
PASS软件在观察性研究设计样本含量估算中的应用
2017-11-02 06:54魏凤江胡良平
四川精神卫生 2017年5期
魏凤江,胡良平
(1.天津医科大学公共卫生学院卫生统计学教研室,天津 300070; 2.天津医科大学基础医学院遗传学系,天津 300070;3.军事医学科学院生物医学统计学咨询中心,北京 100850;4.世界中医药学会联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu812@sina.com)
PASS软件在观察性研究设计样本含量估算中的应用
魏凤江1,2,胡良平3,4*
(1.天津医科大学公共卫生学院卫生统计学教研室,天津 300070; 2.天津医科大学基础医学院遗传学系,天津 300070;3.军事医学科学院生物医学统计学咨询中心,北京 100850;4.世界中医药学会联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu812@sina.com)
样本含量估算是科研人员进行科研设计所关注的重要问题之一,合理估算样本含量是试验设计中的一个重要内容。本文应用PASS 11.0软件对临床研究中观察性研究(即队列研究、病例-对照研究和横断面研究)的样本含量进行计算。探讨PASS软件在科研过程中计算样本含量的实用性和准确性,为科研工作者在进行观察性研究设计阶段进行科学的样本含量估算提供参考。
样本含量;队列研究;病例-对照研究;横断面研究
1 概 述
样本含量(sample size)是指承受研究者实施的样本所包含之观察单位数或样本例数。除个别设计方法外,在研究设计中必须确定需要多少试验对象或观察对象。因为人力、物力、经费等各种因素的限制,开展一项研究往往只能对总体中的一部分进行研究,即研究样本,然后由样本统计量推断总体参数或总体分布。样本含量过小,结果不稳定,不能真实地反映总体规律;而样本含量过大,会增大研究的难度,并造成人力、物力的浪费。所以合理的样本含量一方面可以在既定的科研经费下保证精确度和可靠性,另一方面可以合理利用资源,保证统计推断的最大效果。目前,能够估算样本含量的方法较多,应用较广泛的方法是以公式为基础的SAS编程;也可以利用SAS/STAT模块中的GLMPOWER和POWER两个过程,对样本含量和检验效能进行更加深入的探讨,但是对于编程软件不太精通的人士,SAS软件使用难度很大。PASS,即Power Analysis and Sample Size,是由美国NCSS公司开发的一款样本含量计算软件,覆盖了几乎各种场合下的样本含量计算方法,其界面友好,操作简单,可以满足临床科研需要[1]。本文采用PASS软件对观察性研究设计(即队列研究、病例-对照研究和横断面研究)中样本含量的计算方法进行举例说明。
2 队列研究设计四格表资料统计分析时样本含量估计
样本含量计算公式[2]:

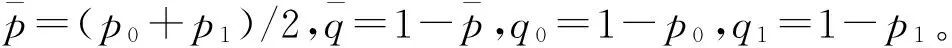
【例1】某医生拟采用队列研究设计方法评价某药物预防脑卒中再发的效果,得知不用药者脑卒中的再发概率为23%,估计RR值为0.5,设α=0.05,β=0.10,问至少需要多大样本含量[3]?
PASS操作如下:

Proportions(+号展开)→TwoIndependentProportions(+号展开)→Test(Inequality)(单击展开)TestsforTwoProportions(Ratios)
按照图1标识,分别在相应位置输入α值、β值、RR值、P0值。最后,输出结果显示用药组和非用药组各需要225人。见图2。

图1 PASS软件队列研究计算样本量操作示意图

图2 PASS软件队列研究计算样本含量结果
3 病例-对照研究设计时样本含量估计
3.1 不配对但病例数与对照数相等时的样本含量
样本含量计算公式[4]:


【说明】如果无p1的估计值,但有备择假设中的优势比的估计值OR,则可用下式计算p1:

式中OR应取优势比OR的可能数值中之最小值。
【例2】在一个病例对照研究中,已知对照人群的暴露率p0=0.33,预计暴露的OR=2.8,设定α=0.05,β=0.10,若要进行假设检验,试估计病例组和对照组所需的样本含量[5]。PASS操作如下:

Proportions(+号展开)→TwoIndependentProportions(+号展开)→Test(Inequality)(单击展开)TestsforTwoProportions(OddsRatios)
按照图3标识,分别在相应位置输入α值、β值、OR值、P0值。最后,输出结果显示病例组和对照组各需要82人。见图4。
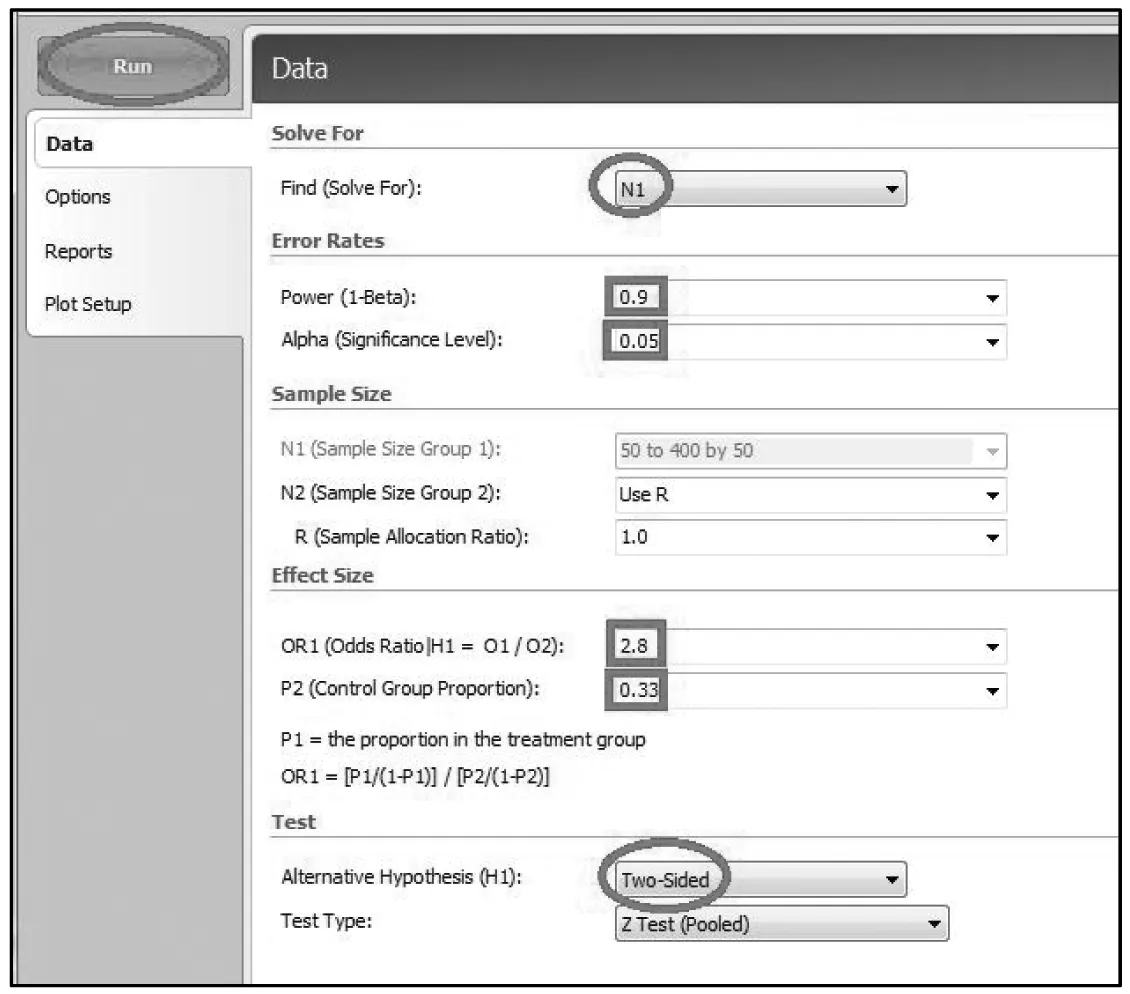
图3 PASS软件病例对照研究计算样本量操作示意图
图4 PASS软件病例对照研究计算样本量结果
3.2 不配对且病例数与对照数不等时的样本含量
设病例组例数与对照组例数之比为1∶C,则病例组的样本含量可按下述公式计算[4]:
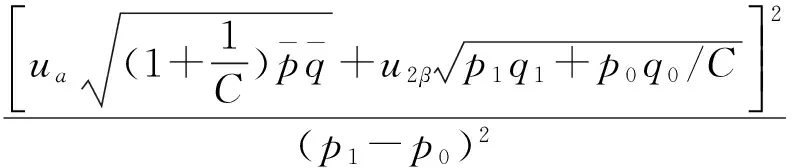

PASS操作:参照例2,R(Sample Allocation Ratio)键入c值。
3.3 配对的病例-对照研究所需的样本含量
1∶1配对的病例-对照研究中,调查结果有四种情况,即++、--、+-、-+。其中++和--称为一致结果,+-和-+称为不一致结果。配对调查的优点是可以对某些干扰因素的作用作均衡处理,并可能减少样本含量。其样本含量(或对子数N)的计算公式为:
N≈n/(p0q1+p1q0)
式中p1为估计的病例组中暴露者的比例;p0为估计的对照组中暴露者的比例;n为不一致的对子数。

如果将例2按照配对的病例-对照研究进行观察,则所需样本含量计算如下:
PASS操作如下:

Proportions(+号展开)→TwoCorrelatedProportions(+号展开)→Test(Inequality)(单击展开)TestsforTwoCorrelatedProportionsinaMatchedCase-con-trolDesign(OddsRatios)
按照下面图5标识,分别在相应位置输入α值、β值、OR值、P0值。最后,输出结果显示需要103对样本。见图6。

图5 PASS软件配对病例对照研究计算样本含量操作示意图

图6 PASS软件配对病例对照研究计算样本含量结果
4 横断面研究所需的样本含量
横断面研究中的主要研究方法是抽样调查,常见的抽样方法有简单随机抽样、系统抽样、分层随机抽样、整群抽样和多级抽样。本文示例主要是应用单纯随机抽样获取样本的样本含量计算方法。
4.1 定量资料
样本含量计算公式[5]:


式中n、δ、σ、S分别为样本含量、允许误差、总体标准差、样本标准差;uα、tα分别为与u临界值表、t临界值表中双侧概率栏所对应的临界值。
【例3】在血吸虫病防治工作中,需要调查血吸虫患者血红蛋白含量(g/L),根据以往经验,标准差为30,这次希望误差不超过5(即置信区间上限与下限之差为10),取α=0.05,在这些条件下,要估计患者的血红蛋白含量,问需调查多少名患者?
PASS操作如下:

Means(+号展开)→OneMeans(+号展开)→ConfidenceIntervals(单击展开)ConfidenceIntervalsforOneMeans
按照下面图7标识,分别在相应位置输入α值、β值、δ值。最后,输出结果显示需调查141人。见图8。
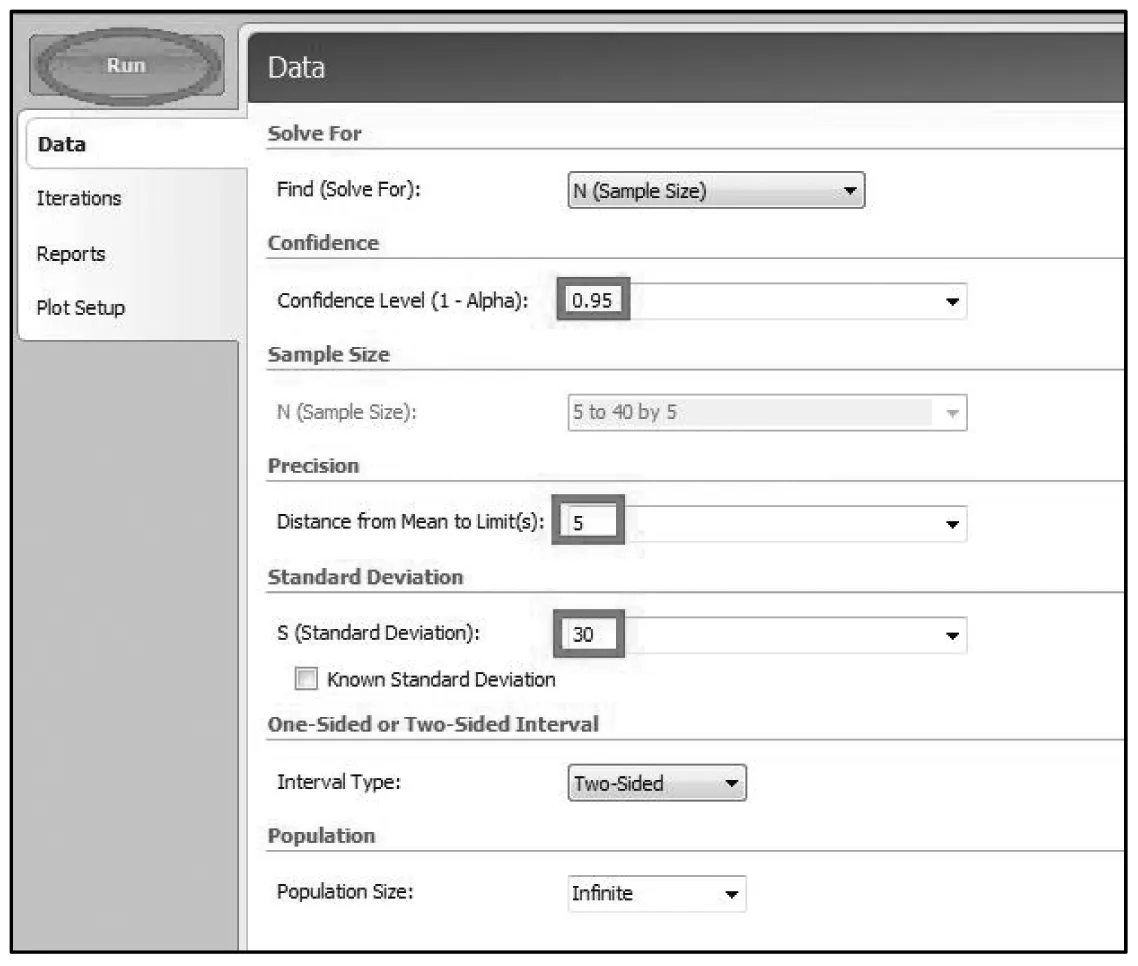
图7 PASS软件横断面研究(计量资料)计算样本量操作示意图

图8 PASS软件横断面研究(计量资料)计算样本量结果
4.2 定性资料

式中n、δ、p分别为样本含量、允许误差、总体率π的估计值。
【例4】拟用抽样调查了解某地小学生蛔虫感染率。假定以往该地小学生蛔虫感染率P=50%,要求误差不超过3%,如取α=0.05,问需调查多少人?
PASS操作如下:

Proportions(+号展开)→OneProportions(+号展开)→Confi-denceIntervals(单击展开)ConfidenceIntervalsforOnePropor-tion
按照下面图9标识,分别在相应位置输入α值、p值、δ值。最后,输出结果显示需调查1 068人。见图10。

图9 PASS软件横断面研究(定性资料)计算样本量操作示意图

图10 PASS软件横断面研究(定性资料)计算样本量结果
5 讨 论
PASS软件目前涵盖的统计学检验超过680种,覆盖了几乎所有临床试验设计所需的样本含量计算方法,在NCSS官网上有软件的使用说明、视频及试用版可以免费下载,经过20年不断进行调试和完善,该软件已成为临床试验样本含量估算的较好选择。
临床观察性研究的样本含量估计只有相对意义,并非绝对精确的数值。因为样本含量估计是有条件的,而这种条件在重复研究中不是一成不变的。实际研究中往往同时探索几个因素,而每个因素都有其各自的OR值及p0,这时估计样本大小常以最小的OR和最适的p0(距50%最远)为准进行估计,以使所有的因素都能获得较高的检验效率。
以上样本含量的研究是基于理论之上,而在实际研究中,样本含量的估计还要考虑研究中面临的一些实际问题,如研究对象的选择、完成研究所需的经费等问题。除此之外。还需要考虑研究对象的依从性和失访等因素,通常会将样本含量增大20%左右。伦理也是在确定样本含量时必须考虑的因素。如果确定了较大的样本量,但实际效果不明显,或为达到所需的研究结果,在较长期限内让研究对象承受生理上的不适,这些都是需要研究者权衡的因素[6]。
[1] 王媛媛,孙瑞华.PASS软件实现临床试验中非劣效、等效和优效性检验的样本量估算[J].中华流行病学杂志,2016,37(5):741-744.
[2] 胡良平.SAS实验设计与统计分析[M]. 北京: 人民卫生出版社,2010: 211.
[3] 胡良平.统计学三型理论在实验设计中的应用[M]. 北京: 人民军医出版社,2006: 215.
[4] 金丕焕.医用统计方法[M]. 2版. 上海: 复旦大学出版社, 2006: 514-517.
[5] 孙振球.医学科学研究与设计[M]. 北京: 人民卫生出版社,2010: 125-127, 135.
[6] Billoir E, Navratil V, Blaise BJ.Sample size calculation in metabolic phenotyping studies[J]. Brief Bioinform, 2015,16(5):813-819.
ApplicationofPASSinthesamplesizeestimationoftheobservationalstudydesign
WeiFengjiang1,2,HuLiangping3,4*
(1.DepartmentofHealthStatistics,SchoolofPublicHealth,TianjinMedicalUniversity,Tianjin300070,China;2.DepartmentofGenetics,CollegeofBasicMedicalSciences,TianjinMedicalUniversity,Tianjin300070,China;3.ConsultingCenterofBiomedicalStatistics,AcademyofMilitaryMedicalSciences,Beijing100850,China;4.SpecialtyCommitteeofClinicalScientificResearchStatisticsofWorldFederationofChineseMedicineSocieties,Beijing100029,China*Correspondingauthor:HuLiangping,E-mail:lphu812@sina.com)
To estimate the sample size is one of the most important issues in the research design, and it is an important part of the experimental design to determine the sample size rationally. In this paper, we used PASS 11.0 software to calculate the sample size of the observational studies including cohort study, case-control study and cross-sectional study. In order to evaluate the practicability and accuracy of PASS software for the purpose of providing reference for the sample size estimation in the observational study design.
Sample size; Cohort study; Case-control study; Cross-sectional study
R195.1
A
10.11886/j.issn.1007-3256.2017.05.002
2017-08-13)
(本文编辑:陈 霞)
国家高技术研究发展计划课题资助(2015AA020102)
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
工程建设与设计(2021年11期)2021-07-28
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
测控技术(2018年4期)2018-11-25
产品可靠性报告(2017年7期)2017-09-05
中华老年口腔医学杂志(2016年6期)2017-01-15
中国感染控制杂志(2015年7期)2015-12-13
中国当代医药(2015年17期)2015-03-01
