
基于粒子群的K-均值算法在电网企业对标中应用
2017-11-01 06:35:32国网娄底供电公司罗林波罗岚波
电子世界 2017年19期
国网娄底供电公司 罗林波 罗岚波 伍 娟
基于粒子群的K-均值算法在电网企业对标中应用
国网娄底供电公司 罗林波 罗岚波 伍 娟
在电网企业对标体系中,结合我国电力行业实际情况与国外已有的对标体系,构建一个多因素,多层次的指标体系。利用聚类分析技术在电网企业对标中的应用,采用了粒子群算法和K-means相结合的聚类算法,同时考虑多种对标。电网企业通过对标指标体系评价,及时发现企业与企业的差距,并制定相应的改进措施。
指标体系;聚类分析;粒子群算法;K-means算法
前言
我国电力体制的改革逐步深化,电力市场逐步成为一个买方市场。为了提高和完善电网企业,电网企业与标杆企业的各项指标进行对比势在必行,不断寻找差距并持续改进,文献[1-3]电力行业开展了同业对标管理工作,选出标杆企业且向其学习,不断改善管理方式和提高经营效益,实现企业的突破性发展,文献[4]通过使用层次从电网公司同业对标综合评价,确定相关指标的权重,多维距离方法来区分相关指标的优劣,与实际相比较,以验证该方法的可行性和平衡。文献[5]使用个人优势识别指标选择电力行业与标杆企业的过程中的行业标准,并通过实例演示了选择科学合理的商业模式的方法。文献[6]通过对电力企业的标准指标灰的特点,分别选取标杆企业,及分类和企业指标综合评价方法,建立相应的二模型,并通过实例说明灰色模型的有效性和实用性。同时数据信息能够给企业提供真实的发展状况,数据挖掘在电网同业中的应用,从供电质量,规范服务,咨询服务,电费缴纳,服务管理建立新型电网企业满意度对标指标体系,通过数据挖掘中的聚类分析,为电网企业的决策提供新的思路,能够为电网企业结合自身发展战略制定更为科学,平衡,合理的工作计划。
1.聚类分析
1.1 K-means算法
聚类分析是统计学中研究物以类聚问题的多元统计方法,它能够将个体(个案或变量)数据根据其诸多特征,按照在性质上的相似性进行自动分类,产生多个分类结果。在聚类之前,个体类划分的数量与类型均是未知的,分类后,类内部的个体特征差异性较大。聚类分析是在大量数据中发现有价值信息的重要手段。聚类在图像处理、系统建模、数据挖掘、模式识别等领域都发挥着非常重要的作用,聚类分析有系统聚类和逐步聚类两种方法,
首先随机选择K个聚类中心,根据最近的原则将其他类别分配到各个类中,然后分别计算k个聚类与每一类中心的平均值,迭代进行个体的再分配,直到没有变化为止,从而得到最终的K个类,K-means算法太过于依赖于初始聚类中心的选择,且得出结果波动性较大。
输入:聚类个数K数据集,输出:K个簇的集合。
步骤1:随机选择k个对象在数据集里。
步骤2:将余下的数据划分到和数据本身相距最近的簇心得簇中。
步骤3:在完成个体的分配之后,针对每一个类,计算其所有个体的平均值,作为该类新的中心,
步骤4:如果得到的结果收敛,则输出聚类结果;如果不收敛,则返回步骤2,进行重新类聚。
1.2 改进K-means的粒子群的聚类算法
由于k-means算法对初始聚类中心的选取容易陷入局部最优解具有波动性,本文基于改进粒子群优化算法的k-means聚类算法,利用粒子群算法全局寻优能力来优化k-means算法的初始聚类中心。消除K-means对聚类中心初值的依赖性。聚类中心用粒子位置表示,每个粒子的位置包含K个聚类中心,通过调整聚类中心获得最优划分,利用粒子群算法给聚类中心加扰动,以增强跳出局部极值和寻找最优聚类的能力,如果多次扰动下聚类划分不变,则认为当前的聚类为最优聚类。
如果达到结束条件(足够好的位置或最大迭代次数),则结束,否则转步骤(2)。其流程图如图1所示。
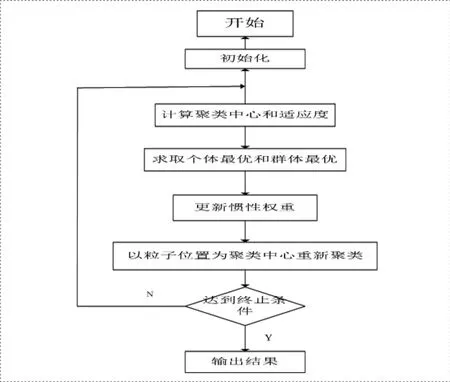
图1 粒子群算法流程图Fig 1 particle swarm algorithm flowchart
1.3 粒子群编码方案及适应度评价
在利用粒子群优化算法对k-means算法的初始中心点进行优化之前。假设待聚类数据集中的数据对象是d维向量,聚类个数为则粒子的位置为k×d维向量,粒子的速度也是k×d维向量。若粒子群数目大小为m,则每个粒子i所对应的适应度值为设Zj为第j个类的中心cj,则粒子可以釆用以下的编码方案:

粒子的适应度函数f(x)是用来评价粒子位置X性能好坏的评价函数,因此可将评价k-means算法聚类效果的准则函数作为粒子群优化算法中评价粒子位置性能的适应度函数f(x)则粒子群的适应度函数可定义为:

2.电网企业同业指标模型构建
其模型必须与电力用户实际情况相结合,因此把电力客户满意度评价模型分为三个层次,第3层直接反应电力客户满意度的基本特征,如供电质量,供电安全性等19个因素。及选取规范服务等5个因素作为二级指标,具体模型如图2所示。
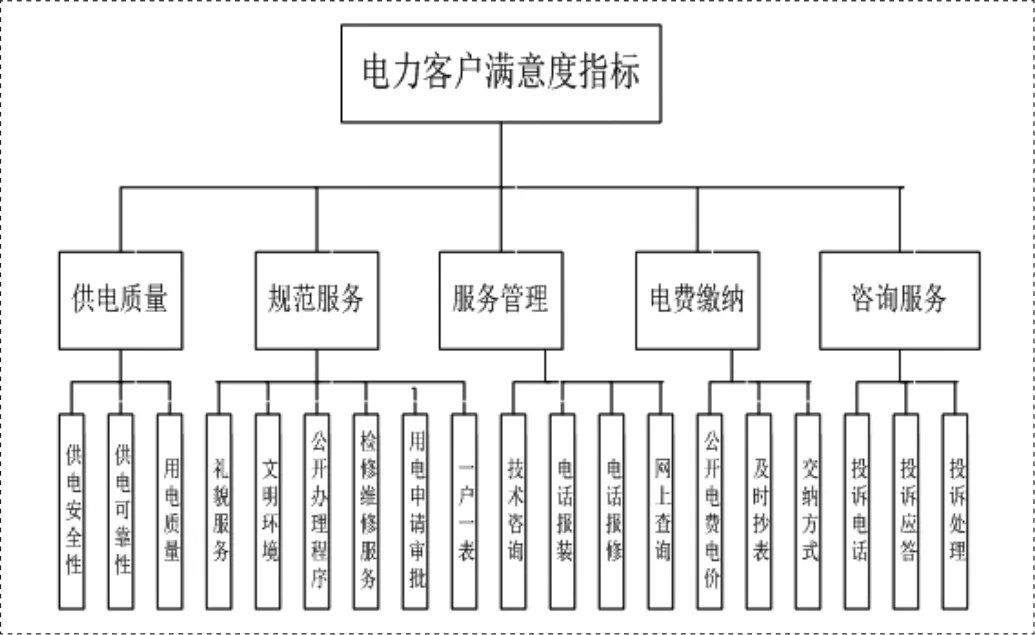
图2 电力客户满意度测评模型Fig.2Measurement Model of Customer Satisfaction
3.实例研究
基于上文提出的粒子群和K-means相结合的算法,首先通过粒子群算法找到初始聚类中心,然后通过K-means算法进行聚类,本节采用基于粒子群的k均值算法,对某省十个地级市的供电公司的相关指标进行实际对标。对标分为3个等级。
首先选取10个地级市的原始数据,每个地级市选取的问卷份数500份,利用基于主成分回归的熵权值对数据进行处理,最后分别得出不同地级市电力公司在供电质量,规范服务,咨询服务,电费缴纳,服务管理五类指标的,各地级市的满意度如表3。

表3 各地级市电力公司满意度Tab 3power companies around the city level satisfaction
初始粒子群大小设定50迭代300次c1=1.2,c2=1.2,wmax=0.9,wmin=0.4可以得到最好值(Best),最坏值(Worst)平均值(Average),标准误差(Std)和达到最优解总的迭代次数(N)还有适应度f(x)。
从表4得知,就输出结果的标准差而言,混合算法优于K-means,K-means容易陷入局部最优解,且每次聚类分析其结果具有较大的波动性,当适应度越小时,粒子性能越好。
表4输出结果看出混合算法比K-means算法分类更加合理,而且混合算法标准误差远小于K-means,K-means易于陷入局部最优解。在供电质量专项指标上,采用混合算法时,G、E市表现欠佳,F、I表现最好,其他六个市次之,F、I作为标杆企业,其他企业应该改善电网结构,提高运行灵活性,改善电网设备,采用新技术。在规范服务专项指标上A、D、F、I最为标杆企业,其他市表现次之的企业在营销与管理制度的不断完善,职场素质提高,市场化意识增强。就咨询服务而言,D公司表现最差,要从企业的本身寻找原因,客户管理方式的改进,对客户需求的全面重视,不断改善对客户的服务水平。电费缴纳而言,十个市相对平稳。但就C市而言,要借鉴其他供电企业经验及时准确抄表,同时要使信息透明化,提高企业文化与形象,方便客户了解自身消费水平,增强客户对企业的信赖。服务管理方面,A、B、J市建立了完善的客户投诉机制,加强了客户反馈信息的管理,及时了解自身的不足。
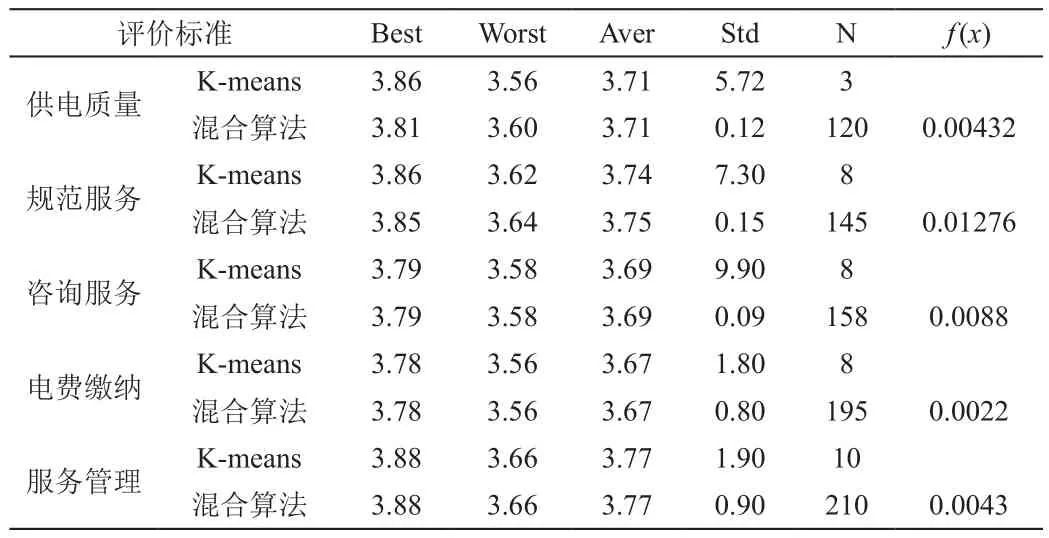
表4 聚类算法性能比较Tab 4 clustering algorithm performance comparison
4.结论
论述企业同业对标管理的作用,并选取了聚类分析中的K-means算法与粒子群算法相结合的方法作为本文章的电力企业同业对标管理的运行方法。第一,在同一类别的供电企业具有差不多的条件与企业规模。其结果具有可比性。在实际情况中,应重视同类供电企业之间对标,有效且及时知道企业服务中的薄弱环节,和存在的服务问题。有针对的提出改进措施。第二,K-means算法与粒子群算法的相互比较,结合两者的优势。提出了基于粒子群的K-means算法,不仅消除算法对聚类中心初值的依赖性,改进算法的聚类能,还能有效的降低迭代次数。
[1]Aoife Brophy Haney,Michael G Pollitt. International bench marking of electricity transmission by regulators: A contrast between theory and practice[J].Energy Policy,2013,62: 267-281.
[2]Aoife Brophy Haney,Michael G Pollitt.Exploring the determinants of“best practice”bench marking in electricity network regulation[J].Energy Policy,2011,39(12):7739-7746.
[3]TJamasb,M Pollitt.Benchmarking and regulation:international electricity experience[J].Utilities Policy,2000,9(03): 107-130.
[4]杨静,张宣江,盛慧慧,等.电力企业对标指标评价方法研究[J].华北电力技术,2009 (05):10-13.
[5]William Chung. Review of building energy-use performance bench marking methodologies[J].Applied Energy,2011,88:1470-147936(10): 55-57.
[6]王邦林.基于个性优势识别的标杆选评方法及其在同业对标中的应用研究[D].沈阳:东北大学,2007.
罗林波(1989-),男,湖南娄底新化人,本科,助理工程师,研究方向:电力运行维护,检修,电网规划。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
测控技术(2018年10期)2018-11-25 09:35:54
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
电子测试(2017年15期)2017-12-18 07:19:27
中国塑料(2016年11期)2016-04-16 05:26:02
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
物理与工程(2014年4期)2014-02-27 11:23:08
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:42
