
基于数据挖掘的文本分类算法
2017-12-20 00:57李志坚
长春师范大学学报 2017年12期
李志坚
(阿坝师范学院,四川汶川 623002)
基于数据挖掘的文本分类算法
李志坚
(阿坝师范学院,四川汶川 623002)
文本分类是网络数据管理研究中的难点,本文运用支持向量机非线性分类能力和协同进化粒子群算法全局搜索能力,提出一种基于数据挖掘的文本分类算法。首先对网络文本样本进行相关预处理,提取文本的特征向量,然后将训练样本输入到支持量机进行训练,采用协同进化粒子群优化算法优化分类器参数,最后采用Reuters21578数据集对模型性能进行分析。研究结果表明,运用协同进化粒子群算法可以快速找到支持向量机的最优参数,提高文本分类的正确率,分类速度可以满足文本分类在线应用要求。
文本分类;协同进化粒子群算法;特征向量;支持向量机
随着互联网的高速发展,网络上的信息量呈指数形式增长,其中非结构化文本数据所占比率最大,如何从纷繁的文本数据中挖掘出用户感兴趣的信息变得日益重要[1]。文本分类是网络文本数据挖掘的基础,分类结果的好坏直接影响文本数据挖掘效果,因此如何构建正确率高的文本分类算法成为网络信息数据挖掘研究中的重点[2]。
针对文本分类问题,国内外学者和专家投入了大量的时间和精力,进行了广泛深入的研究。文本分类算法可以划分两个阶段:人工分类阶段和自动分类阶段[3]。人工分类方法主要通过专家或专业人士对文本类别进行划分,费时费力,而且分类结果不科学,不能满足当前海量的文本数据挖掘需求[4]。自动分类方法主要通过计算机采用一定的算法进行文本分类,分类复杂性大幅度降低,分类效率得以提高[5]。文本自动分类是模式识别中的一种多分类问题,主要包括文本特征提取、选择以及文本分类器的构建等[6],本文主要针对文本分类器进行研究。当前,本文分类器主要基于支持向量机和神经网络等数据挖掘技术进行构建。神经网络是一种基于经验风险最小化原则的数据挖掘技术,其可以描述文本类别与文本特征之间的非线性关系,在文本分类中到广泛的应用[7-9],然而网络文本是一种特殊文本数据,其特征向量的维数相当高,导致神经网络在分类过程中,经常出现“维数灾”等难题,而且神经网络自身存在网络结构复杂等不足,限制了其在文本分类的应用范围[10]。支持向量机是一种基于结构风险最小化原则的数据挖掘技术,较好地解决了“维数灾”等难题,泛化能力优异,成为文本分类中的主要研究方向[10-12]。支持向量机的文本分类性能与核函数及参数密切相关,因此要获得分类正确率高的文本分类结果,首先要解决支持向量机参数优化问题。
针对支持向量机在文本分类中的参数优化难题,本文以提高文本分类为目的,提出了一种基于数据挖掘技术的文本分类算法(CEPSO-SVM),采用协同进化粒子群优化(co-evolution based on particle swarm optimization,CEPSO)算法选择支持向量机的参数,并通过Reuters21578数据集对其性能进行分析。
1 CEPSO-SVM的文本分类模型
基于CEPSO-SVM的文本分类步骤:首先收集相关文本样本,并进行相关预处理,提取特征向量和计算特征向量的权值,然后根据特征向量和特征向量的权值对训练样本和测试样本进行处理,并将测试样本输入到支持量机进行训练,通过协同进化粒子群优化算法选择支持向量机的参数,最后建立文本分类模型,并采用测试样本对模型性能进行分析,其工作原理具体如图1所示。

图1 CEPSO-SVM的文本分类原理
2 文本表示
2.1 文本向量化表示
设文本T={P1,P2,…,Pn},其中n表示文本T中段落的数目,Pi(1≤i≤n)表示文本T中第i个段落,Pi=(ti1,ti2,…,timi),其中mi表示段落Pi中关键词数目,timk(1≤mk≤mi)表示段落Pi中第k个关键词,则文本T可以表示为[13]:
(1)
2.2 计算文本特征项权值
特征项,即关键词,作为文本表示的基本单位,本文选择TF*IDF算法计算特征项权值,具体如下:

(2)
3 支持向量机构建本文分类器
3.1 支持向量机分类原理
支持向量机是一种基于统计学习理论的模式识别方法,其结构如图2所示。
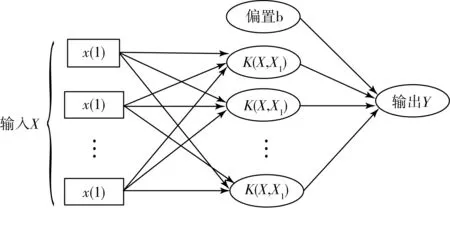
图2 支持向量机的结构
对于已知的样本(xi,yi),yi=±1,i∈N+,通过支持向量机得出一个最优分类平面,满足以下表达式:
w·x+b=0.
(3)
同时,训练集样本中应该满足:
yi(w·x+b)-1≥0.
(4)
将线性分类转化为一个二次回归问题:

(5)
其中,C为惩罚因子[14]。
最后,推导出支持向量的线性判别函数:
(6)
对于非线性分类问题,引入核函数k(xi,xi)性判别函数,可以得到:
(7)
本文选用RBF核函数,其公式如下:

(8)
文本分类是一种多分类问题,采用如图3所示的方式构建文本分类器。

图3 多分类的文本分类器构建
支持向量机在构建文本分类器过程中,需要优化核函数参数σ和C,为此本文协同进化粒子群算法进行优化,以提高本文分类的正确率。
3.2 协同进化粒子群算法
在粒子群算法中,在目标搜索空间中有m个代表潜在问题解的粒子,每个粒子都作为待优化问题的一个可行解,通过粒子之间的协作与竞争寻求其最优解。在第k次迭代中,第i个粒子的当前位置和速度分别为xi(K)和vi(K),粒子个体最优历史位置为:pBesti称为个体最优,种群的全局最优粒子位置为gBesti,粒子种群在寻优过程通过群体中个体之间的协作和信息共享来寻找最优解,每个粒子根据下式对速度和位置进行更新:
vid(k+1)=wvid(k)+c1r1(pBestid(k)-xid(k))+c2r2(gBestid(k)-xid(k)).
(9)
xid(k+1)=xid(k)+vid(k+1).
(10)
其中,k为当代的迭代次数,vid(k)和vid(k+1)分别为第i,i+1代粒子速度,vid(k)和vid(k+1)分别为第i,i+1代粒子位置;c1和c2为加速因子;r1和r2为随机数;ω称为惯性因子。
为了加快粒子种群搜索速度,本文引入双种群协同进化方式,两个种群并行搜索,每一个种群采用不同的惯性权值ω,增强了种群的多样性,较好个体可以在不同种群之间迁移,通过共享信息完成协作进化,提高搜索效率,两个种群惯性权值ω的更新方式分别如下:
ω1=ω1max-k×(ω1max-ω1min)/kmax.
(11)
ω2=(ω2max-ω2min)×(kmax-k)/kmax+ω2min.
(12)
3.3 协同进化粒子群算法优化支持向量机参数
步骤一:设置协同进化粒子群算法的相关参数,主要包括两个子群的规模,最大迭代次数tmax,参数c1,c2等。
步骤二:初始化粒子群S1和S2的位置和速度,并根据适应度值确定pBest和gBest。
步骤三:根据每一种粒子对应的参数(C,σ)得到文本分类正确率作为每个粒子的适应度值。
步骤四:粒子群S1和S2分别根据(9)和(10)同步更新每个粒子的位置和速度,并对S1和S2的pBest和gBest进行更新。
步骤五:比较粒子群S1和S2的pBest和gBest,共享两种群中的pBest和gBest。
步骤六:如果t>tmax,最优个体对应的参数值为最优参数(C,σ),否则返回步骤三。
4 CEPSO-SVM在文本分类中的应用
4.1 数据来源
采用Pentium(R)Dual-Core CPU E5800 @ 3.20GHzI,8 GB RAM,Windows 7操作系统,编程软件为VC++,采用Reuters21578 Top10数据集进行仿真实验。为了全面、准确地评价CEPSO-SVM的优越性,选择遗传算法优化支持向量机(GA-SVM)、粒子群算法优化支持向量机(PSO-SVM)进行对比实验,所有模型运行10次,性能评价指标为分类的正确率(precision)、召回率(recall)作为模型评价标准,它们定义如下:

(13)

(14)
Reuters21578数据集是共有21578个文档,共分为topics、organizations、exchanges、places和people五个大类,135个子类别,最常用的10个子类别称为Reuters21578 Top10,具体如表1所示[15]。

表1 Reuters21578 Top10数据集
4.2 结果与分析
4.2.1 分类正确率和召回率比较
在表1的每个类别中选取一定量的文档(70%)作为训练文本,其余文档(30%)作为测试文本,CEPSO-SVM、GA-SVM以及PSO-SVM的文本分类的准确率和召回率分别图3和图4所示。GA-SVM的文本分类正确率保持在82%左右,PSO-SVM文本分类正确率保持在92%左右,而CEPSO-SVM的文本分类正确率保持在97%左右,相对于对比模型,CEPSO-SVM分别大约提高了10%和5%,同时文本类的召回率也得到相应的提高,这主要是由于相对于遗传算法和标准粒子群优化算法,协同进化粒子群优化的搜索能力更强,找到了更优的支持向量机参数,因此获得了更加理想的文本分类结果。

图4 CEPSO-SVM与其它模型的分类正确率对比

图5 CEPSO-SVM与其它模型的召回率对比
4.2.2 分类速度对比
对于海量文本数据进行挖掘,分类速度是文本评分算法一个重要指标,采用平均分类时间作为每一种算法的分类速度,如表2所示。相对于对比模型,CEPSO-SVM的分类时间最少,主要由于采用协同进化粒子群算法对文本分类进行寻优,加快了算法的收敛速度,可以更好地满足网络文本在线分类需求。

表2 CEPSO-SVM与其它模型的分类速度对比
5 结语
本文针对支持向量机在文本分类过程的参数优化问题,利用协同进化粒子群算法控制参数少、寻优能力强的优势,提出一种数据挖掘技术的文本分类算法,其通过协同进化粒子群算法选择支持向量机参数,并采用文本数据对其性能进行仿真测试。实验结果表明,CEPSO-SVM不仅提高了文本分类的正确率,而且加快了文本分类的速度,是一种有效的文本数据挖掘方法。
[1]袁军鹏,朱东华,李毅,等.文本挖掘技术研究进展[J].计算机应用研究,2006,23(2):1-4.
[2]庞观松,蒋盛益.文本自动分类技术研究综述[J].情报理论与实践,2012,35(2):123-128.
[3]汪敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语相似度计算[J].中文信息学报,2008,22(5):84-90.
[4]王振振,何明,杜永萍,等.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[5]裴颂文,吴百锋.动态自适应特征权重的多类文本分类算法研究[J].计算机应用研究,2011,28(11):4092-4096.
[6]胡元,石冰.基于区域划分的kNN文本快速分类算法研究[J].计算机科学,2012,39(10):182-186.
[7]钟将,孙启干,李静.基于归一化向量的文本分类算法[J].计算机工程,2011,37(8):47-49.
[8]赵辉,刘怀亮,范云杰,等.一种基于语义的中文文本分类算法[J].情报理论与实践,2012,35(3):115-118.
[9]Fernando F,Kseniya Z,Wolf-Gang M.Text categorization methods for automatic estimation of verbal intelligence[J].Expert Systems with Applications,2012,39(10):9807-9820.
[10]Sujeevan A,Younes B.Semi-structured document categorization with a semantic kernel[J].Pattern Recognition,2009,42(9):2067-2076.
[11]何维,王宇.基于句子的文本表示及中文文本分类研究[J].情报学报,2009,28(6):839-843.
[12]Zakaria E,Abdelattif R,Mohamed A.Using word net for text categorization[J].The International Arab Journal of Information Technology,2008,5(1):16-24.
[13]Wei C P,Lin Y T Cross-lingual text categorization:conquering language boundaries in globalize environments[J].Information Processing & Management,2011,47(5):786-804.
[14]任剑锋,梁雪,李淑红.基于非线性流形学习和支持向量机的文本分类算法[J].计算机科学,2012,39(1):261-263.
[15]郑诚,李鸿.基于主题模型的K-均值文本聚类[J].计算机与现代化,2013,24(8):78-80,84.
TextClassificationAlgorithmOptimizingBasedonDataMining
LI Zhi-jian
(Aba Teachers University, Wenchuan Sichuan 623002, China)
Text classification is a key problem in network data management research, this paper puts forward a text classification algorithm based on data mining which uses nonlinear classification ability of support vector machine and search ability of collaborative global evolutionary particle swarm optimization algorithm. Firstly, the text samples are pre-processed to extract features, and then the features of training samples are input to support vector machines for training which co evolutionary particle swarm optimization algorithm is used to optimize the parameters of classifier, finally, the performance of the model is tested by Reuters21578 data. The results show that, co-evolution based on particle swarm optimization algorithm can quickly find the optimal parameters for support vector machine, improve the correct rate of text classification, classification speed can satisfy the application requirement of online classification.
text classification; co-evolution based on particle swarm optimization algorithm; feature vector; support vector machine
TP391
A
2095-7602(2017)12-0047-06
2016-12-30
李志坚(1982- ),男,助理研究员,硕士研究生,从事计算机应用技术研究。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中华养生保健(2020年7期)2020-11-16
计算机应用(2017年4期)2017-06-27
电力与能源(2017年6期)2017-05-14
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
故事会(2016年15期)2016-08-23
信息通信技术(2015年6期)2015-12-26
