
齐普夫定律对朝鲜语适用性的测定
2017-11-27 08:58崔荣一
中文信息学报 2017年5期
崔荣一,赵 雪
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉 133000)
齐普夫定律对朝鲜语适用性的测定
崔荣一,赵 雪
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉 133000)
该文目的在于验证齐普夫定律对朝鲜语的适用性。首先统计了朝鲜语大规模语料中的文字及字母两种语言单位的频率分布,然后利用最小二乘法对文字频率分布曲线进行了拟合,最后计算了文字字频齐普夫定律的参数估计值。实验结果表明,朝鲜语的文字和字母的频率与频级关系都近似符合齐普夫定律,验证了齐普夫定律对朝鲜语的适用性,这对朝鲜语的信息处理与研究具有重要的现实意义。
朝鲜语信息处理;齐普夫定律;文字频率;最小二乘法
1 引言
齐普夫定律是描述词汇分布规律的重要定律之一,它表达了人们在使用语言进行交流时所遵从的省力法则: 讲话的人和听话的人都想达到省力的平衡,说话人只想使用少量的常用词进行交流,听话的人希望使用没有歧义的、形式和意义之间完全一一对应的多样化的词来理解。齐普夫定律指出人们使用的语言中存在着少量的高频词和大量的低频词。
全世界使用朝鲜语(韩语)的人口约有8 000万人,是使用人数位居世界第12位的语言[1-2]。朝鲜语是中国朝鲜族和朝鲜半岛的主要交流语言,在中朝韩三国之间信息传播和社会、文化、经济等建设与发展中起着重要的作用。因此,采用科学方法研究朝鲜语语言文字对我国朝鲜族文明的发展及国际间朝鲜语信息交流都具有重要意义。
本文目的在于考察齐普夫定律对朝鲜语的适用性问题。为此收集整理朝鲜语文本语料并统计获得了文字和字母的分布规律,以此为据考察朝鲜语的字母和文字的分布是否符合齐普夫定律,并通过模型参数计算,验证齐普夫定律适用于朝鲜语文本的情况。研究齐普夫定律对朝鲜语的适用性,有益于朝鲜文字的技术性研究,对建立基于统计的朝鲜语语言模型、朝鲜文字的输入输出、文字识别、发音模式等信息化处理具有重要的现实意义。
本文主要内容及结构安排如下: 第二节介绍相关研究工作现状,第三节介绍齐普夫定律的主要内容,第四节介绍齐普夫定律适用于朝鲜语的实验,第五节介绍拟合评价策略,最后对相关工作进行总结和展望。
2 相关研究
近年来,许多学者对齐普夫定律对多语种的适用性进行了深入地分析研究。Alexander Gelbukh和Grigori Sidorov以英语和俄语为例,验证过齐普夫定律对它们的适用性,对39篇文本中的250万个英文词汇和200万个俄语词汇进行统计分析,计算出齐普夫定律中的α参数值分别为0.970.06和0.890.07[3]。
在中文文本方面,文献[4]对现代汉语计算语言模型中的语言单位的频率和频级关系进行了较为详细地探讨,发现现代汉语中的字、词、二元对等语言单位的频率和频级之间的关系近似遵循齐普夫定律,反映了不同层次的汉语语言单位对齐普夫定律的普遍适应性。文献[5]在汉字字频分布方面做了更为细致的研究,并指出使用齐普夫定律描述汉字字频分布会产生诸如累计频率部分失真等问题,最后用齐普夫定律描述了汉字字频分布的尾部,并验证其属于较好的拟合情况。
在日文方面,Kip Turner对从利兹大学获得的日语大规模文本语料进行词频统计与分析,得到日语的口语比书面语更符合齐普夫定律的结论[6]。在藏文文本方面,王维兰统计分析了藏文语言单位频率和频级的关系,证实了现代藏文在字丁、音节等语言单位上,其频率和频级关系也近似符合于齐普夫定律[7]。在印第安语系方面,B D Jayaram基于印度的涵盖四种不同内容、不同语言的语料库,分析研究了文字频率和频级分布,通过拟合得出其中三种语言的词频符合齐普夫定律的结论[8]。
S W Choi研究了朝鲜语文本中字词符合齐普夫规律的情况,并与英文和法文情况进行了对比,发现幂指数参数依赖于语种而不依赖于语料类型和规模[9]。此研究工作并未考察朝鲜文字母的统计分布规律,而且语料仅限于韩国文档,影响了其结果的广泛性。
3 齐普夫定律
齐普夫定律是20世纪40年代由美国哈佛大学语言学家Zipf发现的,是反映英文单词词频分布的经验规律,描述了词频和词级间存在的联系,揭示了语言学中普遍存在的统计规律。根据齐普夫定律,语言中的常用高频词数量较少,低频词的数量很大。该定律被广泛地应用于多个领域,如文献计量学、文本特征选择、词典编撰、机器翻译和关键词抽取等。
对于一个有K个词组成的总长度为L的语料库,若将词语出现的频率(即词频)记作pr,将该词的词频排位(即频级)记为r,则齐普夫定律可表示为式(1)。
其中C为一个大于零的常数,因此式(1)表明某个词汇出现的频率和频级的乘积。这条定律说明,人们一般偏好比较常用的词汇,而不是生僻的词汇。若将pr和r的关系在双对数坐标系中表示,所绘制出的曲线几乎为一条直线,并且斜率近似为-1。为了准确求解这一斜率,齐普夫定律还可以推广为式(2)。
其中α为待定常数,r为频级:r=1,2,…,n。对式(2)两边取对数后整理得到式(3)。
在双对数坐标系下,α即为直线的斜率,logC是直线在y轴上的截距,如图1所示。
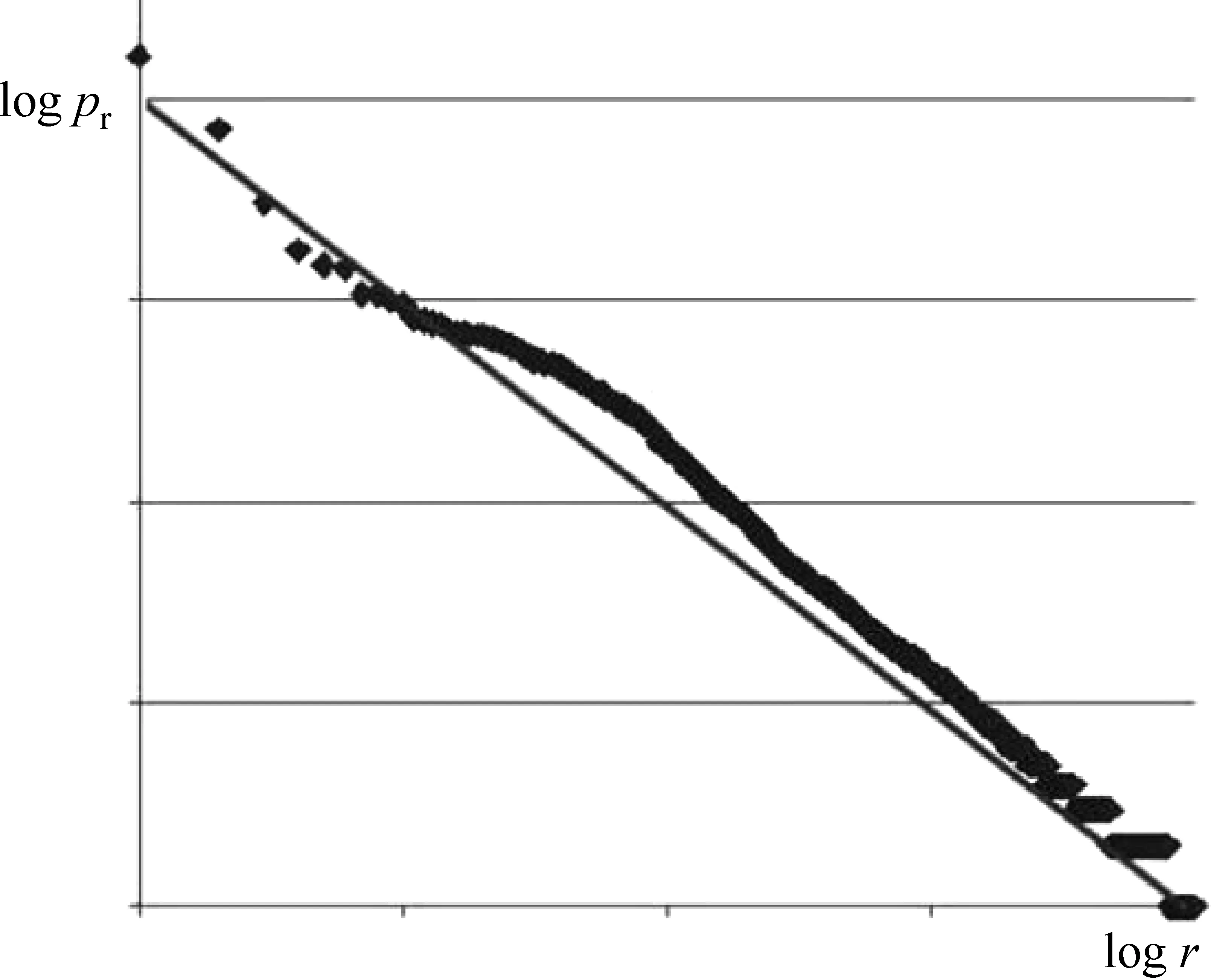
图1 齐普夫定律曲线
在不同语种的实验中,经验数据表明α≈1。不同语言之间的α表现得十分相似,但并不完全一样,比如英文文本表现得非常符合,但是中文和其他语种的文本并不严格符合。
4 齐普夫定律对朝鲜语的适用性
本文利用网页爬取技术获取了两千万字规模的朝鲜语文本语料,其中包含韩国和中国的朝鲜语文本,涵盖的内容包括学术、法律、经济、体育和文学等领域。在所获文本语料上统计朝鲜文字和字母的频率,并分析其分布规律,最后研究了朝鲜文字的频率和频级之间的关系,以验证齐普夫定律对朝鲜语的适用性。
4.1 朝鲜文字分布特征
对整体语料进行文字统计分析,得出以下研究结论。
(1) 高频区。由频级为1到20的文字组成,20个文字的累积字频为27.39 %。根据韩国KSC—5601标准字符集,可以认为现代常用的朝鲜文字有2 350个[9],因此高频区数量占整体文字数量的20/2 350≃0.85%。可以看出,朝鲜文字的频率分布极不均匀,常用的朝鲜文字往往是以助词、前缀、后缀等形式出现的,这是高频区文字数量小但累计频率却相对较高的根本原因。

(2) 中频区。由频级为21到320之间的文字组成,累积字频为35.27 %。高频部分和中频部分词级为1到320之间的累积字频分布为27.39%+35.27%=62.66%。中频部分的文字频率与频级分布对于整体文字频率分布来讲具有普遍的代表意义。
(3) 低频区。由所有频级大于321的文字组成,其累积字频为38.34%,而占常用文字的(2 350-320)/2 350=86.38%。虽然这部分文字的累积频率小,但文字数量占整个常用文字的比例却很大。由此看出,占整体文字数量比例大的文字在语料中出现的次数少,表达含义也十分有限,在宏观上符合“80-20”原则。
文献[5]指出,齐普夫定律在描述低频词的分布上存在一定的缺陷,所以需对字频分布曲线的中间部分及对应的中频区进行拟合,并计算参数的估计值。
4.2 朝鲜语字母分布特征
朝鲜语文字由初声、中声、终声三个类别的字母组成。对朝鲜语语料中的字母按照类别进行统计,并在双对数坐标系下绘制朝鲜语字母分布曲线,结果如图2所示。
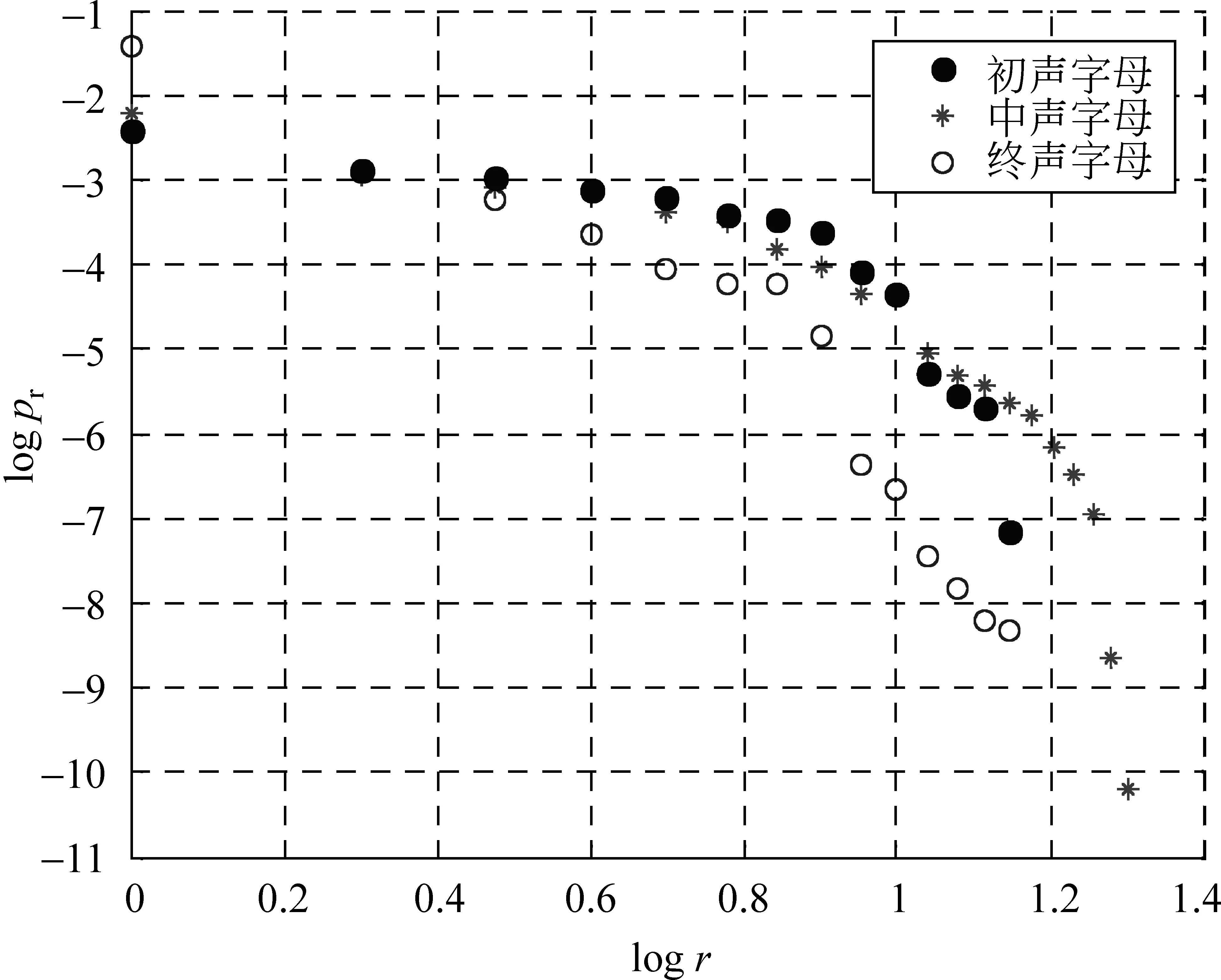
图2 朝鲜语初声、中声、终声字母分布曲线
该图反映了三种不同类别字母的频率与频级关系,图中横坐标为频级的对数值,纵坐标为频率的对数值。不同类别字母之间的频率与频级关系存在着一定的差异。根据曲线的走势可以看出,初声、中声、终声类别字母的频率与频级之间呈现负相关关系,即随着频级的增加,频率逐渐减少。该曲线的走势与齐普夫曲线的走势大致相同,所以我们推断朝鲜语字母的频率、频级关系近似遵从齐普夫定律。
4.3 朝鲜文字频率与频级关系
按照出现频率由高到底的顺序赋予不同文字由小到大递增的频级,并在双对数坐标系下绘制出朝鲜语文字频率分布曲线如图3所示。

图3 文字频率分布
图3中,横坐标为文字频级的对数值,纵坐标为文字频率的对数值。可以观察出频率与频级呈现负相关关系,即随着文字频级的增大,文字的频率逐渐降低,这与齐普夫定律对于英文词频分布的描述相符合。由此我们推断,齐普夫定律同样也适用于朝鲜文字字频分布。为了验证我们的推断,用最小二乘法对文字频率分布曲线进行拟合,以获得文字频率与频级之间关系的最佳函数拟合,并计算齐普夫定律的参数估计值。
齐普夫分布曲线头部和尾部一般偏离整个拟合曲线。经过字频统计发现,字频分布的中间部分分布更为平稳,对于真实的字频分布更具有代表性。因此,利用最小二乘法对字频分布曲线的中部进行拟合,最后获得齐普夫定律中参数α的估计值。图4所示是文字频率分布曲线的分段拟合直线图,拟合后的直线能够较好地贴合于字频分布曲线,说明最小二乘法能够较好地对字频分布曲线进行拟合。

图4 文字频率分布曲线的分段拟合直线
计算拟合直线的斜率即为齐普夫定律中参数α的估计值,表1是部分实验数据。
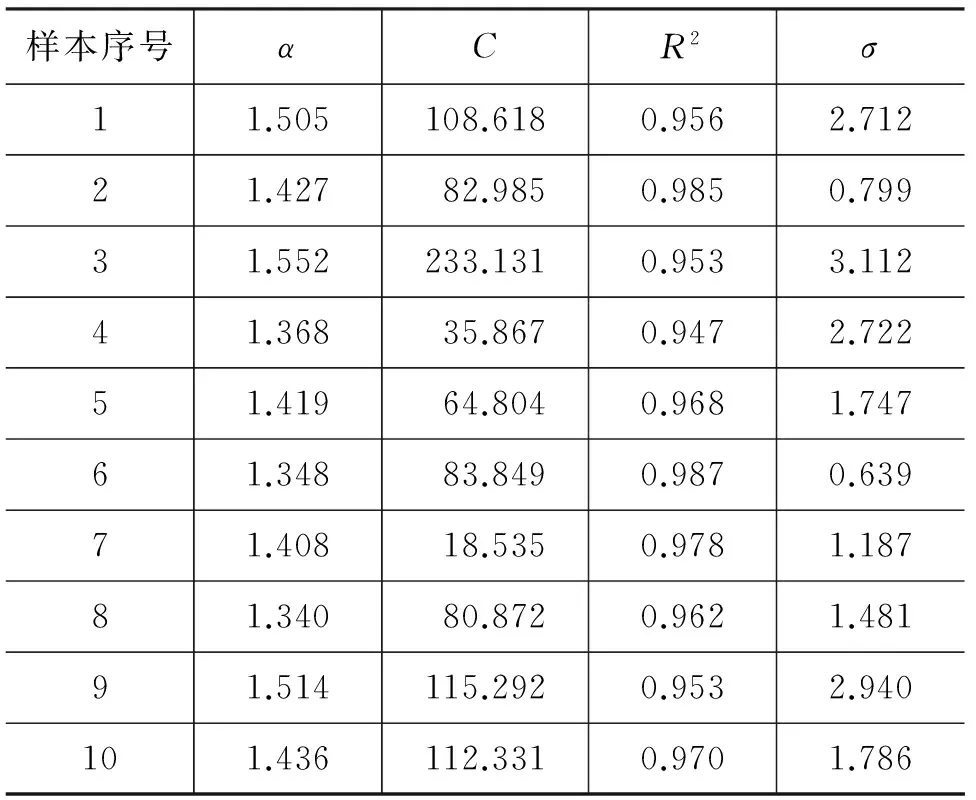
表1 部分实验数据
在以上十次实验结果中,参数α的值在1.433 30.09之间。计算整体实验中的全部数据,得到参数α的平均值约为1.453,参数C值的分布更加类似于某种概率分布,受样本具体情况的影响,这里不做具体讨论。R2为复相关系数,是用以评价拟合优度的统计指标;σ是剩余标准差,即残差,用来衡量拟合后公式的精确度。
5 拟合策略评价
最小二乘法是一种常用的数据处理方法。从n对观测数(x1,y1),(x2,y2),…,(xn,yn)确定出x与y之间对应关系y=f(x)的一种最佳估计,使得观测值与估计值之差(即偏差)的平方和最小[10]。该方法能尽量消除偶然误差的影响,可求出最可靠、最可能出现的结果。
一般情况下,采用复相关系数R2和剩余标准差σ相结合的策略来评价最小二乘法拟合的情况。复相关系数满足0lt;R2lt;1,R2越接近于1,表明对样本数据拟合程度越高,拟合越有意义。通常若R2在0.8以上,则认为拟合优度较高。本文中R2是文字频率与频级之间的相关关系r的平方。然而,单纯利用复相关系数不能说明拟合得到的经验公式的精确度,需要结合剩余标准差σ 一起评价拟合的程度。
剩余标准差 σ 用来检测经验公式的可靠程度,其表现形式为式(4)。
式(4)中S剩表示剩余平方和,f剩表示自由度。剩余标准差σ可以看作自变量固定时,衡量所有随机因素对因变量一次观测的平均变差大小。剩余标准差σ 越接近于0,拟合的可靠程度就越高。在实际问题中,σ往往较大。如表1中十次实验数据,所有的复相关关系R2都大于0.8,且σ的最小值可达0.639,说明拟合效果良好。
6 结论
本文通过统计朝鲜语语料获得了文字和字母的分布规律,观察和分析发现朝鲜语字母和文字的频率-频级关系都遵从齐普夫定律。本文利用最小二乘法对文字分布曲线进行拟合,计算了齐普夫定律参数α的估计值,采用复相关系数R2和剩余标准差σ综合评价拟合结果,验证了齐普夫定律对朝鲜语语种的适用性。
鉴于中、朝、韩三国朝鲜民族使用文字的规范和习惯不完全相同,分别对三国的语料进行分析,揭示朝鲜语在中、朝、韩三国使用的统计特征和差异,是下一步待深入研究的内容。
[1] Ostler N. 语言帝国:世界语言史[M]. 章璐, 梵非, 蒋哲杰,等,译. 上海: 上海人民出版社, 2011: 476.
[2] 朴太秀. 朝鲜民族的语言文字[J].黑龙江民族丛刊,1998(4):99-100.
[3] Gelbukh A, Sidorov G. Zipf and heaps vaws’ coefficients depend on language[C]//International conference on intelligent text processing and computational linguistics, Mexico City, Mexico, 2001: 332-335.
[4] 关毅,王晓龙,张凯. 现代汉语计算语言模型中语言单位的频度-频级关系[J].中文信息学报,1999,13(2):8-15.
[5] 游荣彦. Zipf定律与汉字字频分布[J].中文信息学报,2000,14(3):60-65.
[6] Turner K. Visualizing Zipf’s law in Japanese [EB/OL]. http://classes.soe.ucsc.edu/cmps161/Winter12/projects/katurner/proj/paper/paper.pdf.
[7] 王维兰. 现代藏语语言单位频率和频级关系的统计分析[J]. 科学技术与工程, 2004,4(5):413-417.
[8] Jayaram B D, Vidya M N. Zipf’s law for Indian languages[J]. Journal of Quantitative Linguistics, 2008,15(4):293-315.
[9] Choi S W. Some statistical properties and Zipf’s law in Korean text corpus[J]. Journal of Quantitative Linguistics, 2000, 7(1): 19-30.
[10] 田垅, 刘宗田. 最小二乘法分段直线拟合[J]. 计算机科学, 2012, 39(6):482-483.

崔荣一(1962—),通信作者,博士,教授,主要研究领域为智能计算、模式识别、机器学习、自然语言处理。
E-mail: cuirongyi@ybu.edu.cn

赵雪(1991—),工程硕士,主要研究领域为文本信息处理。
E-mail: 383169216@qq.com
OnZipf’sLawinKoreanLanguage
CUI Rongyi, ZHAO Xue
(Intelligent Information Processing Lab., Department of Computer Science and Technology, Yanbian University, Yanji, Jilin 133000, China)
This paper aims to verify the Zipf’s law in Korean language. Firstly, the statistical distribution is investigated for two linguistic units, words and alphabets, on a massive Korean text corpus. Then the least square method is adopted to simulate the curve of rank-frequency distribution of words in Korean text. Finally, the estimation values of the parameter of Zipf’s law is calculated. The experimental results show that the relationship between frequency and rank of both linguistic units falls into the Zipf’s law in Korean language.
information processing of Korean language; Zipf’s law; word frequency; least square method
1003-0077(2017)05-0081-04
TP391
A
2015-03-16定稿日期2016-04-23
国家语委“十二五”科研规划项目(YB125-178);吉林省科技发展计划项目(20140101186JC)
猜你喜欢
韩国语教学与研究(2022年1期)2022-09-19
通信技术(2021年12期)2022-01-25
韩国语教学与研究(2021年1期)2021-07-29
汉字汉语研究(2021年1期)2021-06-11
延边大学学报(社会科学版)(2020年2期)2020-03-25
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
儿童故事画报·智力大王(2019年5期)2019-07-14
计算机应用与软件(2018年9期)2018-09-26
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
