。主要研究方向为计算机软件。
作者单位
湖北大学知行学院 湖北省武汉市 430011endprint
猜你喜欢
