
基于互联网的城市时空数据调查技术方法研究
2017-12-27 17:27周小伟何小波任梗睿
地理空间信息 2017年12期
周小伟,何小波,何 宗,任梗睿,彭 婧
(1.重庆市武隆区城乡建委,重庆 408500;2重庆市地理信息中心,重庆 401121)
基于互联网的城市时空数据调查技术方法研究

周小伟1,何小波2,何 宗2,任梗睿1,彭 婧2
(1.重庆市武隆区城乡建委,重庆 408500;2重庆市地理信息中心,重庆 401121)
分析互联网时空数据的类型和来源,研究互联网时空数据的获取和挖掘方法。以重庆市空气质量的时空变化研究为例进行案例分析,探讨在时空数据获取和挖掘中的应用。
时空数据;数据挖掘;网络爬虫;地理编码
城市时空大数据关注空间实体所承载的空间属性、自然属性、管理属性和社会属性,以及在时间序列中不断发展变化所形成的变化信息。互联网的迅猛发展,尤其是在Web2.0时代,各种社交网络、生活消费类网站、电商平台积累了大量的时空信息,大众消费者已成为网络数据的重要提供者[1],这些时空信息已成为当前地理信息扩充应用的重要渠道。据IDC预计,到2020年全球互联网数据总存储量将超过40 ZB,而其中与地理位置相关的数据占80%以上[2]。Goodchild认为,互联网是地理空间信息最大的收藏地,其中大部分都未被利用[3]。互联网信息的获取和应用将为时空大数据提供新的机遇,互联网数据和传统时空数据的融合技术方法是时空大数据研究的重要内容之一。
1 互联网时空数据
互联网时空数据杂乱散布在众多互联网节点上,既有包含地理空间坐标信息的专业数据,也有语义描述的非专业数据。互联网时空大数据不仅具有数据体量巨大、类型繁多、价值密度低、处理速度快等特点,还具有时空信息、多源异构、动态变化、多尺度等特点[4]。
1.1 互联网时空数据分类
互联网时空数据是指广泛存在于互联网中的各类与空间位置直接或间接相关的数据。与传统空间数据不同,互联网时空信息存储于互联网广泛分布的服务器中,并可以通过各类Web服务、标准化接口或URL地址的形式被访问和获取。其表现形式主要以文本的方式进行发布,可以是结构化文本、半结构化文本或非结构化文本[5]。互联网时空数据可按数据结构和按位置信息两种方式分类,如图1。
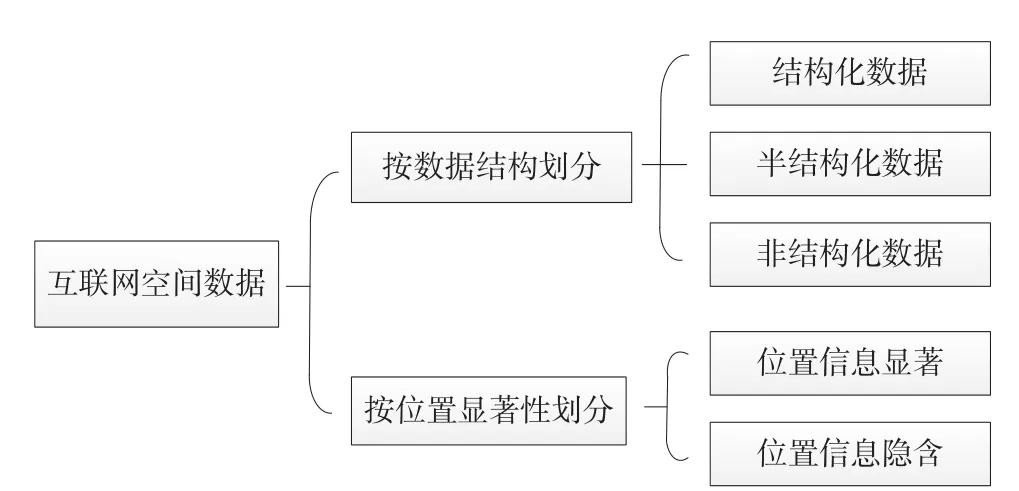
图1 互联网时空数据分类
按数据结构的不同,分为结构化数据、半结构化数据和非结构化数据3类:
1)结构化数据是指具有固定格式的文本数据。结构化文本数据的解析方式唯一,可根据数据的固定结构设定解析模式。互联网中的结构化数据主要有JSON、XML等,用于描述、保存地理信息的KML格式数据就是以 XML结构进行扩展而来。
2)非结构化数据是指无固定格式文本数据,大多以普通文本形式存在,例如图片、声音、视频、微博评论等。非结构化数据的解析模式,一般通过语义理解将原文本进行分段分类归纳,不同的语义理解得到不同的解析模式。
3)半结构化数据不同于以上两种类型,具有一定的结构性,但结构变化大。可以依据文本格式将其归纳成若干独立段落的集合,通过对文本结构在一定程度上进行分类归纳,确定一种对半结构化文本数据的解析模式。
按位置信息的显著性,分为位置信息显著和位置信息隐含两类:
1)位置显著的文本空间信息指数据中明确提供了实体所在精确坐标位置的数据。
2)位置隐含的文本空间数据指数据中没有明确提供坐标位置信息,但可通过地名地址、方位等信息进行坐标位置的推算,从而得到较为精确的位置信息。
1.2 互联网时空数据来源
互联网中有着海量的时空数据,数据的生成来源众多,存在方式各异,这些时空数据将为地理分析和数据挖掘提供新的认知渠道。基于互联网的时空数据主要包括兴趣点数据、LBS数据、VGI数据和有含有空间信息的专题网站数据[2,6,7]。
1)兴趣点数据。兴趣点是与人们生活密切相关的地理实体,互联网地图中包含了海量的兴趣点数据,如百度地图、高德地图、腾讯地图等,互联网地图提供的兴趣点数据具有服务精度高、准确性好、更新快、服务免费等特点。这些兴趣点数据不再是常规的位置和名称信息,还包含了分类、服务、点评、特色、电话、时段、访问量等延伸信息,可研究城市功能区与城市变化、城市热点、城市空间分析等。互联网兴趣点数据已打破了单独提供空间位置服务的范畴,在当前大数据快速发展的情况下,众多研究机构、学者、技术人员正在基于兴趣点开展新型数据挖掘研究。
2)LBS服务数据。LBS是一种基于位置的服务,主要用于移动互联网应用。通过用户签到或系统上传的方式,自动地记录用户的位置信息、运动轨迹和其他行为特征信息,如美团、大众点评、糯米等消费点评类网站,以及微博、微信等社交类工具等。LBS数据是一类高时效性、高准确性的时空数据,这类数据在提供大量的位置信息服务的同时,也包含了大量的美食、休闲、旅游、购物等诸多生活消费类信息,可以在一定程度上借助其海量信息对城市相关服务业的空间分布、密度、热度进行分析,为城市管理决策提供支撑。
3)VGI数据。自发性地理信息是用户以开放的遥感影像、矢量瓦片以及个人空间认知的地理知识为基础参考,通过互联网在线协作的方式创建、管理和维护地理信息数据,供网络上其他用户使用,较广泛使用的VGI服务平台有OpenStreetMap、Google Map Maker等。VGI数据具有共享性强、数据获取成本低、现势性高、属性信息丰富、传播速度快等优点。这类数据可以用来丰富传统的空间数据,成为新的更新来源。
4)含有空间信息的专题网站。随着互联网技术的发展,越来越多的公司、机构和政府部门提供了专题网站或门户网站。网站中直接或间接地蕴藏着大量空间信息,而且其中的很大一部分网站更提供了带有空间参考的坐标信息,如链家、房天下、安居客等房地产类网站。这一类网站含有城市房产等信息的变化趋势,对于城市政策制定以及城市房地产市场调控研究具有重要借鉴意义。
2 互联网时空数据获取方法
互联网数据获取的主要手段是网络爬虫,它是一种自动化浏览网页内容的应用程序,最初被广泛用于互联网搜索引擎,后来用以抓取这些网站中的某些专题数据。网络爬虫技术主要有两个分支:通用爬虫和聚焦爬虫[8]。通用爬虫技术是基于各种网页和链接分析算法,从初始网页的URL开始抓取,不断从页面中抽取新的URL放入任务队列,直到抓取真正有用的数据,主要被应用于通用搜索引擎中。聚焦爬虫技术是针对某一专题或某一个网站数据进行爬虫,它是通用爬虫的细分和延伸,目的在于抽取特定网页中感兴趣的内容,返回符合要求的网络信息给用户[9]。聚焦爬虫技术更加复杂,具有更强的目的性,往往需要在抓取前预先设定抓取规则和目标。总的来说,聚焦爬虫得到的结果更精确、详细。对于蕴含海量时空数据的专题网站,抓取方法主要依赖聚焦爬虫技术。
爬虫过程包括页面下载、页面解析、任务调度和地理编码4个基本模块。总体上互联网时空数据爬虫呈环状,使爬虫能够自动化、持久化地运行,基本架构见图2。

图2 互联网时空数据爬虫基本框架
1)数据下载模块。数据下载是互联网时空数据爬虫的基础,综合利用C#、Python编程下载网页中的时空信息。借助于Selenium、PhantomJS等提供的网络请求模拟功能,向网络服务器发出请求,并获取响应结果,完成网络资源的下载。还提供了应对下载错误、多线程下载等功能。
2)数据解析模块。数据解析模块包括数据预处理和数据提取:直接爬虫下载的网页数据大多呈现非结构或半结构化,在使用前需要进行结构化、对象化预处理操作,对于XML或JSON结构化数据可直接解析操作;数据提取主要是利用HtmlAgilityPack、正则表达式和xpath等技术,根据网页结构制定数据的抽取规则,对预处理后的数据进行解析和提取,从而获取目标数据。
3)任务调度模块。任务调度模块主要进行网络地址的去重和过滤等处理,并实现在多线程条件下,为每个子线程分配爬虫任务。在进行某专题网站的爬虫时,任务调度模块会解析页面中符合要求的URL,并与已有的URL请求队列进行比对,剔除已完成下载的URL,同时记录下载失败的URL;采用多线程异步并行策略将一个大任务分为互不影响的多个子任务,各个子任务由独立的线程并行处理,为各个小任务分配独立的代理服务器,每个服务器单独完成抓取任务,可以避免某些网站的反爬虫技术。
4)地理编码模块。地理编码模块是互联网时空数据爬虫的重点,为了便于对抓取的互联网时空数据进行空间分析,需要对互联网文本数据进行地理编码处理。根据位置信息的显著性不同实现地理编码的方法也不同,位置显著的互联网文本信息可以直接通过自带的坐标值实现空间化处理,此类数据定位精准。位置隐含的互联网文本数据通过地名地址的匹配实现地理编码,匹配的方法可以借助百度地图提供的API,如图3、4,也可通过已有的地名地址库进行模糊匹配查找,再进行人工校核。
图3 百度地址匹配工具
从互联网中获取到的多源空间数据在存储上面临着数据内容和结构灵活多变、存储并发量大等几个特点,不能使用固定的表结构来存储海量的网络地理数据,与传统地理空间数据存储系统也完全不一样,导致横向扩展困难、计算性能不足,实时变化的数据管理与处理无法实现[2]。本研究中将抓取的互联网时空数据根据数据类型不同采用不同的存储方式,包括文件存储系统、GDB数据库及Oracle数据库。

图4 百度地址匹配结果
3 互联网时空数据挖掘方法
Web时空数据挖掘是Web数据挖掘和时空数据挖掘共同衍生的一个分支。Web时空数据挖掘是以互联网资源为处理对象,经网络资源收集、时空信息抽取,保存成数据存储库,之后利用数据挖掘技术提取用户感兴趣的模式和知识,基本流程如图5所示。
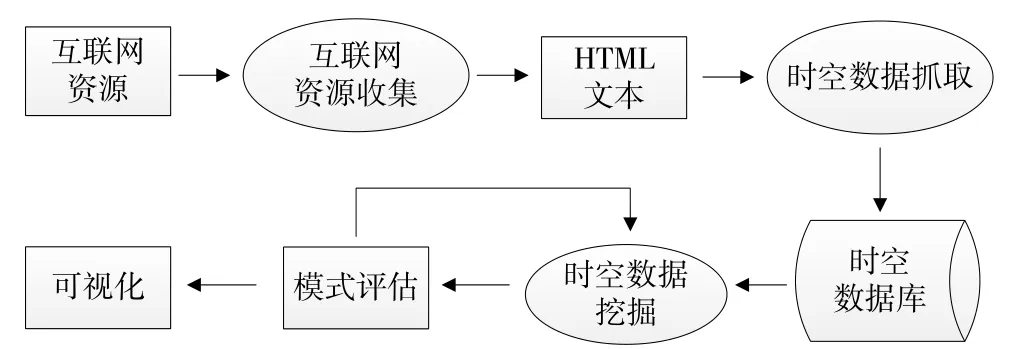
图5 web时空数据挖掘基本流程
针对抓取的互联网时空数据大多存储在关系型数据库(如MySQL或Oracle等)或表格形式的文件(如Excel、CSV或TXT等)里,为了充分利用时空数据挖掘其中隐含的有价值的知识和规则,需要通过建立空间坐标关联,实现抓取数据的空间可视化,再与传统的多源地理空间数据进行整合,并利用GIS领域中的空间分析方法、地学信息图谱方法、几何计算方法等,统计学中的统计分析法、归纳学习法、聚类方法和分类方法等,完成相关的应用分析[10]。
4 应用实践
重庆市空气质量发布系统网站服务的空间尺度为重庆市全市级区域,共69个监测点。网站发布的空气质量数据包括实测 PM2.5、PM10、SO2、CO、NO2和 O3等,如图6所示;每间隔1 h,更新一次,且保留过去24 h内的实测数据。本应用是动态抓取重庆市2016-12-28~2017-01-12期间的空气质量数据。
1)数据抓取与解析。从网站内容中抽取的信息有时间、站点、实测的空气质量数据,数据字段的值为Json格式数据,利用Json.NET工具库解析Json数据将其转为结构化表,如图7。
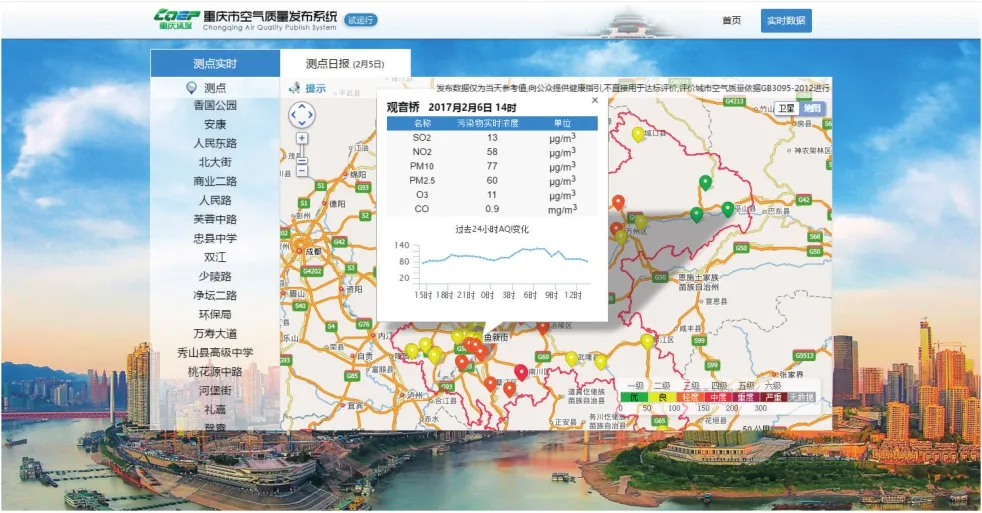
图6 重庆市空气质量发布系统网页

图7 抓取内容
2)数据存储。本研究选用MySQL数据库管理系统存储整理得到的结构化数据,针对实测空气质量数据建立两张表,字段设置分别见图8。实测的空气质量数据将长期保留在数据库中,针对空气质量日报数据1 d更新一次,空气质量时报1 h更新一次。

图8 数据入库存储
3)数据处理及挖掘。通过爬虫抓取的站点坐标为火星坐标系,通过坐标转换工具将其转换为WGS84坐标,并与重庆市行政区划进行匹配。利用空间插值方法,对时间序列的空气质量在重庆市范围内进行插值处理,再根据PM2.5监测网的空气质量新标准(优 :0~35 μg/ m3;良 :35~75 μg/m3;轻度污染 :75~115 μg / m3;中度污染 :115~150 μg/m3;重度污染 :150~250 μg/ m3;严重污染 :大于 250 μg/m3及以上),制作重庆市PM2.5的空间分布时序图。
通过对16 d的PM2.5数据分析可以看出,城口县、酉阳县、秀山县空气质量处于优良状态的天数最多,受PM2.5污染程度低,而潼南区、合川区、巫溪县、江津区、綦江区等受PM2.5污染更为严重。2016-12-31~2017-01-07重庆市域范围内空气质量均受到PM2.5重度污染, 其中1月3日至1月4日最为严重,见图9。

图9 重庆市PM2.5空间分布时序图
5 展 望
研究了利用网络爬虫技术从海量的互联网资源中抓取具有时间和空间信息标签的数据,借助百度地图API和已有的基础地理数据库对抓取的互联网时空数据进行地名地址匹配,从而实现地图可视化表达。将这些多源地理空间数据进行整合,充分发挥GIS空间分析能力和可视化表达技术,发现其中隐含的价值和知识。
[1]徐兴元. Web 时空数据挖掘及其地图信息服务[D]. 上海:华东师范大学, 2013
[2]蔡地. 互联网多源矢量空间数据自动获取与管理方法研究[D].中国测绘科学研究院, 2015
[3]Goodchild M F. Citizens as Sensors: the World of Volunteered Geography[J]. GeoJournal, 2007, 69(4): 211-221
[4]孙嘉, 裴韬, 龚玺, 等. Web时空数据挖掘研究进展[J]. 地球科学进展, 2011, 26(4) :449-459
[5]陈晓慧, 陈荣国, 卫文学. 基于网络爬虫的 Web 服务抓取解析器的设计与实现[J]. 地理信息世界, 2010, 8(3): 64-68
[6]马宏斌, 王柯, 马团学. 大数据时代的空间数据挖掘综述[J].测绘与空间地理信息, 2014, 37(7): 19-22
[7]Ling X, Weld D S. Temporal InformationExtraction[C].Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence. USA: AAAI Press, 2010: 1 385-1 390
[8]杨定中, 赵刚, 王泰. 网络爬虫在 Web 信息搜索与数据挖掘中应用[J]. 计算机工程与设计, 2009 (24): 5 658-5 662.
[9]王明军. 基于 Web 的空间数据爬取与度量研究[D]. 武汉大学, 2013
[10]徐胜华, 刘纪平, 胡明远. 空间数据挖掘与发展趋势探讨[J].地理与地理信息科科学, 2008, 24(3): 24-27
P208
B
1672-4623(2017)12-0031-04
10.3969/j.issn.1672-4623.2017.12.010
2017-06-26。
周小伟,工程师,研究方向为地理信息技术在城乡规划中的应用。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
电子制作(2017年9期)2017-04-17
环境保护与循环经济(2017年3期)2017-03-03
汽车与安全(2016年5期)2016-12-01
汽车与安全(2016年5期)2016-12-01
中国环境监察(2016年11期)2016-10-24
