
基于多模型融合的互联网信贷个人信用评估方法
2018-01-11 01:15:01白鹏飞NicolaasFransdeROOIJ周国富
华南师范大学学报(自然科学版) 2017年6期
白鹏飞, 安 琪, Nicolaas Frans de ROOIJ, 李 楠, 周国富,,3
(1. 华南师范大学华南先进光电子研究院, 广州 510006; 2. 深圳市国华光电科技有限公司, 深圳 518110;3. 深圳市国华光电研究院, 深圳 518110)
基于多模型融合的互联网信贷个人信用评估方法
白鹏飞1*, 安 琪1, Nicolaas Frans de ROOIJ2, 李 楠2, 周国富1,2,3
(1. 华南师范大学华南先进光电子研究院, 广州 510006; 2. 深圳市国华光电科技有限公司, 深圳 518110;3. 深圳市国华光电研究院, 深圳 518110)
针对网络个人信用有效评分缺失的问题,分析了互联网信贷个人信用评估数据的特点,选用支持向量机、随机森林和XGBoost分别建立了信用预测模型,并对3种单一模型进行了投票加权融合. 基于互联网信贷数据的特点,在特征工程中对样本集特征进行了离散化、归一化和特征组合等处理. 为增加对比,对实验数据集进行了FICO评估核心——Logistic回归分析. 实验结果表明:3种单一算法性能均优于Logistic回归,XGBoost表现优于支持向量机和随机森林模型,预测相对准确;投票融合模型的表现比单一模型更好,模型分辨能力更优秀,预测精度更高,更适用于互联网信贷个人信用评估.
个人信用评估; 互联网信贷; 支持向量机; 随机森林; XGBoost; 模型融合
近些年,随着互联网金融的不断发展,我国的信贷体系也发生了很大变化,出现了P2P网络借贷、微额小贷和消费分期付等互联网信贷形式. 信用风险是互联网信贷的最大风险[1],而由于我国的社会信用体系建设起步较晚,尚处于发展中,资金方与网络信贷用户存在信息不对称问题,导致用户很难借贷成功. 随着大数据技术的进步,基于数据挖据算法的个人信用评估模型为互联网信贷机构风控管理提供了可能.
与传统个人信贷评估数据不同,互联网个人信贷信用评估所用数据通常具备以下3个特点:(1)数据来源更多元,涵盖用户日常生活的方方面面,主要包括个人基本信息、银行信用类信息、通讯运营商信息、电商支付类信息及社交网络类信息这五大维度数据;(2)指标维度更高维,庞大的互联网数据造成样本变量数目出现爆炸性增长,达成千上万维,有价值信息密度变低;(3)数据模型更新更及时[2],时刻处在动态变化中,着重近期和正在发生的数据. 随着大数据技术在信用评分领域的发展,我们可以充分运用大数据技术对海量数据进行处理、匹配及整合,从中发掘出有用的信用信息,进而提高信用评分的准确性.
本文以互联网信贷平台真实数据作为研究样本集,选用支持向量机、随机森林和XGBoost分别建立了信用预测模型,并对3种单一模型进行了投票加权融合. 基于互联网信贷数据的特点,在特征工程中对样本集特征进行了离散化、归一化和特征组合等处理.
1 样本数据及数据处理
1.1 样本数据
采用国内某互联网小额信贷平台真实数据作为研究样本集,主要采集了用户基本信息、通讯运营商信息和社交网络类信息等. 为了用户及平台隐私,样本数据已做脱敏处理. 本数据集共有15 000个样本,正负样本比为9∶1. 每个样本包含1 138维特征,其中1 045维是数值特征,93维是类别特征. 为了检测模型的泛化能力,从原数据集中随机取12 000个样本为训练集,剩余3 000个样本为测试集.
1.2 数据处理
在对数据进行建模之前,需要对数据进行特征工程. 首先,原样本集中个别样本存在大量缺失属性值,对模型产生较大的干扰,需将其从原样本集中直接删除[3]. 然后对所有样本的缺失值进行填充:数值型缺失值采用均值填充,类别型缺失值作为特征新取值进行填充. 针对数值型特征,用最大最小规范法

(1)
进行数值归一化,式中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值. 针对类别型特征,采用独热编码进行0-1编码处理[4].
从统计上来说,原始特征仅仅是真实特征分布在低维空间的映射,不足以描述真实分布,若加入组合特征,则能在更高维空间拟合真实分布,同时兼顾全局模型和个性化模型,使得预测更准确. 本文对任意两原始特征a、b进行a-b、a+b、a×b、a/b和a2+b2等5种组合,计算其与标签列的皮尔逊相关系数;对任意3个原始特征计算(a-b)×c与标签列的皮尔逊相关系数,最终选择每类组合中排名前200位的特征加入到训练特征中. 因为连续特征的离散化对异常数据有很强的鲁棒性,能够使模型更稳定,所以将原始数据中所有连续的数值特征进行等量离散化到10个区间,用1~10表示,添加至训练数据集.
最后统计每个样本的特征处于各区间内的次数,得到10维计数特征,也加到训练特征集中.
2 评分模型
当前国内各大银行的信用评估主要是参考美国的FICO评分体系,其核心是Logistic回归算法[5]. 但是考虑到我国基本国情以及互联网信用数据的特点,一些新的基于大数据的机器学习算法更为适合[3]. 本文的评分模型是基于支持向量机、随机森林和XGBoost等3种算法,分别构建单模型和融合模型,并对比各模型预测表现. 所选用的3种单一模型具备很好的多样性,相关性较小,性能表现也较为接近,满足模型融合的基本条件.
2.1 支持向量机模型
支持向量机[6-7](Support Vector Machine,简称SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高泛化能力,实现经验风险和置信范围的最小化. 它在解决小样本、非线性及高维模式识别中表现出许多特有的优势.
支持向量机的基本思想是寻找一个满足分类要求的超平面,使其在保证分类精度的同时最大化超平面两侧的空白区域[8]. 针对线性不可分情况,通常引入核函数将非线性可分的特征向量空间映射到线性可分的特征向量空间,简化映射空间中的内积运算,避免直接在高维空间中进行计算,然后再利用线性可分的支持向量机进行分类.
设训练样本集D={xi,yi}(i=1,2,…,m),xin,yi{+1,-1},yi为输出. 把这m个样本点看作是n维空间中的点,如果存在一个分类超平面
(2)


图1 最优分类面示意图
要使分类间隔最大等价于使‖ω‖2/2最小,寻求最优分类面H的问题就转化为求解下面的最优化问题:
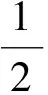
s.t.yi[ωTx+b]≥1 (i=1,2,…,m).
(3)
根据优化理论,可得线性可分条件下的分类决策树为
(4)
其中,b*是分类阈值,αi是每个样本对应的Lagrange乘子,αi不为零时所对应的样本就是支持向量.
在构建SVM模型时,核函数以及核参数的选取决定着SVM模型的最终表现. 为了使模型有较好的预测能力,本文采用径向基核函数作为支持向量机的内积核函数,利用网格搜索来选择径向基核函数的最优参数γ和惩罚因子C. 在对本文信用评估研究数据集特征选择中,采用了Filter方式的单变量相关系数法,从全部3 966维特征中选取出前1 000维最重要特征. 在此过程中SVM核函数参数γ和惩罚因子C设置在一定区间内取随机值,多次训练取平均值. 选出重要特征之后,再用网格搜索法确定最优参数,进而训练模型并对测试集预测信用程度.
2.2 随机森林模型
随机森林[9-10](Random Forest,简称RF)是通过自助法重采样技术,从原始训练样本集N中有放回地随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定. 单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品需要经过每一棵树分类决策,统计后的结果更接近于正确分类. 随机森林对多元共线性不敏感,对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用.
由于随机森林模型在训练过程中可以输出特征重要性排序,本文采用Embedded方法,从离散化特征、归一化特征、独热编码特征和组合特征等4类特征中分别选取前400名,构成1 200维的重要特征集,用于模型最终的训练和预测. 随机森林中最重要的参数是决策树的棵树,在参数调优中,通过网格搜索法确定出最优决策树棵树. 最后进行模型训练,代入测试集检验模型表现.
2.3 XGBoost模型
XGBoost[11-12](Extreme Gradient Boosting)是Gradient Boosting Decision Tree(简称GBDT)的一个C++实现. GBDT是Boosting型分类器,在生成每一棵树的时候采用梯度下降的思想,以之前生成的所有树为基础,向着最小化给定目标函数的方向多走一步. 与传统GBDT方式不同,XGBoost能够自动利用CPU的多线程进行并行,同时对损失函数进行了二阶的泰勒展开,并增加了正则项,用于权衡目标函数的下降和模型的复杂度.
设样本集D={xi,yi}(|D|=n,xim,yi),可由集成树模型得出预测值i=φ其中F={f(x)=ωq(x)}是所有树的集合,q代表树的结构部分,ω代表叶子权重部分,共T棵树.
设计整体目标函数为
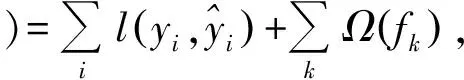
(5)
其中,Ω(f)=γT+‖ω‖2/2;l(φ)是损失函数,通常是凸函数,用于刻画预测值i和真实值yi的差异;Ω(φ)为模型的正则化项,用于降低模型的复杂度,减轻过拟合问题. 模型目标是最小化目标函数.
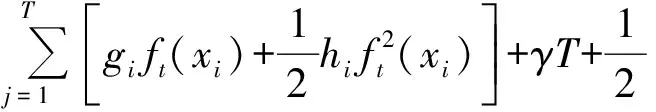
(6)
其中,gi是一阶导数,hi为二阶导数.
定义Ij={i|q(xi)=j}为叶子j的样本集合,则
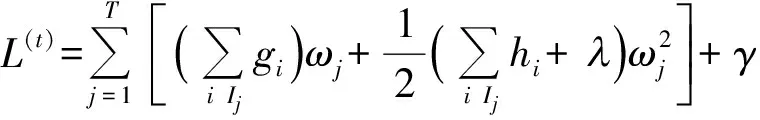
(7)
在树结构q已知时,式(7)中叶子节点权重ωj有闭式解,解和对应的目标函数值如下:
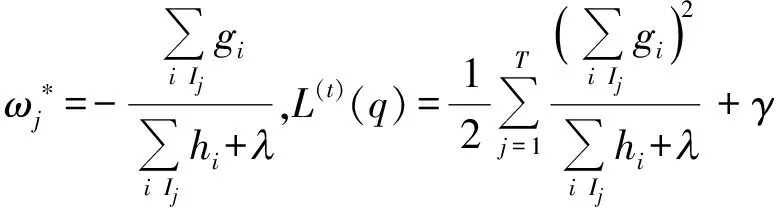
(8)
本文在XGBoost建模时,选择树模型为基分类器,AUC为模型表现的度量指标. XGBoost参数众多,但整体鲁棒性好,在大多数情况下,只需调节树深、最小叶子节点样本权重和、L2正则化系数等就能取得不错的效果. 利用Bagging的思想,分别对离散化特征、归一化特征、独热编码特征和组合特征进行单独模型训练并预测,然后对4类特征的预测值进行加权融合,最终得到XGBoost模型的预测结果.
2.4 融合模型
模型融合是一种以增加算法的多样性、减少泛化误差来提高模型准确率的强有力技术,分为Stacking、Blending和Voting等思路[13]. 模型融合有2个基本要素:一是单一模型之间的相关性要尽可能小,二是单一模型之间的性能表现相差不大. 在实践中,往往是相关系数较低且性能较好的单一模型融合之后能明显改善最终的预测结果[14-15]. 本文中随机森林是Bagging型算法,XGBoost是Boosting型算法. Bagging主要关注降低方差,而Boosting主要关注降低偏差. 这是2种完全不同的集成树学习策略. 另外,支持向量机不属于集成学习,它是一种基于结构风险最小化的机器学习算法. 可见本文3种单一算法具备很好的多样性,相关性较小,性能最终表现也较为接近,符合模型融合对单一模型的要求.
Stacking的基本思想是使用大量基分类器,然后使用另一种顶层分类器来融合基分类器的预测,旨在降低泛化误差. 相对于Stacking,Blending更加简单,用不相交的数据训练不同的基模型,将基模型的输出取平均.
实践中最常用的融合方法是Voting,即投票加权融合,它快速直接,只需要已建立模型在测试集上的预测结果,而不需要重新训练. 在投票时,加入相应权重,模型表现越好,其权重也就越高. 投票加权融合公式如下:
M融=n1M1+n2M2+…+nkMk,
(9)
其中n1+n2+…+nk=1.
本文采用简单加权投票的融合方法,对已经建立的SVM、RF和XGBoost等3种单一模型的预测结果进行模型融合,以期获得更准确的互联网信贷个人信用评估方法.
3 实验结果与分析
本文模型均在Python环境利用Scikit-Learn机器学习包实现. 模型的表现采用AUC值和F1分数指标来度量.F1分数是统计学中用来衡量二分类模型精确度的一种指标,同时兼顾了分类模型的准确率和召回率,是模型准确率和召回率的一种加权平均,最大值是1,最小值是0. ROC曲线通常被用来描述模型的分辨能力. 以假正率为横坐标,真正率为纵坐标绘制成曲线. 而曲线下面积(Area Under Curve,简称AUC)能更好地衡量ROC所表达结果的好坏,AUC值越大,代表模型的预测精度越高.
3.1 支持向量机建模
对于径向基核函数来说,最主要的参数是惩罚因子C和最优参数γ,其中C控制对误分样本的惩罚力度,γ用来控制最优分类面的形状. 利用单变量相关系数法选取出前1 000维最重要特征之后,用网格搜索法对参数寻优,最终确定当核参数γ为0.01、惩罚因子C为2时,SVM模型在验证集上的表现最佳.
最终,SVM模型的F1分数为0.778,AUC值为0.691 013.
3.2 随机森林建模
随机森林中决策树的棵树(设为Ntree)太多或者太少,效果都不好. 当Ntree较小时,随机森林的分类误差大,性能也比较差. 当树的棵数增大到一定值后,模型性能基本稳定了,再增加Ntree只会增加计算量. 同时森林的规模达到一定程度时,将导致森林的可解释性减弱. 利用网格搜索方法,确定了当树的棵树为450时模型效果最好.
经过RF模型的训练,代入测试集进行预测,最终得出F1分数为0.748,AUC值为0.680 278. RF模型在测试集上的表现不如SVM.
3.3 XGBoost建模
首先,在利用Bagging的思想分别对离散化特征、归一化特征、独热编码特征和组合特征单独训练并预测时,为了减少运算量同时能保证模型的精确度,采取对主要参数加入扰动的方式增加多样性,在一定范围内随机取值,训练10次取预测平均值.
然后对4类特征的预测结果进行加权融合(表1),权重比例为1∶1∶2∶6,最终得到F1分数为0.802,AUC值为0.714 592. 可以看出,XGBoost的表现优于SVM和RF模型.
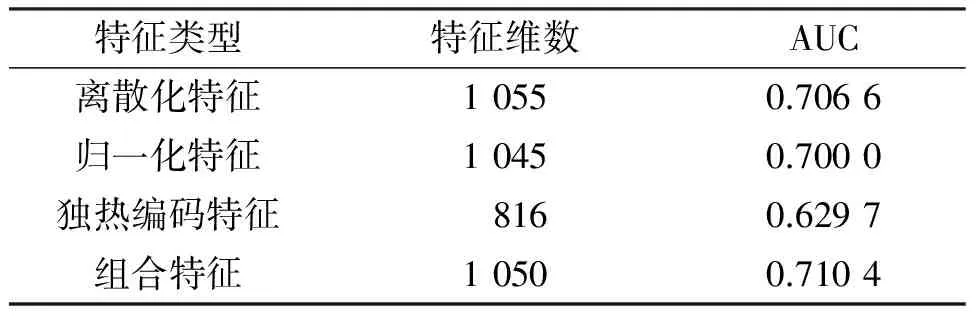
表1 XGBoost的加权融合Table 1 Weighted fusion of XGBoost
3.4 模型融合
最后对已建立的SVM、RF和XGBoost等3种模型的预测结果进行简单加权投票融合,经网格寻优得出SVM、RF、XGBoost的最佳权重比例为1∶1∶8. 投票之后融合模型的F1分数为0.806,AUC得分为0.714 941. 融合后的模型优于单个模型的表现(表2和图2). 说明基于多模型融合的互联网信贷个人信用评估方法能有效改善评分精确度,有助于信贷平台风险控制的健康发展. 本文在4G内存Linux系统条件下实验,各模型单次运行所占用的CPU时间(tCPU)见表2. 建立融合模型时,3种单一算法同时运行,得到结果之后执行融合,总计算用时有一定程度的增加,但在可接受范围之内.

表2 单一模型投票融合Table 2 Voting ensemble of single models
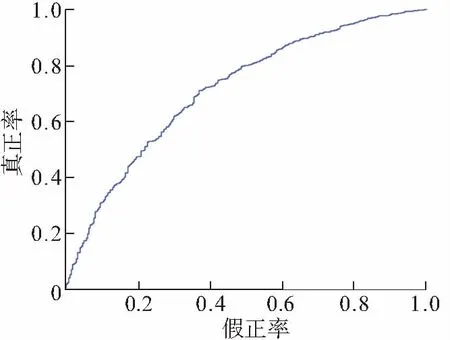
图2 投票融合模型的ROC曲线
4 结束语
信用评估对互联网个人信贷风险控制至关重要,本文根据互联网信用数据的特点,基于支持向量机、随机森林和XGBoost分别建立了预测模型,并对3种单一模型进行投票加权融合. 采用F1分数和AUC值对模型表现进行对比,实验结果表明:XGBoost模型表现优于SVM和RF,投票融合模型的预测结果比单一模型更好,评分精确度更高,更适用于互联网信贷个人信用的评估.
[1] 易宪容. 当前互联网金融最大风险是信用风险[N]. 证券日报,2014-03-08(B02).
[2] 武安华. 互联网个人信用评分研究[J]. 中国金融,2016(16):46-47.
[3] 向晖,杨胜刚. 个人信用评分关键技术研究的新进展[J]. 财经理论与实践,2011(4):20-24.
XIANG H,YANG S G. Recent development in key techniques of credit scoring[J]. The Theory and Practice of Finance and Economics,2011(4):20-24.
[4] 向晖. 个人信用评分组合模型研究与应用[D]. 长沙:湖南大学,2011.
XIANG H. Research on ensemble model for credit scoring and its application[D]. Changsha:Hunan University,2011.
[5] 刘新海. 运用大数据开展P2P信用风险评估的Upstart[J]. 征信,2016(6):18-20.
LIU X H. Upstart:a company making P2P credit risk assessment based on big data[J]. Credit Reference,2016(6):18-20.
[6] VAPNIK V. The nature of statistical learning theory[M]. New York:Springer,1995.
[7] VAPNIK N. Statistical learning theory[M]. New York:Springer,1999.
[8] 肖智,李文娟. 基于主成分分析和支持向量机的个人信用评估[J]. 技术经济,2010(3):69-72.
XIAO Z,LI W J. Personal credit scoring based on PCA and SVM[J]. Technology Economics,2010(3):69-72.
[9] BREIMAN L,FRIEDMAN J H,OLSHEN R A,et al. Classification and regression trees[M]. Belmont:Wadsworth,1984.
[10] BREIMAN L. Random forests[J]. Machine Learning,2001,45:5-32.
[11] CHEN T Q,GUESTRIN C. XGBoost:a scalable tree boosting system[C]∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM,2016:785-794.
[12] CHEN T Q,LI H,YANG Q,et al. General functional matrix factorization using gradient boosting[J]. Proceedings of the 30th International Conference on Machine Learning,2013,28:436-444.
[13] ROHAVI R,ROHAVI R. An empirical comparison of voting classification algorithms:bagging,boosting and variants[J]. Machine Learning,1999,36:105-139.
[14] KITTLER J,HATEF M,DUIN R P W,et a1. On combining classifiers[J]. IEEE Transactions on Pattern Analysis and Machine Learning,1998,20(3):226-239.
[15] JAIN A K,DUIN R,MAO J C. Statistical pattern recognition:a review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(1):4-37.
Internet Credit Personal Credit Assessing Method Based on Multi-Model Ensemble
BAI Pengfei1*, AN Qi1, Nicolaas Frans de ROOIJ2, LI Nan2, ZHOU Guofu1,2,3
(1. South China Academy of Advanced Optoelectronics, South China Normal University, Guangzhou 510006, China; 2. Shenzhen Guohua Optoelectronics Technology Co., Ltd, Shenzhen 518110, China;3. Academy of Shenzhen Guohua Optoelectronics, Shenzhen 518110, China)
To solve the problem of the missing of the effective scores of online personal credits, the characteristics of internet personal credit assessment data are analyzed. Support vector machine (SVM), random forest (RF), and XGBoost have been adopted to establish the credit forecasting model in the paper, respectively. The voting fusion of the proposed models is conducted. Based on the data characteristics of internet credit data, discretization, normalization, and feature combination are adopted to experimental data set in feature engineering. In order to improve the contrast, the logistic regression analysis-the core of FICO assessment is carried out. The experimental results show that the performance of the three established algorithm are better than logistic regression. The performance of XGBoost are better than SVM and RF model in the accuracy prediction. The performance of voting fusion model is better than that of single model, with outstanding model resolution and prediction accuracy, which is more suitable for internet personal credit assessment.
personal credit assessing; online lending; support vector machine; random forest; XGBoost; model ensemble
2017-03-06 《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
国家自然科学基金委员会-荷兰国家基金机构间合作重点项目(NSFC-NWO)(51561135014);教育部“长江学者和创新团队发展计划”资助项目(IRT13064);广东省引进创新科研团队计划项目(2013C102);广东省科技计划项目(2014B090914004,2016B090918083);广东省引进第四批领军人才专项资金项目(2014);深科技创新【2015】291号科技金融股权投资项目(GQYCZZ20150721150406);国家高等学校学科创新引智计划111引智基地(光信息创新引智基地)
*通讯作者:白鹏飞,副研究员,Email:Baipf@scnu.edu.cn.
TP39
A
1000-5463(2017)06-0119-05
【中文责编:庄晓琼 英文审校:叶颀】
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
成都信息工程大学学报(2020年2期)2020-08-24 08:05:36
法大研究生(2020年2期)2020-01-19 01:43:22
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
汽车与安全(2016年5期)2016-12-01 05:22:05
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
