
基于加权混合特征的话者识别算法
2017-11-23 08:22:29,,
浙江工业大学学报 2017年6期
,,
(浙江工业大学 信息工程学院,浙江 杭州 310023)
基于加权混合特征的话者识别算法
徐志江,赵梦娜,卢为党
(浙江工业大学 信息工程学院,浙江 杭州 310023)
用多窗谱估计和伽马通滤波改进经典的梅尔倒谱特征(MFCC)的识别性能,并与delta特征相结合,提出了一种基于加权参数设置策略的混合特征话者识别算法.该算法解决了梅尔倒谱系数方差过大、听觉特征不明显及话者识别算法特征单一的问题.仿真结果表明:与MFCC和线性预测的提取方法相比,该算法鲁棒性能更优,对不同噪声环境的适应性更好.
多窗谱估计;伽马通滤波器组;加权函数;加权混合特征
说话人特征提取算法从话者语音中提取能够表征话者个性特征的参数,是话者识别算法中的核心技术之一.目前,在话者识别算法中应用最为广泛的特征参数有梅尔倒谱系数(Mel frequency cepstral coefficient MFCC),线性预测倒谱系数(Linear prediction cepstrum coefficient LPCC),基音周期等[1].梅尔倒谱系数是基于人耳听觉特征的特征参数,具有较好的区分度,是当前话者识别的主流参数[2].实验表明人耳具有特别优异的语音识别性能和抗噪性能.研究结果表明:相对于Mel滤波器组,伽马通滤波器组可以更好地模拟人耳耳蜗听觉模型.因此,笔者采用伽马通滤波器组优化Mel倒谱提取算法.进一步针对MFCC频谱具有高方差,且有时延性的缺点[3],摒弃传统谱估计,利用多窗谱估计来提取基于伽马通滤波器组和多窗谱估计的改进MFCC.改进的梅尔倒谱参数具有实时性,且其谱估计值具有低方差性,相对于利用特征弯折、RASTA滤波等算法提取的MFCC,具有更好的鲁棒性.同时,新型MFCC特征也具有缺点,其只反映语音静态特性,缺失动态信息[4],因此笔者提取该特征的二次特征即Delta特征加入特征向量.
在对经典梅尔倒谱系数进行深入研究后,发现该特征参数的各个分量对语音的表征能力不同.进一步针对改进的基于伽马通滤波器组和多窗谱估计的MFCC的参数特性,分析特征的各维系数对语音表征的贡献度,提出一种基于加权函数的改进Mel倒谱混合特征参数.
1 文献算法概要
1.1 经典MFCC提取
人耳听到的声音高低与声音本身的频率并不是线性成正比关系[5].一般使用Mel刻度来描述不同频率的声音对听觉系统的作用.梅尔频率与声音频率的公式[6]为
Mel(f)=2 595ln(1+f/700)
(1)
MFCC的提取流程图如图1所示.
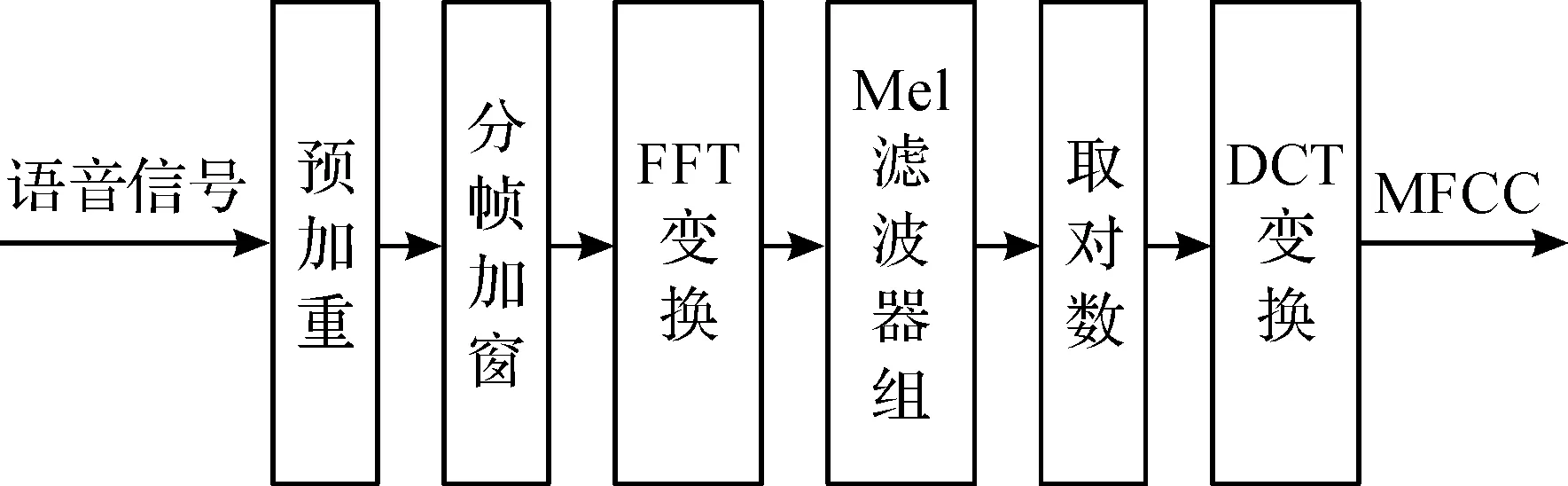
图1 MFCC提取过程Fig.1 MFCC extraction process
1.2 多窗谱估计
多窗口谱估计是一种采用不同权值的多个窗函数,用它们频域的平均值来获得语音信号的频谱估计的算法.设X=[x(0),…,x(N-1)]为一帧有N个采样点的语音信号,多窗谱估计[7]的定义为
(2)
式中:K为正交窗函数的个数;ωj(t)为正交窗函数;λ(j)为第j个窗函数对应的权值;M为语音帧个数.
1.3 伽马通滤波器
伽马通滤波器组是一个标准的耳蜗听觉滤波器,其滤波器组的冲激响应的典型模式[8]为
gk(t)=AtT-1exp(-2πbkt)cos(2πfkt+φk)t≥0,1≤k≤T
(3)
式中:A为滤波器增益;T为滤波器阶数;fk为中心频率;φk为相位;bk为衰减因子,其决定了滤波器冲激响应的衰减速度,并与相应滤波器的带宽有关,bk=1.019ERB(fk).
ERB(fk)为等效矩形带宽,即
(4)
这里设定T=24,即由24个滤波器叠加成伽马通滤波器组来实现耳蜗滤波器模型.
2 加权改进特征提取
2.1MFCC缺陷分析
频谱的估计是MFCC提取过程中的重要步骤.然而,经典的谱估计一般采用单窗对语音进行加窗,这使得到的频谱具有高方差值,引起巨大的MFCC偏差,降低识别的准确性.笔者采用多窗谱估计来解决该问题.此外,MFCC是基于人耳听觉特性的特征,具有良好的区分性.但梅尔滤波器组却不能很好地模拟人耳耳蜗的听觉模型,从而严重影响到梅尔倒谱特征的识别性能.因此,采用伽马通滤波器替代梅尔滤波器组来模拟耳蜗听觉模型,提出一种基于多窗谱和伽马通滤波器组的改进MFCC特征(RMFCC,Reformative MFCC).
语音信号具有时变特性,但RMFCC并不能表征帧间相关性.而各人发音的习惯差异主要表现在语音信号频谱结构的时间变化上,因此应充分利用语音的动态特征以弥补RMFCC的缺陷.将RMFCC的动态特征(Delta)加入特征向量.
实验证明:倒谱特征各维分量的均方差差异十分明显,参数的各个分量对系统识别率的贡献并不相同[9].特征参数分量中对语音的表征能力微弱的部分不仅不能提高识别率,反而会降低识别性能.若仅将特征各维分量直接进行简单组合,这是一种比较粗糙的方法.进一步,加权参数是一种至关重要的参数,与加入向量的特征特性以及环境有关,对说话人识别算法具有很大的影响,笔者将根据RMFCC和Delta的特性和噪声环境,提出加权参数设定策略.
2.2 改进MFCC特征提取
RMFCC算法抛弃传统的谱估计,利用多窗谱估计,且将三角滤波器组改为伽马通滤波器组.多窗谱估计在减小语音频谱方差上的性能优越.而伽马通滤波器组是基于人耳耳蜗听觉模型建立的,可以很好地模拟人耳基底膜的分频特性,并可进一步抑制语音的背景噪声,具有一定的抗噪性.因此,RMFCC既可以减小频谱方差,提高特征的准确性,又可以更好地模拟人耳特性,还使倒谱特征具有一定的抗噪性能,因此将两者相结合得到新型听觉特征参数.图2为RMFCC特征的提取流程图.
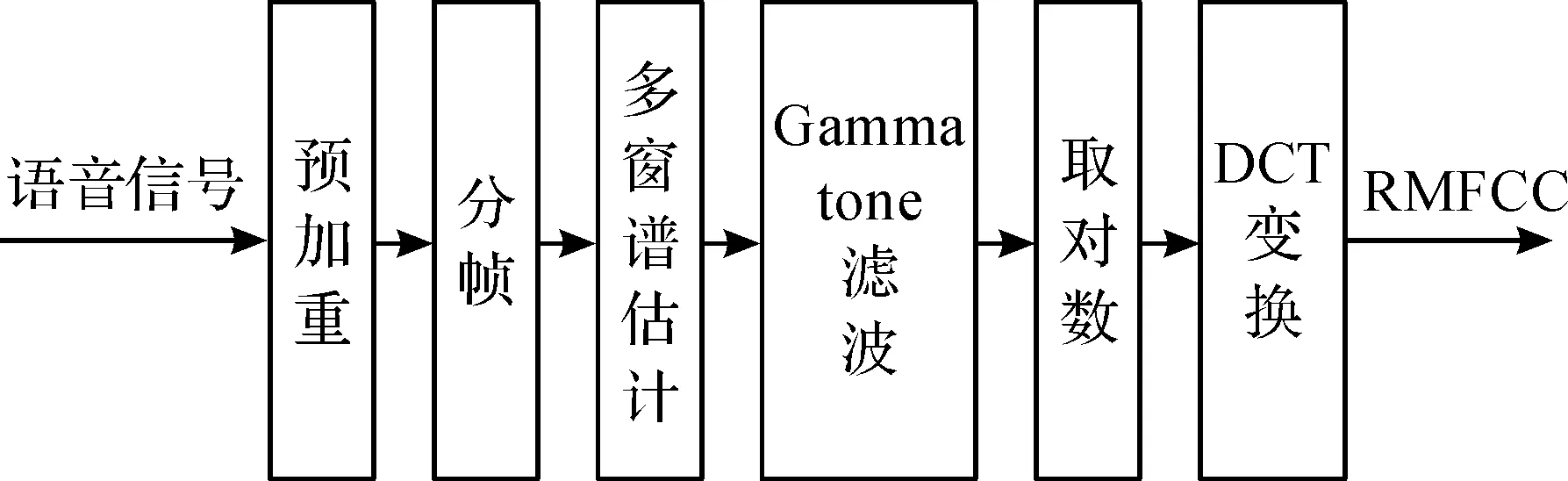
图2 RMFCC提取流程图Fig.2 RMFCC extraction process
2.3 Delta参数的提取
Delta特征是通过将特征向量在语音帧序列的时序上做一次傅里叶变换就得到了该特征向量的Delta特征.笔者采用RMFCC进行二次提取以得到鲁棒性更佳的语音帧间动态信息.
Delta公式[10]定义为
(5)
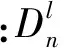
2.4 加权参数的设定
各维特征参数分量对说话人识别的表征能力是不同的,为增强特征参数的区分性,对加入特征向量的特征进行加权.加权参数能够更好地突出说话人的个性特征,将对识别率贡献较低的特征分量进行衰减处理.在将特征加入特征向量之前,将特征各维分量与相应加权系数相乘,使之最大程度反映出特征的个性信息.笔者采用升半正弦函数对特征进行加权,传统采用的升半正弦函数[11]为
r=0.5+0.5sin(π(m-1)/L)m∈[1,L]
(6)
式中L为特征参数的维数.传统的升半正弦加权参数分布如图3所示.由图3可知:传统升半正弦函数值在第13维左右时最大,但在第2维左右趋近于0.
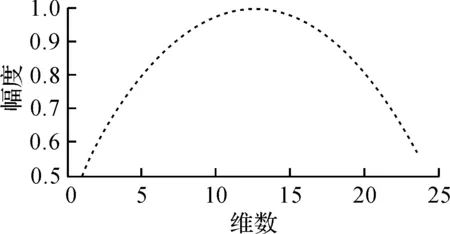
图3 升半正弦函数加权参数分布Fig.3 Weighted half-sine function
实验采用TIMIT标准语音数据库[12]中dr1~dr5(其中,dr为TIMIT语音库中的分类文件夹名称)部分的前20个说话人(男女各10人)的语音进行RMFCC提取.进而深入研究不同噪声环境下RMFCC的特性.RMFCC特征参数图如图4所示.图5为在信噪比为5 dB的babble,car,factory,white等四种噪声环境下,最大幅度值的RMFCC在维数上的分布图.
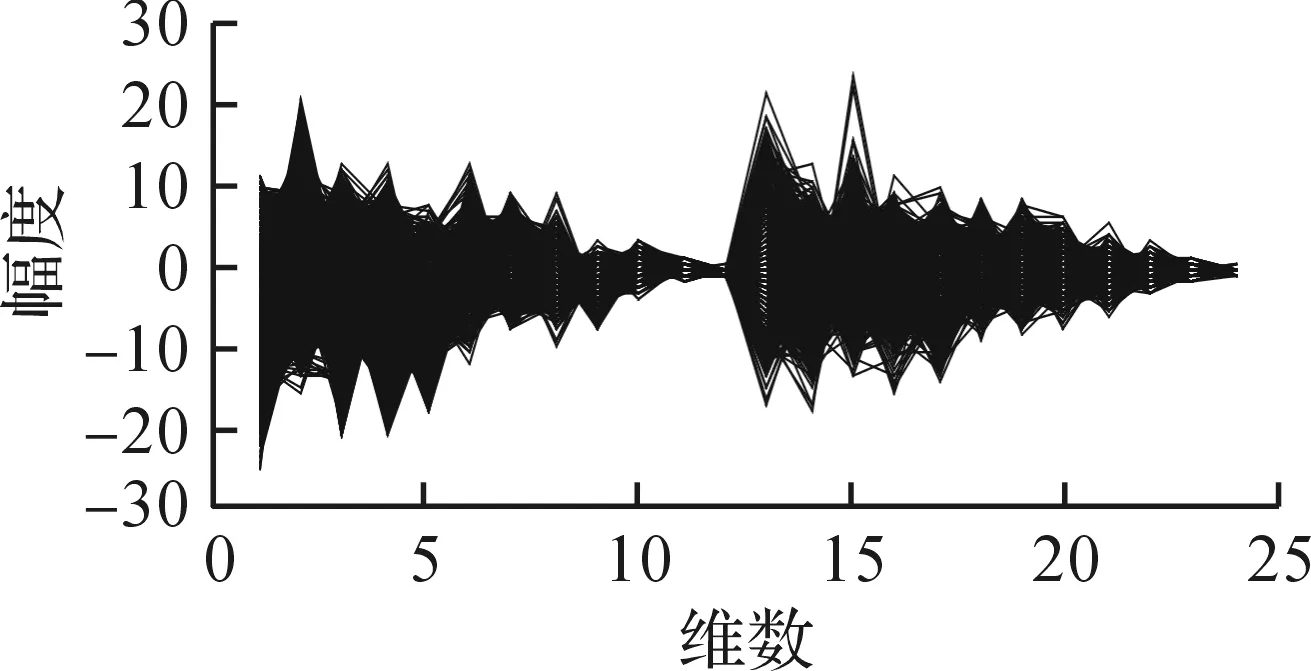
图4 RMFCC的参数分布Fig.4 Parameter distribution of RMFCC
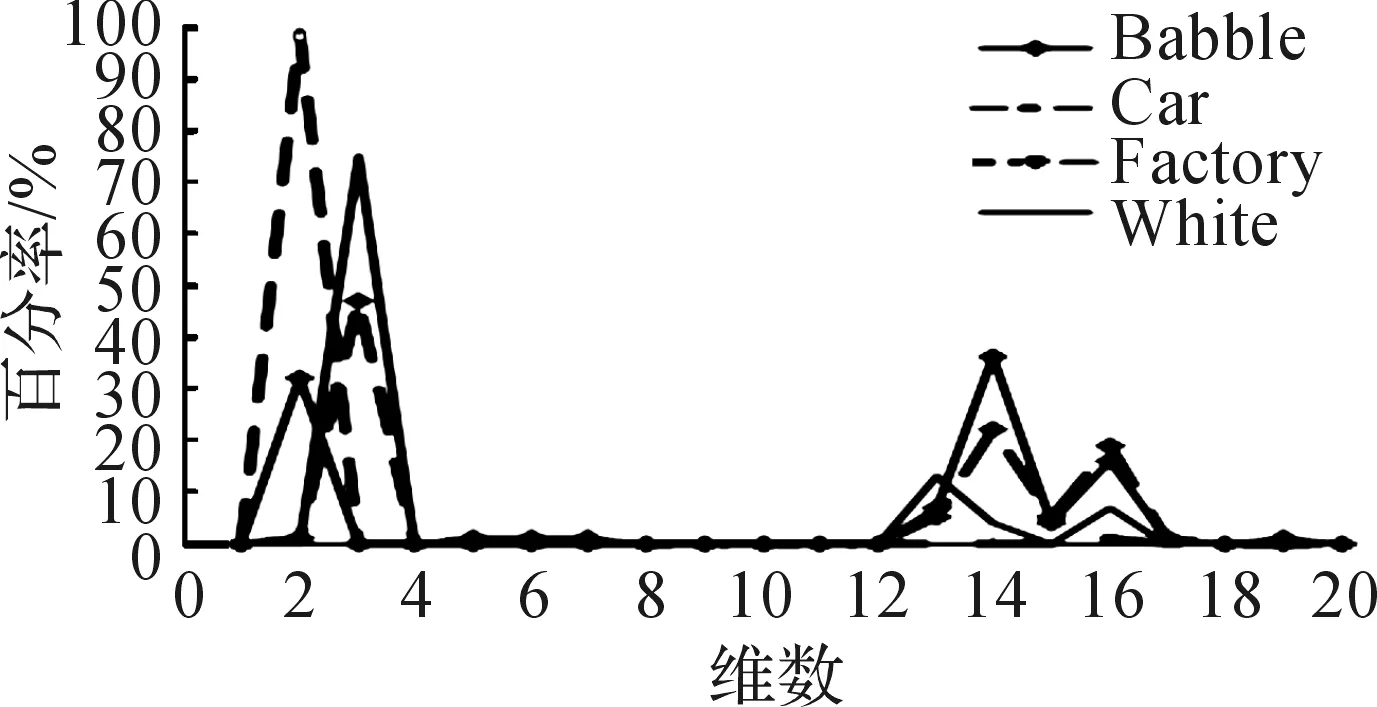
图5 RMFCC最大幅值位置分布Fig.5 Maximum amplitude position distribution of RMFCC
分析图4可以得到:RMFCC特征参数在第2维和第13维左右的特征参量值达到最大,而在第10维到第12维左右趋近于0.从图5可以得到:在4种噪声中,RMFCC的最大幅值大多分布在第1~3维,其余基本集中在第12~15维,还有少部分集中于第15~17维.由此可得语音能量主要集中在低频.研究表明:幅值较小甚至趋近于0部分对语音的表征能力较弱,为使特征参数的区分性突出,加权函数的最大值位置应与特征参数的最大幅值位置相匹配,显然,式(6)所示的加权函数并不理想.因此提出另一种加权函数为
(7)
式中:L为特征参数的维数,设定L=24;a为加权函数的静态分量,根据试验结果,设定a=0.35,目的是保证系数不会完全衰减,同时保证低维分量的作用比高维分量更大.
加权函数分布图如图6所示,得到的加权特征如图7所示.对比图5,6可以得到:改进加权函数的峰值位置与RMFCC最大幅值的位置分布基本一致.由于幅值大小与该维特征对语音的表征能力成正比,因此改进加权函数能够提升特征的鲁棒性.分析图7可得:说话人特征进行加权函数处理后,在保留特征参数较大幅值的同时,对可能由噪声引起的幅值较小的波动进行一定的弱化,从而使加权特征参数能够更精确地反映不同说话人的区别.
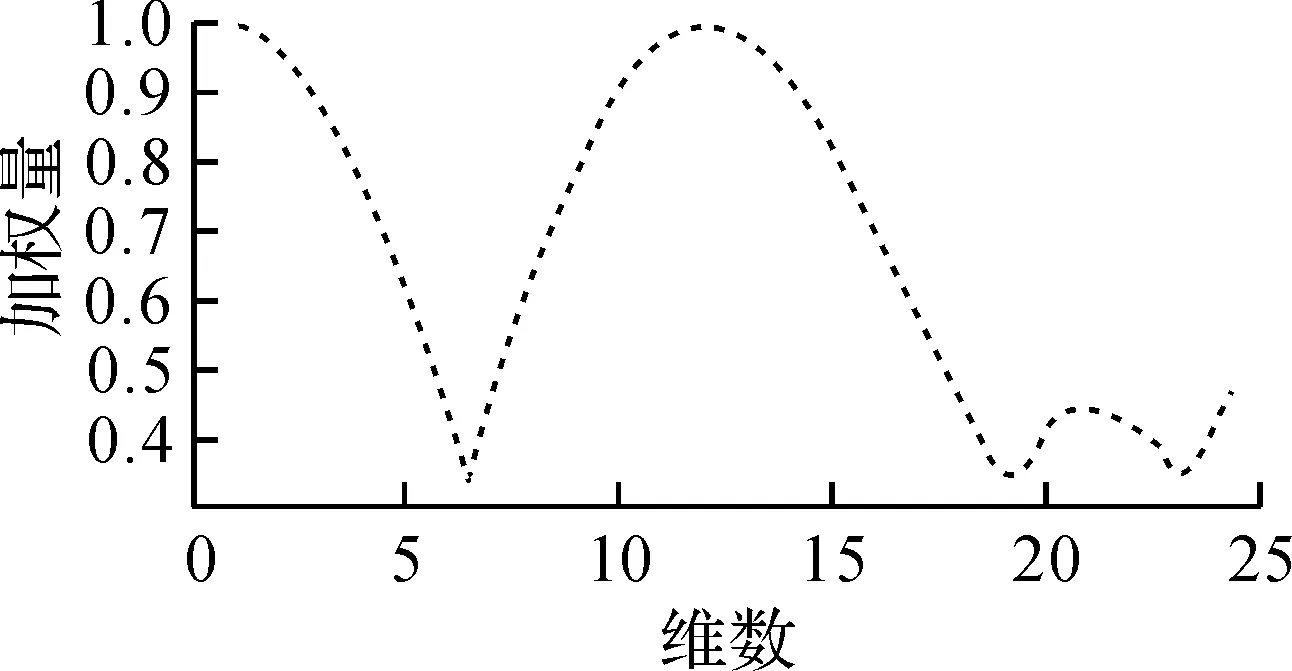
图6 改进的加权函数参数分布Fig.6 Improved weight function parameter distribution
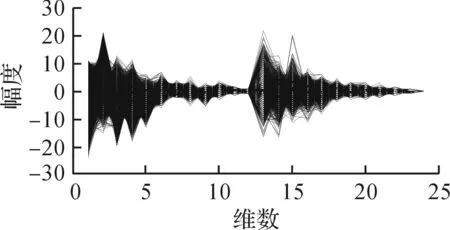
图7 加权RMFCC的参数分布Fig.7 Weighted RMFCC parameter distribution
现实环境中的语音必然会包含噪声,而去噪也是语音特征处理的一个重要的过程,分析图8可知:RMFCC特征参数的第4~6维特征以及14,15维特征受噪声影响较大,会一定程度降低识别性能.因此,为优化识别性能,采用维度筛选,选择表征说话人个性能力良好,且受噪声影响较小的特征.在进行参数组合时,选择1~3,7~13,16~24维特征.将RMFCC和delta特征相组合得到38维混合特征向量.

图8 受噪的RMFCC参数分布Fig.8 The parameter distribution of noisy RMFCC
3 实验结果与分析
3.1 实验参数的设定
本实验采用TIMIT标准语音实验库中的语音数据.语音库中具有多人的纯净语音,每段语音时长为3~6 s.语音采样率为16 kHz,采样精度为16 bit,语音分帧长度为16 ms.NOIZEX-92是一种标准的噪声语音库,具有多种常用的噪声[13].笔者采用库中car,restaurant,street这三种噪声,每种噪声的信噪比分别为15,10,5,0 dB.针对话者识别而言,识别结果只有正确和错误这两种情况,且正确概率和错误概率总和为1,由此实验采用正确识别概率作为评价算法性能的指标.
3.2 特征提取实验
实验一测试RMFCC听觉特征对话者语音的区别性能.采用随机从纯净TIMIT语音库中dr3,dr5两个语音数据集中选取的24个说话人(男女各12个),对每个说话人语音,随机选择一段作为测试音,其他语音作为训练语音.
实验二测试RMFCC听觉特征对噪声环境的抗噪性能,采用TIMIT语音库中的语音,分别在car,street,restaurant环境下进行试验.
实验三测试在三种噪声环境下,测试加权混合特征的改进的有效性和鲁棒性.
试验首先将语音进行预加重、分帧,对每帧语音提取RMFCC,Delta两种参数.对两种特征参数进行加权,并将加权特征进行组合得到加权混合特征向量.采用高斯混合模型——支持向量机混合模型对特征参数进行建模和分类[14-15].其中高斯混合模型混合阶数为16.
3.3 结果与分析
实验一的话者识别结果如表1所示.
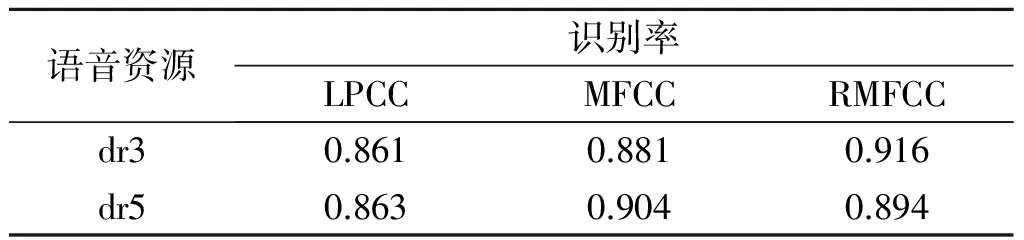
表1 纯净TIMIT语音下的识别率Table 1 The recognition rate of pure TIMIT speech
分析表1的结果,得到RMFCC与MFCC在纯净语音下的性能相当,而LPCC相比这两者鲁棒性较差,RMFCC和MFCC均比LPCC高约3%左右.这个结果表明新型听觉特征RMFCC对语音具有识别性能.
实验二的话者识别结果见图9~11.分析图9~11可以看出:在三种噪声情况下,RMFCC的识别性能明显比MFCC,LPCC更好.在语音环境恶劣的情况下(信噪比在0~5 dB时),RMFCC随着信噪比的增长,识别率增长速度远大于MFCC和LPCC,且识别率也高于其他两种特征参数.这说明RMFCC的抗噪性比MFCC,LPCC更强,在低信噪比环境下,鲁棒性更为优异.信噪比为10~15 dB时,图9~11中传统MFCC和LPCC的识别性能相对近似,但同比MFCC性能较好.这是因为MFCC能更好地描述元音,而LPCC对辅音的描述效果较优,基于不同的语音,识别率略有变化.此外,MFCC参数强调低频信息,且参数无任何前提假设,因此抗噪性比LPCC参数更强,在0~5 dB环境下性能更优.RMFCC与MFCC,LPCC识别率相差不多,这说明在环境优良时,三种参数的性能相差不多,这表示RMFCC同样适合在信噪比良好的情况下作为话者识别算法的特征参数.这个结果证明不同的语音环境下,RMFCC的鲁棒性都比MFCC,LPCC更好.

图9 Car噪声下的识别结果Fig.9 Recognition results under car noise
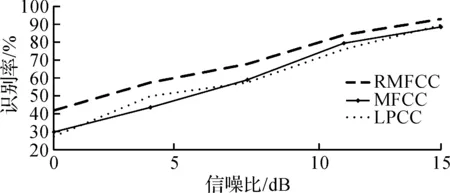
图10 Street噪声下的识别结果Fig.10 Recognition results under street noise
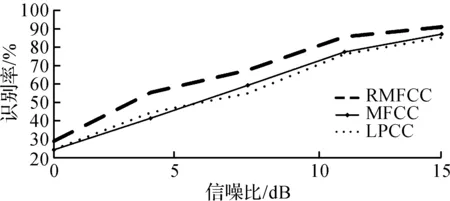
图11 Restaurant噪声下的识别结果Fig.11 Recognition results under restaurant noise
实验三的话者识别结果见图12~14.对图12~14的识别结果分析可以得到:加权混合特征的识别率总体要明显高于RMFCC,MFCC,LPCC.这证明该特征的识别性能比其他三种更优,加权函数对说话人算法特征的优化是有效的.此外,在低信噪比环境下,加权混合特征不仅在识别性能上表现良好,并且在识别性能的提升速度方面也比其他三种特征更优异.这表明该特征的抗噪性和对语音环境的适应性比RMFCC,MFCC,LPCC更好.在语音环境较好的情况下,虽然加权混合特征的识别率的增长速度变慢,但识别率明显仍高于其他三种语音特征参数.这表明加权混合特征的识别性能和抗噪性均优于其他三种特征.
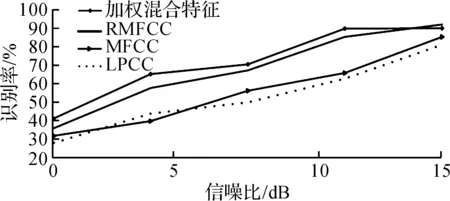
图12 Car噪声下的识别结果Fig.12 Recognition results under car noise
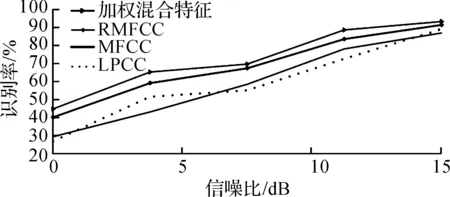
图13 Street噪声下的识别结果图Fig.13 Recognition results under street noise

图14 restaurant噪声下的识别结果图Fig.14 Recognition results under restaurant noise
4 结 论
在研究多窗谱估计和MFCC时,针对传统MFCC方差过大和区分性能不佳的缺陷,采用多窗谱提取特征频谱,并利用伽马通滤波器替代三角滤波器模拟人耳耳蜗滤波模型,弥补MFCC特征的缺陷.从而得到一种基于多窗谱估计和伽马通滤波器组的新型听觉特征参数RMFCC.由于RMFCC是静态特征,缺失语音的动态信息,因此为保证说话人特征信息的完整性,提取说话人语音的动态特征即Delta特征.进一步,分析RMFCC特征参数的幅值位置分布的特性,提出改进的加权函数.对特征进行加权并组合,由此提出一种基于新型听觉特征和加权函数的加权混合特征.实验结果表明:提出的加权混合特征与MFCC,LPCC相比,不仅在良好语音环境下具有优良的鲁棒性,并且在低信噪比环境下具有更好的识别性能和抗噪性.
[1] SAHIDULLAH M, SAHA G. A novel windowing technique for efficient computation of MFCC for speaker recognition[J]. IEEE signal processing letters,2013,20(2):149-152.
[2] ALAM M J, KINNUNEN T, KENNY P, et al. Multitaper MFCC and PLP features for speaker verification using i-vectors[J]. Speech communication,2013,55(2):237-251.
[3] 曾祺,甘涛,曾红斌.改进的多窗谱MFCC在说话人确认中的应用[J].计算机系统应用,2014,23(11):192-195.
[4] 方志刚,胡国兴,吴晓波.基于非语音声音的听觉用户界面研究[J].浙江大学学报(工学版),2003,37(6):684-688.
[5] TRANGOL J, HERRERA A. Traditional method and multi-taper to feature extraction using Mel frequency cepstral coefficients[J]. International journal of information and electronics engineering,2015,5(1):27.
[6] ALAM M J, KENNY P, O’SHAUGHNESSY D. Low-variance multitaper Mel-frequency cepstral coefficient features for speech and speaker recognition systems[J]. Cognitive computation,2013,5(4):533-544.
[7] SANDBERG J, HANSSON-SANDSTEN M, KINNUNEN T, et al. Multitaper estimation of frequency-warped cepstra with application to speaker verification[J]. IEEE signal processing letters,2010,17(4):343-346.
[8] LI M, NARAYANAN S. Simplified supervised i-vector modeling
with application to robust and efficient language identification and speaker verification[J]. Computer speech & language,2014,28(4):940-958.
[9] ZHU L, YANG Q. Speaker recognition system based on weighted feature parameter[J]. Physics procedia,2012,25:1515-1522.
[10] ZHAO X, SHAO Y, WANG D L. CASA-based robust speaker identification[J]. IEEE transactions on audio, speech, and language processing,2012,20(5):1608-1616.
[11] SAHIDULLAH M, SAHA G. Design, analysis and experimental evaluation of block based transformation in MFCC computation for speaker recognition[J]. Speech communication,2012,54(4):543-565.
[12] ZUE V, SENEFF S, GLASS J. Speech database development at MIT: TIMIT and beyond[J]. Speech communication,1990,9(4):351-356.
[13] VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: II NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech communication,1993,12(3):247-251.
[14] 姚明海,何通能.一种基于模糊积分的多分类器联合方法[J].浙江工业大学学报,2002,30(2):156-159.
[15] 汤一平,严海东.非约束环境下人脸识别技术的研究[J].浙江工业大学学报,2010,38(2):155-161.
(责任编辑:陈石平)
Speakerrecognitionalgorithmbasedonweightedmixturefeatures
XU Zhijiang, ZHAO Mengna, LU Weidang
(College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China)
Multi-window spectrum estimation and gamma-pass filtering are used to improve the recognition performance of classical Mel-cepstral feature (MFCC). Combined with the delta feature, a mixed feature speaker recognition algorithm based on weighted parameter setting strategy is proposed. The algorithm solves the problem that the Mel-cepstral coefficient variance is too large, the auditory features are not obvious, and the feather of speaker recognition algorithm is simple. The simulation results show that the proposed algorithm has better robust performance and better adaptability to different noise environments than MFCC and linear predictive extraction methods.
multi-window spectrum estimation; gamma-pass filter bank; weighted parameter; weighted mixed characteristic parameters
2016-12-14
国家自然科学基金资助项目(61471322,61402416)
徐志江(1973—),男,浙江绍兴人,副教授,研究方向为信道编译码、网络测量与建模、计算机网络及应用等,E-mail: zyfxzj@zjut.edu.cn.
TP391
A
1006-4303(2017)06-0628-06
猜你喜欢
军事文摘(2024年4期)2024-03-19 09:40:02
军事文摘(2023年18期)2023-10-31 08:11:44
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
家庭影院技术(2018年8期)2018-08-21 12:09:20
制造技术与机床(2017年11期)2017-12-18 06:46:39
电子设计工程(2017年17期)2017-09-07 06:37:46
数字通信世界(2015年4期)2015-09-23 07:57:30
电测与仪表(2015年7期)2015-04-09 11:40:04
装备环境工程(2015年1期)2015-02-06 07:48:55
