
基于数据挖掘的食品零售价格分类研究
2017-11-13 04:23:54韩天鹏白玲玲
韶关学院学报 2017年9期
韩天鹏,白玲玲
(1.阜阳师范学院计算机与信息工程学院,安徽阜阳236037;2.中共阜阳市委党校教务处,安徽阜阳236034)
基于数据挖掘的食品零售价格分类研究
韩天鹏1,白玲玲2
(1.阜阳师范学院计算机与信息工程学院,安徽阜阳236037;2.中共阜阳市委党校教务处,安徽阜阳236034)
应用数据挖掘技术可以使食品零售价格分析更加准确.本文首先分析了食品零售价格的实际情况;其次对数据挖掘的基本理论进行了深入的研究;然后设计了基于FP-tree算法程序对数据进分类挖掘;最后以基于FP-tree树挖掘算法设置的时间序列所计算的趋势距离为依据,得出食品零售价格波动和分类规则.结果表明,食物可分为六种类别,说明数据挖掘技术是分析食品零售价格分类的有效手段之一.
数据挖掘;分类;食品零售价格
随着经济的增长,人们对经济发展的关注度不断提高.商品价格随着人们生活水平的提高而不断提高,但人民生活水平随着商品价格的不断上涨却不断下降.食品是人们生活的主要商品,而食品内在特点是通过供给和市场的需求价格波动体现的,食品常见的内在特征是从价格波动中发现的.应建立一种先进的技术,以食品零售价格为研究对象,对消费价格指数的相关信息进行分析[1].以及用适当的方法对食物进行分类,以提高食品零售价格分类的有效性.
数据挖掘技术可以从不完备、噪声、模糊、随机的应用数据中提取潜在的、有价值的信息和知识,通过深入分析数据来解决复杂的问题.在数据挖掘过程中,可自动搜索存储在计算机内电子表格中的数据,然后进一步通过关联规则、分类回归、聚类分析、数据结构等方法将数据处理,最后可以发掘出隐藏在信息中有价值的数据.数据挖掘技术是食品零售价格分类的一种较好的方法[2].笔者旨在为数据挖掘技术进行食品零售价格分类的研究提供参考.
1 零售价格分析
消费物价指数是一个有效的物价变动指数,它能反映生产和劳务价格与人民生活的统计结果,是观察通货膨胀加剧的重要指标.若食品价格进一步增加,CPI也会相应增加,这表明,通胀压力正在增加.城市居民食品零售价格是消费品价格指数的重要组成部分,粮食生产和流通成本的增加会导致农产品价格的提高,尤其是特殊天气情况,生产成本将大大增加,国际粮食价格会影响到国内供应和需求,食品价格将进一步增加[3].在有些年份,若CPI有较大的上升幅度,那么通货膨胀将增加.城市居民食品零售价格是消费品价格指数的重要组成部分,对食品零售价格变动趋势的研究是研究CPI变化的一种有效工具,分类研究不同类型食品价格是研究食品零售指数更好的方法,最后也可以得到好的变化趋势.
城市居民的食物可分为5类,第一类是新鲜猪肉、新鲜牛肉和新鲜羊肉.第二类食品包括花生油、鸡肉和鱼.第三类食物包括豆类、芹菜、白糖、红糖.第四类食品包括菜籽油、大豆油、大豆混合油、鸡蛋、草鱼、鲤鱼、油菜、黄瓜、茄子、西红柿、青椒、韭菜、苹果、西瓜、酱油、醋、草原鲜奶.第五类食物包括卷心菜、萝卜、土豆、胡萝卜、卷心菜、香蕉、豆腐、食用盐[5].
食品零售价格的变化会影响到中国市场经济的稳定,也会影响到欧盟等其他国家的稳定.为了有效的控制食品零售价格的增加,可对农业采取相应的补贴措施.例如,增加农民的补贴,大力推广新技术和新农业生产的应用,这样就会能够迅速提高农场农民种粮的热情,粮食生产供应就可以得到保证.另外严格控制化肥和农用化学品价格,降低农业生产成本.农民还应该掌握整个市场的信息,并能缩短分销链,降低分配成本.有效地开展市场价格和成本调查监测,供给和需求的监测分析.加强监测粮食、食用植物油、肉类、蛋类、蔬菜、牛奶及其食品价格变化,及早定位、标志问题.以上方法可以保证粮食供应,保持粮食市场秩序,及食品零售价格长期平稳[5].
2 数据挖掘的基本理论
利用记录食品零售价格历史变化,对食品价格数据进行分类,找出食品零售价格特征与数据之间的关系,最后对食品零售价格进行分类.基于数据挖掘的食品零售价格分类程序包括:数据准备与分类、对象确认、数据清理、数据标准化、数据离散化、数据的简约化,最终得到食品零售价格的分类.
(1)数据清理.这一步是删除采集到的异常数据,主要包括加入空缺值,删除传感器错误产生的无效数据,或者在数据传输过程中随时收集的数据.
(2)数据标准化.这一步是比较基于统一标准的传感器采集的数据.当食品零售价格变化异常,异常数据无法证实,同时最大、最小和实时采集数据的平均值对食品零售价格分类效果又不明显时,为了提高食品零售价格的分类效果,可以用下面的数据标准化方法:
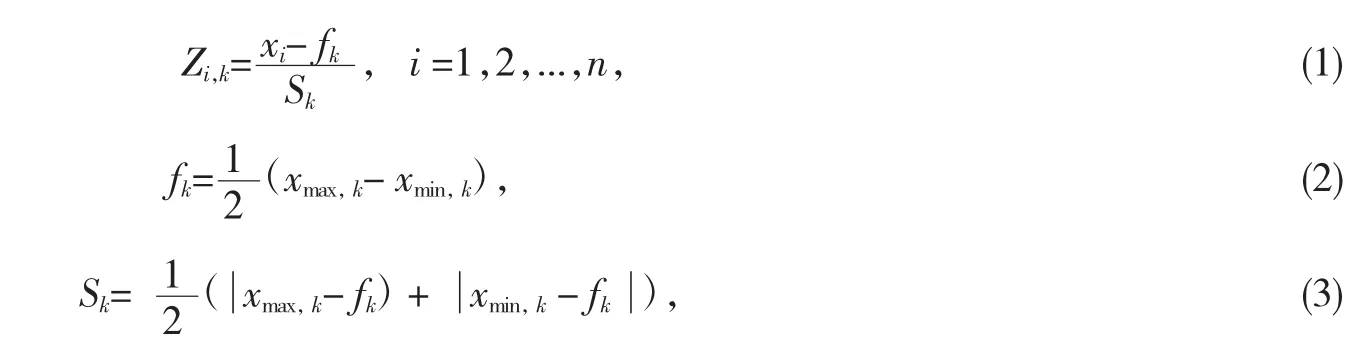
其中,Zi,k指的是收集到的数据的异常因素,当-1<Zi,k<1时收集到的数据处于正常状态,fk表示属性k的平均值,Sk表示属性 k 的平均绝对偏差,xmax,k和 xmin,k表示属性 k 的最大值和最小值[6].
(3)数据离散化.这一步可以和不同区间元素决策价值类似将符合不同条件的元素进行间隔,不同区间的元素可以分为几个有限的间隔.数据离散化处理的过程中应该考虑收集数据的特点,在收集的数据变化不大,而对食品零售价格分类影响较大,小的离散区间可以选择,从而可以得到正确的食品零售价格分类.否则,大离散区间可选择.
(4)模糊粗糙集的数据挖掘方法.模糊粗糙集是粗糙集理论的扩展,已知的话语域U,模糊集合F(U)定义为弱模糊划分,定义如下[7]:

(b)Ai是U上的正则模糊集;
A,Bi∈F(U)两个模糊集合是已知的,两个模糊集合之间的关系可以用包含度表示,包含度的表达式如下:

模糊集合X到ε的上近似集和下近似集定义如下:

其中,A一σ(X)表示上近似集,A一τ(X)表示下近似集.
决策系统的条件属性和决策属性属于模糊集合,隶属度可以根据属性集合中不同属性值反映模糊集合的隶属度,从而为简约规则提供依据.
知识推理是决策系统的重要组成部分,决策能够有效地表达知识.决策表的对象和决策规则映射一一对应,决策可以定义如下[8]:
信息系统的S=(U,A)是已知的,C是条件,D是决策属性,属于两个子集合A,C∩D=A,C∩D=Φ,S是决策表.
在决策过程中,基于决策表约简的条件属性较少,决策表一致性具有以下约简过程:首先,在决策表中删除列;其次,冗余行被删除;最后,在决策规则中删除冗余属性数.
3 数据挖掘算法设计
3.1 算法思路
由于历史原因,许多存储零售食品价格数据的数据库数据格式都不尽相同,其传统的关系测量算法的正确性和效果也不能保证.造成这种情况的主要原因是处理器在处理大量的数据时处理效率低下,数据不是一次性处理的.解决上述问题可通过云计算资源交互概念,利用FP-Tree树算法,建立对海量数据的有效挖掘算法,根据结果收敛的特点构造快速有效的关系度量算法.关系表达式如下:

上述表达式是对称的组合.根据样本容量和综合信息内容的客观事实,重要信息添加到公式(7),全面考虑关联系数的尺度,因此连接功能的设计表示如下:
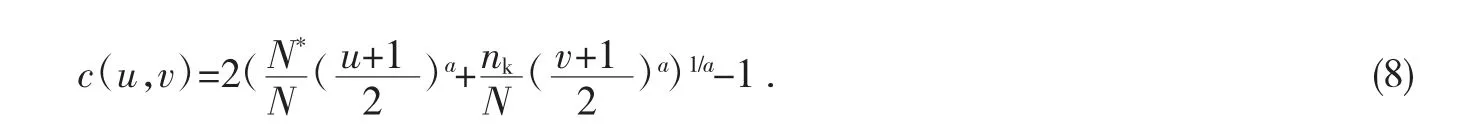
其中 ni是第 i个数据样本,N*=n1+n2+...+nk-1;N=N*+nk,-1≤u,v≤1,0<a<1,1≤ck≤1;a 是设置参数.
将小样本集合si转换成待处理的海量数据,根据数据的特殊性确定关系系数的有效计算方法,并用以下公式对x到y的关系效应水平ri进行了评价:
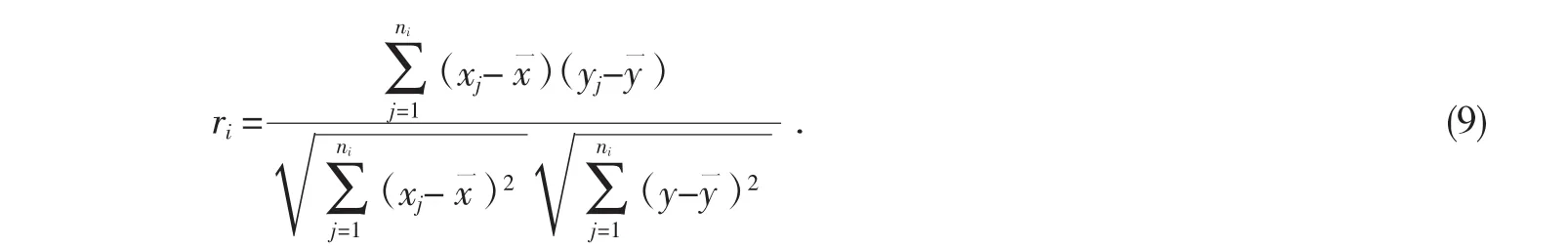
其中,xj和 yj表示 si和y一中的观测值,ni是 si的样本容量.
si+1其他海量数据采集的独立样本,然后计算出效应水平
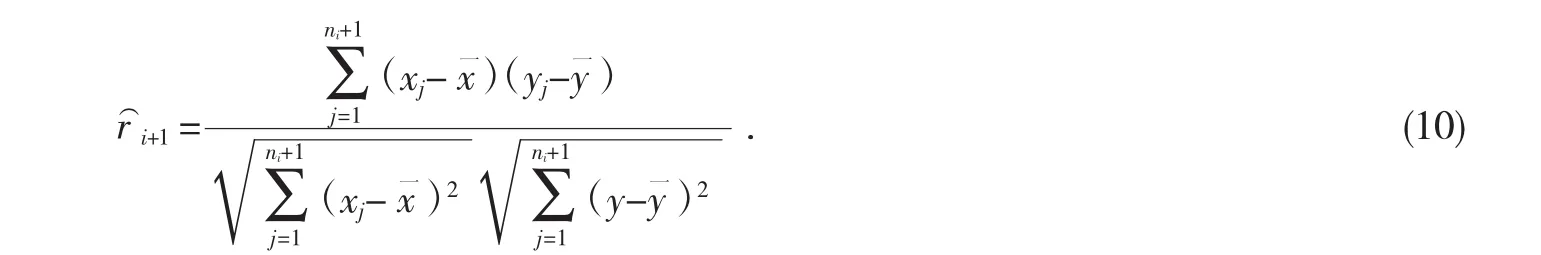
将采样后两个小样本集合并确认,公式如下:

样本容量计算如下所示:

通过建立连接函数将两个小样本之间的关联程度联系起来,下式定义了复合样本合并的关联度.
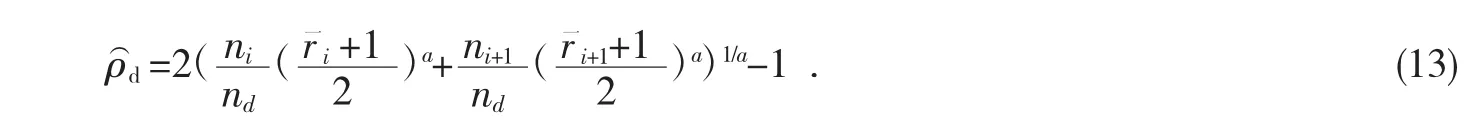
对ρ⌒d评估后,si+2最后评估x中y和的关联程度r一i+2和ni+1的样本容量,sd和si+2合并集合样品集sd+1被证实,样本容量可以定义为:

关联程度变量,集合中元素和值的确定是根据连接作用,其定义如下:
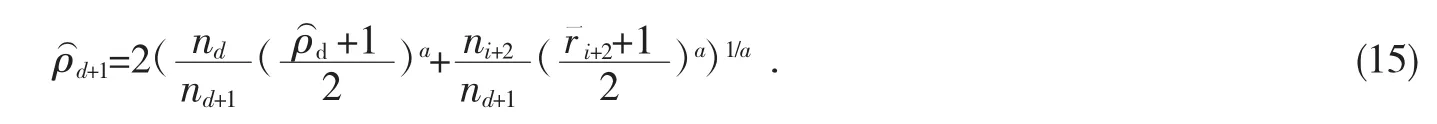
算法的结束条件如下:

其中ε<0.
3.2 算法描述

if((freq==0)then nextISetP=p;
if(ChildCountFlag==false)then
{ChildCount=Get Child-Count of p;
if(ChildCount>1)then
{ChildCountFlag=true;
nextISetP=p;} }
freq=Get频率 from p;}
until(p==root);//直到根节点
p=nextISetP;
Add N to V;}
until(ChildCount>1)or(p=root)}
Return V.
以上描述了本地数据集在整个空间数据中构建分布式FP-tree的算法Cl_FP-Growth[10].为从 FP-tree 中读取项集,Cl_FP-Growth 被调用两次,一次用于两个周期性数据库中的FPT1,第二次用于FPT2.若FP-tree树的高度为H,算法的时间复杂度为O(KH+N).构建FP-tree仅需扫描两遍空间数据集D[11].算法Cl_FP-Growth有着较高的运行效率.
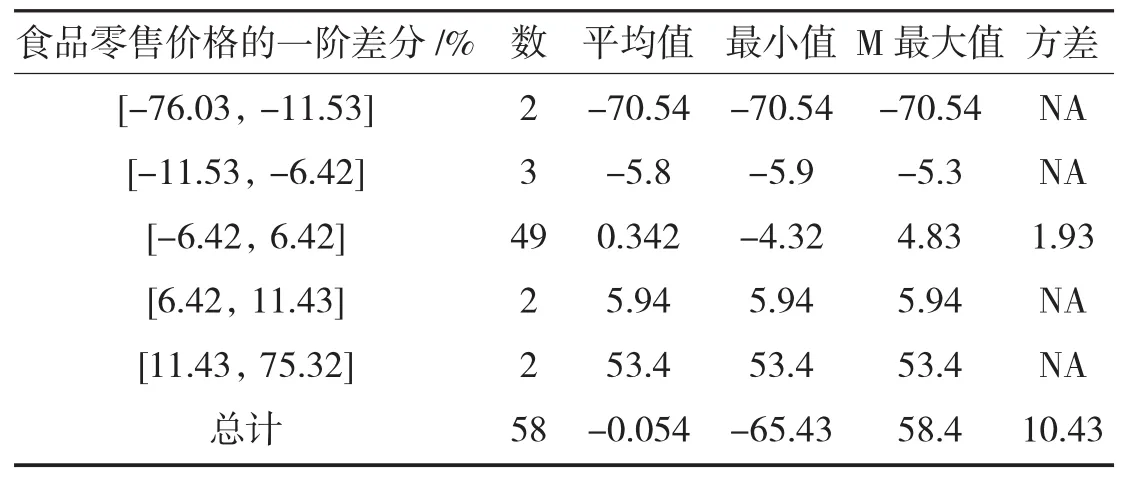
表1 食品零售价格增长率幅度的分类
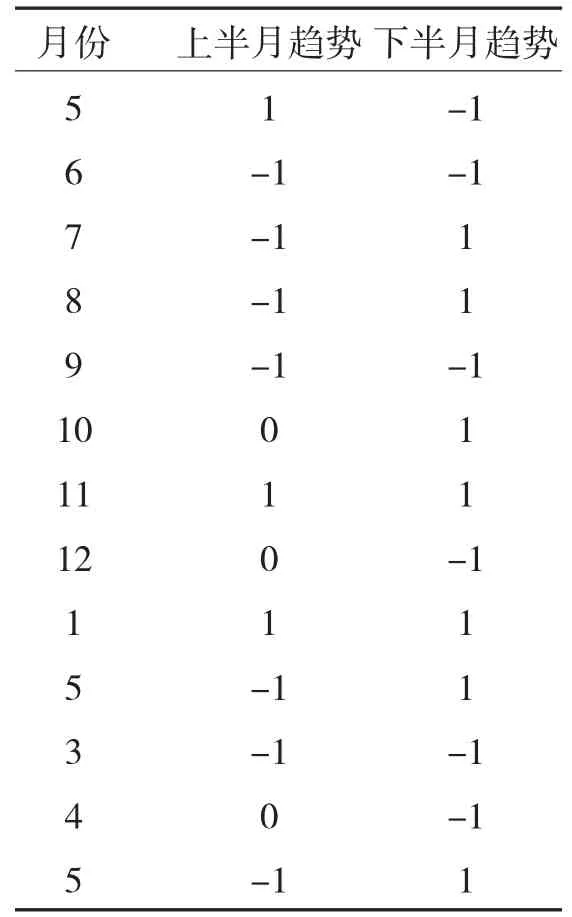
表2 花生油趋势表示
4 算法分析验证
近年来,食品零售波动呈现出一定的规律性,但在某些年内食品零售价格会发生突变,这种现象表明食品零售价格受市场力量的影响,对随机因素会产生冲击[6].根据食品零售价格季度数据,食品零售价格增长率见表1.
在数据挖掘基本理论的基础上,利用MATLAB软件编制相应的程序,以花生油为例,周期时间为2015年5月至2016年5月为例,趋势表示见表2[13].
基于程序进行时序模式的相互比较,得到趋势距离矩阵,使用趋势距离去衡量这两个序列模式之间的相似程度,其距离越接近于0,表示待匹配的两个序列趋势越接近[14];反之趋势距离越大表示待匹配序列趋势可能会有较大差异,最终无法归为同一类.
根据趋势距离去度量各种食品的相似性,开始时将每一样商品都作为一类,根据趋势距离的大小将距离最近的逐步合并,直到所有样品合并为一类为止.根据该算法对食品零售价格最终分类,结果见表3.
食物可分为6种,即油、高蛋白肉类、单季蔬菜、多季蔬菜、非季节性蔬菜和辅料类(见表3).食品零售价格分类具有重要的经济意义,从表3可以看出分类结果与实际情况一致.食品的内在性和不可估量性可以有效地反映出来,如供求变化情况、价格弹性等,分类结果具有较强的指导意义.
4 结语

表3 基于数据挖掘的食品零售价格分类结果
食品零售价格是居民关心的重要经济指标,在各种因素的影响下会发生波动.食品零售价格与人民生活密切相关,其波动很大程度上影响人民的生活,因此应有效控制物价波动,使人民在稳定的经济环境中消费.在本文中将数据挖掘技术应用于食品零售价格分类中,数值模拟结果表明,它是分析食品零售价格的有效手段.
[1]Tres A,Van D V,Perez-Marin M D,et al.Authentication of organic feed by near-infrared spectroscopy combined with chemo metrics:A feasibility study[J].Journal of Agricultural and Food Chemistry,2016,60(33):8129-8133.
[2]Li T,Zhang Z G,Liu G L.Sensitivity analysis model of food prices on SVR[J].Journal of Convergence Information Technology,2012,7(21):205-211.
[3]Seck G S,Guerassimoff G,Mai¨zi N.Heat recovery with heat pumps in non-energy intensive industry:A detailed bottom-up model analysis in the French food&drink industry[J].Applied Energy,2013,111:489-504.
[4]Suchomel J,Gejdo?M,Ambru?ová L,et al.Analysis of price changes of selected round wood assortments in some Central Europe countries[J].Journal of Forest Science,2012,58(11):483-491.
[5]Kato T,Pham D T X,Hoang H,et al.Food residue recycling by swine breeders in a developing economy:A case study in Da Nang[J].Waste Management,2012,32(12):2431-2438.
[6]Lone T A,Khan R A.Data mining:Competitive tool to digital library[J].DESIDOC Journal of Library&Information Technology,2014,34(5):401-406.
[7]Nishimura K,Maehata Y,Sunayama W.Improved Inspection of Facilities for High-Voltage Class Using Data Mining[J].Electrical Engineering in Japan,2015,191(2):47-54.
[8]Wang X F,Wang Y,Bi H B,et al.Heat-Supply Network State Prediction Based on Optimum Combination Model of Data Mining Journal of Applied Sciences,2014,13(13):2443-2449.
[9]Kyunglag K,Daehyun K,Yeochang Y,et al.A real time process management system using RFID data mining[J].Computers in Industry,2014,65(4):721-32.
[10]张明卫,朱志良,刘莹,等.一种大数据环境分布式辅导关联分类算法[J].软件学报,2015,26(11):2795-2810.
[11]袁景凌,钟珞,杨光,等.绿色数据中心不完备能耗大数据填补及分类算法研究[J].计算机学报,2015,38(12):2499-2516.
[12]Yang X Q,Zou C F,Yue L,et al.Research on food complains document classification based-on topic[J].Journal of Software,2012,7(8):1687-1693.
[13]吕艳霞,王翠荣,王聪,等.大数据环境下的不确定数据流在线分类算法[J].东北大学学报(自然科学版),2016,37(9):1245-1249.
[14]马彪,周瑜,贺建军.面向大规模类不平衡数据的变分高斯过程分类算法[J].大连理工大学学报,2016,56(3):279-284.
Research on Food Retail Price Classification Based on Data Mining
HAN Tian-peng1,BAI Ling-ling2
(1.School of Computer and Information Engineering,Fuyang Teachers College,Fuyang 236037;2.Information Management Center,Fuyang Party Institute of CCP,Fuyang 236034,Anhui,China)
The application of data mining technology can make food retail price analysis more accurate.In the paper,firstly,the real situation of Chinese food retail price is analyzed.Secondly,the basic theory of data mining is studied and then designed based on FP-tree algorithm program for data classification mining,from which finally,the calculated time series trend distance results in food retail price fluctuation and classification rules.The result shows that the food can be divided into six categories and the data mining technology is an effective means for analyzing the food retail price classification.
data mining;classification;food retail price
TP274+.2
A
1007-5348(2017)09-0031-06
2017-08-22
国家自然科学基金项目(61673117);阜阳师范学院自然科学研究项目(2016FSKJ03).
韩天鹏(1982-),男,安徽阜阳人,阜阳师范学院计算机与信息工程学院讲师,硕士;研究方向:数据挖掘、大数据应用、云计算.
(责任编辑:欧 恺)
猜你喜欢
中国化肥信息(2022年8期)2022-11-30 06:21:22
中国化肥信息(2022年9期)2022-11-23 07:56:12
中国化肥信息(2022年4期)2022-06-07 06:35:12
中国化肥信息(2022年2期)2022-04-19 12:46:32
阜阳师范大学学报(社会科学版)(2021年1期)2021-03-30 03:29:50
大众投资指南(2021年35期)2021-02-16 01:06:26
城市道桥与防洪(2019年5期)2019-06-26 00:55:34
今日农业(2019年13期)2019-01-03 15:05:47
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
