
基于用户行为的社交网络挖掘分析
2017-12-22 07:16刘青青
洛阳师范学院学报 2017年11期
刘青青
(洛阳师范学院数学科学学院, 河南洛阳 471934)
基于用户行为的社交网络挖掘分析
刘青青
(洛阳师范学院数学科学学院, 河南洛阳 471934)
本文基于分布式云计算, 提出了一种社交网络行为搜索算法, 其可以增加影响因素, 并把时间箭头和页面相关因子转化为挖掘因子, 从而可提高挖掘性能的计算和搜索效率. 实验证明, 该计算有较好效果, 并对云计算的用户分析具有指导意义.
分布式计算; 用户搜索; 社交网络
0 引言
目前, 随着社交平台的快速发展, 出现了海量的信息, 并且信息量呈指数级增长. 预计到2020年, 每年产生的数字信息中将会有超过三分之一的内容存在云平台上. 为了对这些数据进行分析处理, 以获取更多的有价值的信息, 基于云计算的研究已成为一个重要研究方向. 在国外, 美国斯坦福大学提出了网页的排名[1], IBM提出了HITS技术的理念[2-3]. 基于海量信息的特点, 传统的数据存储和计算方法很难适应. 因此, 针对这一问题, 本章提出了一种结合网络搜索行为的算法.
Hadoop是一个能够让用户容易使用的构架和分布计算平台[4]. 用户可以很容易在Hadoop上开发处理海量数据的应用程序. 它有以下几个优点: 高可靠性、 强扩展性、 高效性、 高容错性. 目前, 基于Hadoop的应用非常多, 比如, Facebook借助于集群运行Hadoop来进行数据的分析和机器学习, 百度也使用Hadoop进行搜索日志分析和网页数据的挖掘工作[5].
1 Map/Reduce模型
在云计算中, 资源和任务的分配并不是一一对应的. 首先, 任务反映在相应的资源上, 然后通过相应的物理设备反映出来. 目前, 这种思想主要采用Map / Reduce云计算模型来实现, Map/Reduce模型如图1所示.
在上述模型中, 云计算模型系统在运行时可分为多个部分, 以供用户在做任务时使用. 由于云计算资源的限制、 经常性资源竞争的结构异质性特征可能导致资源分配不合理的情况, 所以在资源的分配中, 如何使资源合理配置是资源分配的核心工作.
2 用户操作行为的相关工作
2.1 各种搜索索引的权重
基于云计算社交网络的信息量巨大. 首先, 搜索引擎将根据用户提交的关键词进行文本分割, 并删除无关的词; 然后, 使用搜索引擎分析搜索词的权重; 之后, 可以用计算值来选择关键词[6].
采用单词权重作为搜索单元和术语集, 以关键词的权重来作为单元词的整合. 假设Xij是搜索后的权重,Yi,j是查询序列中某个词的权重,Zi,j是序列分割的权重. 据此, 可以得到以下结论:
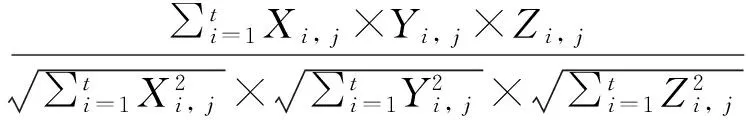
(1)
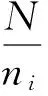
(2)
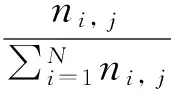
(3)
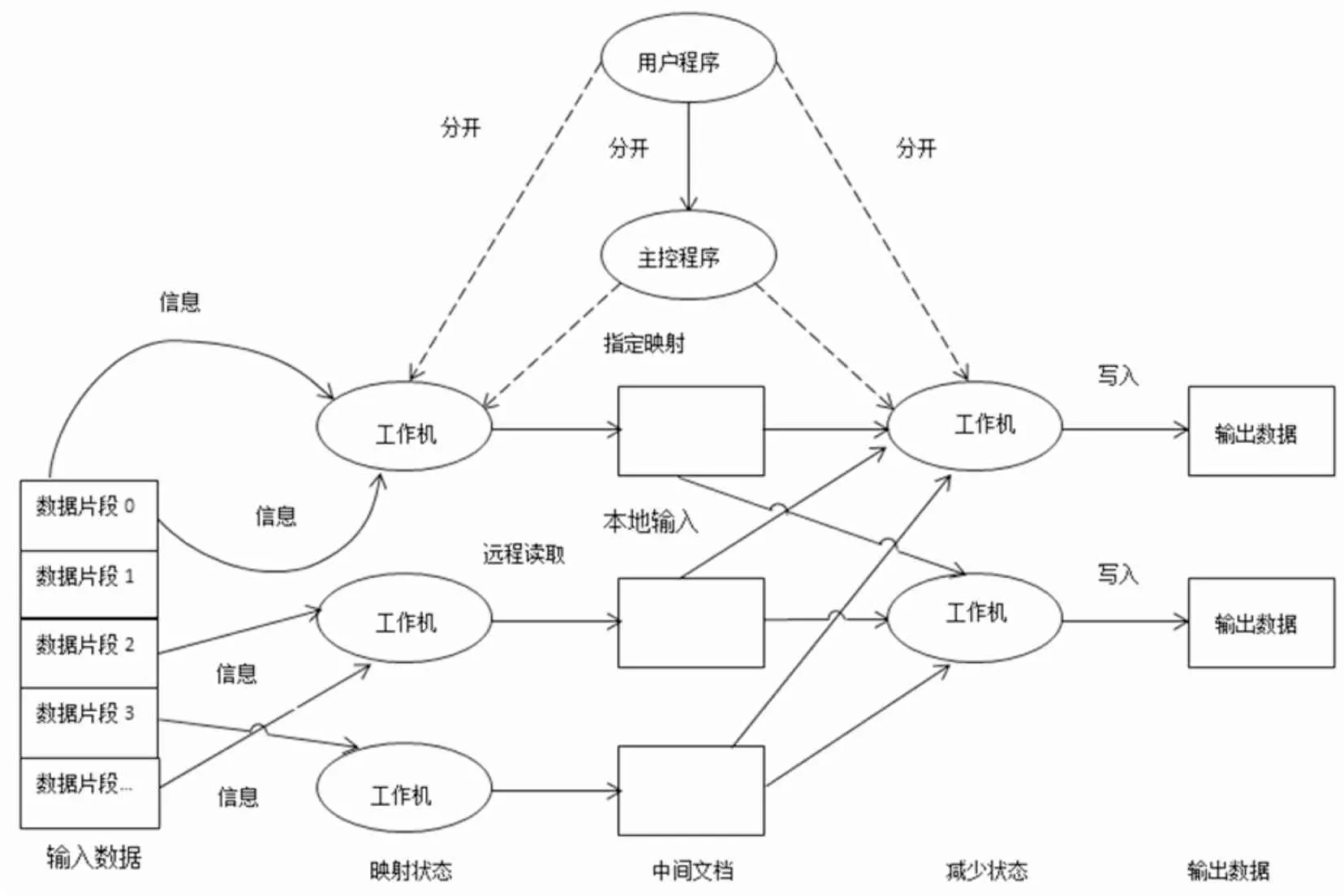
图1 Map/Reduce模型
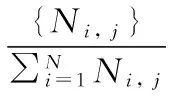
(4)
其中, Frei,j指的是关键词i在网页j中引用的频率,N指的是资源的数量,ni是含有关键词i的网页总数.
2.2 模型因素
基于网络页面的算法, 首先从搜索频率和偏好的角度分析用户搜索行为, 然后考虑权重. 主要包括:
①用户搜索行为: 考虑到用户可以忽略返回结果的页面, 故搜索行为会受到很大影响. 笔者采用以下公式来弥补这一缺陷.
(5)
在公式(5)中, c(A,q)是网页A的平衡因子, Click(A,q)是点击量.
②用户思考时间: 在进行搜索行为时, 如果用户发现搜索行为之间存在相似性, 他们会停留一段时间, 而这与他们的满意度无关. 因此, 采用公式(6)来描述搜索时间的权重.
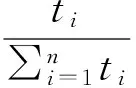
(6)
在公式中,ti是指用户浏览网站时, 查询单词的集合.
③页面之间的相关性
在云计算的搜索过程中, 页面i和j之间存在相关性, 但权重可能有很大差别. 因此, 考虑使用平衡因子于对页面进行补偿. 方法是: 假设进行N次迭代, 在某一时间段[0,t]内, 使用用户点击的页面构造矩阵CN×N, 其中Ci,j指i和j被点击的次数, 如果Ci,j以及Cj,k大于0, 那么我们可以说i,j,k有关系. 据此, 可以得出以下结论:
K(A,Ti)=λ(IDA,IDTi)
(7)
在公式中,K(A,Ti)是指的是A和T的相关性, 基于两页的ID找到的相关值.
2.3 用户信息的搜索反馈
在基于云计算的用户搜索过程中, 首先通过搜索引擎得到一个结果集, 之后通过用户点击目标网页, 获取其ID号; 再之后, 基于相关的隐含值, 将结果集与隐含的相关程度进行比较, 并把页面紧密相关作为新的搜索附加结果反馈给用户, 实时反馈的流程图如图2所示.
2.4 算法流程
步骤1: 根据用户搜索获取相关页面;
步骤2: 基于基本的页面排名计算, 对用户影响因素, 时间箭头指向和页面相关性进行分析;
步骤3: 分析有关影响用户因素的网页;
步骤4: 根据基于时间箭头指向所需的时间进行分析;
步骤5: 根据页面相关性的分析选择;
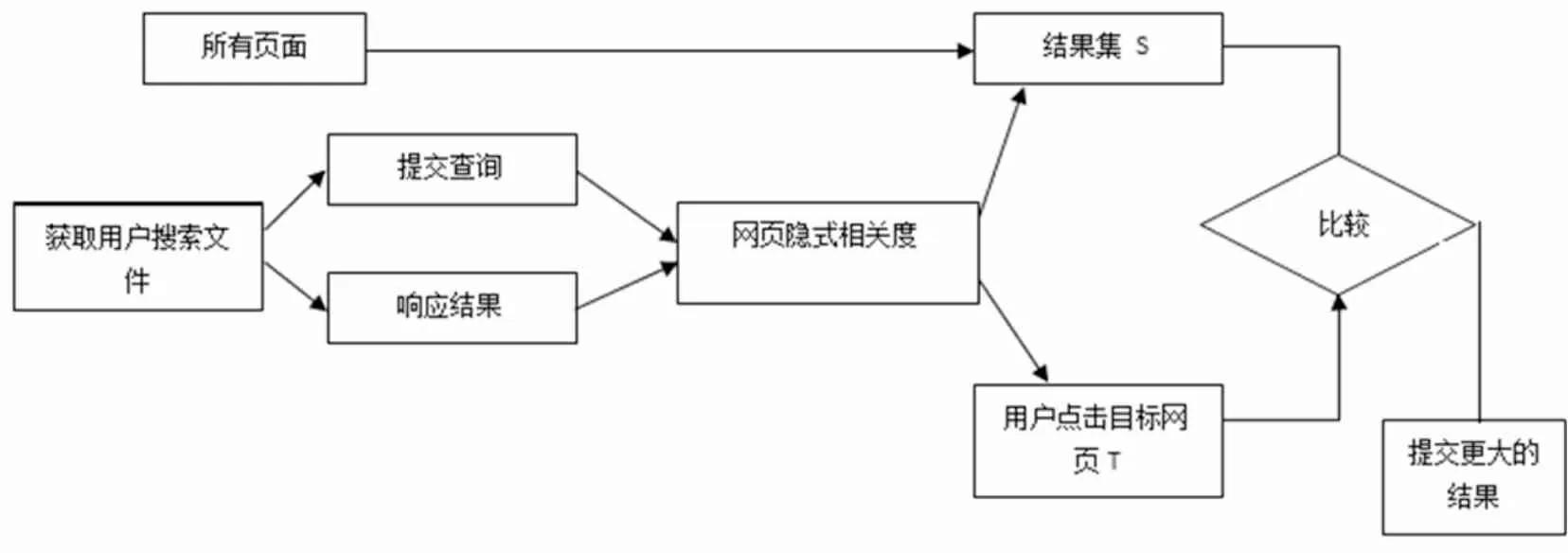
图2 实时反馈的流程图
步骤6: 将步骤3和步骤5的结果提交给页面排序并计算结果;
步骤7: 向用户反馈结果.
3 实验的验证
本实验采用五台 PC构建一个基于Hadoop的分布式计算平台, 其中一台PC作为服务器, 主要负责主节点, 其他四台用于任务跟踪.
3.1 数据收集
实验中使用的数据主要来自58同城网的数据. 本文收集了大约1000万个查询记录, 查询记录格式如表1所示.

表1 查询记录格式
3.2 删除功能
用户搜索时会产生一些Query不同, 但实际意义是一样的记录, 比如张磊男性和男性张磊. 为解决此问题, 本文采用Map / Reduce方法实现, 其伪码如下:
Map(String No,Stirng Content)
{ String Str[]=”lineContent.spli()”;
Collect(id,term);// Collect all data
}
Reduece(String id, Tree terms)
{ While each<=terms
{// Duplicate Weedout
}
Collect(id,new Terms);
}
3.3 用户数据分析
Hadoop框架能够从多个角度分析和挖掘数据, 包括热搜索词和单一的点击频率. 此部分主要基于热词的搜索, 并可对这些搜索行为进行分析. 更重要的是, 数据集的大小可以存储和计算. 此部分的伪码如下所示:
Map(String No,Stirng Content)
{ String Str[]=”lineContent.spli()”;
Collect(id,term);// Collect all data
While each<=terms { collect(term,reduce)// reduce Send the data to reduce
}
}
Reduece(String query,Tree values)
{ intnum=0;// Ser counter
While each<=terms
{num=num+values// Accumulative page view
}
Collect(query,num);
}
3.4 实验结果分析
本文数据来自Heritrix页面[7-8]. 其视图的数据量基于10万、 3万、 5万和100万, 且具有4个簇(10万、 2万、 3万和4万). 基于不同页面视图的三种算法的比较如图3所示.
4 小结
基于Hadoop的用户搜索行为能够帮助用户获取信息, 查询日志和数据挖掘技术也可以应用到以后的情感分析中. 基于云计算的模型有利于对用户的数据分析, 可以对基于Hadoop分布式计算框架的缺点进行有效的弥补. 此外, 通过用户的日志, 我们寻找出了用户的行为规律, 这也有助于下一步的用户情感分析.

图3 基于不同页面视图的三种算法的比较
[1] Page L,Brin S,Motwani R,et al.ThePagerank Citation Ranking;Bringing Order to the Web[R].TechicalReport,Standford Digital Library Technologies Project,2011.
[2] Kleinberg J M.Authoritative Sources in a Hyperlinked Environment[J].Journal of the ACM,2012,46(5):604-632.
[3] Chakrabarti S,Dom B,Raghavan P,et al.Automatic Resource List Compilation by Analyzing Hyperlinked Resource List Compilation by Analyzing Hyperlink Structure and Assocaitaed Text[EB/OL].[2013-11-17].http://citeseer.ist.psu.edu/chakrabarti98automatic.htm.
[4] Powered By-Hadoop Wiki[EB/OL].[2013-11-17].http://wiki,apache.org/hadoop/PoweredBy.
[5] Borthakur D.HDFS Architecture[EB/OL].[2012-11-17].http://hadoop.apache.org/common/ docs/current/hdfs_design.
[6] Mao G J,Duan L J. The principle and algorithm of data mining[M]. Bei jing Tsinghua university press,2009.
[7] Chen C,Zhan Y W,Li Y. PageRank parallel algorithm based on Journal of Computer Applications[J].2015,35(1):48-52.
[8] Cao S S,Wang C.Improved PageRank Algorithm Based on LinksandUserFeedback[J],Computer Science, 2014,41(12):179-182.
Analysis of Social Network Mining Based on User Behavior
LIU Qing-qing
(College of Mathematics and Science, Luoyang Normal University, Luoyang 471934, China)
This paper comes up with social network behavior search algorithm based on Hadoop cloud computing. The main reason is to increase the impact of factors. Time arrow and page correlation factor are transformed into mining factors, so as to improve excavation performance and search efficiency of mining performance. The experiment proves that the calculation is effective. And it has guiding significance for user analysis of cloud computing.
distributed computation; user search; social network
TP311
A
1009-4970(2017)11-0056-04
2017-05-06
刘青青(1978—), 女, 河南洛阳人, 硕士, 副教授. 研究方向: 计算机软件及应用.
[责任编辑 徐 刚]
猜你喜欢
保健医苑(2022年1期)2022-08-30
动漫界·幼教365(中班)(2021年4期)2021-05-23
成都信息工程大学学报(2021年6期)2021-02-12
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
应用科技(2015年5期)2015-12-09
郑州大学学报(理学版)(2012年4期)2012-03-25
