
基于特征加权的新闻主题句抽取
2017-11-27 08:58张桂平朱耀辉
中文信息学报 2017年5期
万 国,张桂平,白 宇,朱耀辉
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
基于特征加权的新闻主题句抽取
万 国,张桂平,白 宇,朱耀辉
(沈阳航空航天大学 知识工程研究中心,辽宁 沈阳 110136)
根据新闻文本的特点,分别对新闻标题与正文进行分析,该文提出了一种针对新闻文本的特征加权的主题句抽取方法。首先对新闻主题句在文本中的分布情况进行分析,选取了位置特征;然后根据新闻标题对于新闻主旨的提示作用,选取了标题句子重合度与关联度的特征,且在关联度特征中将基于加权二部图的最大匹配算法融入其中;最后依据句子的得分排名,进行主题句抽取。实验显示,利用该方法进行主题句抽取的P@1为75.9%,P@3 达到92.4%。
特征加权;重合度;关联度;加权二部图
1 引言
随着互联网技术的飞速发展,网络数据正以爆炸式的方式迅速增长。新闻作为众多信息来源的一种,具有真实、及时、广泛等特点,是人们了解实时动态的主要渠道。然而面对海量的新闻报道,人们如何快速锁定所关注的内容,一直是一个亟需解决的问题。
新闻主题句作为一篇新闻报道的核心,基本能够反映出新闻的主要内容。若能标注出文章的主题句,无疑会加速人们对新闻文本的阅读和理解,节省大量的时间。而且基于文本的主题句抽取对文本分类[1]、文本文摘[2]、信息检索[3]、文本倾向性分析[4]等有着重要的作用。然而面对海量的新闻文献,人工一一进行标注,显然是不切实际的,如何快速有效地自动识别出新闻的主旨一直是人们关注的焦点。
目前国内外的学者在主题句抽取方面已经做了一些研究。王力[5]等人基于LDA模型进行主题抽取,采用Gibbs抽样的方法通过多个侧面来反映主题的信息,利用主题概率分布的平滑度进行可信度计算,取得最终的主题句,在实验验证中取得了较好的效果。Harada[6]等人利用文章作者写作时表述观点的语气和态度、句子主题的依赖性和句子中运用的修辞手法等综合因素进行主题句的抽取,实验证明最终抽取的句子可以很清楚地表达作者的观点。张云涛[7]等人运用不同的权值度量方式,对同义概念进行语义归并,对上下文概念进行语义聚焦,综合评估句子反映主题价值的多少,以此抽取最能反映文章主题的句子。葛斌[8],Yeh[9]等人将主题句抽取问题转化为无向图中结点权重计算问题,根据图中边的权重来衡量其在文章中的重要程度,以此抽取最终的主题句。
虽然已有不少针对文本主题句抽取的研究,但专门针对新闻主题句抽取的研究却还相对较少。新闻作为一种特殊的文本有着自身的特性,对于它的研究与其他文本的研究有着很重要的差异。目前针对新闻抽取的研究主要集中于新闻中关键词、短语的抽取[10-11]等。而在新闻文本的主题句抽取方面,Kastner[12]等人运用了大量的特征包括(语法、语义和一般的统计特征)来从新闻专线的文章中找出能够代表文章内容的关键句子。王伟[13]等人根据新闻标题对于主题句的查找是否具有提示作用,将新闻标题进行分类,并结合句子的位置、长度及句子中的命名实体等综合特征来计算句子的重要程度。
本文在借鉴前人的基础之上,分析新闻文本自身的特点,依据主题句在文本中的分布与新闻标题对新闻主旨的借鉴作用来制定规则,最终通过特征加权的方式建立主题句抽取模型。
2 新闻文本的特点
新闻作为一种信息传输的媒介,一种特殊的文本,具有其自身的特性。一般的新闻主要由新闻标题、新闻正文两部分构成。对于一般的新闻,标题统领文章的主要含义,正文是对新闻标题的延续与扩充。新闻主题句正是根据新闻标题与新闻内容的特点,从新闻文本中筛选过滤而得的能代表新闻主旨的句子。下面分别从新闻标题与新闻正文两方面阐述新闻文本的特点。
2.1 新闻标题
新闻工作者认为新闻标题是新闻的灵魂,为了吸引读者的眼球,新闻标题大体表述了新闻的主旨思想。新闻标题的长度一般较短,但却包含了丰富的含义、便于人们了解新闻报道的主体信息。用户一般根据新闻标题来选取自身感兴趣的话题,短而精炼的标题对于用户快速定位自身感兴趣的新闻有着很好的促进作用。
本文从人民网、新华网、科学网等网站中搜集了总计10 000个新闻标题,对新闻标题的长度进行统计分析,具体情况如图1所示。
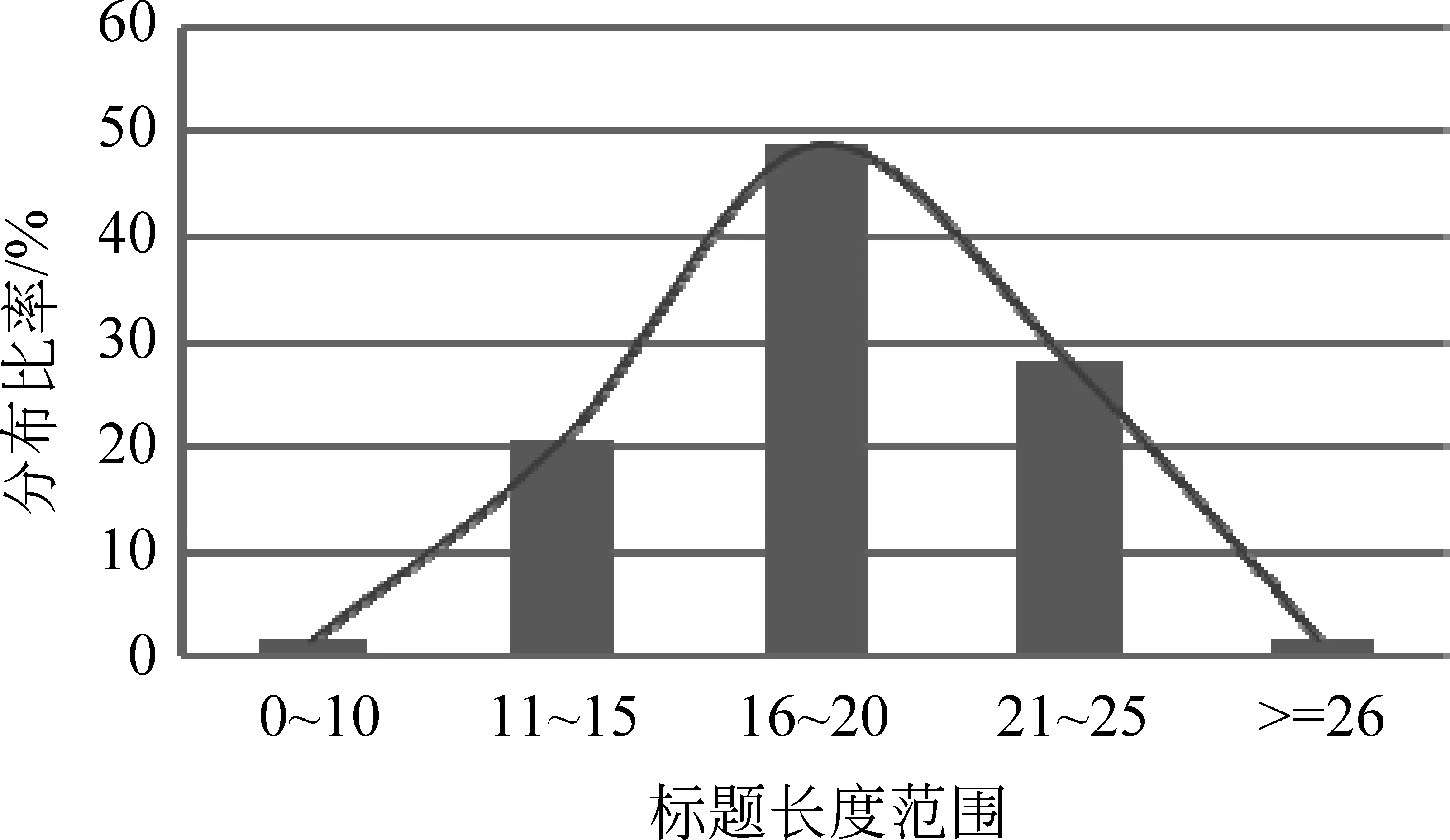
图1 新闻标题长度的统计
由图1可知,新闻标题的长度大多数集中于 11~25个字符之间。正好符合新闻写作的一般技巧[14],若字符太少,很难详尽地描述出新闻的主体内容;若字符过多,又显得不那么简约精炼。新闻标题正是通过这些短而精炼的字符,将新闻最核心的内容呈现给了读者。因此新闻标题对于最终主题句的抽取有着很好的借鉴作用。
2.2 新闻正文
新闻正文详细论述了新闻的具体事务,按照新闻表述的一般形式,新闻的要点一般出现在新闻的前面,新闻的后半部分只是对新闻主题的具体阐述与扩充。主题句的位置对于人们了解文本的内容至关重要[15],因此新闻主题句一般出现在新闻的开头。图2为本文语料中主题句在新闻文本中的分布情况(仅统计前十句为主题句的情形)。
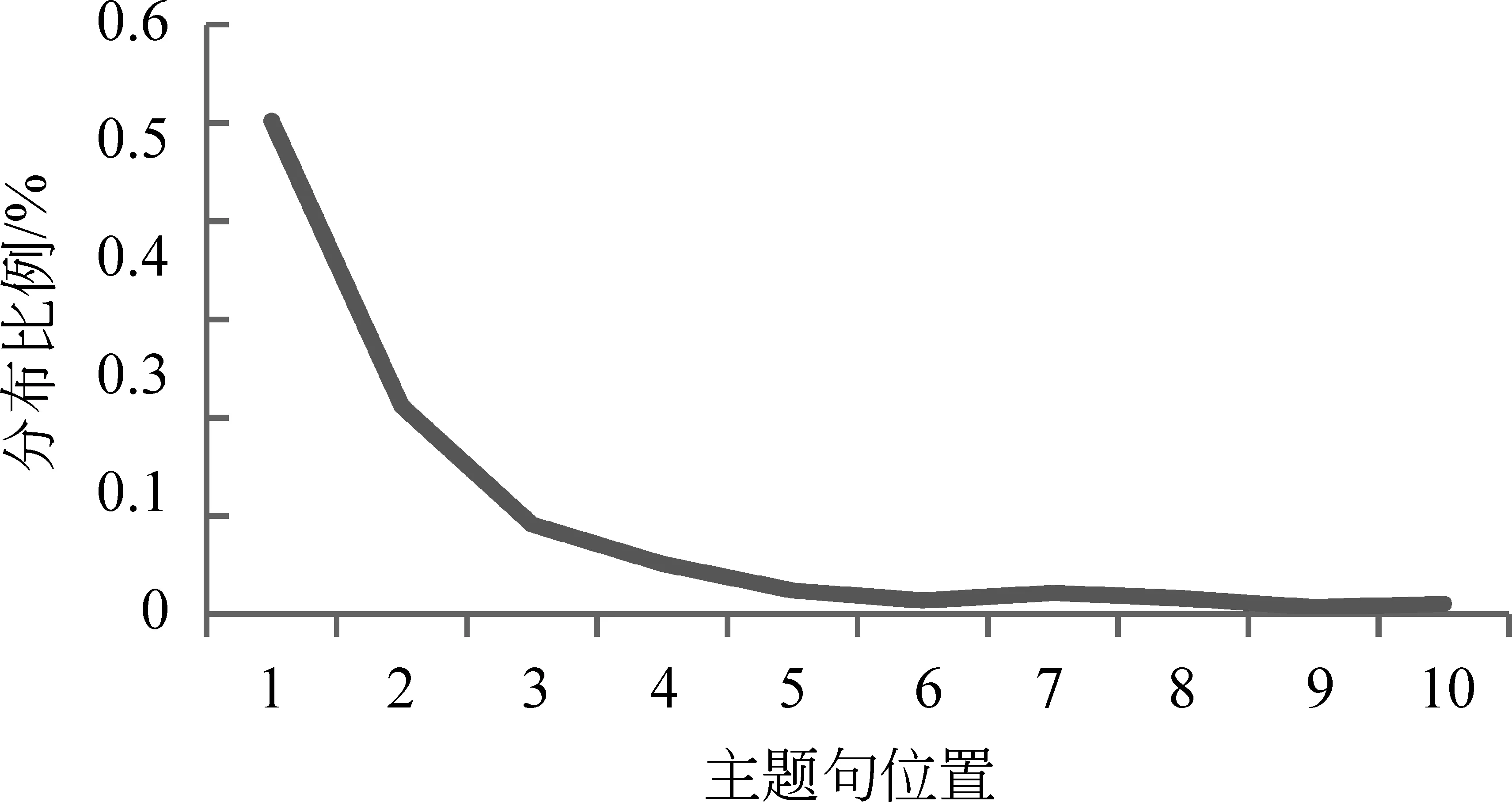
图2 主题句在新闻中的位置分布比例
由图2可以看出,随着位置的后移,新闻主题句分布比例不断减少。这与新闻要点前置这一现象基本一致,也为新闻主题句的抽取提供了可靠的依据。
3 新闻的主题句提取
新闻主题句是指基本能够反映新闻主旨的句子,目前已有许多运用特征进行主题句抽取的研究,但选取的特征大都基于特定领域,对于文本的依赖性较大。本文根据上文描述的新闻标题、正文的特点,即新闻主旨鲜明、标题大体反映新闻的主要内容、正文从结构上讲将要点前置等这些准则,选取了针对新闻文本自身的一些特征,最终通过特征加权的方式建立了新闻主题句抽取的模型。
3.1 特征选取
(1) 句子的位置
根据图2可知,句子的相对位置与该句是否为主题句有很大的关联。因此文本中句子的相对位置对主题句的抽取有很大的借鉴作用。具体特征如式(1)所示。
Scoreloc(si)=1-logi/logn
(1)
其中i为句子在文本中的相对位置,n为文本中句子总数。
(2) 标题句子重合度
标题对于主题句的选取有着很好的指引作用。一般情况下句子与标题中重复的词越多,该句话是主题句的概率也越高。具体特征如式(2)所示。
Scoreoverlap(si)=∑w∈T∈siterm_weight(w)
(2)
其中T为新闻标题,si为文本中的第i句话,term_weight(w)为词的权重,权重计算公式用传统的tf-idf方式计算而得,Scoreoverlap(si)为该句子与标题重合度的得分。
实验过程中发现,某些时候tf-idf的计算方式不能很好地度量词的权重,如句子与标题有很多重复的词,但这些词的权重都相对较小。此时将重复词的个数与权重进行组合得式(3)。
(3)
其中Numoverlap为句子与标题中重合的词的个数。
最后,为了保证最终特征加权时每个特征在0~1范围内,对该特征进行归一化。最终的句子特征重合度的计算公式为式(4)。
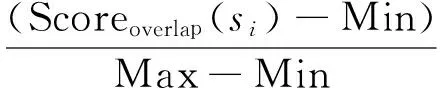
(4)
其中Min指用式(3)计算而得的文本中句子标题重合度中值最低的得分, Max为最高得分。
(3) 标题句子关联度
鉴于新闻标题在新闻文本中无可替代的作用。虽然上面句子标题重合度已经将标题应用于主题句抽取的特征中,但上述特征要求重合的词必须完全一致。但实际应用中发现在标题中很多时候为了语言的精炼使用了大量的简称、缩略词等。如北大和北京大学,这样的情况重合度的特征就不适用。为了解决这一情形对于实验结果的影响,我们引入词向量来描述词与词之间的相近程度,运用加权二部图的最大匹配法寻找句子标题之间的极大匹配作为句子标题的关联度。
计算标题与句子关联度的伪代码如下:

句子标题关联度算法输入:标题T(w1,w2,...,wn)、句子Si(s1,s2,...,sm)、词向量字典初始化参数:句子标题的关联度得分Scoresim(si)repeatfori=1tondo forj=1tomdo 计算句子标题的权值矩阵weights 根据weights,用加权二部图的最大匹配计算标题句子的关联度Scoresim(si) endforendfor运用式(4)的方法进行归一化输出:句子标题的关联度得分Scoresim(si)
其中,T(w1,w2,...,wn),Si(s1,s2,...,sm)分别表示标题T和句子Si,w1,w2,...,wn和s1,s2,...,sm分别表示构成标题和句子Si的词。词向量字典的获得通过ICTCLAS2014(http://ictclas.nlpir.org/)将新闻语料进行分词,然后通过开源工具word2vec(https://code.google.com/p/word2vec/)训练而得。句子标题的权值矩阵weights,由词与词之间的相似度矩阵构成,而词与词之间的相似度通过cos的方式计算两个单词间的词向量而得。
用加权二部图的最大匹配计算标题句子的关联度Scoresim(si),将标题中的词的集合和句子中的词的集合看成二部图,词与词之间的相似关系,看成它们之间的权值。通过Kuhn-Munkras求解出权和最大的匹配。如图3所示的案例中,标题T中有两个词(w1,w2),句子S中有三个词(s1,s2,s3),边上的权

图3 基于加权二部图的句子标题关联度实例
值代表词与词之间的相似性。运用加权二部图的极大匹配可以求得最终标题与句子的关联度为13。当然,最终要对文本中所有的标题句子关联度进行归一化。
3.2 主题句提取
根据上述选取的特征,结合新闻自身的特点,最终新闻主题句的计算如式(5)所示。
g(x)=∑iwi·Scorei
(5)
其中wi为它们对应的权值,Scorei代表Scoreloc,Scoreoverlap,Scoresim,其中∑wi= 1,0≤wi≤1。
求解wi的值时,根据∑wi=1,0≤wi≤1,设定步长为0.1,组合所有的可能性共66种,因为新闻主题句语料的限制,运用5折交叉验证的方式查看不同特征值组合时主题句抽取的准确率的情况,实验中发现每次取最优值时的参数比较集中,为了求解出最终的实验结果,取五次实验的平均值。 图4显示了wi为不同取值时,新闻主题句抽取正确率的情况。由图4可知,当w1=0.3,w2=0.2,w3=0.5时,实验的准确率最高,最终主题句抽取模型的参数就选定为该组值。
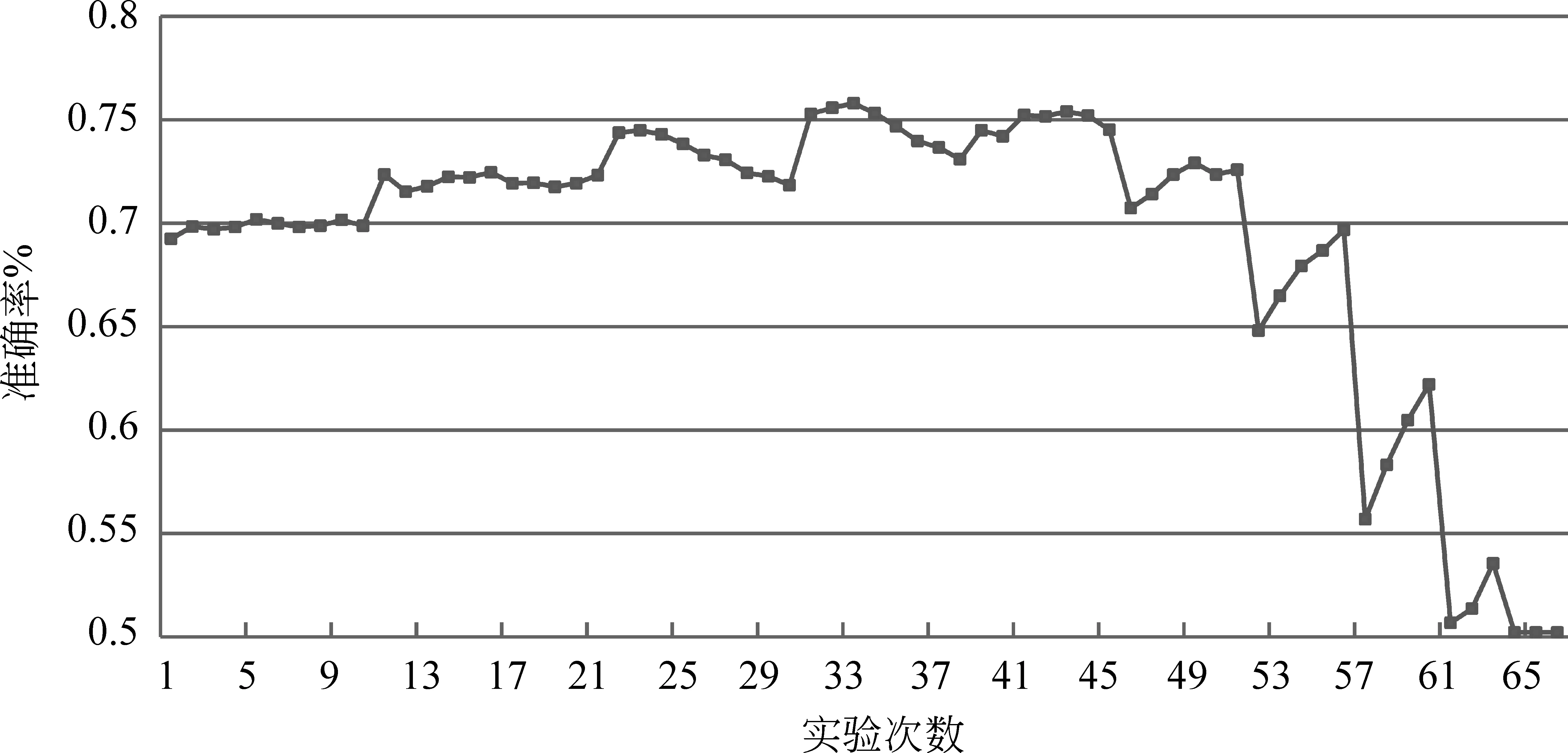
图4 每组wi对应的准确率的值
为了更好地理解该组参数,表1分别对图4中的特殊点进行分析研究。其中实验1至3为每个特征单独抽取时的准确率,实验4至6为三个特征两两组合,准确率最高时的情形。实验7为三个特征组合时准确率最高时的情形。可以看到两个特征组合时,无论loc与overlap组合还是与sim组合,得到的效果都很显著,并且loc与sim组合时的效果要优于与overlap组合时的效果,说明loc对于sim的促进效果更加显著。而overlap与sim组合的效果低于overlap单个特征时的准确率,却高于sim单个特征时的准确率,说明这两个特征组合到一起对overlap有抑制作用,而对sim有促进作用。三个特征组合时求得的结果最终优于上面的情形。根据上面的分析,当取得最大值时对应的参数w1=0.3,w2=0.2,w3=0.5便比较合理了。
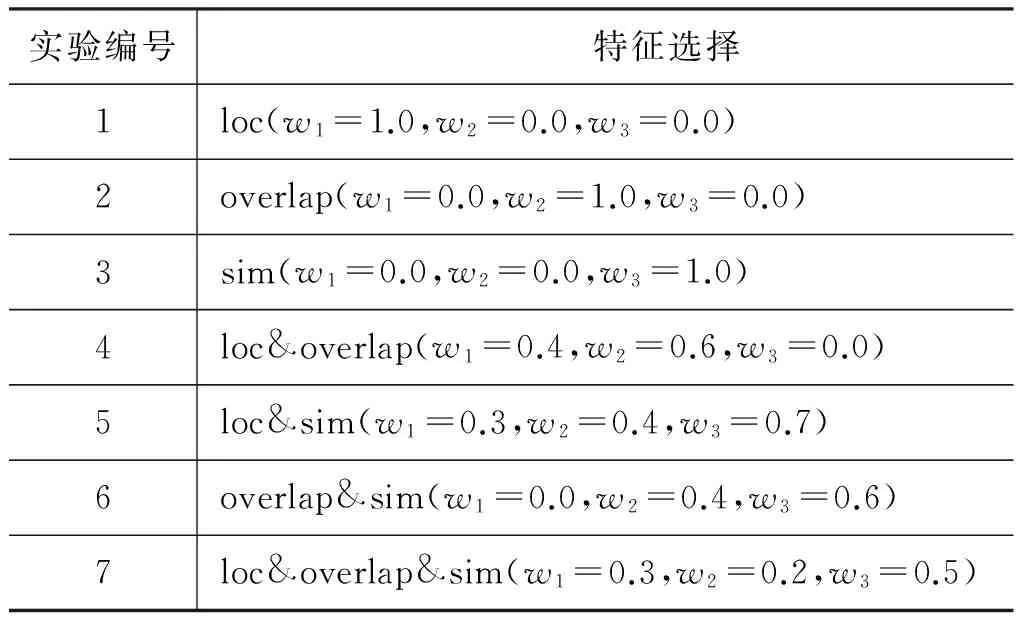
表1 特征选择及对应准确率的值
4 实验设计及结果分析
4.1实验语料及评价指标
为了验证本文提出的特征对于新闻主题句抽取的有效性,从人民网、新华网、科学网等网站中收集了1500篇新闻文本,涉及政治、民生、体育、环保、IT等多个方面。由两名自然语言处理专业的研究生分别进行主题句的标注,人工标注时对于主题混淆不清的新闻报道予以剔除,最终选取两名同学标注一致的新闻共878篇,作为我们的语料进行实验。实验中随机选取语料中的80%作为训练数据,剩余的20%作为测试数据。实验过程中为了消除不同新闻语料对实验结果的影响,使用了交叉验证。
表2为所使用语料的基本信息。
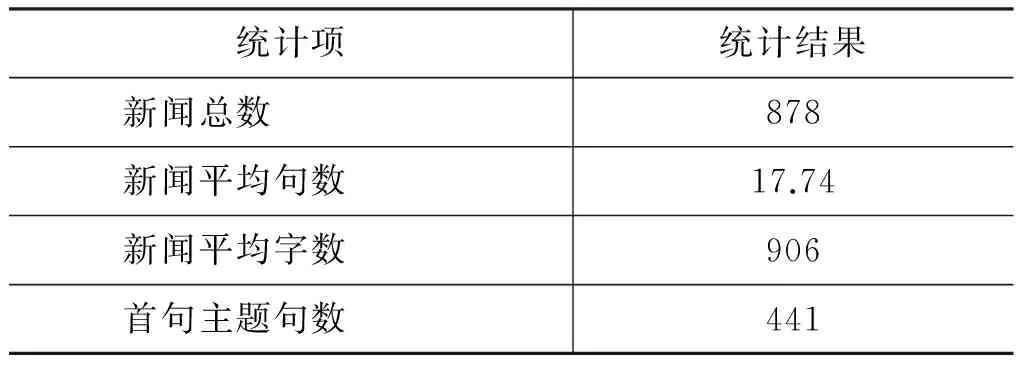
表2 新闻语料的信息统计
本文的主题句主要是指最能够代表新闻观点的论句。设定每篇新闻报道只标注一句话作为其主题句。本文采用的评价指标为准确率。但与传统的准确率略有不同,具体如式(6)所示。

其中,正确抽取的句子数指从单篇文本中抽取得分最高的N句,若其中包含所标注的句子,则记为抽取正确。根据从单篇文本中抽取句子数目的不同,准确率记为P@N。
4.2 实验结果和分析
通过特征加权的主题句抽取,实际上就是通过选取能够描述文章内容的特征,选取合理的权值,将它们结合到一起,选取最能够代表文章内容的一句话。本文主要通过三种方法进行主题句抽取的对比分析。
① 首句法,根据图2的分析研究,了解到句子的位置与该句是否为主题句有很大的关系,以及Dorr[16]直接将首句作为主题句的先例,本文直接选取首句作为新闻的主题句,记为基于首句的主题抽取方法(FS_based)。
② 运用文献[8]中的方法,在该篇论文中选择的特征较多,同时还考虑到了标题是否具有提示作用,选择最好的实验效果作为本实验的对比结果,记为基于多特征的主题抽取方法(Multi_Feature)。
③ 为本文提出的特征加权的主题句抽取方法(Feature_Weight)。
为了减少新闻语料差异性对主题句抽取结果的影响,分别在交叉验证集上进行五次实验,最终取五次的平均值作为最终实验的结果。实验结果如图5所示。
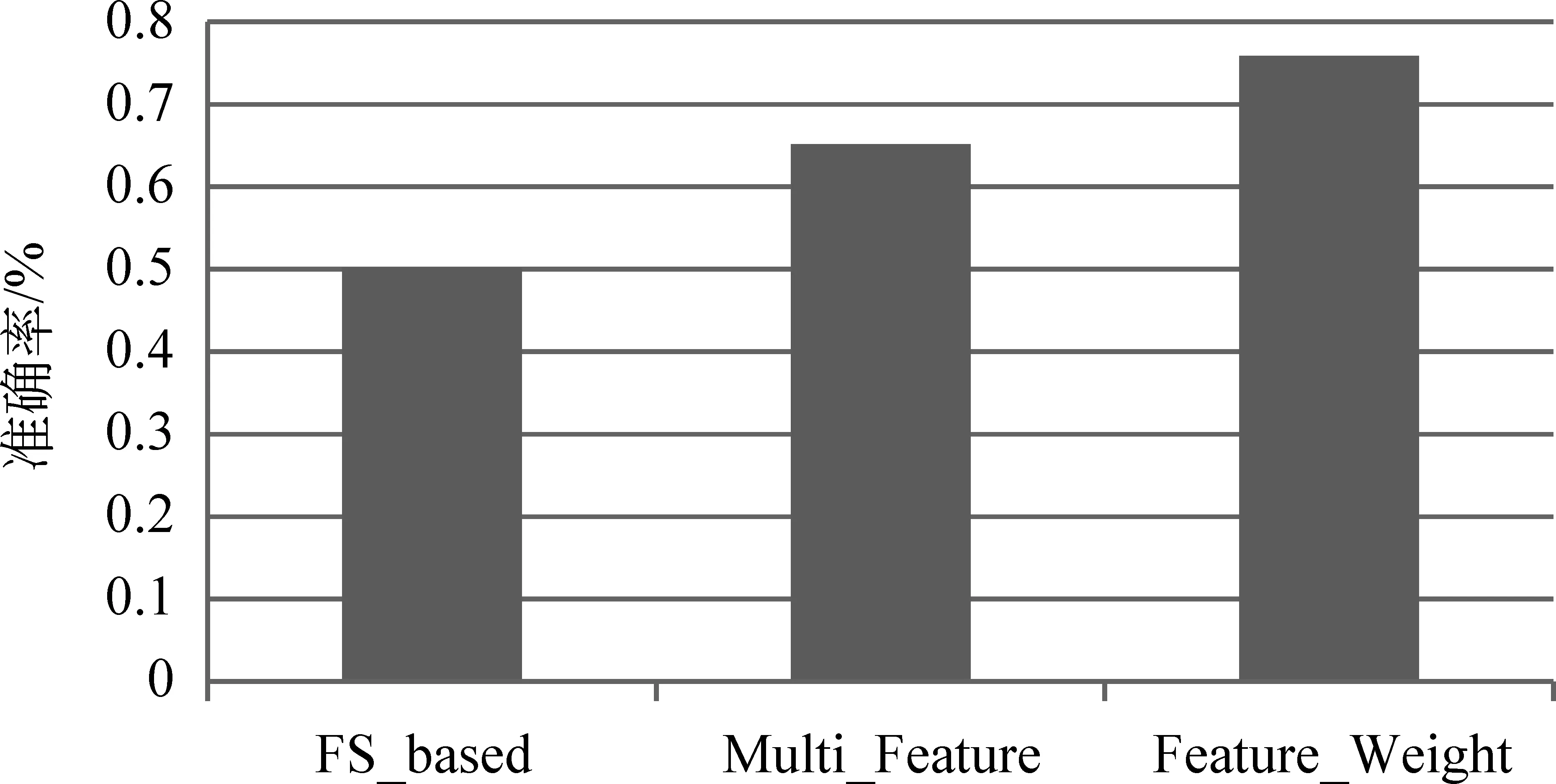
图5 三种方法准确率的比较
如图5所示,基于特征加权的方法大大优越于基于首句的方式,比多特征的主题抽取方法也高出了10%,说明本文提出的方法能更有效地提取新闻的主题句。方法②中的特征个数比方法③中的特征个数多,实验结果却不及方法③,说明特征的选取并非越多越占优势,选取的特征之间相互影响或许会降低整个抽取的效果。
本文还加大了单篇文本的抽取数目,以查看不同P@N值的情况,详情如图6所示。
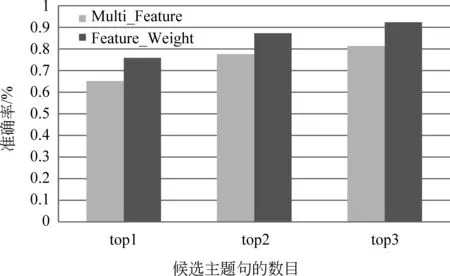
图6 两种算法在不同候选值中准确率
用主题句抽取算法进行主题句抽取时,随着抽取数目的增多,能够抽取的新闻主题句的数目也不断增加。当选择前三句话作为候选主题句时,两种方法的准确率都有较大幅度的提升,而且本文中的方法要明显高于多特征方法的准确率。当抽取三句话时,本文方法的P@3达到了92%,说明本实验中的方法可以将候选的主题集合限定在较小的范围内。关于没有抽取到的10%,可能的原因如下: 某些新闻的主旨太过分散,一两句话难以描述该新闻的主要内容,案例如图7所示;也有些新闻标题太短,透露的信息量相对较少,文中有很多句子都可以描述新闻标题所要描述的内容,案例如图8所示,图中灰色标注的都可以反映新闻的主旨。

图7 新闻案例1

图8 新闻案例2
为了进一步验证本文所选取特征的高效性,本文还考查了在单特征下选取不同数目的候选主题句时P@N的情况,具体如图9所示。
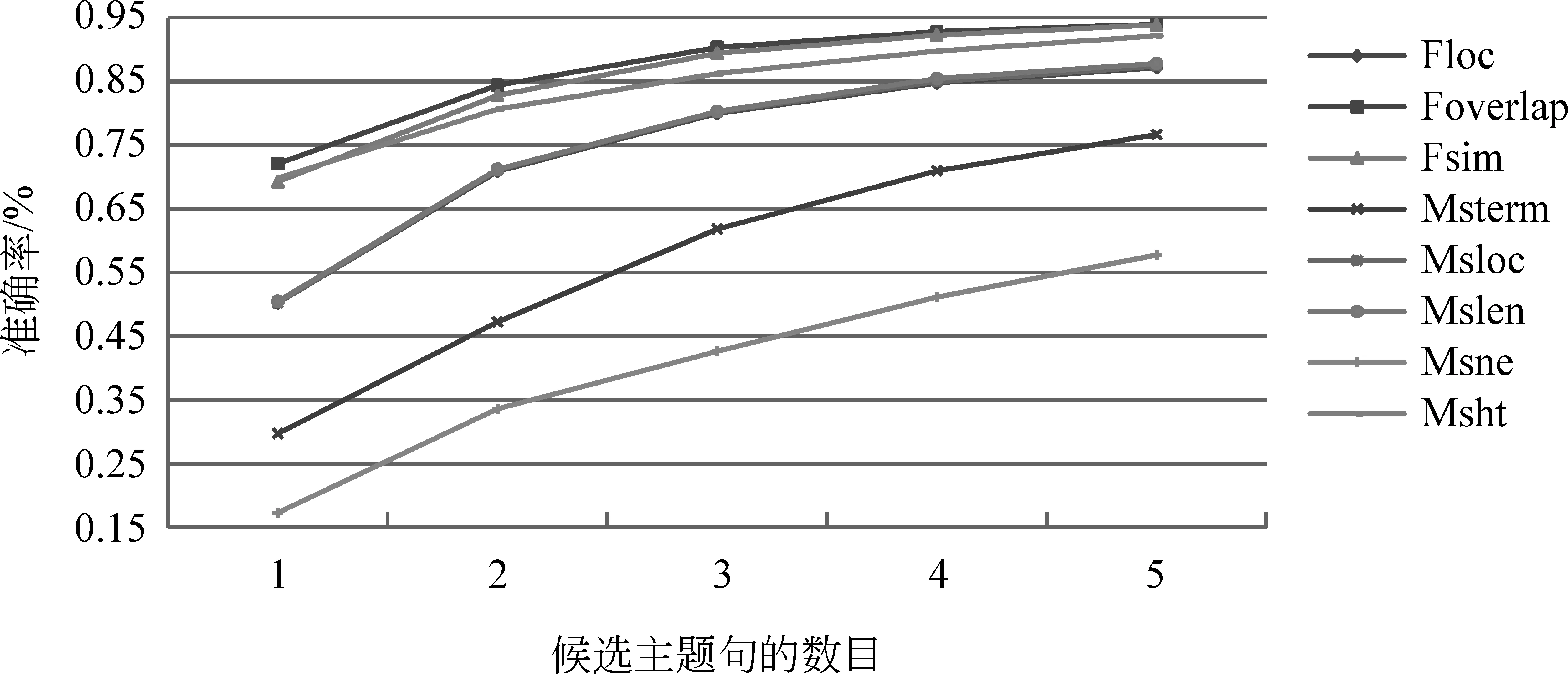
图9 单特征在不同候选主题句时的准确率
由上图可见,本文中所选取的标题句子重合度与标题句子关联度就单特征而言,比其他选取的特征对于主题句的识别具有更好的优越性。
5 总结
本文针对新闻文本的特点,选取了指定的特征,通过特征加权的方式进行新闻的主题句抽取。实验结果表明本文提出的方法与选取的特征对于最终主题句抽取的结果有明显的提升作用。但由于该方法是基于标题能够反映新闻主旨这一前提进行的,若标题不能够很好地体现新闻的价值,如出现标题党问题[17]的情况,本文的方法则不能进行很好的处理。下一步工作是针对这种问题进行分析处理,将其与现有的主题句模型进行融合,以使抽取的主题句更加精准与完善。
[1] Ogura Y, Kobayashi I. Text Classification based on the Latent Topics of Important Sentences extracted by the PageRank Algorithm[C]//Proceedings of the ACL student research workshop, 2013: 46-51.
[2] Jung W, Ko Y, Seo J, et al. Automatic text summarization using two-step sentence extraction[C]//Proceedings of the asia information retrieval symposium, 2004: 71-81.
[3] Zuo J, Wang M, Wan J, et al. Information Retrieval Model Combining Sentence Level Retrieval[C]//Proceedings of the international conference on asian language processing. IEEE, 2013:37-40.
[4] You J, ZhangY, Tong Y. An Approach to Sentiment Analysis for Chinese News Text Based on Topic Sentences Extraction[C]//Proceedings of the international journal of knowledge and language processing, 2014:20-31.
[5] 王力, 李培峰, 朱巧明. 一种基于LDA模型的主题句抽取方法[J]. 计算机工程与应用, 2013, (2):160-164.[6] 原田, 宗樹, 柳本等. Topic Sentence Extraction from Editorial Articles Based on Sentence Structure and Topic Relevance[J]. システム制御情報学会研究発表講演会講演論文集, 2013, 57.
[7] 张云涛, 龚玲, 王永成. 基于综合方法的文本主题句的自动抽取[J]. 上海交通大学学报, 2006, 40(5):771-774.
[8] 葛斌, 李芳芳, 李阜等. 基于无向图构建策略的主题句抽取[J]. 计算机科学, 2011, 38(5):181-185.
[9] Yeh J, Ke H, Yang W. iSpreadRank: Ranking sentences for extraction-based summarization using feature weight propagation in the sentence similarity network[J]. Expert Systems with Applications, 2008, 35(3):1451-1462.
[10] Wang C, Zhang M, Ru L, et al. An Automatic Online News Topic Keyphrase Extraction System[C]//Proceedings of the IEEE/WIC/ACM international conference on Web intelligence and intelligent agent technology. IEEE Computer Society, 2008:214-219.
[11] Yin Z H, Wang Y C, Cai W, et al. Extracting subject from internet news by string match[J]. Journal of Software, 2002,13(2):159-167.
[12] Kastner I, Monz C. Automatic single-document key fact extraction from newswire articles[C]//Proceedings of the conference of the european chapter of the association for computational linguistics. Association for Computational Linguistics, 2009:415-423.
[13] 王伟, 赵东岩, 赵伟. 中文新闻关键事件的主题句识别[J]. 北京大学学报:自然科学版, 2011,47(5):789-796.
[14] 张彦荣. 试论新闻标题的制作技巧[J]. 青海师范大学学报:哲学社会科学版, 2011, (4):147-149.
[15] Farhady H. Location of the Topic Sentence, Level of Language Proficiency, and Reading Comprehension[J]. Iranian Efl Journal, 1999:308-318.
[16] Dorr, Bonnie, Zajic, et al. Hedge Trimmer: a parse-and-trim approach to headline generation[C]//Proceedings of the north American Chapter of the Association for Computational Linguistics, 2003: 1-8.
[17] Deng X. Cultural Interpretation of Online News Title Party[J]. Journal of Guangzhou Open University, 2012:71-79.

万国(1990—),硕士研究生,主要研究领域为信息检索。
E-mail: wanguo_sau@163.com

张桂平(1962—),博士,教授,主要研究领域为机器翻译,知识管理。
E-mail: zgp@gesoft.com

白宇(1982—),博士研究生,讲师,主要研究领域为信息检索。
E-mail: baiyu@sau.edu.cn
NewsTopicSentenceExtractionviaWeightedFeatures
WAN Guo, ZHANG Guiping, BAI Yu, ZHU Yaohui
(Knowledge Engineering Research Center, Shenyang Aerospace University, Shenyang, Liaoning 110136, China)
A topic sentence extraction method for news text is proposed. Firstly, the location feature is derived from the distribution of news topic sentence in the text. Then, the overlap ratio between a sentence and the title calculated owing to the interrelation of the news title with the theme. To best estimate the relevancy between the title and the candidate topic sentence, a maximum matching based on weighted bipartite graph is applied. Finally, the topic sentence is selected according to the sentence rank score. The experimental results show that the proposed method reaches 75.9% in P@1, and 92.4% in P@3.
feature weighted; overlap ratio; relevancy degree; weighted bipartite graph
1003-0077(2017)05-0120-07
TP391
A
2015-11-03定稿日期2016-03-20
沈阳省自然科学基金(20170540696);沈阳市科技计划项目(17-231-1-82)
猜你喜欢
选煤技术(2022年2期)2022-06-06
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
中国交通信息化(2018年5期)2018-08-21
喜剧世界(2016年9期)2016-08-24
