
基于MapReduce的空间数据并行划分算法
2017-12-05 07:01:06付艳丽吴艳民张金标赵长虹方发林
测绘通报 2017年11期
付艳丽,吴艳民,张金标,郑 坤,赵长虹,郑 康,5,方发林,5
(1. 济南市勘察测绘研究院,山东 济南 250013; 2. 中国地质大学(武汉)信息工程学院,湖北 武汉 430074;3. 北京创时空科技发展有限公司,北京 100083; 4. 广东省气象探测数据中心,广东 广州 510610; 5. 武汉兆图科技有限公司,湖北 武汉 430070)
基于MapReduce的空间数据并行划分算法
付艳丽1,2,吴艳民3,张金标4,郑 坤2,赵长虹3,郑 康2,5,方发林2,5
(1. 济南市勘察测绘研究院,山东 济南 250013; 2. 中国地质大学(武汉)信息工程学院,湖北 武汉 430074;3. 北京创时空科技发展有限公司,北京 100083; 4. 广东省气象探测数据中心,广东 广州 510610; 5. 武汉兆图科技有限公司,湖北 武汉 430070)
针对海量空间数据分布式存储中存在的不顾及空间邻近性、分布不均和数据倾斜的问题,基于MapReduce并行编程模型,对Hilbert空间曲线层次分解的思想和节点容量感知的方法进行了研究,提出了一种层次分解的空间数据并行划分策略,并通过临界值判定实现空间数据的均衡存储。最后通过实例分析说明该方法可以在保证空间数据邻近特性的同时,解决海量空间数据分布式存储不均和数据倾斜的问题。
MapReduce;Hilbert空间曲线;空间数据并行划分
随着GIS应用的逐步深入和拓展,各行业对GIS海量空间数据的处理能力及效率提出更高要求,分布式GIS及分布式空间数据库应运而生[1]。特别是随着现代测量计算技术的发展,空间数据呈TB和PB级增长,大规模空间数据的分布式处理效率显得尤为重要[2]。
空间数据划分是空间数据分布式存储和处理的首要任务,其方法的优劣和执行效率直接影响空间数据分布式存储管理的整体性能。常用面向并行数据库的划分方法主要有轮转法、散列划分、范围划分、混合划分法等[3]。文献[3]对目前4种空间数据划分方法进行了探讨,指出这些划分方法基本上只能在选定关系的一个属性上划分,不能有效地支持非划分属性上的查询,并对常用的空间填充曲线Z-ordering曲线、Hilbert曲线进行了介绍。由于Hilbert曲线没有斜线,不能很好地保持空间邻近性,引起更多学者的关注;文献[4]基于Hilbert曲线自身的分形相似性特点,提出了Hilbert快速编码方法,通过空间层次分解提高了Hilbert曲线的编码速度;文献[1]基于Hilbert空间填充曲线提出了可以有效保证各存储节点间存储均衡的空间数据划分方法;文献[5]针对现有空间数据划分方法不考虑相邻对象空间关系对数据划分的影响等问题,提出了一种基于Hilbert空间填充曲线层次分单元的空间数据划分方法。这些研究为进一步研究空间数据划分算法提高了理论基础,但面对TB级或PB级海量的空间数据,空间数据划分效率低的问题一直没有得到很好的解决。
为了提高空间数据划分效率,一些学者提出将空间数据划分算法和并行计算技术相结合,如文献[6—7]基于MapReduce对Z-ordering曲线空间数据划分策略和基于X-means单元迭代的空间数据划分策略算法进行了并行执行。MapReduce是2004年Google在OSDI国际会议上提出的一种并行编程模型[8],公布了其基本原理和主要设计思想。由于其在海量数据处理方面的可扩展、容错性、高效率等特性,得到了很多学者广泛的关注和迅速发展。Yahoo针对MapReduce不能支持多个关联异构数据集的不足,对该模型进行了优化,提出了Map-Reduce-Merge,此后有很多学者对MapReduce进行了进一步的发展,如MoustafaAbdelBaky[9-10]等提出MapReduce-CometCloud框架,解决了MapReduce并行模型处理不同数量、不同大小的数据集性能低的问题。但关于空间数据划分算法和MapReduce技术相结合的研究相对较少,并且由于空间数据的分布特征,造成每个磁盘间的数据存储容量不均衡而产生的数据倾斜现象一直没有得到很好的解决。
基于以上分析和数据并行处理技术的研究,在顾及空间数据邻近特征的基础上,本文提出一种基于MapReduce的空间数据并行划分处理模型,实现空间数据的并行划分,以解决海量空间数据分布式存储不均和数据倾斜的问题。
1 MapReduce并行编程模型
MapReduce并行编程模型,使开发人员只需要通过map()和reduce()接口定义自己的处理函数,处理一组key/value(键值对)的输入,使用MapReduce映射规约进行运算,生成需要的key/value,很容易开发基于大型集群的程序,满足高效处理海量数据的要求[11-12]。
MapReduce并行执行框架对开发者隐藏了应用层算法外的所有细节,结合图1来说明MapReduce框架处理数据的执行过程。在MapReduce编程模型中,集群中的节点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务调度,TsakTracker负责并行执行任务,任务的执行主要分为map、shuffle、reduce 3个阶段。首先将输入数据文件进行划分,文件划分大小通过函数参数进行配置,一般为16 MB到64 MB大小,然后通过JobTracker为M个Map和R个Reduce分配任务。Map()函数阶段从HDFS读取对应的输入数据块,通过计算输出中间结果;Shuffle阶段将map()函数输出的结果按照key值划分成R分,每个划分对应于一个Reduce,并按key值做归并merge()处理,将具有相同key的key/value对合并,形成新的键值对数据集并传递给Reduce()函数。Reduce()函数对传入的每个key/value对进行相应的分析,输出最终结果。

图1 MapReduce框架数据处理执行过程
2 顾及空间邻近性且数据均衡分配的空间数据划分算法
2.1 空间数据划分思想
空间数据划分思想主要分为两部分:一是划分过程中保持空间数据之间的邻居特性;二是在划分过程中,体现存储节点之间性能的差异,使数据负载均衡。利用空间填充曲线中近似表示方法对空间数据进行划分,将数据划分成大小相同的网格,并按照一定的规则对每个网格进行编码,在一定程度上保持空间邻近性,将多维的空间数据降维在一维空间中表示[13]。Hilbert曲线利用一个线性序列来填充空间,由于阶数不同的Hilbert网格之间遵循四叉树分解规则,这就可以对子网格依据四叉树的层次分解编码方法,获得子网格下一级的Hilbert编码,这样无需细分整个空间,就能达到良好的划分效果。根据以上对MapReduce并行编程模型和空间数据划分思想的分析,以MapReduce并行编程模型为基础,利用Hilbert曲线层次划分方法和临界值限定来确保划分后空间数据的邻近性及多个存储设备上的均衡划分,具体的空间数据划分思想如图2所示。
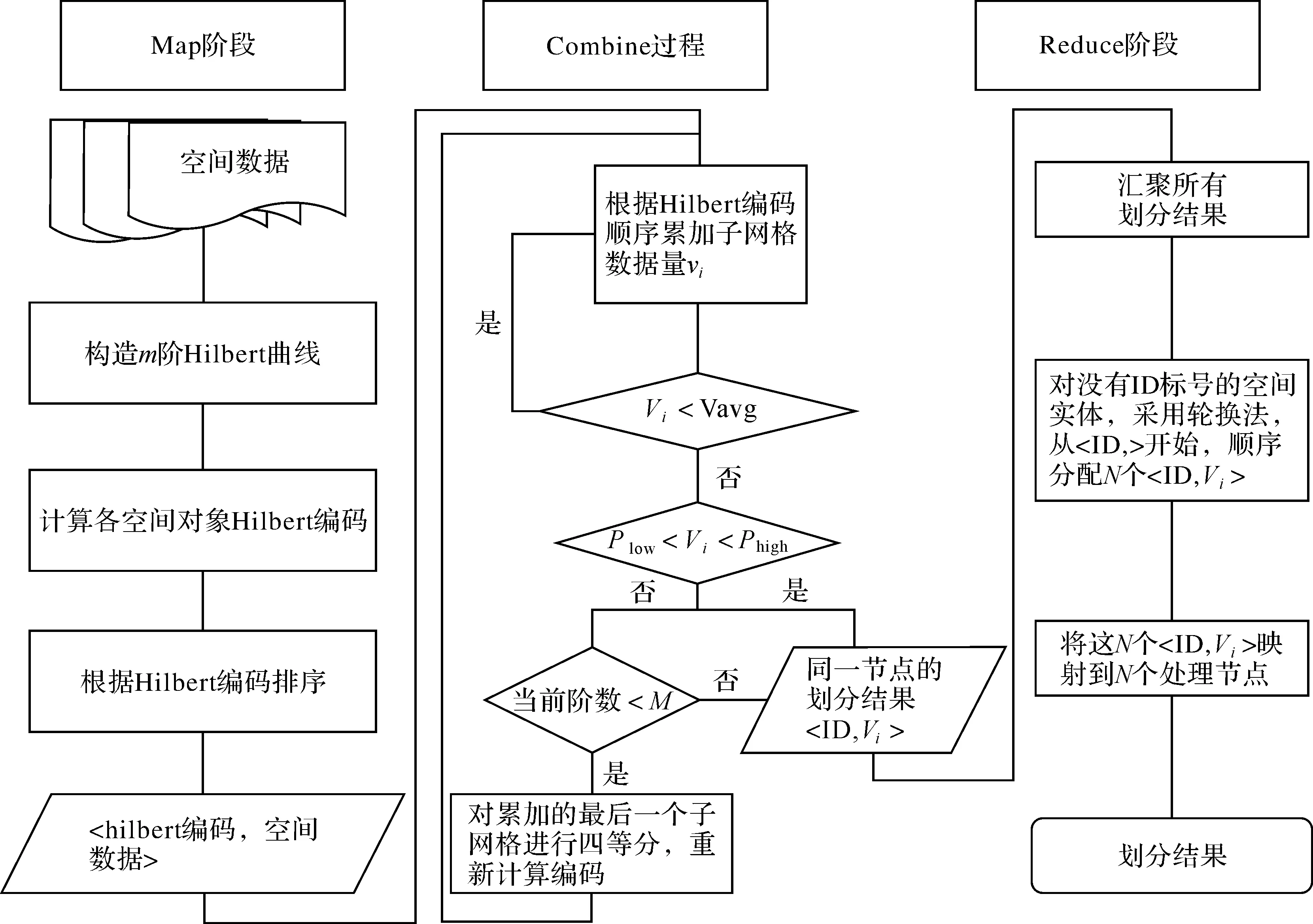
图2 基于MapReduce的空间数据划分算法流程
结合图2基于Hilbert曲线层次分解提出的空间数据划分思想如下[14-15]:①根据空间数据对象个数n,确定Hilbert曲线的初始阶数m和子网格层次分解的中止阶数M,将整个空间范围划分成2m×2m的网格;②根据Hilbert编码对空间对象进行排序[11],并从起始编码累加各个空间对象的数据量,当累加到第K个子网格时,如果总数据量超过单个存储节点限定的平均存储量Vavg,则对第K个子网格进行四等分,计算下一级网格的Hilbert编码,直至适量的空间对象放入存储节点或子网格层次分解次数到达中止阶数M,停止子网格的层次划分;这样不仅保证了空间数据间的邻近性,又使得划分后的数据量大致均衡。其中Vavg采用的公式如下
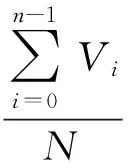
(1)
在保证数据划分均衡的前提下,为体现节点之间的性能差异,应使节点之间负载均衡。在空间数据划分过程中采用节点容量感知的方法,设置每个存储节点容量的临界值Plow和Phigh,两个值的计算公式如下
(2)
Plow=P(1-k)
(3)
Phigh=P(1+k)
(4)
式(3)—式(4)中,Si为第i个节点的物理地址范围之和;Wi为每个节点的资源标准化权值(如采用100 GB为单位,300 GB的节点W值为3,200 GB的节点W值为2);k0,1,k值的设定和物理节点的个数有关,物理节点数越多,k值越小,一般设置k值为25%。
2.2 基于MapReduce的空间数据划分处理
根据以上对MapReduce并行编程模型和空间数据划分思想的分析[16-17]可以看出,基于MapReduce的并行空间数据划分算法主要分为以下4部分:①数据集分发管理阶段;②数据预处理阶段;③空间数据划分执行阶段;④数据划分结果的控制输出。图3为MapReduce空间数据处理流程。实现基于MapReduce空间数据划分主要体现在Map()、Combine()、Reduce()函数的实现上,以HilbertBegin类为程序入口,通过setMapperClass()、setReducer()设定HilbertMap、HilbertCombine、HilbertReduce分别作为以上3个函数的实现类。
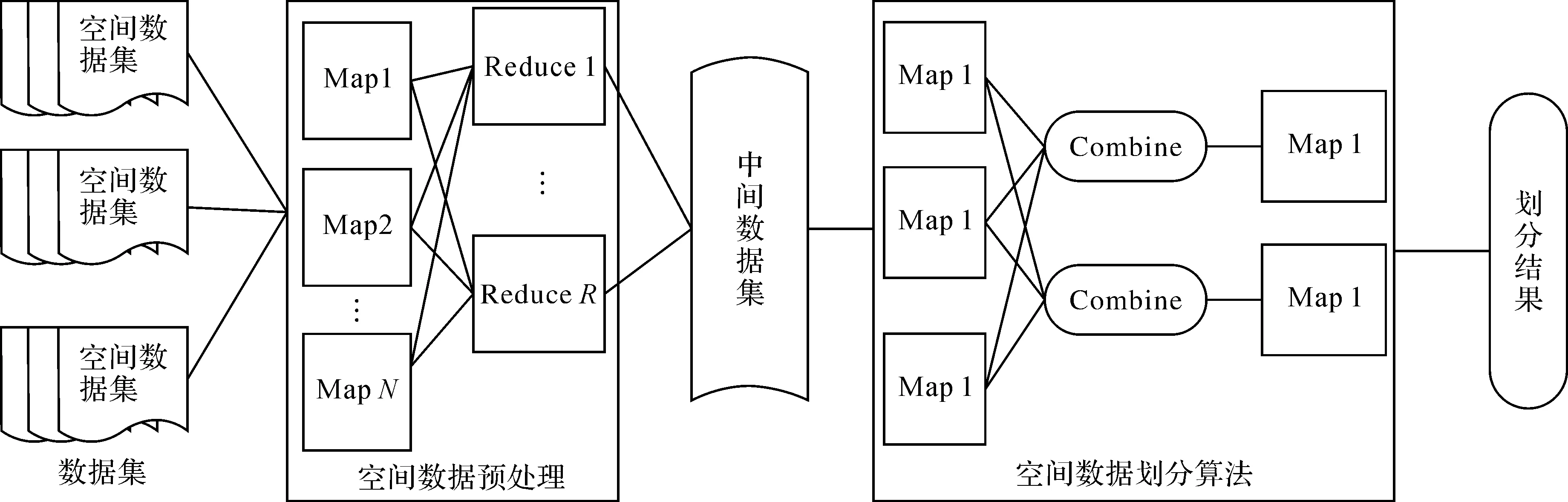
图3 基于MapReduce数据划分处理流程
3 算法实例分析
为了验证算法的有效性,基于Hadoop在一台主频2.3 GHz、四核i5处理器,内存为4 GB的电脑上创建3台操作系统为RedHatEnterprise 5的虚拟机,使用MyEclipse+Hadoop plugin开发环境进行开发,对包含98 762个空间对象的数据集进行数据划分试验。表1是使用此划分方法在3个存储节点上的数据划分结果,可以看出,该方法保证了相对均衡,基于层次分解的Hilbert编码在保证空间邻近性的同时,通过Vavg、Plow和Phigh两次临界值判定,保证各个存储节点数的据量相对均衡,避免了数据倾斜,达到负载均衡的效果。
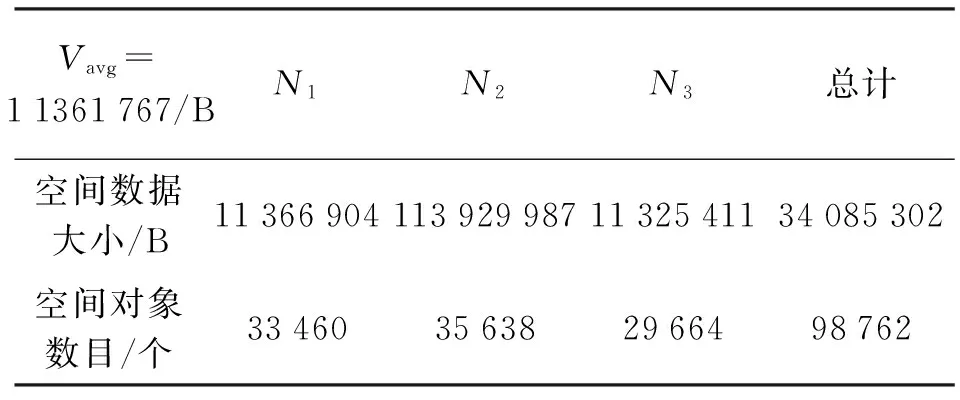
表1 各个存储节点的数据划分结果
此外为了验证算法的效率,与传统串行Hilbert曲线划分法进行对比,结果如图4所示。在相同磁盘I/O条件下,当空间对象数目很少时,基于MapReduce的空间数据划分算法没有任何优势,但随着空间对象的增加,基于MapReduce的并行空间数据划分算法的时间优势逐渐显著,从图形曲线走势可以推断,基于MapReduce的并行空间数据划分算法在海量空间数据划分中具有更高的数据划分效率。
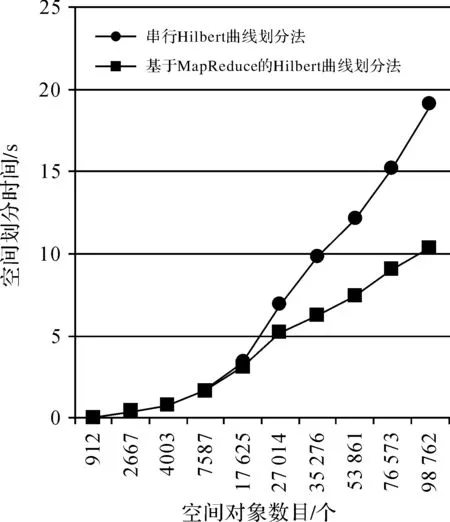
图4 两种空间数据划分方法效率比较
4 结 论
空间数据的划分方法是分布式空间数据存储的关键,关系空间数据整体应用和服务功能。本文在MapReduce并行编码模型的基础上构建了基于Hilbert的层次分解的空间数据划分算法,在利用层次分解思想保证空间邻近特征的同时,采用节点容量感知的方法增加临界值判定,通过实例分析证明该方法克服了海量空间数据分布式存储不均和数据倾斜的问题,在一定程度上提高了空间数据划分的时间效率,为海量空间数据存储提供了有益参考。由于受条件的制约,有关该算法的效率分析还有待今后在实践中进行更深入的验证和改进。
[1] 赵春宇,孟令奎,林志勇. 一种面向并行空间数据库的数据划分算法研究[J]. 武汉大学学报(信息科学版), 2006, 31(11): 962-965.
[2] ZHENG K, GU D, FANG F, et al. Data Storage Optimi-zation Strategy in Distributed Column-oriented Database by Considering Spatial Adjacency[J]. Cluster Computing, 2017: 1-12.
[3] SHEKHAR S, CHAWL S. 空间数据库[M]. 北京:机械工业出版社,2004.
[4] 陆锋,周成虎. 一种基于空间层次分解的Hilbert 码生成算法[J]. 中国图象图形学报,2001,6(5): 465-469.
[5] 周艳, 朱庆, 张叶廷, 基于Hilbert曲线层次分解的空间数据划分方法[J]. 地理与地理信息科学, 2007,23(4):13-17.
[6] CARY A, SUN Zhengguo, HRISTIDIS V,et al.Experiences on Processing Spatial Data with MapReduce[C]∥21st International Conference on Scientific and Statistical Database Management. Berlin: Springer, 2009.
[7] CARY A, YESHA Y, ADJOUADI M, et al. Leveraging Cloud Computing in Geodatabase Management[C]∥2010 IEEE 16th International Conference on Parallel and Distributed Systems (ICPADS). [S.l.]: ICPADS, 2010:73-78.
[8] DEAN J,GHEMAWAT S. MapReduce:Simplified Data Processing on Large Clusters[J]. Conference on Symposium on Opearting System Design and Implementation, 2014, 51(1):10.
[9] ABDELBAKY M,KIM H,RODERO I,et al. Accelerating MapReduce Analytics UsingCometCloud[C]∥2012 IEEE 5th International Conference on Cloud Computing. [S.l.]: IEEE, 2012:447-454.
[10] BENDAHMANE A,ESSAAIDI E, MOUSSAOUI A E, et al. A New Mechanism to Ensure Integrity for MapReduce in Cloud Computing[C]∥2012 International Conference on Multimedia Computing and Systems (ICMCS). [S.l.]: ICMCS, 2012: 785-790.
[11] LI F, OOI B C, WU S. Distributed Data Management Using MapReduce[J]. ACM Computing Surveys, 2014, 46(3): 1-42.
[12] 王凯,曹建成,王乃生,等.Hadoop支持下的地理信息大数据处理技术初探[J].测绘通报,2015(10):114-117.
[13] 曹雪峰,万刚,张宗佩.紧致的 Hilbert 曲线 Gray 码索引算法[J]. 测绘学报, 2016, 45(S1): 90-98.
[14] 付仲良,胡玉龙,翁宝凤,等. M-Quadtree 索引: 一种基于改进四叉树编码方法的云存储环境下空间索引方法[J]. 测绘学报, 2016,45(11):1342-1351.
[15] 周敬利,周正达.改进的云存储系统数据分布策略[J]. 计算机应用,2012, 32(2): 309-312.
[16] 陈德军,高晓军,王义飞. 基于 AHP 的云存储负载均衡研究[J]. Computer Engineering and Applications, 2015, 51(7): 56-60.
[17] ELDAWY A, MOKBEL M F. SpatialHadoop: A MapReduce Framework for Spatial Data[C]∥2015 IEEE 31st International Conference on Data Engineering (ICDE). [S.l.]: IEEE, 2015: 1352-1363.
SpatialDataParallelPartitioningAlgorithmBasedonMapReduce
FU Yanli1,2,WU Yanmin3,ZHANG Jinbiao4,ZHENG Kun2,ZHAO Changhong3,ZHENG Kang2,5,FANG Falin2,5
(1. Jinan Geotechnical Investigation and Surverying Institute, Jinan 250013, China; 2. School of Information Engineering, China University of Geosciences(Wuhan), Wuhan 430074, China; 3. Beijing Create Space-time Science and Technology Limited Company, Beijing 100083, China; 4. Guangdong Meteorological Observation Data Center,Guangzhou 510610,China; 5. Wuhan Trillion Map Technology Limited Company,Wuhan 430070, China)
Spatial data partitioning method plays an important role in spatial data distributed storage, and its key problem is how topartition spatial data to distributed storage nodes in network environment. This paper discusses massive spatial data partitioning strategies and analyses their disadvantages which these partitioning methods have not taken into account spatial object size and spatial proximity. Aiming at these questions,this paper proposes a new spatial data parallelpartitioning strategy based on MapReduce and capacity-aware method to improve load balance which could avoid unevenly distributed data storage and data skew. Experimental analysis shows that the presented spatial data parallel partitioning algorithm not only achieves better storage load balance in distributed storage system,but also keeps well spatial locality of data objects after partitioning.
MapReduce; Hilbert space filling curve; spatial data parallel partitioning
付艳丽,吴艳民,张金标,等.基于MapReduce的空间数据并行划分算法[J].测绘通报,2017(11):96-100.
10.13474/j.cnki.11-2246.2017.0356.
P208
A
0494-0911(2017)11-0096-05
2017-05-16
国家重点研发计划(2016YFB0502603);湖北省自然科学基金(ZRY2015001543);中国地质大学(武汉)中央高校基本科研业务费资金(1610491B20)
付艳丽(1988—),女,硕士,工程师,主要从事GIS开发工作。E-mail:fuyli@126.com
张金标。E-mail: zhangjb@grmc.gov.cn
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
当代陕西(2019年14期)2019-08-26 09:42:00
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
测绘科学与工程(2016年4期)2016-04-17 06:51:13
雷达与对抗(2015年3期)2015-12-09 02:38:50
自动化博览(2014年12期)2014-02-28 22:34:27
测绘科学与工程(2014年2期)2014-02-27 07:05:49
测绘科学与工程(2013年1期)2013-03-11 15:07:25
