
MASNUM 海浪模式的代码现代化优化
2017-11-14 07:48杨晓丹宋振亚刘海行尹训强
海洋科学进展 2017年4期
杨晓丹,宋振亚,周 姗,刘海行,尹训强
(1.中国海洋大学海洋与大气学院,山东青岛266010;2.青岛海洋科学与技术国家实验室区域海洋动力学与数值模拟功能实验室,山东青岛266237;3.国家海洋局第一海洋研究所,山东青岛266061;4.英特尔亚太研发有限公司,上海200241)
MASNUM 海浪模式的代码现代化优化
杨晓丹1,2,3,宋振亚2,3*,周 姗4,刘海行2,3,尹训强2,3
(1.中国海洋大学海洋与大气学院,山东青岛266010;2.青岛海洋科学与技术国家实验室区域海洋动力学与数值模拟功能实验室,山东青岛266237;3.国家海洋局第一海洋研究所,山东青岛266061;4.英特尔亚太研发有限公司,上海200241)
海洋数值模式当前已经成为海洋研究和预测的核心工具,其高分辨率。多物理过程的发展趋势对数值模式计算速度也提出了越来越高的要求。为了使得海洋数值模式更好的适应计算机基础架构,充分发挥现代化计算机体系的计算特点,提高计算效率,本文提出了一种简单易行且有效的代码现代化优化方案,并以MASNUM海浪模式为例进行了测试。首先利用诊断工具Intel Vtune Amplifier XE和Intel Trace Analyzer Collector,对模式的性能和负载均衡性进行了分析;之后,针对热点函数,在单节点上制定了4个优化步骤,包括编译器选项优化,串行和标量优化,向量化和Open MP并行优化。结果表明,经过优化后,单节点内模式的计算速度可以提高1.95倍,多节点的模式强扩展性呈线性。这表明本文提出的代码现代化方案是一种行之有效的优化方法。
Intel分析工具;代码现代化优化;海洋数值模式;海浪模式;高性能计算
海洋数值模拟是基于一定的物理定律,以电子计算机为手段,通过数值计算对特定的海洋中物理或者工程问题进行研究的方法。海洋数值模拟的出现使得海洋科学成为一个可重复、可实验的科学。自20世纪70年代Manabe和Bryan[1]的开创性工作以来,随着地球科学的发展,当前海洋数值模拟正朝着更高分辨率、更多物理过程和更快的计算速度发展[2-4]。通常来说,分辨率每提高1倍,计算量将变为原来的8~10倍;同时随着分辨率的提高,新的参数化方案也需要多次数值实验进行调整和验证,这都对计算速度提出了更高的要求。充分利用现有计算资源提高计算效率已经成为海洋数值模拟发展的一个必要条件。
代码的现代化优化是提高高性能数值模拟性能的一种有效途径。它通过对高性能应用软件的设计进行优化,以充分利用和发挥现代计算机的高性能,如多核处理器,超线程,大缓存,高带宽的通信结构和高速I/O功能等。代码现代化方法包括5个部分:合理使用优化工具和库,串行和标量优化,向量化,并行优化,从多核应用到众核。这些优化过程相互影响,共同提高应用程序的性能[5]。
MASNUM海浪模式是20世纪90年代初海洋环境科学与数值模拟国家海洋局重点实验室与国际同步自主发展的第三代海浪数值模式。随着高性能计算机的发展,经过二十余年,MASNUM海浪模式也已经从串行版本发展到MPI(Message Passing Interface)并行版本[6-7],尤其最近发展的基于非规则类矩形网格剖分方案的高效并行版本,具有良好的扩展性和负载均衡性[8]。然而当前MASNUM海浪模式的性能提高都是基于并行层面,在模式编程中未充分考虑代码的现代化,如变量是否存在重复计算、多重循环的嵌套顺序等。以MASNUM海浪模式作为例子,研究如何使用代码现代化方法提高海洋数值模式的计算性能,非常具有代表性和必要性。
为了充分利用和发挥现代高性能计算机的性能,进一步促进海洋数值模拟的发展,本文尝试以MASNUM海浪模式为例,提出了海洋数值模式代码现代化优化的方案,并在此基础上对代码进行现代化优化,为今后海洋环境数值模拟的研究和发展提供参考和基础。
1 模式代码现代化优化方案
为了充分提高代码现代化优化的效果,我们设计了数值模式代码现代化优化的策略(图1)。首先,使用Intel分析工具对数值模式的性能以及负载均衡性进行分析;其次,针对模式存在的问题,在编译选项优化、串行和标量优化、向量化优化和并行优化四个层面上制定优化策略,以提高模式在单节点的性能;最后,将优化后的模式从单节点扩展到多节点,测试和优化其扩展性。通过以上3个步骤的反复,最大限度地达到代码现代化优化的效果。具体如图1所示。

图1 数值模式代码现代化优化策略Fig.1 Strategy for code optimization of numerical model
1.1 性能分析
为了使得模式的优化更有针对性,首先采用Intel分析工具对模式的计算和并行性能进行分析,主要包括热点函数分析和负载均衡分析。利用Intel Vtune Amplifier XE可以得到每个函数的计算时间,根据计算时间可以定位出热点函数(模式中耗时最长的函数),之后对这个热点函数进行重点优化。利用Intel Trace Analyzer and Collector(ITAC)可以通过可视化界面查看程序MPI的并行计算和不同进程间的通信情况。若模式负载不均衡,则可以通过更改模式并行方式或重新分配每个进程的任务,使其实现负载均衡。
1.2 单节点代码现代化优化策略
在性能分析的基础上,在编译器选项、串行和标量、向量化和并行优化四个层面对模式在单节点内进行优化。
1.2.1 编译器选项
编译器提供了不同编译器选项,选用合适的编译选项能够有效提高模式计算性能。在选择编译选项时,为了最大限度地发挥处理器硬件的优势,首先应该保证指令由处理器所支持的最高指令集生成,然后在此基础上再根据程序和系统特点选用其他的编译选项。
1.2.2 串行和标量优化
在对模式进行向量化和并行化优化等进一步优化前,应该确保代码使用最少的计算量和合适的精度获得正确的结果,这一步的优化称为串行和标量优化。减少重复性计算是其中一种优化方法。重复计算可以从循环中移出,然后将计算的结果存储到临时的常数或矩阵中。另外,优化方法还包括选择适当的浮点精度,避免或减少条件分支等,这需要根据代码存在的问题进行优化。
1.2.3 向量化
向量化计算是一种特殊的并行计算的方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或一批指令,或者说把指令应用于一个数组/向量。向量化的处理方式是现代计算机的一个特点,使用向量化能够有效提高应用软件的计算性能,当前无论硬件还是软件上,都提供了向量化的支持。在使用编译器编译时,通常默认优化选项中都包括了自动向量化的功能,即若代码没有违反向量化的规则,那么它将被自动向量化。但自动向量化要求较为严格,如循环中有数据依赖、循环对内存访问不连续等情况时,就会无法自动向量化,此时需要对代码进行分析和修改。
1.2.4 MPI/Open MP并行化
当前MPI和Open MP混合并行方法已经在多个海洋和大气环流模式中得到了应用[9-11]。Open MP可以实现共享内存层面的任务并行,它是一种简单有效的并行方式[13-14]。在使用MPI并行时,随着模式进程数的增加,每个分区之间的数据交换量成倍增加,而使用MPI和Open MP混合并行方法,可以根据实际需要分别定义MPI进程数和每个MPI进程使用的Open MP线程数。这种混合并行方法通过减少进程数,可以减小进程间通信开销,同时打开超线程又能充分利用计算资源,使得并行结构更加合理[15],有效提高计算效率。对于多节点的集群来说,MPI和Open MP的组合提供了一个有效的并行策略。
2 实验设计
2.1 模式简介
MASNUM海浪模式是基于Yuan等[16]建立的LAGFD-WAM区域海浪模式,后由杨永增等[18]发展成球坐标系下的全球海浪波数谱模式。它在数值计算上采用了复杂特征线嵌入计算格式,该方式考虑了波能包沿特征线变化的传播特征,其物理意义更为合理,并能够最大限度的放宽积分时间步长的限制。在物理空间和波数空间上,网格点的分布分别采用了与经纬度线平行的梯形格点分布和基于极坐标的网格。MASNUM海浪模式波数谱计算中主要包含传播函数(propagate)和源函数(implsch)两部分。在源函数(implsch)中,水平相邻点之间无数据交换,只在波数空间上进行计算,而在传播函数(propagate)中,计算与相邻点相关,需进行数据之间的交换。本研究所使用的MASNUM海浪模式版本是由赵伟等[8]发展的并行版本,该模式版本是基于Fortran90语言编写,只使用了MPI并行方法,地理空间采用非规则类矩形网格划分,保证了各分区计算量达到近绝对均衡,为了更方便的进行进程间数据交换,将两维的地理空间分布转化为一维序列。
2.2 测试环境及实验设置
实验测试环境见表1。测试平台共有7个节点,每个节点具有2颗18核心的Intel Xeon E5 2699 v3处理器,一个节点内具有36个物理核心和72个逻辑核心,节点间通过InfiniBand QDR进行互联。本研究中MASNUM海浪模式的空间分辨率为0.2°×0.2°(1 800×701网格数),波空间中的波数和波向分别为25和12。为了保证模式计算时间不少于5 min,在单节点内测试时,模式积分步数为240个时间步长;在扩展性测试时,模式积分步数为1 680个时间步长。需要说明的一点,为了减小I/O对扩展性的影响,本研究中的测试是针对模式计算性能的无I/O测试,文中加速性能分析时的测试时间为整个模式运行的墙钟时间。

表1 测试环境Table 1 Testing environment
3 MASNUM代码现代化优化
3.1 性能分析
3.1.1 负载均衡分析
首先,使用ITAC进行了MASNUM海浪模式MPI并行的负载均衡分析。从结果来看,本研究中使用的MASNUM海浪模式版本在空间上采用非规则类矩形网格剖分方法,使得该模式在每个进程分配的计算任务几乎相同,基本达到了负载平衡(图2),这也与赵伟等[8]的结论相一致。因此,下面的优化将主要针对Intel VTune检测出的热点函数进行优化,提高其计算效率,减少其计算时间。

图2 MASNUM海浪模式负载均衡性(单节点36个进程)Fig.2 Load balance of MASNUM wave model(36 processes on a single node)
3.1.2 热点函数分析
其次,采用Intel VTune进行了MASNUM海浪模式热点函数的分析。根据Intel VTune统计得到的模式中每个函数的计算时间(图3),可以很容易地找到耗时最长的热点函数为海浪模式的源函数部分(implsch),因此本研究将重点对此函数进行优化。
3.2 单节点代码现代化优化
为了做到优化的准确高效,需要首先分析热点函数的特征。在本研究中,热点函数implsch中,多个表达式在除法运算上耗时较长;在循环内存在重复计算;循环未全部成功自动向量化;在并行方面,模式不包括Open MP并行,这可能会影响模式在集群上的扩展性。因此,在制定单节点代码现代化优化策略时,主要包括选择合适的编译器选项、减少重复性计算、改进代码结构提高向量化比例和效率以及Open MP并行化。

图3 单节点测试实验中MASNUM模式优化前(红)、后(蓝)函数的运算时间Fig.3 Comparison of computation time consumed by different functions before(red)and after(blue)the MASNUM model is optimized on a single node
3.2.1 编译器选项优化
本研究所使用的处理器最高支持AVX 2指令集,因此为了最大限度地发挥处理器硬件的优势,首先选取了“-xCORE-AVX2”作为编译优化选项;同时为了优化热点函数内的浮点数除法运算,增添了编译优化选项“-noprec-div”进行优化。在添加此编译器选项后,相对于原始性能的加速比可以达到1.59。此外,比较了使用-O3和-O2优化选项后模式的计算速度,发现二者基本一致。因此最终选用了编译器默认的-O2优化选项。
3.2.2 串行和标量优化
以下是热点函数中重复性计算优化的例子:
在此循环(图4a黄色)中,costh和sinth不随着idx的变化而变化。因此对它们的计算可以从循环中移出,计算的结果被保存在两个新的数组precos和presin中。然后再将这两个数组的结果传回到循环中进行计算(图4b黄色)。
串行和标量优化后,减少重复计算使得模式计算效率比以前提高了6%。当我们检查由Intel Vtune生成的函数时间分布(图3)时,发现三角函数sin和cos的时间成本降低了93%。

图4 重复性计算优化前后对比Fig.4 Comparison of codes before and after the repetitive computation is reduced
3.2.3 向量化
向量化在同一时间可以将单指令应用在多个数据上,它对提高代码计算效率起着重要的作用。由于热点函数的物理过程是非常复杂的,因此我们不能完全消除方程间的依赖关系。图5a是循环没有向量化成功的例子,其原因是两个红色表达式之间存在可能依赖关系。

图5 向量化优化前(a)后(b,c)对比Fig.5 Comparison of codes before(a)and after(b,c)optimization of vectorization
在k方向的循环,方程之间没有依赖性,然而,向量化只能对最内层循环起作用。为了使向量化成功,我们交换了mr,j,k三重循环的循环顺序(图5a和5b黄色)。此外,如果内存访问不连续时,数据的读取耗时较长,因此向量化一般情况无法实现或者效果不好。在FORTRAN语言中,数组元素的读取顺序是列优先。由于数组wp的访问已经是连续的,因此可以进行有效的向量化。
通过查看向量化报告,我们发现在不同的行,se变量互相存在依赖性,因为通过计算得出的j11和j12可能是同一个值。一种解决方案是将具有依赖性的部分从循环中移出。我们通过将内循环拆分成两部分后(图5b和5c红色),发现不存在依赖性的部分可以成功地向量化,从优化报告中也可以看出这一点。
将热点函数中可以向量化的部分成功向量化后,模式显示加速比为1.07倍。如果向量化指令变得更宽,比如最新的Intel Xeon Phi支持512位SIMD,向量化后模式性能提升的效果可能会更明显。
3.2.4 Open MP并行
MASNUM海浪模式中热点函数的最外层循环是空间维度的循环,本研究中使用的空间维度已由二维变成一维,使其外层循环次数可以达到25 662,因此Open MP对其性能提高应是非常有效的。图6为MASNUM海浪模式MPI和Open MP的扩展性。从中可以看出,在单节点内MPI的扩展性非常好,加速比从2到36个进程几乎呈线性变化(图6红线)。Open MP的扩展性,当线程数小于18时也较好,之后存在一定的下降(图6蓝线)。通过测试发现,当进程数乘以线程数为72,即用满单节点内的逻辑核时,计算效率最高。使用36个进程并打开Open MP超线程,使得海浪模式的性能相对纯MPI 36个进程的性能可提升8%。
由于我们只在热点函数中增加了Open MP并行,因此无法给出该模式混合并行的最佳性能。然而,仅在热点函数中增加Open MP并行也使得模式性能得到了明显的改善,这说明了Open MP是简单且非常有效的并行方式。

图6 单节点内MPI扩展性和一个进程内Open MP的扩展性Fig.6 MPI scalability on single node and Open MP scalability in one process
图7显示了模式在单节点每一步优化后的性能改进,除Open MP优化后使用36个进程2个线程之外,其余过程均只使用36个MPI进程。在针对热点函数implsch进行了4个阶段的优化后,加速比可以达到1.95,大大降低了整体运算时间。其中,热点函数implsch的计算时间由219 s减少到87.86 s(图3),加速比可达到2.49倍。需要说明的是,图7中的加速比性能分析是基于整个模式运行的时间进行比较的,因此加速比性能(1.95倍)相对热点函数加速性能(2.49倍)稍低。这说明Intel Vtune Amplifier对热点函数的分析是准确的,同时我们使用的优化策略也是非常有效的。经过优化后,模式包含3种不同级别的并行化方式:向量化,Open MP和MPI,这也是现代化代码的共同特点。
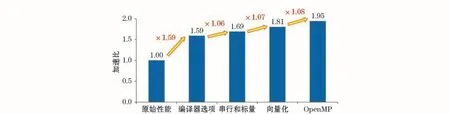
图7 模式在单节点内的优化性能Fig.7 Performance of the optimized model on single node
3.3 多节点扩展性
图8给出了海浪模式优化前后在多个节点上的加速比,与单节点一致,除Open MP优化后每个节点使用36个进程2个线程之外,其余过程均只使用36个MPI进程。从图中可以看出,模式加速比随着核心数目的增加,呈线性增长趋势。252个进程相对于6个进程的理论加速比为42,在经过原始性能优化、编译器选项优化、串行和常量优化、向量化优化以及Open MP优化后,252个进程相对于6个进程实际加速比分别可以达到31.9,29.3,29.3,28.2和29.8。在对模式进行了优化后,加速比略有下降,原因可能是由于所使用的进程数并未减少,进程间数据交换的耗时是固定的,因此计算时间所占的比例相对于各自原始代码偏少。从而代码优化的越好,其计算时间所占的比例越少,而随着进程数的增加,数据交换所占的时间越多,使得模式的加速比相对于原始性能略有降低。

图8 模式优化前后在多节点上的扩展性Fig.8 Scalability of the numerical model before and after optimization on multi nodes
增加Open MP并行后,通过测试,发现当每个节点内MPI进程数为36,Open MP线程数为2时,模式性能达到最优。通过模式原始性能可以看出,由于测试规模较小,模式的扩展性并未遇到瓶颈,因此,超线程对扩展性的提高作用未能发挥出来。又由于每个节点内MPI的扩展性好于Open MP(图6),所以当MPI的进程数达到36时模式整体性能最好。当测试规模达到十万甚至百万核心时,模式性能会存在一定的下降[6],此时利用MPI和Open MP混合并行方式,通过减少进程数,增加线程数,将有利于提高模式的扩展性,这将在今后的工作中进行测试和分析。
4 结 语
在本文中,首先提出了海洋数值模式代码现代化优化的策略和方案,然后以MASNUM海浪模式为例,对该模式进行了代码现代化优化。结果表明,通过对热点函数源函数部分(implsch)不同层面的优化,能够大幅提高MASNUM海浪模式的计算效率。编译器选项可使得模式计算速度提高近1.59倍;串行和标量优化,如减少重复计算,使得计算性能提高了近6%;深入的向量化优化,使其满足Intel编译器自动向量化的规则,模式的计算速度可提高1.07倍;基于Open MP并行的改进,使得模式性能提高约8%。经过以上4个步骤的优化,相对于原模式,在单节点内可以提高计算性能提高1.95倍,节省了近50%的计算资源,同时模式在多个节点内的扩展性也呈线性。值得注意的是,随着对源函数优化的深入和节点数的增多,模式的热点函数也许会发生变化,在进一步大规模并行时需要按照优化步骤重新进行分析和优化。同时,研究结果也表明本研究提出的代码现代化方案是行之有效的,这对其它海洋数值模式的计算性能优化具有非常好的借鉴作用。
在MASNUM海浪模式代码现代化优化实验中,由于测试平台的限制,只进行了MPI/Open MP混合并行方案的并行优化。需要说明的是本研究提出的代码现代化方案应该也适用于当前的异构集群,如GPU集群或众核集群等。从文中分析可以看到,源函数是计算量最大的热点函数,而其在计算中无相邻数据交换的特点非常适合GPU或者MIC等协处理器。因此,下一步还将基于Intel Xeon Phi的架构,将MASNUM海浪模式的热点函数移植到协处理器上提高计算效率,进一步检验本文提出的代码现代化优化方案。
此外,当前针对各种计算程序所做的优化大多都是围绕内存访问效率来进行的,本文提出的代码现代化优化方案是一种相对简单、易行的优化策略,较为容易实现,总体的性价比较高。也正是由于其相对简单易行,因此经过优化后内存访问效率还有可提高的空间,如修改模式计算流程和计算负载均衡控制,使其可以充分利用进程与超线程间的关系,但这些修改会较为复杂,对于普通模式研发人员来说,会较难实现。因此,本文提出的优化方案和实验未涉及这些深入的研究。
[1] MANABE S,BRYAN K.Climate Calculation with a combined ocean-atmosphere model[J].Journal of Atmospheric Sciences,1969,26(4):786-789.
[2] LU J,LIU X H,TENG Y,et al.Theoretical basics of a systematic ecology-sediment-environment dynamical numerical model for coastal areas[J].Advance in Marine Science,2015,33(4):471-483.芦静,刘学海,滕涌,等.近海系统化生态-沉积-环境动力学数值模式——理论基础[J].海洋科学进展,2015,33(4):471-483.
[3] GAO X M,WEI Z X,LV X Q,et al.Accuracy assessment of global ocean tide models in the South China Sea[J].Advance in Marine Science,2014,32(1):1-14.高秀敏,魏泽勋,吕咸青,等.全球大洋潮汐模式在南海的准确度评估[J].海洋科学进展,2014,32(1):1-14.
[4] CUBASCH U,WUEBBLES D,CHEN D,et al.Introduction.In:climate change 2013:in the physical science basis,working group I contribution to the fifth assessment report of the intergovernmental panel on climate change,WMO/UNEP[M].United Kingdom and New York:Cambridge University Press,2013.
[5] PEARCE M.What is code modernization?[EB/OL].(2015-07)[2016-09-01]https:∥software.intel.com/en-us/articles/what-is-codemodernization.
[6] WANG G S,QIAO F L,YANG Y Z.Study on parallel algorithm for m PI-based LAGFD-WAM numerical wave model[J].Advance in Marine Science,2007,25(4):401-407.王关锁,乔方利,杨永增.基于MPI的LAGFD-WAM海浪数值模式并行算法研究[J].海洋科学进展,2007,25(4):401-407.
[7] ZHANG Z Y,ZHOU Y F,LIU L,et al.Performance characterization and efficient parallelization of MASNUM Wave Model[J].Journal of Computer Research and Development,2015,52(4):851-860.张志远,周宇峰,刘利,等.MASNUM海浪模式的性能特点分析与并行优化[J].计算机研究与发展,2015,52(4):851-860.
[8] ZHAO W,SONG Z Y,QIAO F L,et al.High efficient parallel numerical surface wave model based on an irregular quasi-rectangular domain decomposition scheme[J].Science China:Earth Sciences,2014,44(5):1049-1058.赵伟,宋振亚,乔方利,等.基于非规则类矩形剖分的高效并行海浪数值模式[J].中国科学:地球科学,2014,44(5):1049-1058.
[9] SMITH R,DAKOWICZ J,MALONE R.Parallel ocean general circulation modeling[J].Physica D-nonlinear Phenomena,1992,60:38-61.
[10] STEVENS B,GIORGETTA M,ESCH M,et al.Atmospheric component of the MPI-M Earth System Model:ECHAM6[J].Journal of Advances in Modeling Earth Systems,2013,5(2):146-172.
[11] SANNINO G,ARTALE V,LANUCARA P.A hybrid Open MP-MPI parallelization of the Princeton Ocean Model[EB/OL].[2016-09-01]http:∥www.utmea.enea.it/staff/sannino/Papers/ParCo/ParCoPOM.pdf.
[12] COLLINS W D,RASCH P J,BOVILLE B A,et al.Description of the NCAR community atmosphere model(CAM 3.0)[J].National Center for Atmospheric Research Ncar Koha Opencat,2004:tn-464+str(TN-485+STR).
[13] EPICOCO I,MOCAVERO S,ALOISIO G.The NEMO oceanic model:computational performance analysis and optimization[C]∥IEEE International Conference on High PERFORMANCE Computing&Communication,Canada:HPCC,2011:382-388.
[14] ZHANG X,JI Z Z,WANG B.Some study on application of Open MP in mesoscale meteorological model-MM5[J].Climatic and Environmental Research,2001,6(1):84-90.张昕,季仲贞,王斌.Open MP在MM5中尺度模式中的应用试验[J].气候与环境研究,2001,6(1):84-90.
[15] SU M F,EL-KADY I,BADER D A,et al.A Novel FDTD Application Featuring Open MP-MPI hybrid parallelization[EB/OL].[2016-09-01]http:∥www.cc.gatech.edu/fac/bader/papers/FDTD-ICPP2004.pdf.
[16] YUAN Y,HUA F,PAN Z,et al.LAGFD-WAM numerical wave model I.Basic physical model[J].Acta Oceanologica Sinica,1991,10(4):483-488.
[17] YANG Y Z,QIAO F L,ZHAO W,et al.MASNUM ocean wave numerical model in spherical coordinates and its application[J].Haiyang Xuebao,2005(2):1-7.杨永增,乔方利,赵伟,等.球坐标系下MASNUM海浪数值模式的建立及其应用[J].海洋学报,2005(2):1-7.
Code Modernization Optimization of MASNUM Wave Model
YANG Xiao-dan1,2,3,SONG Zhen-ya2,3,ZHOU Shan4,LIU Hai-xing2,3,YIN Xun-qiang2,3
(1.College of Oceanic and Atmospheric Sciences,Ocean University of China,Qingdao 266010,China;2.Laboratory for Regional Oceanography and Numerical Modeling,Qingdao National Laboratory for Marine Science and Technology,Qingdao 266237,China;3.The First Institute of Oceanography,SOA,Qingdao 266061,China;4.Asia-Pacific Research&Development Ltd,Intel,Shanghai 200241,China)
Numerical model has become one of key tools for ocean research and prediction,and the demand for increasing the computational efficiency is now necessary and urgent.In order to make full use of the modern computer architecture and improve ocean model's computational efficiency,a code optimization scheme,which is demonstrated by using MASNUM wave model as an example,was proposed in this paper.Firstly,Intel Vtune Amplifier XE and Intel Trace Analyzer Collector were used to evaluate the performance and load balancing of the MASNUM wave model.Then four steps of optimization,which are compiler options,serial and scalar optimization,vectorization,and MPI/Open MP parallelization,are designed for hotspot function located by Intel Vtune Amplifier XE.The result shows that after optimization,the computational speed can be improved up to 1.95 times in a single node,and strong-scalability of the model is almost linear when computation is extended to multi nodes,suggesting that our code optimization is very effective.
Intel analysis tools;code optimization;oceanic numerical model;surface wave model;high performance computation
October 17,2016
P73
A
1671-6647(2017)04-0473-10
10.3969/j.issn.1671-6647.2017.04.004
2016-10-17
国家重点研发计划——大规模多模式多过程地球系统模式耦合平台研发(2016YFA0602200);中央级公益性科研院所基本科研业务费专项——束星北青年学者基金(2016S03);青岛海洋科学与技术国家实验室鳌山人才计划——优秀青年学者专项;国家自然科学基金委员会-山东省人民政府联合资助海洋科学研究中心项目——海洋环境动力学和数值模拟(U1406404);全球变化与海气相互作用专项——海洋动力系统可预报性研究(GASI-IPOVAI-06)
杨晓丹(1988-),女,山东聊城人,博士研究生,主要从事海-气相互作用方面研究.E-mail:yangxiaodan@fio.org.cn
*通讯作者:宋振亚(1982-),男,山东聊城人,副研究员,博士,主要从事海气耦合方面研究.E-mail:songroy@fio.org.cn
(李 燕 编辑)
猜你喜欢
幼儿园(2021年13期)2021-12-02
小读者(2021年2期)2021-11-23
书香两岸(2020年3期)2020-06-29
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
新课程(中学)(2018年4期)2018-02-27
学周刊(2016年26期)2016-09-08
电脑爱好者(2016年8期)2016-04-28
