
软件缺陷预测中基于Wrapper的特征选择方法*
2017-11-17 06:39常瑞花沈晓卫
火力与指挥控制 2017年10期
常瑞花,沈晓卫
(1.武警工程大学科研部,西安 710086;2.火箭军工程大学,西安 710025)
软件缺陷预测中基于Wrapper的特征选择方法*
常瑞花1,沈晓卫2
(1.武警工程大学科研部,西安 710086;2.火箭军工程大学,西安 710025)
特征选择是提高软件缺陷预测精度的关键步骤之一。传统的软件缺陷预测过程主要基于Filter方式进行特征选择,基于Wrapper特征选择方法的研究还处于起步阶段。为了进一步研究Wrapper式特征选择方法在软件缺陷预测中的应用情况,将特征选择和缺陷预测过程相融合,结合不同的评价指标,设计了8种基于Wrapper式特征选择的缺陷预测方法。在这些方法中,首先选择4种常用的缺陷预测算法分别作为内部与外部分类器,然后在AUC和F-measure指标下选择特征子集,在AUC指标下评估预测结果。仿真结果表明,内部分类器和外部分类器均选择为RF时,软件缺陷预测精度最佳,NB次之,但是RF耗费时间较多,综合考虑精度与效率,推荐内外分类器均采用NB算法。
软件缺陷预测,特征选择,Wrapper,度量元
0 引言
软件密集型装备,例如航空航天系统中,软件所占比例日益增加,系统的可靠性愈来愈依赖于其采用软件的可靠性。为提高系统的可靠性,软件缺陷预测已成为软件工程数据挖掘领域中热点研究内容之一[1],学者们利用统计学、机器学习等技术提出了大量的软件缺陷预测模型[2-6]。研究表明,软件缺陷预测模型的有效性不仅依靠算法而且依赖于度量元数据的质量[7],无关特征与冗余特征可能对预测模型产生弱化效果,对度量元数据进行降维,去掉原始数据中与类别不相关和多余特征,可以大大提高软件缺陷预测模型的性能[8]。软件度量元数据的特征选择已成为构建软件缺陷预测模型不可或缺的部分,本文对此展开研究。
1 相关工作
特征选择指的是从D维的原始特征集F中选择一个d维子集,该子集在原始特征集F所有维数为d的子集中使某个准则函数J最优[9]。特征选择问题是NP难问题[10]。按照与后续分类算法的结合方式可将其分为 Filter、Wrapper两类[11]。目前,特征选择技术在软件缺陷预测中的应用研究还十分有限,文献[12]提出一种可容忍噪声的特征选择框架,该框架首先利用聚类分析,将原始特征划分到指定的簇中,然后设计了3种启发式的特征选择策略。文献[13]对比分析3种基于Filter和Wrapper的特征选择方法,结果表明Wrapper优于Filter方法,但计算成本较大。Guo等人[14]研究发现无关特征对随机森林的预测效果影响较大,使用随机森林对特征进行排序时,发现前5个特征的预测效果和使用21个特征进行预测的效果相当。Gao等人[15]在一个大型通信系统上进行仿真实验,结果表明移除85%的全部特征后,预测准确率没有降低,反而提升,同时发现各种过滤式方法的预测效果类似,没有显著性差异。Wang等人[16]认为单个特征选择方法不稳定,他们将多个特征选择方法进行综合以获得稳定的特征集合,研究了18种特征排序方法,对这18种方法进行组合,共生成17种集成方案,实验结果表明随着特征选择方法集成数目的增加,缺陷预测性能开始提升;在集成2~4个特征选择方法时,效果最佳;随着集成数量的增加,预测效果反而开始下降。Menzies等人[17]使用信息增益对特征进行排序,他们的结论和Guo[14]相似。Rodriguez等人[18]使用3种过滤式和2种封装式特征选择方法在5组软件工程数据集上进行了研究,结果表明封装式方法的预测效果优于过滤式方法,但封装式方法计算开销高,实用性差。Wang[19]等人通过仿真实验也发现,只需要3个软件度量元特征就能达到软件缺陷预测效果,因为对于每一类特征,除了基本特征是从源代码中直接抽取外,其他特征均是由基本特征计算得到。
2 基于Wrapper的特征选择方法与实验设计
2.1 基于Wrapper的特征选择方法
封装式(Wrapper)特征选择方法将分类器与特征选择集成起来,利用分类器的结果对特征子集好坏进行评价。封装式特征选择的过程如图1所示。

图1 基于Wrapper的特征选择方法框架
由图1可以看出,封装式特征选择方法的性能主要受3方面的影响,分别是:①最优特征子集的搜索方式;②学习(分类)器;③对已选择特征子集的评估。与过滤式特征选择算法不同,该方法考虑具体的分类学习算法,为了便于区分,本文将与特征选择过程集成的学习器称为内部学习器,特征选择后的分类器称为外部学习器。内部学习器主要进行特征子集的评判,外部的学习器主要实现软件缺陷的预测。
为了进一步分析封装式特征选择方法在软件缺陷预测领域中的应用情况,本文分别从上述3方面出发,设计了多个Wrapper式特征学习器,并在3组航空航天软件数据上进行仿真实验。
2.2 内部与外部分类器设计
2.2.1 朴素贝叶斯学习器(NB)
朴素贝叶斯算法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法,该算法中对于给定的训练数据集,首先基于特征条件独立假设,学习输入/输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。朴素贝叶斯算法实现简单,模型训练与预测的效率都很高,是软件缺陷预测过程中常用的一种基准算法。
2.2.2 决策树学习器(C4.5)
决策树(Decision Tree)是众多的分类模型中,应用最广泛的分类算法之一,其通过构造树来解决分类问题。本文选择C4.5算法生成特征决策树。首先利用训练数据集来构造决策树,一旦树建立起来,就可为未知样本产生一个分类。决策树具有便于使用、高效、规则易于解释等特点。
2.2.3 支持向量机学习器(SVM)
支持向量机(Support Vector Machine,SVM)是借助最优化方法解决机器学习问题的新工具,最初由V.Vapnik等人在1995年首先提出,近几年来在其理论研究和算法实现等方面都取得了很大的进展,开始成为克服“维数灾难”和过学习等困难强有力的手段。根据Vapnik&Chervonenkis的统计学习理论,如果数据服从某个(固定但未知的)分布,要使机器的实际输出与理想输出之间的偏差尽可能小,则机器应遵循结构风险最小(Structural Risk Minimization,SRM)原则,而不是经验风险最小化原则,通俗地说就是应当使错误概率的上界最小化。与传统的人工神经网络相比,SVM具有结构简单且泛化能力高等特点。
2.2.4 随机森林学习器(RF)
随机森林学习算法(Random Forest,RF)通过训练生成多个决策树模型,然后综合利用多个决策树进行分类。对于每个新的测试样例,RF综合多个决策树的分类结果作为最终的分类结果。在随机森林中,无需交叉验证来评价其分类的准确性,随机森林自带OOB(Out-Of-Bag)错误估计,OOB被证明是无偏的。
2.3 评价指标
为了对特征子集以及预测结果进行评价,本文在混淆矩阵的基础上,构造了软件缺陷预测领域常用的评价指标,分别是F-measure和AUC。
2.3.1 混淆矩阵
下面首先给出二维混淆矩阵,如表1所示。

表1 二维混淆矩阵
2.3.2 F-measure
基于表1所示的二维混淆矩阵,下面给出F-measure的计算公式:
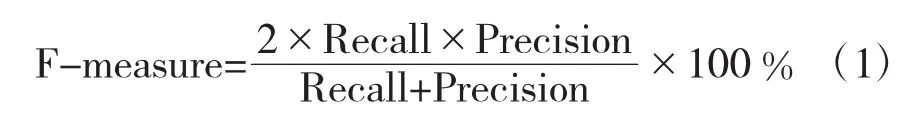
2.3.3 AUC
AUC(Area Under roc Curve)是一种用来度量分类模型好坏的一个标准,在软件缺陷预测中得到了广泛的使用。AUC主要计算ROC曲线下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了算法较好的性能。其中,ROC曲线的横纵坐标分别由PD、PF表示,如式(2)和式(3)所示。
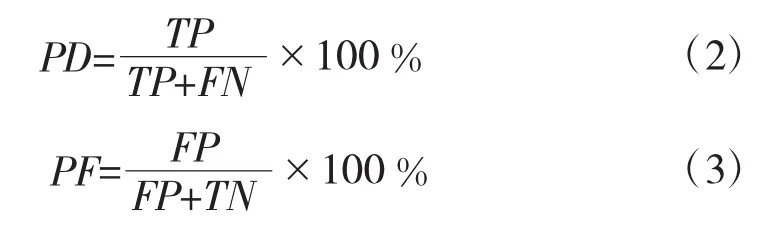
2.4 搜索方式
特征选择方法依据特征子集搜索策略可分为完全搜索、启发式搜索和随机搜索3类。本文选择GreedyStepwise(向前或向后的单步搜索)搜索方式。它由一个空集开始正向处理或从全集开始反向搜索,一旦加入或删除最佳剩余属性导致评估度量下降时,它能够及时终止。
2.5 实验数据
为了进一步验证上述多个特征选择方法的有效性,利用航空航天局NASA MDP数据库中的3组数据集进行仿真实验,数据描述如表2所示。本仿真实验中使用的表示软件特征的度量元主要包括Line of Code度量元,McCabe度量元,Halstead基本度量元及其扩展度量元。

表2 缺陷数据集
2.6 实验设计
下面给出基于Wrapper特征选择算法的仿真实验设计图,如图2所示。
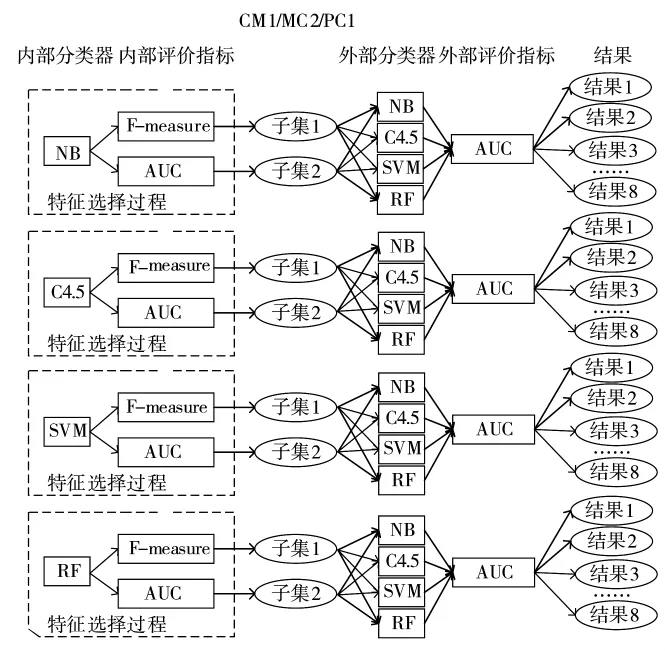
图2 基于Wrapper的特征选择设计
以CM1数据为例,由图2可以看出:①特征选择过程,使用了4种不同的内部分类器以及2种不同的评价指标,分别得到8组特征子集;②在上述特征选择的基础上,进行软件缺陷预测,主要使用了4种不同的外部分类器以及AUC评价指标,得到32组预测结果。
3 仿真结果与分析
3.1 特征选择过程耗时分析
根据上述的实验设计,不同的内部分类器、不同的内部评价指标组合后,可以分别得到8种特征选择算法。本文实验环境为:Intel(R)Core(TM)i5-3210M CPU,2.50GHz,12GDDR 内存,Windows 7操作系统,MatLab(R2014a)和 Weka3.6.2。为了更准确地衡量算法的性能,给出了上述算法10次独立运行后仿真结果的平均值。利用Weka软件中自带的4种分类算法进行仿真实验,参数设置为默认值。下面首先对不同的特征选择方法的运行时间进行对比和分析,仿真结果如表3所示。

表3 不同特征选择算法运行时间
由表3可以看出,首先对于CM1数据而言,NB-F-measure特征选择方法所用时间最短,RF-AUC特征选择方法所用时间最长,达到了720 s。对于MC2数据而言,NB-F-measure与C4.5-F-measure两种特征选择方法所用时间一样均为7 s,RF-AUC特征选择方法所用时间最长,达到了843 s。对于PC1数据而言,NB-F-measure特征选择方法所用时间最短约5 s,RF-AUC特征选择方法所用时间最长,达到了1 982 s。综上可以看出:①F-measure评价指标下所用的时间往往小于AUC评价指标下耗费的时间;②NB分类器在两种评价指标下所用的时间与其他分类算法相比,均是最短的,而且在CM1、MC2、PC1 3组数据上的结果是类似的;③RF分类器在这3组数据以及两种评价指标下进行特征选择所需的时间均是最多的。
3.2 不同评价指标下的预测结果
为了进一步验证上述不同的特征选择算法对于软件缺陷预测模型的影响性能,下面选择4组不同的外部分类器,在AUC评价指标下,对上述24组特征子集进行仿真验证,仿真结果如表4~表6所示。
由表4可以看出,在AUC的评价指标下,从纵向来看外部分类器RF取得了最佳的预测结果,NB次之。需要说明的是SVM受参数c影响较大。从横向来看,RF-AUC-RF取得了最佳的预测结果,然而,结合表3耗时数据(720 s)看出,最佳的预测结果建立在最长的特征选择时间基础上。因此,综合耗时预测精度,本文推荐NB-F-measure-RF组合。
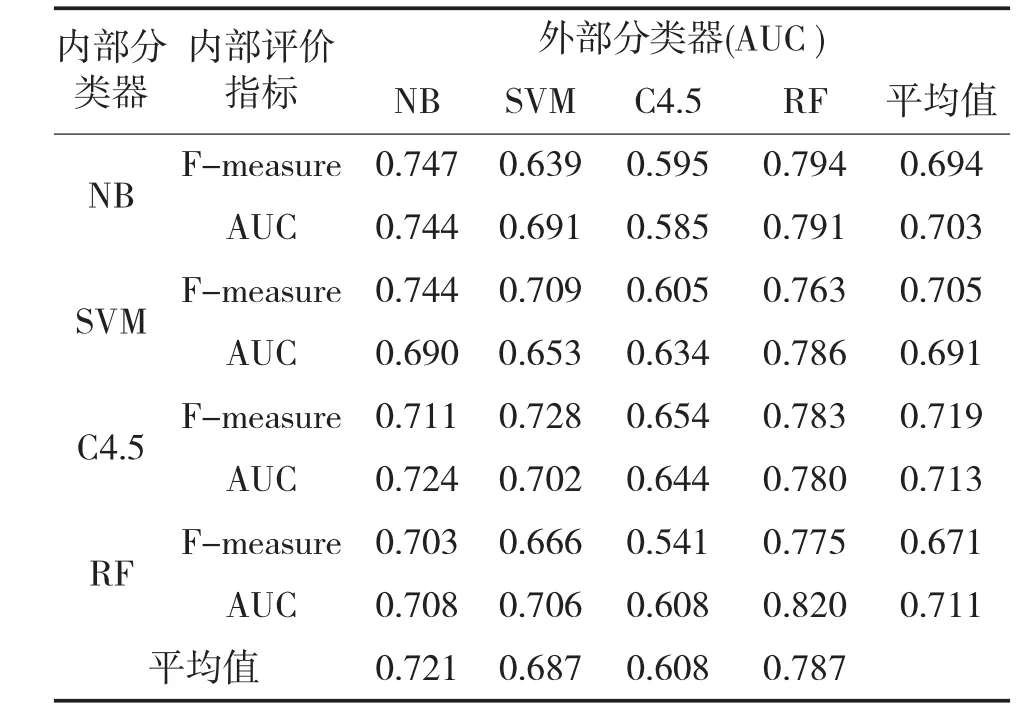
表4 CM1数据预测结果
表5给出了MC2数据在上述8种特征选择方法下的预测结果。

表5 MC2数据预测结果
由表5可以看出,在AUC的评价指标下,首先从横向来看,对于前3种特征选择方法,外部分类器选择NB时,预测结果最佳;对于后5种特征选择算法,外部分类器选择为RF时,预测结果最佳。同时,从横向和纵向所求的平均值,可以看出内部分类器或者外部分类器设置为RF时,AUC预测值均比较高。然而,观察整个表5可以看出取得最佳预测值为C4.5-AUC-RF组合。
另外可以发现,不论内部分类器与评价指标如何选择,外部分类器NB和RF两种分类器的平均预测结果均达到了0.7以上,RF最佳,NB次之。如果结合算法运行时间来考虑,鉴于RF运行时间较长,对于一些效率要求较高的算法,推荐采用内部和外部分类均为NB算法的组合,即NB-AUC-NB。
表6给出了PC1数据在上述8种特征选择方法下的预测结果。
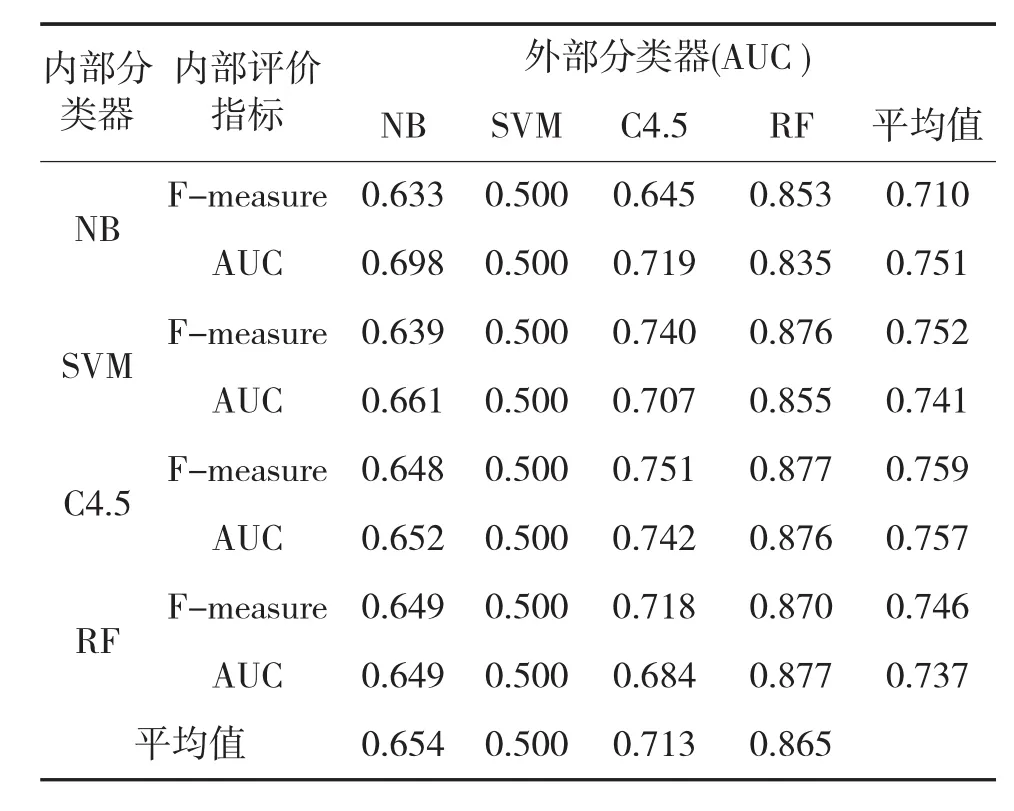
表6 PC1数据预测结果
由表6可以看出对于PC1数据而言,内部分类器与内部评价指标不论如何设计,外部分类器选择为RF算法时,预测性能最佳,尤其在内部分类器也选择为RF时,达到预测的最高值0.877。C4.5分类器次之。
另外一点需要说明的是SVM算法在所有情况下的预测值均为0.5,预测结果比较差。(其所有参数设置为WEKA软件中的默认设置,例如惩罚因子c=1.0)。在SVM算法中,由软间隔非线性分类模型产生的规则化参数(C)和高斯核函数的参数高斯宽度(σ)直接影响着SVM分类的表现性能:过高的参数C可能导致SVM的分类效果过拟合,过低的参数C可能影响SVM对线性不可分数据的分类性能。
4 结论
综上,通过上述3组仿真数据可以看出,随机森林预测结果最佳,但耗费时间最多;支持向量机算法受参数c影响,在默认参数下,预测结果较差。在综合考虑预测时间和精度的条件下,推荐具有坚实数学基础和稳定分类效率的朴素贝叶斯算法,该算法所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。然而其假设属性之间是相互独立的,这个假设在实际应用中往往是不成立的,这给朴素贝叶斯模型的正确分类带来了一定影响,下一步将对此展开研究。
[1]郁抒思,周水庚,关佶红.软件工程数据挖掘研究进展[J].计算机科学与探索,2012,6(1):1-31.
[2]王青,伍书剑,李明树.软件缺陷预测技术[J].软件学报,2008,19(7):1565-1580.
[3]陈翔,顾庆,刘望舒,等.静态软件缺陷预测方法研究[J].软件学报,2016,27(1):1-25.
[4]HALL T,BEECHAM S,BOWES D,et al.A systematic literature review on fault prediction performance in software engineering [J].IEEE Transactions on Software Engineering.2012,38(6):1276-1304.
[5]MICHAEL S J,ISLAM M Z.Software defect prediction using a cost sensitive decision forest and voting,and a potential solution to the class imbalance problem [J].Information Systems,2015,51:62-71.
[6]ZTüRK M M,CAVUSOGLU U,ZENGIN A.A novel defect prediction method for web pages using k-means++[J].Expert Systems with Application,2015,42(19):6496-6506.
[7]CHEN J Q,LIU S L,CHENG X,et al.Empirical studies on feature selection forsoftware faultprediction[C]//In Proceedings ofthe 5th Asia-Pacific Symposium on Internetware.ACM New York,NY,USA,2013.
[8]GAO K,KHOSHGOFTAAR T M,WANG H.An empirical investigation of filter attribute selection techniques for software quality classification[C]//In Proceedings of the 10th IEEE International Conference on Information Reuse and Integration.Las Vegas,Nevada,2009.
[9]NARENDRA P M,FUKUNAGA K.A branch and bound algorithm for feature subset selection[J].IEEE Transactions on Computers,1977,26(9):917-922.
[10]AMALDI E,KANN V.On the approximability of minimizing nonzero variables or unsatisfied relations in linear systems[J].Theoretical Computer Science,1998,209(1-2):237-260.
[11]KOHAVI R,JOHN G H.Wrapper for feature subset selection[J].Artificial Intelligence,1997,97(1):273-324.
[12]刘望舒.一种面向软件缺陷预测的可容忍噪声的特征选择框架[J].计算机学报,2016,33(39):1-16.
[13]RODRIGUEZ D,RUIZ R,CUADRADO-GALLEGO J,et al.Detecting fault modules applying feature selection to classi-fiers[C]//In Proceedings of 8th IEEE International Conference on Information Reuse and Integration,Las Vegas,Nevada,2007.
[14]GUO L,MA Y,CUKIC B,et al.Robust prediction of fault-proneness by random forests[C]//In Proceedings of International Symposium on Software Reliability Engineering(ISSRE),IEEE,2004:417-428.
[15]GAO K,KHOSHGOFTAAR T M,WANG H.Choosing software metrics for defect prediction:an investigation on feature selection techniques [J].Software:Practice and Experience,2011,41(5):579-606.
[16]WANG H,KHOSHGOFTAAR T M,NAPOLITANO A.A
comparative study of censeble feature selection techniques for software defect prediction [C]//In:Proceeding of the International Conference on Machine Learning and Applications(ICMLA),IEEE,2010:135-140.
[17]MENZIES T,GREENWALD J,FRANK A.Data mining static code attributes to learn defect predictors[J].IEEE Transactions on Software Engineering,2007,33(1):2-13.
[18]RODRIGUEZ D,RUIZ R,CUADRADO G J,et al.Detecting fault modules applying feature selection to classifiers[C]//In Proceedings of the International Conference on Information Reuse and Integration,IEEE,2007.
[19]WANG H,KHOSHGOFTAAR T M,SELIYA N.How many softwaremetricsshouldbeselectedfordefectprediction[C]//Proceedings of the Twenty-Fourth International Florida Artificial Intelligence Research Society Conference,AAAI.Palm Beach,Florida,USA,2011:69-74.
Feature Selection Based on Wrapper During Software Defect Prediction
CHANG Rui-hua1,SHEN Xiao-wei2
(1.Research Department of Armed Police Engineering University,Xi’an 710086,China;2.University of Rocket Engineering,Xi’an 710025,China)
Feature selection is one of the key steps to improve prediction accuracy of software defects.In the traditional fields of software defect prediction,feature selection based on filter is more often used than wrapper.In order to further investigate how to use feature selection based wrapper in software defect prediction application,eight feature selection methods based on wrapper with combining the process of prediction and selection is designed.Firstly,four common defect prediction algorithms are used as internal and external classifiers.Then AUC and F-measure are used to assess the performance of feature selection methods.Simulation results show that the internal and external classifiers select RF,software defect prediction accuracy is the best,and NB is the second.But because of RF is more timeconsuming,NB algorithm is recommended considering the precision and efficiency.
software defect prediction,feature selection,wrapper,metrics
1002-0640(2017)10-0059-05
TP311.53
A
10.3969/j.issn.1002-0640.2017.10.013
2016-08-15
2016-10-25
国家自然科学基金(51503224);陕西省自然科学基金(2015JQ6224);武警工程大学基础研究基金(WJY201602);大学军事理论研究基金资助项目(JLX201680)
常瑞花(1982- ),女,山西清徐人,博士,工程师。研究方向:机器学习,模式识别。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
南京理工大学学报(2021年4期)2021-09-15
数学小灵通(1-2年级)(2021年4期)2021-06-09
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
小型微型计算机系统(2018年5期)2018-07-04
计算机研究与发展(2018年5期)2018-05-28
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
少儿科学周刊·儿童版(2017年3期)2017-06-29
