
大数据位置类应用实现方式研究
2017-12-28 09:31董昭李娟张海峰张天骁
互联网天地 2017年8期
□ 文 董昭 李娟 张海峰 张天骁
大数据位置类应用实现方式研究
□ 文 董昭 李娟 张海峰 张天骁
一、前言
大数据技术日益发展成熟,已经在互联网尤其是电商、社交、搜索等领域取得了较为成熟的应用。电信运营商拥有多年的数据积累,数据已成为一种商业资本和一项重要的经济投入,而如何应用和挖掘海量数据,则成为运营商赢得市场的关键因素。
为满足政府、商业机构及公司内部市场部分的需求,电信运营商需洞察一定区域范围内的人群位置信息,推出基于位置信令等数据的统计、分析和挖掘服务。交通运输、城市安全、智慧旅游、商业经营等均是规模庞大、潜力巨大的市场。
二、应用场景分析
大数据位置类应用是基于位置信令等数据的统计、分析和挖掘的服务,为机构选址、城市规划、智慧旅游等场景提供解决方案。主要的产品形态和服务形态为结合地理信息的GIS数据产品及服务,面向用户的实时位置查询API服务。具体如下:
(一) 机构选址
基于大数据位置类信息,结合用户特征信息,对特定区域进行人口流动性分析,面向零售、餐饮、娱乐服务等商家在辅助选址和顾客分析方面提供高效的信息获取、全面的信息汇聚和深度的客户洞察等数据应用服务,寻求提升商家在某个区域竞争力的机会。
(二) 城市规划
区域商圈规划:根据城市特点和人群分布结构,合理规划区域和商圈,分摊核心区域压力。
交通规划设计:根据人群分布和通勤特点,科学合理制定交通路线、站台位置等,提高城市交通效率。
建设项目选址:根据建设项目和人群特点,合理规划项目位置。
(三) 公共区域安全监测
特定区域监控:在特定区域内全方位常态监控人群流量、密度、驻留时间等,以及在特定区域内人群流量或密度突增时触发预警。
区域智能预警:监控、预警未知区域的人群突增,即根据区域历史数据建模输出区域内人群突增三个级别的预警参考值,依据参考值设置预警指标值,满足未知区域人群突增智能预警。
(四) 城市交通
高速公路监控:交通枢纽、事故多发地段车流量监控、高速分路段通畅情况监控。监控情况和交通部门现有摄像监控、车速监控雷达结合,形成对外消息发布和预警及处理信息。
(五) 智慧旅游
通过对景点的游客来源、驻留时长、组成特征进行多维度分析,为景区精细化营销、景点路线规划与服务提升提供数据支撑。还可进行游客来源分析,逗留时长分析,旅游路线分析,景区热度分析,优化最佳旅游路线,科学调配旅游资源。
通过上面的分析我们看到,如果运营商要发展位置类自有产品,具有四点优势:
第一,使用壁垒低。用户可随时随地无需受到硬件限制即可获得位置服务,而GPS定位需要硬件支持,成本高、普及难度大;

第二,适用人群广。只要有手机,都可以使用,而“签到”定位及GPS定位适用于年轻群体及偏好高新技术群体;
第三,实时性高。具有地图数据、交通路况等实时更新的优势;
第四,体系内产品的支持力度大。可以通过短信、彩信、增值业务平台等多种方式推送定位结果。
另一方面,如果运营商要发展嵌入式第三方产品,其位置输出能力也具有一定优势,运营商向第三方输出位置能力,通常作为第三方产品定位的必要补充手段,其优势在于庞大的用户规模和真实准确的基站信息库。与手机号码的捆绑使运营商可同时为第三方在业务支撑与控制、业务分析与运营上提供支持。
三、关键技术
在移动互联网业务蓬勃发展的今天,用户密度决定市场宽度,如果运营商能够将位置能力与大数据平台分析能力结合起来,将可大幅度的提高位置服务的价值,为增值服务市场迎来爆发式增长。
目前对大数据处理主要采用两种核心技术:一种是基于磁盘处理任务调度的批处理技术,另一种是基于内存计算的实时流处理技术。本文主要研究实现位置类应用的流处理技术。流处理的特点主要包括:
☒ 可以可靠的处理无界持续的流数据,保证每个消息至少能得到一次完整处理;
☒ 分布式的集群架构,伸缩性良好,易扩展且容错性高;
☒ 可实时处理海量数据,高性能即处理速度快。
这里面主要介绍实现大数据平台位置类应用采用到的Kafka、Storm、Flume及Streaming等关键技术:
Storm:分布式实时计算系统,可用来处理源源不断流进来的消息,处理之后将结果写入到存储中。Storm集群主要由一个主节点(master node)和一群工作节点(worker nodes)组成,通过Zookeeper集群进行协调。主节点运行Nimbus进程,负责资源分配和任务调度,通知监控工作节点的运营状态。工作节点运行Supervisor进程,负责接受nimbus分配的任务,启动和停止属于自己管理的工作进程。Storm通常被广泛用来进行实时日志处理,从kafka中读取实时日志消息,经过一系列处理,最终将处理结果写入到一个分布式存储中,提供给应用程序访问。每天处理几十亿的用户日志信息,从用户行为发生到完成分析延迟在秒级。
S4:S4是一个通用的、分布式的、可扩展的、分区容错的流式系统,其计算平台具有可伸缩、易扩展、分区容错的特点,通常处理实时性要求高的业务。通过部署廉价的服务器集群,S4进行分布式处理,处理模型参照MapReduce模式。S4是同类平台中为数不多采用对等架构的系统,集群中的所有工作节点都是对等的,不存在主节点。使得系统具有很强的伸缩性,并且不存在单点故障,系统的部署和运维也得以简化。但无法保障数据传输过程中的可靠性,某节点故障后将导致该节点数据丢失。因此,S4更适合对数据处理精确性要求不高的场景。
Streaming:实时数据流处理组件,是spark体系中的一个流式处理框架,建立在Spark上的实时计算框架,可以实现高吞吐量的、具备容错机制的实时流数据的处理。通过它提供的丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。支持从多种数据源获取数据,从数据源获取数据之后,可以使用诸如map、reduce等高级函数进行复杂算法的处理。最后还可以将处理结果输出到多种不同的数据平台中,包括文件系统和数据库等。
Kafka:分布式消息队列,是一种分布式的,基于发布/订阅的消息系统,同时支持离线和在线日志处理。以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能,具有高吞吐率,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,该文件夹下存储这个分区的所有消息和索引文件,这使得Kafka的吞吐率可以水平扩展。
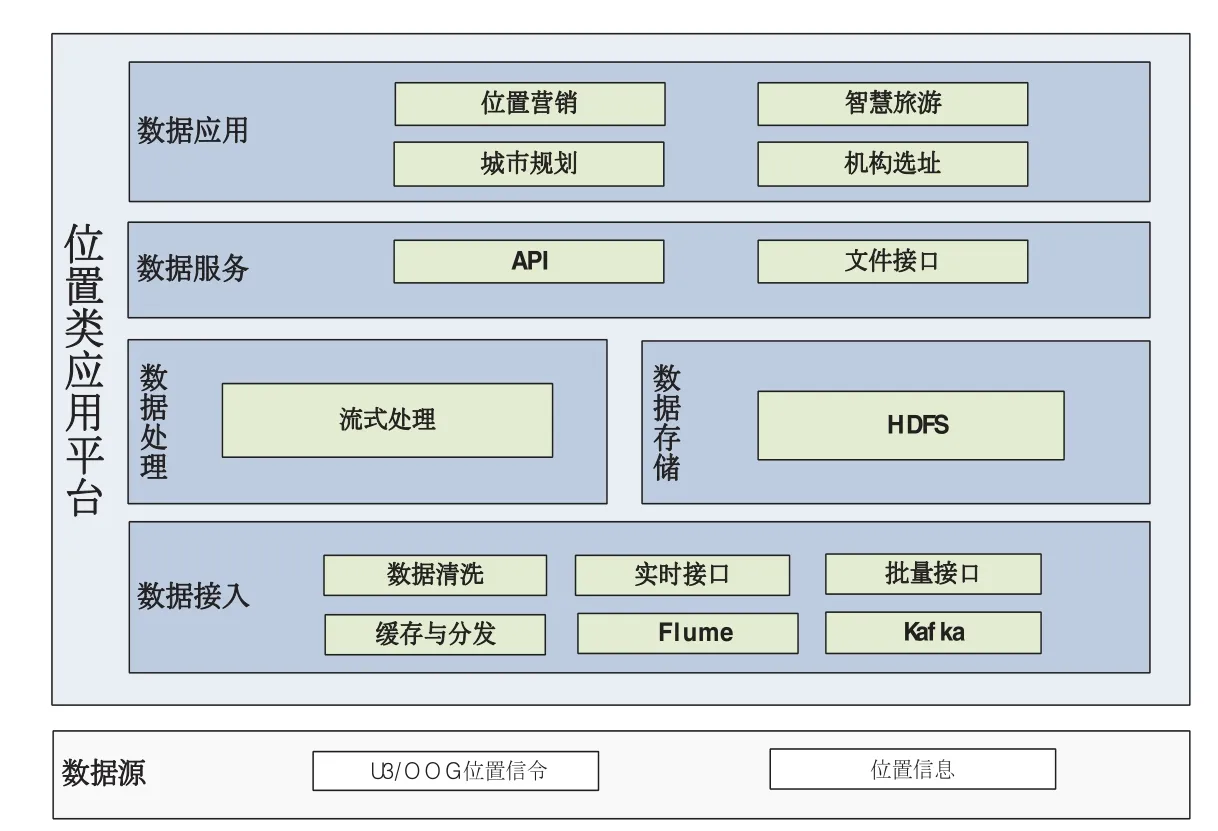
图1 位置应用平台架构图
Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。Flume以agent为最小的独立运行单位,单agent由Source、Sink和Channel构成。
四、位置应用平台架构探讨
位置类应用以位置信令处理为核心服务内容,实现对位置信令进行加密、过滤以及关联回填。本文主要采用实时计算实现位置类应用平台,实时计算过程一般划分为以下三个节点:数据的产生于收集、传输与分析处理、储存并对外提供服务。参考实时计算的框架位置应用平台主要包括数据源、数据接入、数据处理及存储、数据服务及数据应用等内容。如图1所示。
数据源:将MC口数据、S1-MME数据、基站基础信息数据等作为数据源传输至大数据平台。
数据接入:数据接入层完成数据的采集和预处理工作,实时从数据源采集S1-MME等信令数据。数据采集分为两种方式:一对于实时性要求较强的信令数据,由接收服务层实现实时位置信令的采集,通过flume解析实时上报的位置信令;二对于实时性要求不高的数据,采用周期性文件采集方式汇聚到平台。同时,大数据平台按照数据处理规则完成数据的初步清洗、合并等工作,以提供后继对位置业务处理工作。
数据存储处理:数据存储处理层负责数据存储与计算工作。对于经过预处理的实时信令数据,部分落地至数据存储介质中(如分布式文件系统HDFS,MPP等),另一份经过实时流计算处理引擎进行数据脱敏处理和数据过滤处理,在数据脱敏处理中,主要是对用户隐私字段进行脱敏处理,如将用户号码信息通过哈希等加密方式进行加密。在数据过滤处理中,主要是依据应用的需求,过滤出所需字段。
数据服务:通过API和文件接口两种方式,对外提供服务,供应用调用。
数据应用:提供基于位置信令数据的对外服务,如机构选址、位置营销、智慧旅游、城市规划等。
五、位置应用建设方式研究
(一)建设原则
大数据平台位置类应用规划和建设遵循以下基本原则:
1、先进性原则
位置类应用的建设必须实现“高起点、高标准、高要求”,要本着“低成本高效”原则,充分引入云计算、大数据、智能展示等新技术。
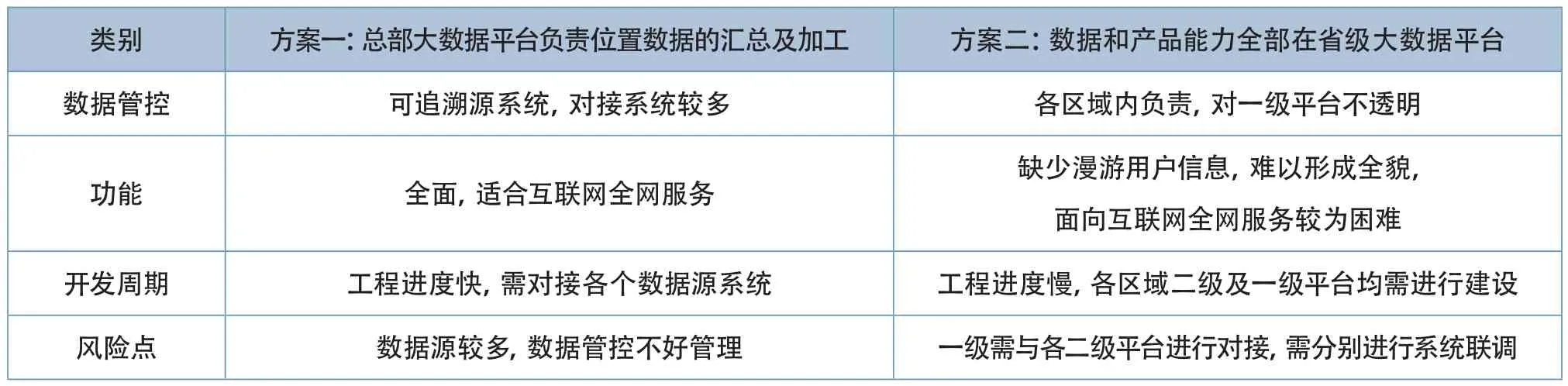
表1 方案对比分析
2、标准化原则
位置类应用需遵循标准化原则,逐步深化平台系统建设的标准化工作,包括标准化信息模型、标准化数据接口、标准化开发管理、标准化对外服务等系统建设模式。
3、开放性原则
系统中的各种网络协议、硬件接口和数据接口等应符合业界开放式标准。应逐步通过数据封装开放系统数据内容和应用功能,全面支持市场经营工作以及其它IT系统的数据和应用需求,实现应用百花齐放,充分满足个性化需求,提升大数据平台分析系统的广度和深度。
(二)建设方式
如表1,大数据位置类应用平台可采用如下两种方式进行建设:
方案一:全网集中建设一套一级位置类应用平台
全国统一建设一套位置类应用平台,统一采集全网数据,统一负责位置数据的汇总及加工,并以API的形式开放给外部应用使用。
方案二:分散各地建设多套二级位置类应用平台
按区域划分建设多套二级位置类应用平台,数据和产品能力全部在各区域大数据平台。将数据上传给一级位置类应用平台,由一级平台通过服务调用或查询服务,满足对全网服务的需求。
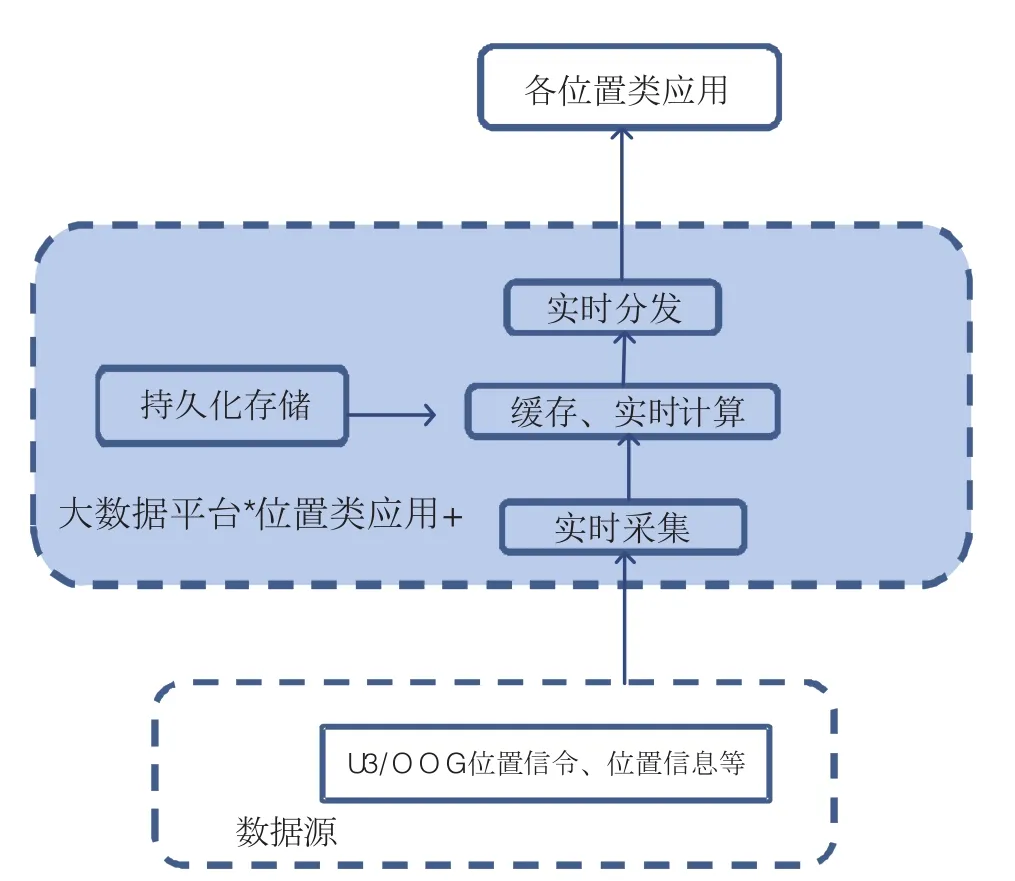
图2 分工及数据处理流程
方案比较:
方案一工程进度较快,且便于对数据源进行追溯,对技术与运营团队技术要求较高,可满足互联网全网服务。方案二各地进度不统一,且面向全网服务较为困难,但可成分调动各区域公司的建设热情,满足本区域内的服务需求。
本文以方案一为例举例说明位置类应用平台的各部分工作分工及数据处理流程。如图2。
由各数据源将将位置信令数据透传至大数据平台,由大数据平台实现数据的格式统一、敏感信息脱敏、关联处理等操作,并将结果提供给各位置类应用使用。

1、由各数据源将Mc口、S1-MME口等位置信息数据透传至大数据平台;
2、大数据平台实时采集数据后对数据进行过滤、加密并输出到缓存;
3、大数据平台实现数据的格式统一、敏感信息脱敏、数据过滤、数据匹配、关联处理等操作;
4、数据存储需对所有数据进行持久化存储,为位置类平台提供数据支持;
5、大数据平台负责位置数据的汇总及加工,并以API的形式开放给外部应用使用。
六、结束语
随着大数据平台的实时处理能力相关技术的发展,基于用户位置的位置类便民信息服务已成为重要亮点。今后随着用户可随时随地查询身边的地铁口、加油站、银行ATM、电力/水力营业厅、移动营业厅以及WLAN热点等公共设施的分布情况,“掌上公交”、“商户联盟”、“实时交通”等一系列位置类应用服务将广受好评,大数据平台位置类应用的建设必将更加受到广泛关注。■
中国移动通信集团设计院有限公司网络所)
[1]吴京润,黄经业译.颠覆大数据分析:基于Storm、Spark等Hadoop替代技术的实时应用.电子工业出版社,2015.
[2]泰德.敦宁,流式架构Kafka与MapR Streams数据流处理.电子工业出版社,2017.
[3](美)吉奥兹,(美)奥尼尔 著,董昭 译. Storm分布式实时计算模式.机械工业出版社,2015.
[4]丁维龙,Storm:大数据流式计算及应用实践,电子工业出版社,2015.
[5]张毅,大数据环境下的实时流式数据处理技术,东南大学 , 2014.
猜你喜欢
今日农业(2021年9期)2021-11-26
发明与创新·小学生(2021年3期)2021-03-25
电脑爱好者(2018年14期)2018-08-05
中国新通信(2017年10期)2017-06-02
北京教育·普教版(2017年1期)2017-02-05
中国新通信(2016年13期)2016-08-12
电脑知识与技术(2016年8期)2016-05-19
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
