
基于相关性密度的多变量时间序列属性选择
2018-01-03 01:58:49张坤华丁立新万润泽
计算机应用与软件 2017年12期
张坤华 丁立新 万润泽
(武汉大学计算机学院 湖北 武汉 430072)
基于相关性密度的多变量时间序列属性选择
张坤华 丁立新 万润泽
(武汉大学计算机学院 湖北 武汉 430072)
属性选择是一种有效的数据预处理方法。为了移除多变量时间序列属性集中的冗余属性和噪声属性,选择出包含足够原始信息并能提高精度的属性子集,提出一种基于相关性密度的属性选择算法。该算法使用相关性矩阵表示原多变量时间序列,定义每个属性的局部密度来表示属性的代表性,定义属性的判别距离作为该属性与其他属性间的区分度。最后根据决策图的分布来筛选具有较大代表性和区分度的属性。使用SVM分类器对UCI数据库中的4种不同数据集进行实验,实验结果表明该算法相比已有算法在分类准确度和时间效率上均有一定的优越性。
多变量时间序列 相关性矩阵 决策图 密度 属性选择
0 引 言
时间序列是指一组按时间顺序排列的数据,并广泛应用于众多领域,如金融股市预测[1]、医疗数据记录[2]、气象预报[3]和工业产品质量控制分析[4]等。根据时间序列中记录的变量个数,时间序列又分为单变量时间序列UTS(Univariate Time Series)和多变量时间序列MTS(Multivariate Time Series)[5]。相比单变量时间序列,多变量时间序列同时具有时间维和变量维的信息,提供的数据信息更丰富,但给后续的针对多变量时间序列的挖掘研究分析和数据挖掘任务提高了难度,因此对多变量时间序列降维预处理是十分必要的。多变量时间序列的降维,主要分为特征表示和属性选择,特征表示将原时间序列映射到另一低维空间,并尽可能地表达原时间序列信息[6],但却失去了与原空间特征间的一一对应关系和实际物理意义,不便于后续理解和认知。属性选择是从原时间序列的高维空间中挑选出一组最有代表性的变量属性[7],在筛选后的属性子集中进行后续操作,以提高效率和精度。本文主要针对多变量时间序列的变量维数约简,即属性选择。
目前很多学者对多变量时间序列属性选择作了深入研究,并提出了一些优化算法。文献[8]提出了基于度量学习的无监督属性选择算法。文献[9]提出了基于分形维数计算和离散粒子群优化的属性选择算法。文献[10]提出了基于RFE的属性选择算法。相对经典的算法是文献[11]提出了基于公共主成分属性选择算法(CleVer)。该算法基于以下假设:在所有的多变量时间序列中存在一个由正交向量构成的公共子空间,各序列在该公共子空间上的投影能够最大程度地体现出差异性,投影后获得与所有序列主成分最接近的描述公共主成分,根据每个属性对描述公共主成分的贡献度进行排名,从排名高的属性集中筛选属性子集,但在实际情况中,一个MTS数据集会存在多个不同的类别,将不同类别的子空间投影为一类,造成了信息损失[12]。文献[13]提出基于互信息和类可分离性的属性选择算法(CSFS),由类可分离性引申出属性可分离性,将其定义为属性间离散矩阵和已选属性子集离散矩阵的比值,用于评估属性间的冗余度,使用互信息对MTS进行特征提取后,根据冗余度降序排列进行属性选择。然而利用互信息计算相关性时,计算变量间的概率密度函数是十分困难的,需要借助其他函数估计互信息值,时间复杂度较高[14],且基于类可分离性是一种监督方法,在数据缺失类标信息时,该算法得不到较好的应用。文献[15]提出一种增量互相关过滤式属性选择算法(ICF),该算法通过滑动点积计算两个传感器时间序列的偏移量作为属性间冗余度,设定冗余度阈值去除冗余属性和噪声属性,最后基于迭代应用程序中的一组选择消除规则进行前向式属性选择,但如何选取最优的阈值尚未明确。
基于密度的快速聚类算法[16]由Rodriguez等提出,该算法认为聚类中心具有较高的局部密度和与其他高密度样本较远的特点,通过构建样本点和类之间的隶属关系,发现任意维度和形状的样本中最大密度点群。Liu P等[17]使用该算法进行文本聚类,实验结果表明该算法在提高文本聚类性能和降低误报率上均取得明显效果。Chen等[18]利用该算法实现纤维束的自动分割,通过聚类图像获取感兴趣的光纤束,聚类结果与描述纤维束显示了高度一致性。Sun等[19]利用该算法完成高光谱图像波段筛选,将筛选后的波段完成地物分类,并验证有效性。
本文在快速聚类算法基础上,提出一种有效的多变量时间序列属性选择算法,具有以下特点:1) 将原多变量时间序列转为相关性矩阵,降维同时获取属性间的相关关系;2) 提出基于属性相关性密度排序的属性子集选择方法ACDR(attribute subset selection based on attribute correlation density ranking),定义多变量时间序列属性的局部密度表示该属性的代表度,定义属性的判别距离表示与其他属性的区分度,根据上述两个量绘制出决策图,根据决策图的分布筛选出最优属性子集。将筛选后的属性子集代替原属性集,并与文献[11-13]中所提算法在分类准确率上和时间效率上进行对比。
1 多变量时间序列属性选择方法
1.1 多变量时间序列表示
一个多变量时间序列X可以使用n×m的矩阵表示,记为X=(X1,X2,…,Xm)=(xij)n×m。
式中:m代表变量维度即属性个数,n代表时间维度,Xi表示第i维长度为n的属性序列,t=1,2,…,n,xij表示第j维属性在第i时的记录值,且一般情况下n≫m,当m=1时,该时间序列为单变量时间序列。
1.2 多变量时间序列相似性度量
假设存在两个多变量时间序列(MTS),分别为Xn1×m1和Xn2×m2。通常在同一个数据集中,这两个MTS包含的属性个数相同,但是时间长度可能不同,即m1=m2,n1≠n2。此时计算两个MTS之间的相似度存在以下问题: 1) 当两个MTS长度不相等时不能直接使用欧式距离度量公式计算其相似性,而使用DTW算法[20]虽然支持伸缩时间轴,但计算复杂度高,当序列维度较大时适用性不强;2) 多变量时间序列不是多个单变量时间序列的简单组合,属性之间往往存在重要关联,若直接拼接成行向量,会造成属性间相关信息的丢失。为克服以上问题,本文使用相关性矩阵代替原时间序列,具体步骤如下:
1.2.1 计算MTS属性间相关性
定义1Xi和Xj分别为MTS的第i维和第j维属性,Xi=(x1i,x2i,…,xni)T,Xj=(x1j,x2j,…,xnj)T,则它们之间的相关性可表示为:

(1)

(2)
(3)
R(Xi,Xj)值取-1到1之间,正值表示两个属性间正相关,负值表示负相关,零表示无相关性,即两个属性是独立的。
1.2.2 计算相关性矩阵
通过计算MTS中属性间相关性,一个数据集中第j个MTS即可表示为Mj(j=1,2,…,n),即:
通常一个有意义的多变量时间序列观察值n≫m,原多变量时间序列转化为相关性矩阵后维度由n×m降为m×m,数据规模大大减小,且保留了属性间相关关系信息,相关性矩阵大小只与属性个数有关,与时间长度无关,有利于非等长MTS间相似性度量。使用相关性矩阵表示的两个MTS间的相似度为:
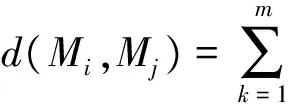
(4)
式中:m为MTS的属性维度,‖*‖为欧氏距离。
1.3 属性的代表度和区分度
样本间的相似度表示除了距离度量、信息度量、还有相关性度量和一致性度量[21],本文使用属性间的相关性来衡量其相似度。
定义2一个多变量时间序列任意两个属性间的相似度为:
d(Xi,Xj)=R(Xi,Xj)
(5)
式中:R(Xi,Xj)为式(1)中的计算结果。
定义3属性Xi序列的局部密度ρi定义为:
(6)
(7)
也可以用高斯核函数形式表示:
(8)
式中:dij表示属性Xi到属性Xj间的相似度距离,dc表示截断距离,Rodriguez等[16]指出dc值的选择标准为:使每个样本点近邻数约为样本总数的1%~2%时聚类效果较好,本文实验中取2%,局部密度ρi越大,表示该属性在局部邻域内越稠密,属性的代表度越高。
定义4定义属性Xi序列的判别距离δi为:
(9)
δi为该属性到比该属性局部密度更大属性的最小距离,当属性Xi的具有最大局部密度时,δi=maxj(dij),δi越大表示,该属性与其他属性间的区分度越大,说明属性Xi与属性Xj的冗余度越小。
1.4 决策图
计算出局部密度ρi和判别距离δi后,根据这两个值绘制决策图。选取UCI数据库中的BCI数据集,该数据集属性个数为28个,该数据集属性生成的决策图如图1所示。
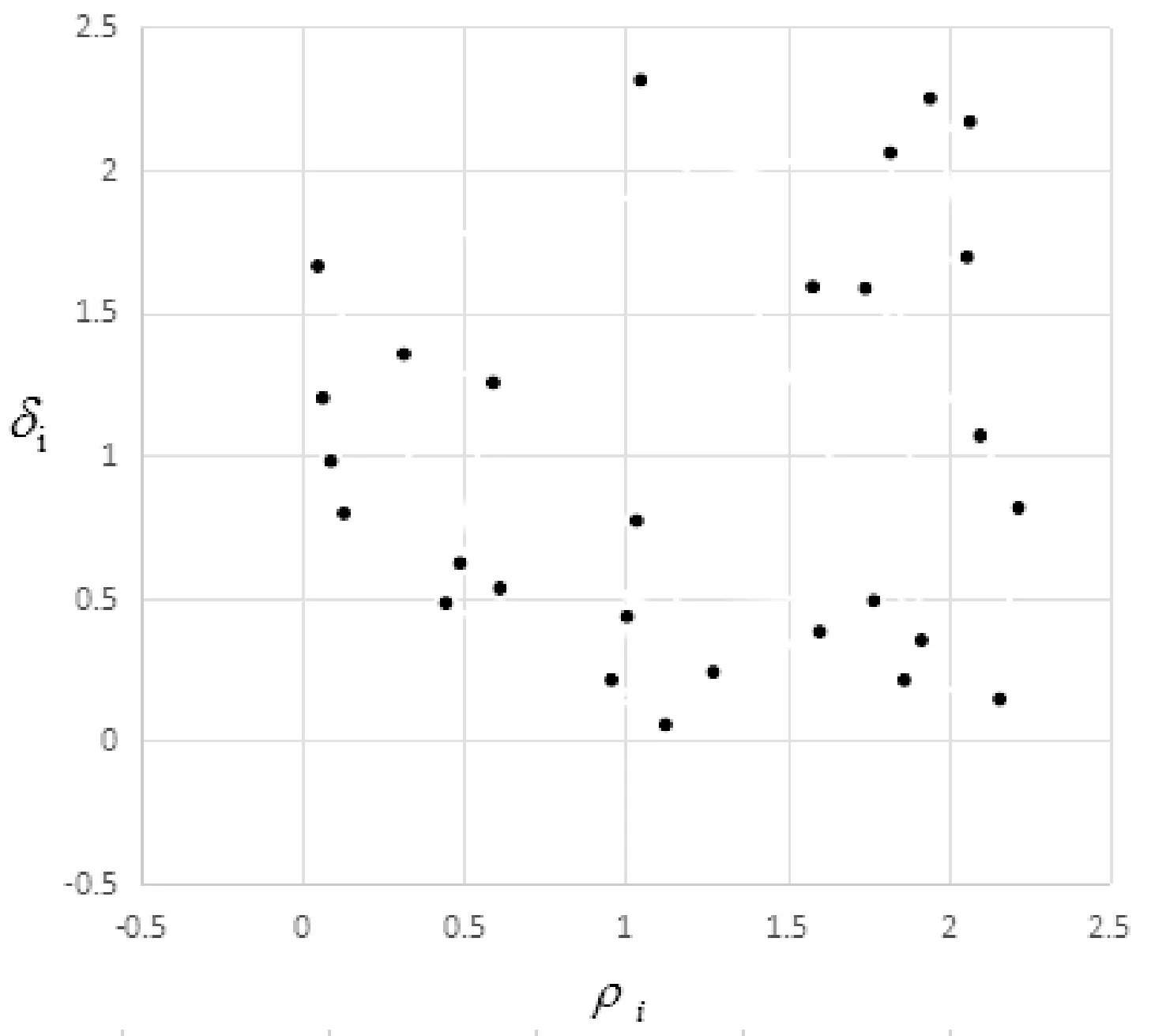
图1 BCI数据集决策图
根据定义3和定义4可知,具有较高代表度、区分度的属性,位于决策图中的右上区域。
定义5选择参考指数ri
从决策图中可以直观地看出重要度不同的属性位置相差较大,我们需要的是选取同时具有较大δi值和较大ρi值的属性作为特征属性,如果手动选取则会非常耗时,为此,本文定义了参考指数ri,计算δi和ρi乘积作为选择参考指数,表示为:
ri=δi×ρi
(10)
按照ri的降序排列,依次选取选取前k个属性构成属性子集。

图2 BCI属性参考指数排序图
通过以上分析,本文算法具有以下几个特点:1) 使用相关性矩阵表示原多变量时间序列,保留多变量时间序列属性间相关关系并降低时间复杂度,提高后续计算效率;2) 该算法是无监督属性选择算法,在缺少类标信息的时间序列中也能得到应用,克服缺少类标签或获取代价较大的缺点;3) 首次将快速聚类算法[16]应用于多变量时间序列的属性选择,根据选择参考指数排名来筛选属性;4) 无需进行子集搜索,可以在短时间内完成计算,避免子集搜索引起的局部最优;5) 可以通过下降值的拐点来确定最优属性子集的个数。
2 算法流程
问题描述:给定一个多变量时间序列集合X=(X1,X2,…,Xm),包含m种属性,且每种属性对应一个时间序列,寻找时间序列X的属性子集X′,使其满足:
X′={X1,X2,…,Xk}⊂X={X1,X2,…,Xm},k≪m
算法基于相关性密度的多变量时间序列属性选择
输入:多变量时间序列X
输出:X的属性子集X′
1:计算该时间序列每个属性和其他属性间相关性R(Xi,Xj)
2:得到该时间序列的相关性矩阵M
3:计算时间序列每个属性的局部密度ρi
4:计算时间序列每个属性的判别距离δi
5:计算每个属性选择参考指数ri=δi×ρi
6:对ri排序,选取相关性矩阵M中前k个属性构成属性子集
3 实验结果和分析
3.1 实验数据
本文使用的数据是来自UCI数据库中的4种数据集,分别为EEG、BCI、JV、Wafer。其中EEG为一组醉酒者和正常人群通过采样频率为256 Hz在受试者头部放置的64个采样点采集时长为1 s的脑电图数据,BCI为一组采集左右手运动对应的28个皮层电位信息数据,JV为一组记录9位日本男性的12个LPC同态普数据描述的发音过程数据,Wafer为一组记录晶硅体生产过程放置的6个传感器记录的微电子序列数据,表1为4种数据集的详细信息描述。采用LIBSVM[22]程序包实现的线性核支持向量机(SVM)作为分类器,采用10倍交叉验证,将每个数据集分成训练和测试数据集,以准确率作为分类结果评价指标。准确率定义如下:
准确率=正确分类的样本数/总样本数
为消除实验结果的偶然性和平台环境的不稳定性对实验结果造成的影响,每次实验都是重复10次并取平均值,本文的所有实验均在表2所示的实验环境中完成。

表1 数据集描述

表2 实验环境及配置
3.2 实验结果及分析
将本文算法ACDR与已有的3种多变量时间序列属性选择算法CleVer[11]、CSFS[13]、ICF[15]在表1中4种数据集上进行实验,通过比较分类准确率和运行时间来评估本文算法的有效性和优越性。4种算法在不同数据集中的分类准确率结果分别如图3-图6所示,横坐标表示选择属性的个数,纵坐标为分类准确率。4种算法的最优分类准确率和平均分类准确率如表3所示,各算法的运行时间如表4所示,其中粗体表示最优结果。

图3 EEG数据集分类结果

图4 BCI数据集分类结果

图5 JV数据集分类结果

图6 Wafer数据集分类结果

数据集算法最优准确率/%平均准确率/%EEGACDR98.4292.43CSFS97.9692.04ICF97.5090.15CleVer95.6087.02BCIACDR78.3174.54CSFS77.2873.80ICF70.9166.78CleVer67.4759.77JVACDR72.4871.63CSFS74.1772.02ICF71.2270.10CleVer72.6069.50WaferACDR90.8776.15CSFS84.8179.11ICF85.3173.70CleVer84.8171.29

表4 4种算法的运行时间
由图3~图6可以看出,在EEG数据集中,当属性维数为1~35时,本文算法性能与其他3种算法相差无几,当属性维数为36~64时,本文算法优势逐渐显著。在BCI数据集中,除个别维数外,本文算法分类准确率上均高于其他3种算法。在JV数据集中,本文算法的分类效果较为平稳,分类效果整体上优于ICF算法和CleVer算法,当属性个数为1~5时,分类准确率仅次于CSFS算法,当属性个数为6~12时,准确率和CSFS算法、CleVer算法相持平。在Wafer数据集中,本文算法性能不太稳定,当属性个数为2~3时,本文算法性能低于CSFS算法,属性个数为4时,分类性能低于CSFS算法和ICF算法,但当属性个数为5时,却达到了最优准确率,当属性个数为6时,性能与其他3种算法趋于一致。
由表3可知,本文算法在EEG和BCI数据集中均取得了最高的最优分类准确率和平均分类准确率。在JV数据集中,分类性能仅次于CSFS算法,准确率分别高出ICF算法1.26%、1.53%,平均分类性能高于CleVer算法3.13%。在Wafer数据集中,本文算法获得了最优分类准确率,平均分类准确率仅次于CSFS算法,准确率分别高于ICF算法5.56%、2.45%,CleVer算法6.06%、4.86%。综合可知,在四种算法中,本文算法和CSFS算法相对于ICF算法和CleVer算法分类性能有较明显的优势,并在不同数据集中分别获得了最优分类性能。
由表4可知,4种算法中,CSFS算法的平均时间开销最大,CleVer次之,本文算法和ICF算法相差无几。本文算法在4种数据集上的平均运行时间分别为CSFS算法平均运行时间的19.52%、CleVer算法平均运行时间的43.79%,ICF算法93.02%,并在BCI数据集和Wafer数据集中取得了最优时间效率。
综合以上可知,在分类准确率上,本文算法和CSFS算法在不同数据集中均明显优于ICF算法和CleVer算法。在运行效率上,本文算法和ICF算法明显优于CSFS算法和CleVer算法。由于CSFS是一种监督的属性选择算法,平均分类准确率虽较高,但时间开销大,而ICF算法运行效率高,但在4种数据集中的准确率均不如本文算法,故本文算法在综合分类准确率和时间效率整体性能上较其他3种算法更优。
4 结 语
针对现有的多变量时间序列属性选择算法准确率不高、时间复杂度高的情况,提出了一种基于相关性密度的多变量时间序列属性选择算法,将原多变量时间序列转为相关性矩阵,根据属性相关性密度进行选择,选择的过程可以被看作是聚类过程,聚类中心可以作为属性集的代表属性,并与其他属性具有较少的冗余度,根据定义计算出属性的局部密度和判别距离后绘制决策图并根据参考指数排名选择属性。对UCI数据库中4种数据集的实验结果分析表明,在综合分类准确率和时间效率整体性能上,本文算法是一种有效的多变量时间序列属性选择方法。此外,属性参考指数排序图中可以看出有明显的拐点,在接下来的工作中,将围绕确定图中下降值的拐点来选择时间序列最优属性子集的个数。
[1] Sun X,Chen H,Wu Z,et al.Multifractal analysis of Hang Seng index in Hong Kong stock market[J].Physica A Statistical Mechanics & Its Applications,2001,291(1-4):553-562.
[2] Peng C K,Havlin S,Stanley H E,et al.Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series[J].Chaos An Interdisciplinary Journal of Nonlinear Science,1995,5(1):82-87.
[3] Temme C,Ebinghaus R,Einax J W,et al.Time series analysis of long-term data sets of atmospheric mercury concentrations[J].Analytical & Bioanalytical Chemistry,2004,380(3):493.
[4] 张延华,王国刚,李朋辉.基于时间序列的挖掘算法在流程工业产品质量控制模型中的应用[J].数学的实践与认识,2010,40(5):87-90.
[5] Vlachos M,Hadjieleftheriou M,Gunopulos D,et al.Indexing Multidimensional Time-Series[J].The VLDB Journal,2006,15(1):1-20.
[6] Wang X,Mueen A,Ding H,et al.Experimental comparison of representation methods and distance measures for time series data[J].Data Mining and Knowledge Discovery,2013,26(2):275-309.
[7] Mao Y,Zhou X B,Xia Z,et al.Survey for study of feature selection algorithms[J].Pattern Recognition & Artificial Intelligence,2007,20(2):211-218.
[8] 郑宝芬,苏宏业,罗林.无监督特征选择在时间序列数据挖掘中的应用[J].仪器仪表学报,2014,35(4):834-840.
[9] 吴虎胜,张凤鸣,徐显亮,等.多变量时间序列的无监督属性选择算法[J].模式识别与人工智能,2013,26(10):916-923.
[10] Lal T N,Schröder M,Hinterberger T,et al.Support vector channel selection in BCI.[J].IEEE Transactions on Biomedical Engineering,2004,51(6):1003-1010.
[11] Yoon H,Yang K,Shahabi C.Feature Subset Selection and Feature Ranking for Multivariate Time Series[J].IEEE Transactions on Knowledge & Data Engineering,2005,17(9):1186-1198.
[12] Li H.Accurate and efficient classification based on common principal components analysis for multivariate time series[J].Neurocomputing,2015,171(C):744-753.
[13] Han M,Liu X.Feature selection techniques with class separability for multivariate time series[J].Neurocomputing,2013,110(8):29-34.
[14] Sakar C O,Kursun O.A method for combining mutual information and canonical correlation analysis:Predictive Mutual Information and its use in feature selection[J].Expert Systems with Applications,2012,39(3):3333-3344.
[15] Bacciu D.Unsupervised feature selection for sensor time-series in pervasive computing applications[J].Neural Computing and Applications,2016,27(5):1-15.
[16] Rodriguez A,Laio A.Clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[17] Liu P,Liu Y,Hou X,et al.A Text Clustering Algorithm Based on Find of Density Peaks[C]//International Conference on Information Technology in Medicine and Education,2015:348-352.
[18] Chen P,Fan X,Liu R,et al.Fiber segmentation using a density-peaks clustering algorithm[C]//IEEE,International Symposium on Biomedical Imaging.IEEE,2015:633-637.
[19] Sun K,Geng X,Ji L.Exemplar Component Analysis:A Fast Band Selection Method for Hyperspectral Imagery[J].IEEE Geoscience & Remote Sensing Letters,2015,12(5):998-1002.
[20] Keogh E,Ratanamahatana C A.Exact indexing of dynamic time warping[J].Knowledge & Information Systems,2005,7(3):358-386.
[21] 王娟,慈林林,姚康泽.特征选择方法综述[J].计算机工程与科学,2005,27(12):68-71.
[22] Chang C C,Lin C J.LIBSVM:A library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology,2011,2(3):1-27.
MULTIVARIATETIMESERIESATTRIBUTESELECTIONBASEDONCORRELATIONDENSITY
Zhang Kunhua Ding Lixin Wan Runze
(SchoolofComputerScience,WuhanUniversity,Wuhan430072,Hubei,China)
Attribute selection is an effective data preprocessing method. Aiming at removing redundant or noisy attributes from the multivariate time series attribute set and selecting an attribute subset containing enough original information to improve accuracy, an attribute selection algorithm based on correlation density is proposed. The algorithm employed in the correlation matrix to represent the original multivariate time series, the local density of each attribute to show its representative ability, the distance discriminant between attributes as their discriminant degree. Moreover, attributes with larger representativeness and discriminant degree were filtered according to the distribution of the decision graph. Experiments with SVM classifier on four different datasets from the UCI repository were performed. The experimental results demonstrate the great improvement of the proposed algorithm in classification accuracy and time efficiency when compared with the existing algorithms.
Multivariate time series Correlation matrix Decision graph Density Attribute selection
2017-02-23。湖北省自然科学基金面上项目(2015CFB405);湖北省教育厅科学技术研究项目(Q20153003)。张坤华,硕士生,主研领域:时间序列降维,相似度度量。丁立新,教授。万润泽,副教授。
TP391
A
10.3969/j.issn.1000-386x.2017.12.052
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:08
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
