
基于深度学习特征的异常行为检测
2017-11-20 08:37王军夏利民
湖南大学学报·自然科学版 2017年10期
关键词:特征提取
王军+夏利民


摘 要:已有的异常行为检测大多采用人工特征,然而人工特征计算复杂度高且在复杂场景下很难选择和设计一种有效的行为特征.为了解决这一问题,结合堆积去噪编码器和改进的稠密轨迹,提出了一种基于深度学习特征的异常行为检测方法.为了有效地描述行为,利用堆积去噪编码器分别提取行为的外观特征和运动特征,同时为了减少计算复杂度,将特征提取约束在稠密轨迹的空时体积中;采用词包法将特征转化为行为视觉词表示,并利用加权相关性方法进行特征融合以提高特征的分类能力.最后,采用稀疏重建误差判断行为的异常.在公共数据库CAVIAR和BOSS上对该方法进行了验证,并与其它方法进行了对比试验,结果表明了该方法的有效性.
关键词:异常行为;深度学习特征;堆积去噪编码器;特征提取;稠密轨迹
中图分类号:TP391 文献标志码:A
Abnormal Behavior Detection Based on Deep-Learned Features
WANG Jun,XIA Limin
(College of Information Science and Engineering,Central South University ,Changsha 410075,China )
Abstract:Most existing methods of abnormal behavior detection merely use hand-crafted features to represent behavior,which may be costly. Moreover,choice and design of hand-crafted features can be difficult in the complex scene without prior knowledge. In order to solve this problem,combining the stacked denoising autoencoders (SDAE) and improved dense trajectories,a new approach for abnormal behavior detection was proposed by using deep-learned features. To effectively represent the object behavior,two SDAE were utilized to automatically learn appearance feature and motion feature,respectively,which were constrained in the space-time volume of dense trajectories to reduce the computational complexity. The vision words were also exploited to describe the behavior using the method of bag of words. In order to enhance the discriminating power of these features,a novel method was adopted for feature fusing by using weighted correlation similarity measurement. The sparse representation was applied to detect abnormal behaviors via sparse reconstruction costs. Experiments results show the effectiveness of the proposed method in comparison with other state-of-the-art methods on the public databases CAVIAR and BOSS for abnormal behavior detection.
Key words:abnormal behavior; deep-learned features; SDAE; feature extraction; dense trajectories
異常行为检测是智能监控系统的核心,近年来,已引起了学术界和工业界的广泛关注,并成为计算机视觉的重要研究课题.然而,场景的复杂性和异常行为的多样性,使得异常行为检测仍然是一项具有挑战性的工作.
根据所用特征,异常行为检测方法可分为两大类:基于视觉特征的异常检测和基于轨迹的异常检测.在基于物体轨迹的异常检测方面,Junejo等[1]以轨迹的位置、速度、空时曲率等作为特征,提出了基于DBN的异常行为检测.Yang等[2]提出了基于轨迹和多示例学习的局部异常检测方法.Li等[3]用三次样条曲线表示目标轨迹,提出了基于稀疏表示的异常检测方法.Mo等[4]提出了基于轨迹联合稀疏表示的异常行为检测方法.Kang等[5]用HMM表示轨迹的运动模式,提出了基于HMM的异常检测方法.然而,在目标遮挡情况下,跟踪性能明显下降,导致异常检测率低.
为了解决上述问题,采用视觉特征进行异常行为检测,如方向梯度直方图HOG,3D空时梯度,光流直方图HOF等.Saligrama等[6]利用局部空-时特征和最优决策规则进行异常检测.Nallaivarothayan[7]以光流加速度、光流梯度直方图作为特征,提出了基于MRF的异常事件检测.Wang等[8]引入加速度信息,构建混合光流方向直方图,采用稀疏编码进行异常检测.Zhang等[9]结合运动信息和外观信息进行异常检测.Mehran等[10] 利用光流特征构建社会力模型SFM来表示人群行为和异常行为识别.Wang和Schmid[11]提出了基于稠密轨迹行为识别,沿着稠密轨迹提取HOG,HOF以及运动边界描述符MBH来表示行为,利用SVM进行行为识别.然而,这些视觉特征是人为设计的,很难有效地反映行为特性,并且计算复杂.endprint
目前,基于深度学习特征表示已成功地用于异常行为检测.Xu等[12]采用堆积去噪编码器提取外观特征和运动特征,利用多类SVM进行异常行为检测.Erfani等[13]利用深度置信网络提取行为特征,利用SVM进行异常行为检测.Zhou等[14]采用空时卷积神经网络提取行为特征,进行人群异常行为检测和定位.Fang等[15]以图像的显著性信息和多尺度光流直方图作为低层特征,然后采用深度学习网络PCANet从这些低层特征中提取更有效的特征用于异常事件检测.Hu等[16]构建了一个深度增强慢特征分析网络,并用于行为特征提取和异常检测.基于深度学习的异常行为检测是借助于深度结构,通过多层非线性变换从原始图像中学习和挖掘复杂的非线性行为特征表示,相比基于人工特征的异常检测,由于深度学习得到的特征往往具有一定的语义特征和更强的区分能力,能更有效地表示行为特性,因此基于深度学习的异常行为检测准确率更高.同时基于深度学习的异常行为检测降低了计算复杂性.然而,基于深度学习的异常行为检测的性能远没有达到人们的期望,主要原因是:1)深度学习方法需要大量的样本用于训练,而一般的行为数据库样本相对比较少;2)为了平衡计算代价,基于深度学习的行为表示通常采用下采样策略,导致信息丢失[17].
为了解决该问题,受文献[11-12]的启发,我们结合堆积去噪编码器和改进的稠密轨迹,提出了一种基于深度学习特征的异常行为检测方法,利用深度学习提取行为特征,采用稀疏重建进行异常行为检测.该方法基本思想是利用堆积去噪编码器的学习能力和稠密轨迹方法的优良采样性能和特征提取策略来提取有效的行为特征.首先利用堆积去噪编码器,沿行为兴趣点轨迹提取深度外观特征和运动特征;由于不同行为视频中目标个数不同,从而兴趣点个数及其对应的轨迹数不同,导致整个特征长度不同,为了解决该问题,采用词包法将特征转化为行为视觉词表示;在此基础上,为了提高特征的分类能力,利用加权相关性法对这二种特征进行融合;最后,采用稀疏重建进行异常行为检测.在公共数据库CAVIAR和BOSS上利用文中方法和其它几种方法进行了对比实验.
1 改进的稠密轨迹提取
首先介绍稠密轨迹的提取[11].把图像划分成大小为W×W的网格,并在每个网格上进行采样.在采样过程中,以网格的中心作为采样点,对每个采样点进行三值插值处理得到兴趣点.为了得到足够多的兴趣点,按1/2比例增加空间尺度,由于视频分辨率的限制,可选择8个空间尺度.通过实验发现,当W=5,在所有数据库上都可以得到很好的实验结果.
由于在没有结构的均匀区域内跟踪不到任何点,因此,将这些区域内的点去掉,这些点对应的自相关矩阵的特征值很小,为此设置一个阈值,舍弃自相关矩阵的特征值小于阈值的兴趣点.阈值设置为:
T=0.001×maxi∈Imin(λ1i,λ2i)(1)
式中:(λ1i,λ2i)是图像I中点i自相关矩阵的特征值.
得到兴趣点后,利用光流法在每个空间尺度上对兴趣点进行跟踪,得到其运动轨迹.设第t帧图像It的稠密光流为wt =(ut, vt),这里ut和vt分别为光流的水平分量和竖直分量,则It中某一点zt =(xt, yt)在下一帧It+1中的位置可通过对wt进行中值滤波平滑得到:
zt+1=(xt+1,yt+1)=(xt,yt)+(M*wt)|(xt,yt)(2)
式中:M为中值滤波的核,其大小为3×3.采用中值滤波可以很好地保留跟踪过程中边界上的点.
把各帧对应的兴趣點连接起来就得到该兴趣点的轨迹:(zt,zt+1,…,zt+L-1).在跟踪过程中可能会出现轨迹漂移,为了避免这种现象,我们限制采样帧的长度L=15,另外,由于一条持续5帧图像的轨迹才是“可靠的”,短于5帧的轨迹自动被删除.为了得到稠密的轨迹,在每一帧图像中,如果在一个W×W的邻域内没有任何跟踪点,那么选择新的点作为采样点,并对新采样点进行跟踪.在后处理阶段,我们删掉静态轨迹和突然漂移比较大的轨迹,因为前者不包含运动信息,后者很有可能是跟踪误差所致.
2 行为深度特征
稠密轨迹附近包含丰富的行为信息,我们利用稠密轨迹和堆积去噪编码器SDAE提取行为深度外观特征和运动特征.首先介绍堆积去噪编码器,然后描述基于稠密轨迹和堆积去噪编码器的行为深度学习特征提取方法.
2.1 堆积去噪编码器
去噪编码器DAE[18]是一种三层神经网络,用于从噪声数据i重建原数据xi,DEA包含二个部分:编码器和解码器.DEA学习就是学习两个映射函数fe(W;b)和fd(W′;b′),其中W,b表示编码器部分的权值矩阵和偏差向量,W′,b′对应于解码器的参数.对于噪声数据i,编码器的隐层输出为y:
y=fe(i)=s(Wi+b)=11+e-(Wi+b)(3)
解码器目的是从噪声数据i重建原数据xi:
zi=fd(y)=s(W′y+b′)(4)
给定一组训练样本X={xi}Ni=1,通过求解下列优化问题来学习DEA的参数(W,W′,b,b′):
minW,W′,b,b′∑Ni=1‖xi-zi‖22+λ(‖W‖2F+
‖W′‖2F)+β∑Kj=1KL(μ‖)(5)
式中:第一项表示重建误差,第二项为权值惩罚项,第三项为稀疏性约束,λ,β为平衡参数,μ是稀疏性参数,它表示隐节点的系数水平,K是隐含层的节点个数,j是隐含层第j 个节点对所有训练样本的平均阈值化激活值,如果平均激活值大于0.5时,j=1,否则j=0.第三项稀疏性约束为:
KL(μ‖j)=-μlogj+(1-μ)log(1-j)(6)
利用梯度下降法对式(5)进行求解,可确定DAE参数.endprint
將多个DAE逐层堆叠形成SDAE,其中低层DAE的输出作为上一层DAE的输入.SDAE的训练,采用从低层向高层逐层训练的方式对各层中的DAE进行训练.训练好的SDAE可用于从输入数据中学习到有效的特征表示.
2.2 行为深度特征提取
我们分别利用两个SDAE在以轨迹为中心的3D体积中提取行为的外观特征和运动特征.3D体积的大小为N×N×L,L=15为轨迹的长度,N取32.为了嵌入结构信息,首先,将该立方体划分为nσ×nσ×nτ的时-空网格,本文取nσ=2,nτ=3;然后在这些网格(大小为16×16×5)中用SDAE提取深度特征;最后将所有网格的特征结合得到与该轨迹对应的深度特征.
图1表示提取行为深度特征的SDAE的结构,它包括两个SDAE,其中一个用于学习外观特征,称为外观堆积去噪编码器(ASDAE),另一个用于学习运动特征,称为运动堆积去噪编码器(MSDAE).每个SDAE 包括两个部分:编码器和解码器.编码器的输入层节点数等于输入数据的维数,然后,每层节点数逐层减少一半,直到“瓶颈”隐层,解码器的结构与编码器对称,“瓶颈”隐层的输出就是深度特征,实验结果表明,当隐层数为5时系统检测率最高.
2.2.1 外观深度特征
在灰度视频图像中,以轨迹为中心的3D体积中各个网格区域的图像(16×16×5)作为ASDAE的输入,其“瓶颈”隐层的输出作为外观深度特征,然后,将体积中各个网格区域的外观深度特征连接起来得到该轨迹(该兴趣点)的外观深度特征.由于网格区域大小为16×16×5,所以ASDAE的输入层节点个数为1 280,各隐层节点个数分别为:640,320,160,80,40;一条轨迹对应的外观特征维数为480(2×2×3×40).
2.2.2 运动深度特征
根据光流场提取运动深度特征.以轨迹为中心的3D体积中各个网格区域的光流场(16×16×2×5)作为MSDAE的输入,其“瓶颈”隐层的输出作为运动深度特征,然后,将体积中各个网格区域的运动深度特征连接起来得到该轨迹(该兴趣点)的运动深度特征.这里ASDAE的输入层节点个数为2 560,各隐层节点个数分别为:1 280,640,320,160,80;一条轨迹对应的外观特征维数为960(2×2×3×80).
将两类特征合在一起,则每一条轨迹可用1 440维的向量表示.相比一般深度特征而言,我们的深度学习特征具有以下优点:
1)不需要大量的行为样本,适合于样本少的行为数据库识别.因为我们用深度网络不是直接提取整个行为特征,而是提取行为区域中的采样点(兴趣点)的特征,而采样点的个数足以训练深度网络.
2)尽可能保留了行为信息.这是因为我们采用的是稠密轨迹采样,这是一种浓密的采样,信息丢失较少,同时保留了结构信息.
3)计算复杂度不高.因为我们只是在稠密轨迹附近提取特征,而包含少量运动信息的区域并未计算.
3 基于加权相关性的特征融合
3.1 行为特征的词包表示
由上可知,对于一条轨迹可以得到一个1 440维的特征向量.由于不同视频中目标个数不同,导致兴趣点的个数以及对应的轨迹条数不同,行为特征维数不同,因此,利用词包法将行为特征用视觉词表示,以统一行为的维数.分别根据外观深度特征和运动深度特征利用词包法建立外观视觉字典和运动视觉字典,然后分别由外观视觉词和运动视觉词表示外观深度特征和运动深度特征.
具体方法是:首先,提取轨迹的外观深度特征/运动深度;然后对所有轨迹外观深度特征/运动深度进行聚类,得到Nv个类中心,每个类对应一个视觉词.对于测试行为样本,根据最近邻原则,把它的每条轨迹分类到每一类,于是可得到各个视觉词在样本中出现的频率,这些频率就构成样本的视觉词表示.
经过多次实验得到外观视觉词和运动视觉词的个数分别为230和470.因此,外观深度特征和运动深度特征分别用230维和470维的视觉词向量表示.
3.2 基于加权相关性的特征融合
为了提高特征的分类能力,采用基于加权相关性的特征融合方法将外观深度特征和运动深度特征结合在一起形成700维的特征向量.
为了表示方便,将外观深度特征和运动深度特征分别用y1,y2表示,则融合后的特征y为:
y=(ω1y1,ω2y2)(7)
这里ωi是加权系数,且(ω1)2+ (ω2)2=1.我们根据类内一致性和类间可分性来确定该加权系数.
类内一致性:一般希望同类中的样本在特征空间尽可能接近.但是通常在同一类中样本特征会出现较大的方差,因此,没有必要要求同类中的所有样本都相互接近.一种权衡的方法是保证同类中同一近邻内的样本尽可能接近.设yi=(ω1 yi1,ω2 yi2),yj=(ω1 yj1,ω2 yj2)表示第i,第j个样本,则类内一致性定义为:
Sc=∑Ni=1∑j∈N+k(Fi)〈yi,yj〉‖yi‖‖yj‖=
∑Ni=1∑j∈N+k(Fi)∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(8)
式中:N+k(Fi)表示样本Fi的、且与Fi属于同一类的k个最近邻样本的索引集.
类间可分性:要求特征具有好的区分性,即不同类的两个样本在特征空间尽可能远离.但这样的样本对很多,为了减少计算量,只考虑特征空间分界面附近的样本对.于是定义类间可分性为:
Sc=∑Ni=1∑j∈N-k(Fi)〈yi,yj〉‖yi‖‖yj‖
=∑Ni=1∑j∈N-k(Fi)∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(9)endprint
式中:N-k(Fi)表示样本Fi的、且与Fi不同类的k个最近邻样本的索引集.
融合后的特征应具有良好的类内一致性和类间可分性,因此通过求解下列优化问题确定加权系数:
maxω{(Sc-Sb)+λs‖ω‖}
s.t. ωk>0,‖ω‖=1(10)
式中,λs是控制参数.
采用梯度下降法求解式(10),即:
ωk(t+1)=ωk(t)+ηLωk|ωk=ωk(t)(11)
式中:t为迭代次数,η为迭代步长,L=(Sc-Sb)+λs‖ω‖为目标函数.
Lωk=
∑Ni=1∑j∈N+k(xi)hij(ω)ωk-∑j∈N-k(xi)hij(ω)ωk+2λsωk(12)
这里:
hij=∑2k=1ω2kykiykj∑2k=1ω2k(yki)2∑2k=1ω2k(ykj)2(13)
hij(ω)ωk=
2fkijb1/2iib1/2jj+bij(b1/2jjf1/2ii/b1/2ii+b1/2iif1/2jj/b1/2jj)∑2k=1ω2k(fik)2∑2k=1ω2k(fjk)2(14)
fkij=ykiykj(15)
bij=∑2k=1ω2kykiykj(16)
4 基于稀疏重建的異常行为检测
得到行为的特征后,采用稀疏重建来进行异常行为检测,其基本思想是任何行为可以用一组正常训练样本的稀疏线性组合表示.对于正常行为,稀疏重建误差小,而异常行为稀疏重建误差比较大.因此,我们可根据重建误差[19]来进行异常检测.
设有C类正常行为,每个行为用上述特征向量表示,D=[D1,D2,…,DC]表示稀疏字典,其中Di是由K个第i类行为构成的子字典,对于测试样本y可表示为:
y=Dα(17)
这里,α=[α1,α2,…,αc]T为稀疏编码向量.稀疏重建的关键是字典学习和求解稀疏编码.
4.1 字典学习
给定训练样本集Y={y1, y2,…, yN}∈Rm×N,yi∈ Rm表示第i个正常样本的特征向量,目的是学习字典D和稀疏编码向量α,使Y可以通过字典的加权和来重建,即:Y=Dα,也就是求解下列优化问题:
minD,α‖Y-Dα‖F+λ‖α‖2,1(18)
这里λ控制参数,第一项是重建误差,第二项是稀疏性约束.这是一个非凸的优化问题.但是如果D和α中的一个固定,则问题就变为线性的.因此,通过依次固定D和α,可以导出D和α,具体算法[20]如下:
1)输入训练样本集Y,初始字典D0∈Rm×K,i=0;
2)令i=i+1;
3)固定D利用式(22)求αi;
4)固定α利用式(21)求Di;
5)重复2),3),4)步,直到收敛;
6)输出字典Di.
算法中每一步确定Di和αi就是求解:
Di=argminD‖Y-Dα‖F(19)
αi=argminα‖Y-Dα‖F+λ‖α‖2,1(20)
式(19)采用K-SVD算法来求解.由于‖α‖2,1是非平滑的,所以,式(20)对应的优化问题是凸的、非平滑的优化问题,用一般优化算法求解会导致收敛速度很慢,在此,利用Nesterov提出的方法[21]来求解.考虑目标函数f0(x) + g(x),其中,f0(x) 是凸的且平滑,而g(x)是凸的、非平滑,Nesterov采用
PZ,L(x)=f0(Z)+〈f0(Z),x-Z〉+
L‖x-Z‖2F+g(x)(21)
来近似表示Z处的f0(x) + g(x).这里L是Lipschitz常数.这样每次迭代,只需求解minx PZ,L(x).
定义f0(α)=‖Y-Dα‖F,g(α)=λ‖α‖1,则有:
PZ,L(α)=f0(Z)+〈f0(Z),α-Z〉+
L‖α-Z‖2F+λ‖α‖2,1(22)
类似文献[21],可得到式(20)的解:
argminαPZ,L(α)=Hλ/L(Z-1Lf(Z))(23)
式中,Hτ:M∈Rk×k → N ∈Rk×k
Ni=0,‖Mi‖≤τ;
(1-τ/‖Mi‖)Mi,otherwise(24)
这里,τ=λ/L,M=Z-(1/L)f(Z),Mi是原数据的第i行,Ni是计算得到的矩阵的第i行.
4.2 异常行为检测
给定一个字典D,对于测试样本y可用式(17)表示,其中,稀疏编码α可通过求解式(25)获得:
α*=minα‖y-Dα‖2+λ‖α‖1(25)
一旦得到最优的稀疏编码α*,可以计算稀疏重建代价(SRC) [19]:
S(y,α*,D)=‖y-Dα‖2+λ‖α*‖1(26)
对于正常行为,稀疏重建代价较小,而异常行为稀疏重建代价较大.因此如果
S(y,α*,D)>ε(27)
则y为异常行为.式中,ε是预先设置的阈值.
5 实验与结果
为了验证所提方法的有效性,我们在公共数据库CAVIAR和BOSS上进行了实验,并与以下4种方法进行对比:1) Mo等[4]提出的基于轨迹联合稀疏表示的异常行为检测方法;2)Wang等[11]提出的基于稠密轨迹方法;3)Xu等[12]提出的基于外观深度网络和运动深度网络的异常检测方法;4)Zhou等[14]提出的基于空时卷积神经网络的异常检测方法.endprint
我们以ROC曲线评估异常行为检测效果,ROC曲线以FPR为横坐标,TPR为纵坐标.其中:
TPR=TPTP+FN,FPR=FPFP+TN(28)
这里,TP (True positive)是真异常行为,FN(False negative)假正常行为,FP (False positive)是假异常行为,TN(True negative)真正常行为. 我们选择不同的阈值ε,分别计算FPR和TPR,然后,作ROC曲线.ROC曲线越靠近上方,曲线下面积AUC越大,则检测的准确率越高,否则检测准确率越低.
5.1 CAVIAR 数据库
在实验中,我们利用CAVIAR数据库的第一部分数据进行实验.这些数据是利用广角镜头拍摄的,包括行走、闲逛,休息、跌倒或晕倒等单人行为,以及会谈、两人走近和分开、两人打架等交互行为.每个场景包括3至5片段,每个片段持续40至60 s,分辨率為384×288,共采用了26个片段.该数据库可用于单人异常行为和两人的交互异常行为.
由于每片段包含几种行为,因此采用人工方法将每片段分成多个镜头,使每个镜头只包含一个行为.结果数据库分成1 200个行为镜头,其中,200个异常行为和1 000正常行为.其中打架、追赶、闲逛、丢包和晕倒等异常行为个数分别为44,39,42,37和38.图2是该数据库的一些异常行为的视频帧.其中,图2(a)为一个人穿过大厅时晕倒;图2(b)是一个人丢包;图2(c)是两个人打架.实验中,我们首先提取稠密轨迹;其次随机选择500万条轨迹训练SDA,并采用K-均值聚类法得到230个外观视觉词和470个运动视觉词(视觉词的个数分别从100到1 000变化时,发现当外观视觉词为230个、运动视觉词为470个可取得最好性能);然后随机选择800个正常行为学习特征融合参数,得到:ω1=0.3,ω2=0.7;最后,用800个正常行为学习稀疏字典.以全部异常行为样本和余下的200个正常样本作为测试样本,测试结果为AUC=0.996,表明文中方法的检测率很高.图3给出了几种检测方法的ROC曲线.表1是几种检测方法ROC曲线下的面积AUC.结果表明,对于单人异常行为和两人的交互异常行为,文中方法比其它3种方法具有更好的检测准确率.
5.2 BOSS数据库
BOSS数据库是在列车上通过9个摄像头拍摄的,包括14个视频序列,每段视频持续1到5 min.分辨率为720×576,帧率25 fps.14个视频包括3个正常行为视频,11个异常行为视频.异常行为包括:抢手机、打架、抢报纸、骚扰、晕倒、恐慌.该数据库可用于单人、多人的异常行为检测.
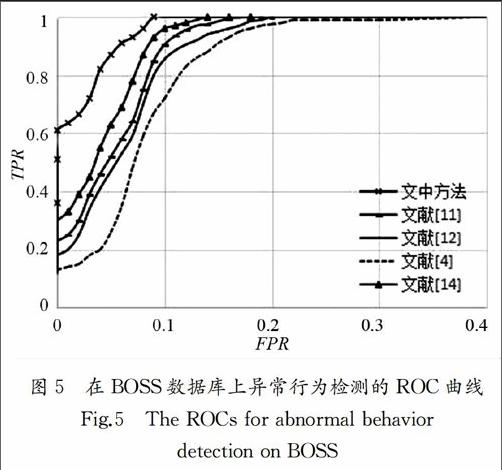
同样采用人工方法将每视频分成多个镜头,每个镜头只包含一个行为.结果这个数据库分成1 600个行为镜头,其中,400个异常行为和1 200正常行为,抢手机、打架、抢报纸、骚扰、晕倒、恐慌等异常行为数分别为52,70,65,58,65,90. 图4是该数据库的一些异常行为的视频帧.其中图 4(a)为打架;图4(b) 是晕倒;图4(c) 为抢手机.实验过程和CAVIAR数据库上的实验一样,随机选择500万条轨迹训练SDA、确定外观视觉词和运动视觉词;选择1 000个正常行为学习特征融合参数(ω1=0.35,ω2=0.65)和稀疏字典.用全部异常行为样本和余下的200个正常样本作为测试样本,测试结果为AUC=0.982,即我们的方法有很高的检测率.图5是几种检测方法的ROC曲线.
以上结果表明,无论是单人的异常行为检测还是多人异常行为检测,与其它方法相比,我们的方法都具有更高的检测准确率.文献[4]采用基于目标轨迹的异常行为检测,由于视频中有多人交互情况,不可避免存在遮挡问题,使得跟踪性能明显下降,导致异常检测率比其它方法低.文献[11]采用稠密轨迹特征(HOG,HOF 和MBH),这些特征是目前最好的人工特征[17],因此检测准确率明显提高.文献[12]和[14]分别采用堆积自动编码器和空时卷积神经网络提取行为特征,这些特征能较好地描述人体行为,因此其检测率超过93%.但这两个方法检测率并不比基于稠密轨迹方法高,这是因为:1)这些方法需要大量的样本用于训练深度学习网络,而行为数据库样本相对比较少;2)为了平衡计算代价,提取行为表示通常下采样策略,采用导致信息丢失.而我们的方法是沿行为兴趣点的稠密轨迹提取行为的外观特征和运动特征.一方面,由于在稠密轨迹附近有丰富的运动信息,利用堆积去噪编码器强大的学习能力可提取有效的行为特征;另一方面,用深度网络不是直接提取整个行为特征,只是提取行为区域中的采样点的特征,而这些采样点的个数足以训练深度网络,因此不需要大量的样本训练深度网络,解决了训练样本不足对深度学习的影响,所以异常行为检测率比其他几种方法更高.
5.3 计算复杂性
我们对所提方法的计算复杂度进行了测试,所有实验都在工作站 (2.8 GHz CPU,32GB RAM)上进行.表3为几种方法分别在CAVIAR,BOSS中每帧平均计算时间.从表中可看出,基于目标轨迹的异常行为检测计算时间最少,而基于稠密轨迹的异常行为检测计算时间最长,我们的方法与其它二个基于深度学习的异常行为检测计算时间适中,表明我们的方法是非常有效的.这是因为这几种方法在异常识别阶段的时间都差不多,并占总时间的很小部分,主要计算时间花费在特征提取上.基于目标轨迹的异常行为检测用B样条函数近似目标轨迹,取B样条函数50个控制点的坐标作为行为特征,显然这些特征的提取需要时间最少.而基于稠密轨迹的异常行为检测所用时间主要在光流场计算、稠密轨迹提取和HOG,HOF 和MBH的计算,其中特征HOG,HOF 和MBH的计算需要很长时间;文献[12]和[14]分别采用深度网络提取特征,因此计算速度快;相比文献[12]和[14],我们的方法多了一步稠密轨迹提取,该过程约占总计算的10%,但由于我们只是提取稠密轨迹附近的特征,那些包含少量运动信息的图像区域并未计算,所以总的计算时间并未显著提高.endprint
6 結 论
结合堆积去噪编码器和改进的稠密轨迹,提出了一种基于深度学习特征的异常行为检测方法.首先,利用堆积去噪编码器沿着稠密轨迹提取深度外观特征和深度运动特征;然后,为了提高特征的分类能力,利用加权相关性方法对这二种特征进行融合;最后,采用稀疏重建进行异常行为检测.为了验证文中方法的有效性,在公共数据库CAVIAR和BOSS上对文中方法进行了测试,并与其它几种方法进行了对比,结果表明,文中方法具有更高的检测率和较低的计算复杂度.
参考文献
[1] JUNEJO I N.Using dynamic Bayesian network for scene modeling and anomaly detection[J].Signal Image and Video Processing,2010,4(1):1-10.
[2] YANG W Q,GAO Y ,CAO L B. TRASMIL:A local anomaly detection framework based on trajectory segmentation and multi-instance learning[J]. Computer Vision and Image Understanding,2013,117(10):1273-1286.
[3] LI C,HAN Z,YE Q M,et al. Visual abnormal behavior detection based on trajectory sparse reconstruction analysis[J]. Neurocomputing,2013,119(6):94-100.
[4] MO X,MONGAV,BALA R,et al. Adaptive sparse representations for video anomaly detection[J]. IEEE Transactions on Circuits and Systems for Video Technology,2014,24(4):631-645.
[5] KANG K,LIU W B ,XONG W W. Motion pattern study and analysis from video monitoring trajectory [J]. IEICE Transactions on Information and Systems,2014,97( 6):1574-1578.
[6] SALIGRAMA V,CHEN Z. Video anomaly detection based on local statistical aggregates[C]// IEEE Computer Vision and Pattern Recognition. Providence:IEEE,2012:2112-2119.
[7] NALLAIVAROTHAYAN H,FOOKES C,DENMAN S. An MRF based abnormal event detection approach using motion and appearance features[C]// IEEE International Conference on Advanced Video and Signal based Surveillance. Seoul:IEEE,2014:343-348.
[8] WANG Q, MA Q ,LUO C H,et al. Hybrid histogram of oriented optical flow for abnormal behavior detection in crowd scenes[J]. International Journal of Pattern Recognition and Artificial Intelligence,2016,30(2):1-14
[9] ZHANG Y ,LU H C,ZHANG L H,et al. Combining motion and appearance cues for anomaly detection[J].Pattern Recognition,2016,51(C):443-452.
[10]MEHRAN R,OYAMA A,SHAH M. Abnormal crowd behavior detection using social force model[C]//IEEE Conference on Computer Vision & Pattern Recognition. Miami Beach:IEEE Comp Soc,2009:935-942.
[11]WANG H,SCHMID C. Action recognition with improved trajectories[C]//IEEE International Conference on Computer Vision.Sydney,Australia:IEEE Comp Soc,2013:3551-3558.
[12]XU D,RICCI E. Learning deep representations of appearance and motion for anomalous event detection[C]//British Machine Vision Conference. Swansea:Spring,2015:1-12.
[13]ERFANI S M,RAJASEGARAR S,KARUNASEKERA S,et al . High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning[J]. Pattern Recognition,2016,58(C):121-134.endprint
[14]ZHOU S F,SHEN W,ZENG D,et al. Spatial- temporal convolutional neural networks for anomaly detection and localization in crowded scenes[J]. Signal Processing -Image Communication,2016,47:358- 368.
[15]FANG Z,FEI F,FANG Y. Abnormal event detection in crowded scenes based on deep learning [J]. Multimedia Tools and Applications,2016,75(22):14617-14639.
[16]HU X,HU S Q,HUANG Y P,et al. Video anomaly detection using deep incremental slow feature analysis network[J]. IET Computer Vision,2016,10(4):258-267.
[17]ZHU F,SHAO L,XIE J,et al. From handcrafted to learned representtations for human action recognition:A survey[J]. Image and Vision Computing,2016,55(1):42-52.
[18]VINCENT P,LAROCHELLE H,LAJPIE I,et al. Stacked denoising autoencoders:Learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research,2010,11(12):3371-3408.
[19]CONG Y,YUAN,LIU J.Sparse reconstruction cost for abnormal event detection[C]// IEEE Computer Vision and Pattern Recognition. Colorado Springs:IEEE,2011,3449-3456.
[20]陳炳权,刘宏立. 基于稀疏分解的分块图像压缩编码算法[J]. 湖南大学学报:自然科学版,2014,41(2):95-101.
CHEN Bingquan,LIU Hongli. Block compressed image coding based on sparse decomposition[J]. Journal of Hunan University:Natural Sciences,2014,41(2):95-101.(In Chinese)
[21]NESTEROV Y. Gradient methods for minimizing composite objective function[J].Mathematical Programming,2013,140(1):125-161.endprint
猜你喜欢
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年23期)2017-01-12
计算技术与自动化(2016年4期)2017-01-11
无线互联科技(2016年13期)2017-01-10
科技传播(2016年19期)2016-12-27
新媒体研究(2016年21期)2016-12-19
电脑知识与技术(2016年25期)2016-11-16
