
一种面向多次发布的隐私保护模型
2017-11-23 02:18:39沈明玉胡学钢王正彬
合肥工业大学学报(自然科学版) 2017年10期
赵 皎, 沈明玉, 胡学钢, 王正彬
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
一种面向多次发布的隐私保护模型
赵 皎, 沈明玉, 胡学钢, 王正彬
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
文章提出了一种面向多次发布的数据库隐私保护模型,通过等价类的动态调整来隐藏数据和等价类间的映射关系,降低隐私泄露的风险。利用伪数据调节数据的多样性以满足匿名规则的要求,伪数据亦可作为噪声数据增加攻击者的分析难度,提高隐私保护强度。在UCI数据库上进行的仿真实验结果表明,该模型能够有效减少因多次发布带来的隐私泄露。
隐私保护;匿名规则;多次发布;隐私泄露;限制发布
0 引 言
互联网大数据背景下利用数据发布提供信息服务的同时,也带来个体隐私泄露的风险。数据库隐私保护技术已经成为信息安全领域的研究热点。
限制发布是常用的3种数据库隐私保护技术之一,采用数据的匿名化来实现隐私保护[1-7]。近年来,国内外学者围绕数据匿名化已做了大量研究工作。文献[5]提出了一种(l,α)-多样性模型,要求一个等价类中敏感值的权重和不小于α,以避免高敏感度的敏感值出现在同一等价类中,从而实现敏感值的均匀分配;文献[7]提出了一种基于敏感属性值语义桶分组的t-closeness隐私模型,该模型根据敏感属性的层次树结构对数据表进行语义相似性桶分组划分,然后采用贪心思想生成满足要求的最小等价类。该模型在减少信息损失的前提下保护敏感信息不被泄露。
以上对匿名化的研究可以有效实现对单次发布数据的隐私保护,但是对多次发布带来的隐私泄露问题的解决仍存在不足。目前国内外学者对面向多次发布的数据库隐私保护问题的研究已取得了一定的成果。文献[8]引入敏感属性树的思想,将敏感属性逐级排列,确保敏感属性多样性,该模型将敏感属性进行泛化处理,增强了敏感信息的保护强度,但是没有考虑到攻击者可能通过分析准标识符与敏感属性间的关联关系而得到某些个体的隐私信息;文献[9]结合局部重编码泛化方法改进匿名算法,提出了一种数据重发布的隐私保护模型,降低发布数据的信息损失,但是该算法的处理复杂度较高;文献[10]首先定义了等价类的相容性,允许一个元组同时存在于2个等价类中,增加了数据的多样性,但这也将增加数据的冗余性,该方法只给出了数据增加时的处理策略,没有给出因多次发布带来的隐私泄露问题的解决方法。
针对上述因多次发布可能存在隐私泄露的问题,本文对面向多次发布的隐私保护模型进行研究,模型中引入了动态等价类及伪数据等技术。
1 技术背景
1.1 数据库隐私保护相关概念
(1) 数据匿名化。数据匿名化是限制发布技术中的一个主要方法,使观察者通过发布的数据难以确定敏感属性和个体之间的关联关系,从而保护个体的隐私信息。数据匿名化一般采用抑制和泛化2种操作实现。抑制即不发布某数据项,泛化即对数据项进行更加概括的描述。
(2) 属性的划分。在隐私保护技术中,数据匿名化技术将数据表中的属性分为标识符、准标识符和敏感属性3类。标识符是指能够直接标识个体身份的属性,如姓名等。准标识符是不能直接标识个体的身份,但是与其他属性链接可以确定个体身份的属性,如年龄、地址等。敏感属性即描述个体隐私信息的属性,如疾病等。
(3) 等价类。数据匿名化需要对元组的准标识符进行泛化处理,使原本精确的值泛化为抽象的范围或者更为概括的表达。经泛化后的数据表中会出现准标识符值相同的元组,将这些准标识符值完全相同的元组归为一个等价类。同一个等价类中的元组除敏感属性外,所有准标识符值完全相同,使得攻击者难以在准标识符上区分这些元组,保护了个体的隐私信息。
1.2 常用的匿名规则
(1)k-anonymity。文献[1]首次提出了k-anonymity匿名规则,若数据表T中任意一个元组在准标识符上至少不能和其他k-1个元组区分,则称该数据表满足k-anonymity匿名规则通过k个不可区分的个体,使攻击者不能判别敏感属性和个体之间的关联关系。k-anonymity的缺陷是没有对敏感属性加以约束,容易受到同质攻击和背景知识攻击。
(2)l-diversity。在k-anonymity的基础上,文献[2]提出了l-diversity匿名规则,要求每个等价类中不同的敏感属性值至少有1个。l-diversity在敏感属性的多样性上加以约束,克服了同质攻击。
(3)t-closeness。文献[3]在k-anonymity和l-diversity的基础上提出了t-closeness匿名规则,该匿名规则要求,所有等价类中敏感属性值的分布尽量接近该属性的全局分布。t-closeness克服了同质攻击和相似攻击。
2 面向多次发布的隐私保护模型
2.1 模型的基本思想
本文提出的面向多次发布的隐私保护模型是对传统隐私保护模型的改进,旨在解决因多次发布带来的隐私泄露问题。伪数据的运用可以使本模型能够有效综合限制发布与数据失真的技术特点,给发布的数据添加噪声,增加隐私信息的分析难度,调节发布数据的多样性,提高隐私性。静态的等价类容易造成更新数据与等价类间映射关系的暴露,本模型引入动态等价类技术,通过等价类的动态调整和维护来隐藏数据与等价类间的映射关系,增强隐私保护强度。
2.2 伪数据
伪数据是一种非真实的数据,在本模型中用于调节数据的多样性和产生噪声数据。伪数据的准标识符值与其等价类的准标识符值相同,根据伪数据的添加目的来确定它的敏感属性的取值。除指定的合法用户外,其他观察者均不能区分伪数据与真实数据,现有的数据库隐私保护模型主要采用伪数据表来对伪数据进行维护。伪数据表是一张用来记录伪数据信息的数据表,表中包括伪数据所在的表名、伪数据的ID等属性。
本文采用伪数据表的动态维护,以确保伪数据信息的真实性和实时性。为了提高伪数据ID的保密性,本模型利用Elgamal数字加密算法对其进行加密处理,将加密后的密文存入伪数据表中。
伪数据的数据多样性调节和数据失真效果增加了攻击者的分析难度,进一步提高了隐私保护强度。以某一等价类为例,见表1、表2所列。

表1 某等价类中的数据
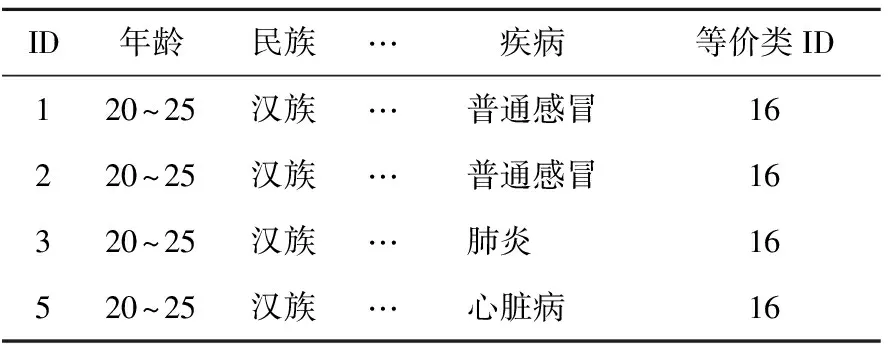
表2 没有添加伪数据的等价类
表1为某一个等价类中的数据,若ID为4的元组被删除,如果不添加伪数据,那么见表2所列。攻击者通过分析2个表之间的差异可以得出被删除元组敏感属性“疾病”的值为“肺炎”,并且获得该元组准标识符值的取值范围,结合已获得的背景知识可能确定该元组对应个体的身份,导致隐私信息泄露。
在本模型中,删除数据时直接将其转换为伪数据,此时表1中ID为4的元组已经为伪数据。伪数据的添加使攻击者不能分析出2次发布的数据之间的差异,从而避免了因多次发布数据间的关联性带来的隐私泄露问题。
2.3 动态等价类
在传统的隐私保护模型中,更新某元组后只相应更新其所在的等价类,不处理其他等价类。数据重发布后,攻击者通过分析多次发布数据间的差异,可以很容易分析得到某些隐私信息。在本模型中,某个等价类调整时也相应调整其他部分等价类,通过等价类的动态调整隐藏更新数据与等价类间的映射关系。
在数据重发布之前,对所有等价类进行维护,完成维护后判断各等价类中是否有元组的更新。若某等价类中插入了新的数据,随机选择其他部分等价类,添加相应的伪数据;若某等价类的准标识符值被修改,随机修改部分等价类的准标识符值,则使攻击者不能准确确定更新数据所在的等价类。
1个简单的等价类更新过程如图1所示。
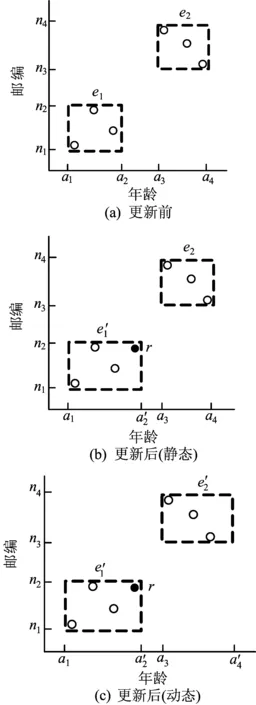
图1 更新前、更新后(静态、动态)的等价类
图1中的数据表有年龄和邮编2个属性;e1和e22个等价类。更新前的数据表添加一个元组r后,若采用静态等价类,则更新后的等价类如图1b所示。攻击者分析图1a、图1b的差异可以很容易地确定添加的元组在等价类e1中,并且可以得出添加的元组r的年龄的值为a2′-a2,元组r的信息遭到泄露。图1c所示为采用动态等价类更新后的结果,向等价类e1中添加一个元组r时,同时调整等价类e2的匿名范围。攻击者分析图1a、图1c间的差异,得到2个等价类均被修改,从而不能确定添加的元组所在的等价类,隐藏了元组r和等价类e1间的映射关系。
3 数据更新及等价类维护的策略
原数据表中有元组更新时,选择相应的处理策略更新等价类,定期对更新后的数据进行重发布。数据重发布前,对所有的等价类进行维护和调整,确保重发布的数据满足规定的匿名规则。
3.1 数据更新时的处理策略
插入数据时,以数据泛化后信息损失最少为原则,选择一个等价类插入数据,修改该等价类准标识符的值;删除数据时,直接将被删除的数据转换为伪数据;修改数据时,首先判断修改后数据的准标识符值是否超出该等价类的最大泛化区间,若没有超出则修改该等价类的准标识符,若超出最大泛化区间则从该等价类中删除该数据,选择一个使其信息损失最少的等价类插入。
3.2 等价类的动态维护
数据多次更新后,可能导致某些等价类中伪数据过多,数据的真实性降低;或者等价类的准标识符匿名范围过大,导致数据的效用性降低。因此需对等价类进行动态维护,维护的方法包括等价类的分解、取消和合并。
3.2.1 分解等价类
(1) 分解条件。1个等价类中真实数据个数大于2k。
(2) 分解方法。删除所有的伪数据,将等价类中真实数据按敏感属性值分组。分别取各个桶中1/2的元组组成一个等价类,另1/2组成1个等价类。
3.2.2 取消等价类
(1) 取消条件。1个等价类中真实数据个数小于k/2或不同敏感属性值个数小于1/2。
(2) 取消方法。删除该等价类中伪数据,将真实数据选择使其信息损失最小的等价类插入。
3.2.3 合并等价类
(1) 合并条件。相邻的2个等价类均满足取消等价类的条件。
(2) 合并方法。删除2个等价类中的伪数据,合并2个等价类中的真实数据,并修改等价类准标识符的值。
在数据重发布之前,首先判断各个等价类是否需要维护,若满足上述等价类的分解、取消或合并的条件,对等价类进行相应的维护。在完成等价类的维护后,向不满足匿名要求的等价类中添加伪数据,确保所有等价类均已满足规定的匿名规则后重新发布数据。
4 实验与分析
本实验采用UCI机器学习数据库中的Adult数据集,该数据集总共包含32 561行数据,删除包含缺失值的数据剩余30 725行数据。选取其中7个属性进行实验,将marital-status作为敏感属性,{age,workclass,education,education-num,race,sex}作为准标识符。
本实验从隐私性和多样性2个方面将本模型与文献[7,9]提出的方法进行对比分析。文献[7]是对t-closeness隐私保护模型的改进,主要是对单次发布的数据进行隐私保护。文献[9]对局部重编码泛化算法进行了改进,旨在解决多次发布带来的隐私泄露问题。
4.1 隐私性分析
本实验通过计算隐私信息泄露的比例来分析隐私保护的强度。实验方法如下:① 从Adult数据集选取20 000行数据进行匿名泛化后首次发布;② 分别对已发布的数据进行插入、删除和修改处理,涉及的数据均为200行;③ 数据重新发布;④ 对多次发布的数据进行人工分析,计算隐私泄露的比例,结果如图2所示。
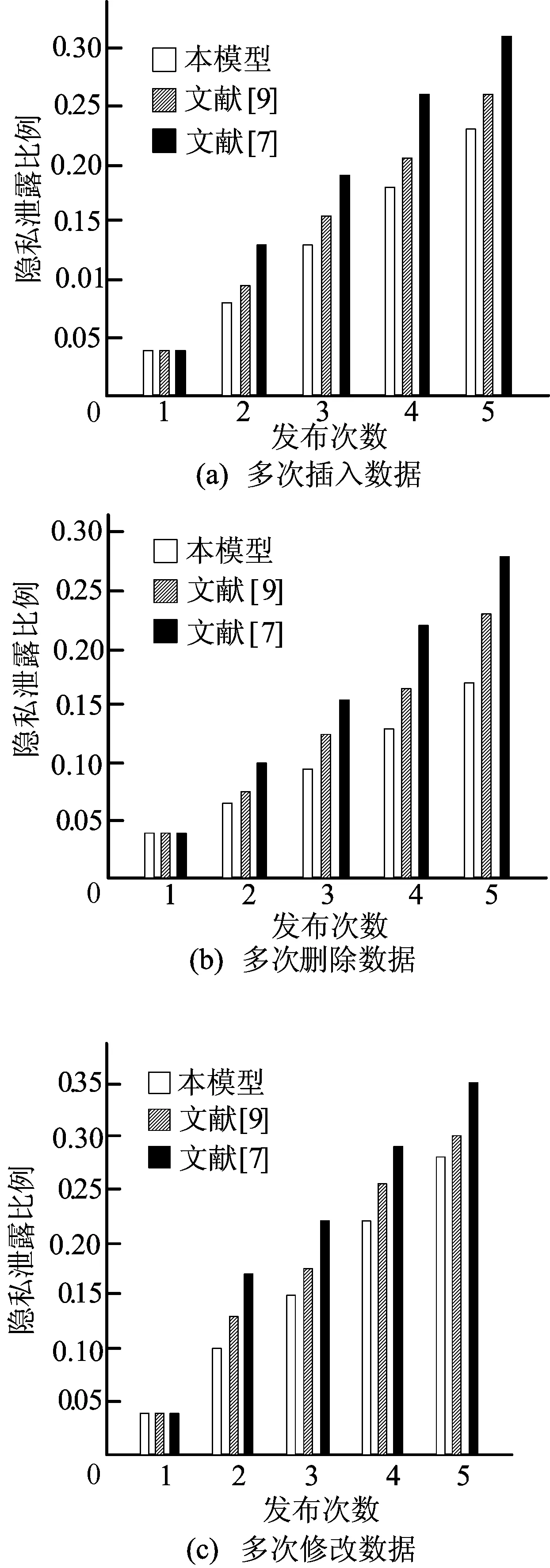
图2 多次插入数据、删除数据及修改数据后隐私信息被泄露比例
从图2可以看出,由于文献[7]没有给出针对多次发布隐私泄露问题的处理策略,随着发布次数的增多,隐私泄露比例迅速增大。文献[9]虽然针对多次发布隐私泄露问题给出了处理策略,但是其采用的是静态等价类,多次发布后数据间的差异会明显增多,隐私泄露也会明显增多。本模型中动态等价类技术可以有效隐藏数据与等价类间的映射关系,增加隐私信息的分析难度;伪数据作为噪声数据给攻击者增加干扰,有效减少多次发布带来的隐私泄露比例。
4.2 多样性分析
发布数据的多样性越高,即等价类中数据的相异程度越高,攻击者分析隐私信息的难度就越大,数据的隐私性越强。对于多样性的度量,实验参考了文献[11]给出的数据表平均多样性的度量公式,即
(1)
D(Ε)=distinct(Ε)+ωH(Ε)
(2)
其中,distinct(E)为等价类E中敏感属性值的种类个数;H(E)为等价类E中敏感值的相异程度;ω为发布者自定义的权值;D(E)为等价类E多样性的大小(下文均简称多样性);DOT(T)为数据表T的多样性。l的值表示等价类中敏感属性值的种类个数,l越大,distinct(E)的值越大,数据表的平均多样性就越大。利用(1)式、(2)式计算l取不同值时使用以上3种方法发布数据的多样性,计算结果如图3所示。

图3 不同l值下数据表多样性的比较
由图3可以看出,随着l的增大发布数据的多样性均会逐渐增大。在l相同的情况下,由于文献[7,9]中的方法没有采用伪数据,发布数据的多样性比本模型中发布数据的多样性低。在本模型中,数据更新后会添加相应的伪数据来调节发布数据的多样性。
5 结 论
为解决多次发布带来的隐私泄露问题,本文基于限制发布技术提出了一个面向多次发布的数据库隐私保护模型。模型引入了动态等价类和伪数据等技术,并对数据更新给出相应的处理策略。伪数据不仅调节数据多样性,还作为噪声数据给攻击者增加干扰。等价类的动态调整和维护有效隐藏了数据与等价类间的映射关系,有效降低了多次发布带来的隐私泄露风险。后续将针对处理开销及信息损失较大等问题进行进一步研究。
[1] SWEENEY L.Achievingk-anonymity privacy protection using generalization and suppression[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):571-588.
[2] MACHANAVAJJHALA A,KIFER D,GEHRKE J,et al.l-diversity:privacy beyondk-anonymity[J].Acm Transactions on Knowledge Discovery from Data,2007,1(1):24.
[3] LI N,LI T,VENKATASUBRAMANIAN S.t-closeness:privacy beyondk-anonymity andl-diversity[C]//IEEE 23rd International Conference on.Data Engineering,2007.ICDE 2007.[S.l.]:IEEE,2007:106-115.
[4] 周水庚,李丰,陶宇飞,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-861.
[5] SUN Xiaoxun,LI Min,WANG Hua.A family of enhanced (L,alpha)-diversity models for privacy preserving data publishing.[J].Future Generation Computer Systems the International Journal of Grid Computing Theory Methods & Applications,2011,27(3):348-356.
[6] LIU J,WANG K.On optimal anonymization forl-diversity[C]//2010 IEEE 26th International Conference on.Data Engineering (ICDE).[S.l.]:IEEE,2010:213-224.
[7] 张健沛,谢静,杨静,等.基于敏感属性值语义桶分组的t-closeness隐私模型[J].计算机研究与发展,2014,51(1):126-137.
[8] ZHAO Y,WANG J,ZHU Q S,et al.A novel privacy preserving model for datasets re-publication[J].Advanced Materials Research,2010,108/109/110/111:1433-1438.
[9] 武毅,王丹,蒋宗礼.基于事务型k-anonymity的动态集值属性数据重发布隐私保护方法[J].计算机研究与发展,2013,50(增刊1):248-256.
[10] BYUN J W,SOHN Y,BERTINO E,et al.Secure anonymization for incremental datasets[J].Third Vldb Workshop on Secure Data Management,2006:48-63.
[11] 韩建民,于娟,虞慧群,等.面向数值型敏感属性的分级l-多样性模型[J].计算机研究与发展,2011,48(1):147-158.
Aprivacyprotectionmodelfordatare-publication
ZHAO Jiao, SHEN Mingyu, HU Xuegang, WANG Zhengbin
(School of Computer and Information, Hefei University of Technology, Hefei 230009, China)
A privacy protection model for data re-publication is put forward. The mapping relations between data and equivalent classes are hidden by adjusting equivalence classes dynamically, which can reduce the risk of privacy leakage. Pseudo data is used to adjust data diversity to meet the diversity requirement of anonymous rules, and to increase the difficulty of analysis for attackers as noise data. The results of the experiments on the UCI database show that under the premise of improving the diversity of the released data, this model can effectively reduce the privacy disclosure risks caused by the multiple releases.
privacy protection; anonymous rule; data re-publication; privacy disclosure; limited release
2016-03-03;
2016-04-20
国家自然科学基金资助项目(61273292)
赵 皎(1990-),女,河北石家庄人,合肥工业大学硕士生; 沈明玉(1962-),男,江苏兴化人,博士,合肥工业大学副教授,硕士生导师,通讯作者,E-mail:shenmy@126.com; 胡学钢(1961-),男,安徽当涂人,博士,合肥工业大学教授,博士生导师.
10.3969/j.issn.1003-5060.2017.10.008
TP393
A
1003-5060(2017)10-1338-05
(责任编辑 张 镅)
猜你喜欢
中国设备工程(2023年16期)2023-08-29 07:10:58
计算机应用(2022年8期)2022-08-24 06:30:36
电脑报(2021年14期)2021-06-28 10:46:22
党员生活(2020年2期)2020-04-17 09:56:30
计算机系统应用(2020年8期)2020-03-22 07:41:52
计算机与生活(2019年5期)2019-07-18 01:08:56
铁道通信信号(2018年10期)2018-12-06 09:34:56
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
中国美术馆(2016年6期)2017-01-19 08:44:24
中国石油企业(2014年4期)2014-11-30 06:13:06
