
基于极值随机森林的慢性胃炎中医证候分类
2017-11-01 11:52:52,,,,,,3,
华东理工大学学报(自然科学版) 2017年5期
, , , , , ,3,
(1.华东理工大学机械与动力工程学院,上海 200237; 2.上海中医药大学四诊信息综合实验室,上海 201203;3.上海中医药大学交叉科学研究院,上海 201203)
基于极值随机森林的慢性胃炎中医证候分类
颜建军1,胡宗杰1,刘国萍2,王忆勤2,付晶晶2,郭睿2,3,钱鹏2
(1.华东理工大学机械与动力工程学院,上海200237;2.上海中医药大学四诊信息综合实验室,上海201203;3.上海中医药大学交叉科学研究院,上海201203)
大多数机器学习算法能得到较好的分类效果,但模型却无法解释;而随机森林等模型有良好的可解释性,却无法处理中医数据中兼证的情况。本文利用极值随机森林算法对慢性胃炎中医数据进行证候分类研究,其中决策树的叶节点能输出多个标签,通过加权机制综合分量来处理兼证问题。与已有多标记学习算法和C4.5、CART等基于决策树的算法进行比较,实验结果表明,极值随机森林算法无论在6个证型的分类准确率上,还是在多标记评价指标上都具有更好的效果,而且模型中得到的规则基本符合中医理论。
证候分类; 极值随机森林; 可解释性; 慢性胃炎; 决策树
辨证论治是中医诊断学的精髓,其中辨证是综合了临床各类信息并加以分析、归纳,以辨清疾病的病因、病机、病性和病位的过程。然而,在中医辨证中存在大量的不确定性和模糊性,缺乏客观的评价标准,制约了中医的推广和发展。利用数据挖掘、机器学习等计算机技术分析中医四诊信息,探索症状与证型之间的关系,构建中医辨证模型,实现中医诊断数字化和客观化,已成为中医诊断现代化发展的趋势。
大多数机器学习算法能得到较好的分类效果,但模型却无法解释。决策树用直观易懂的图结构模型来表示观测变量与观测变量、观测变量与标签之间的关系,从根节点到叶节点的每一条路径都有一个完整的决策规则[1],由此生成的模型具有良好的可解释性和分类效果,所以决策树在中医辨证模型的研究中得到了广泛应用。早在20世纪90年代,就有学者利用决策树提取专家经验,建立专家系统并取得了较好的结果[2]。本世纪研究者对中医辨证推理开始了比较深入的研究,应用决策树方法进行中医证型的分类,如文献[3-5]利用决策树算法建立了不同疾病的辨证模型。随着算法的不断改进,决策树在分类效果和可解释性的优势越发明显。2001年,Breiman等[6]提出随机森林算法,利用bootstrap重复采样技术来构建多个决策树模型,算法在样本数量大或者属性多的情况下处理效果非常好。文献[7-9]对随机森林算法开展了进一步研究,也取得了不错的成果。
然而,在这些传统的监督学习中,一个对象只对应一个标签,当学习对象明确且唯一时,这些算法在一定程度上能取得较好的分类效果,但它却无法处理一个对象对应多个标签的情况[10]。若一个样本和多个标签相对应,则称这样的数据为多标记数据,中医辨证就属于这类任务,中医临床兼证多见,即一个病人可能会对应多个证型。本文中慢性胃炎数据的证型包括脾胃湿热、湿浊中阻、脾胃气虚、脾胃虚寒、肝气郁滞和肝胃郁热6类,一个病例样本可能同时对应多个证型,属于典型的多标记数据。多标记学习是处理这类数据的有效方法,可以解决一个样本同时对应多个标签的情况,通过对大量的多标记数据样本进行训练得到多标记模型,通过该模型对未知的多标记样本进行预测。近些年来,也有学者将基于树的算法应用于多标记学习中[11-14],并对算法模型的解释性做了进一步研究[15-19]。本文利用极值随机森林(Extremely Randomized Forest,ERF)算法来处理慢性胃炎患者多兼证的问题,即多个证型同时输出的问题,通过加权机制综合分量来处理兼证问题,并与其他多标记算法和C4.5、CART等基于决策树的算法进行了比较。
1 实验方法
1.1ERF算法
ERF算法[20]根据自上而下的过程,生成一组无剪枝的决策树,与其他基于树的集成算法相比有2点不同:(1)属性的切割点是完全随机选择的;(2)使用整体学习样本(而不是重复采样)来生成决策树。ERF算法在每个分裂节点处随机选取k个不同的属性,生成k个分裂点,选取Score分值最高的分裂点将节点分裂为左右子树,建立决策树模型。极值随机森林算法伪代码如下:
extra_random_forest(S)输入:训练集S
输出:由M棵决策树T={t1,…,tM}组成的随机森林
Fori=1 toM
生成决策树ti=extra_tree(S)
Return 极值随机森林T
extra_tree(S)
输入:训练集S
输出:一棵决策树t
IF
节点中当样本数|S|<分裂所需要的最小样本数nmin,或节点中只存在一个标签,或候选属性唯一
Return 叶节点
else
随机选取k个不同的属性ai,…,ak,产生k个分裂点s1,…,sk
si=random_split(S,ai),∀i=1,…,k,选取结果最好的分裂点为最佳分裂点s*
Score=maxi=1,…,kScore(si,S),分裂为左右子树
左子树tl=extra_tree(Sl),右子树tr=extra_tree(Sr),直至节点变成叶节点
random_split(S,a)
输入:训练集S和属性a
输出:最佳分裂点s*
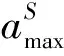
在分类问题上,Score的表达式为

(1)
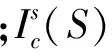
假设学习样本lSN={(xi,yi):i=1,…,N},N为总的学习样本数量,lt为决策树t的叶子,lt,i(x)为决策树t第i个叶子的特征函数,nt,i为第i棵决策树学习样本的数目。则t的特征函数lt(x)为
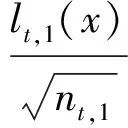
(2)
则模型可以表示为
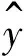
(3)
由式(2)、(3)可以看出:极值决策树模型可以看作基于核的模型,核可表示为
(4)
对于M个集成树T={ti:i=1,…,M},核的集成模型可表示为
(5)
由此得到预测模型
(6)
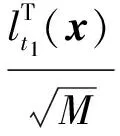
(7)
该集成核为
(8)
通过式(7)、(8)可以得到最终的集成预测模型(式6)。
以上算法包含了3个设定的参数:在任意节点上被随机选取的属性的数量k、分裂节点所需要的最小样本数量nmin和集成树的数量M。
1.2参数的选择
参数k表示ERF算法中每个节点的随机选择属性的数目。对于给定的问题,k越小,算法的随机化越强,学习样本的输出与模型结构的依赖性就越弱。在极端情况下,当k=1时,属性和切点会选择一个完全独立的输出变量。而在另一个极端情况下,当k=n时,属性的选择就不是确定的随机了,算法仅仅通过随机点的行为来影响随机效应。k的选择是算法可解释性的另一个重要体现。当k较大时,由于考虑了更多的属性之间的相互关联,得到的模型会具有较好的可解释性,但会使得算法模型分支太多而导致分类准确率下降,所以k的正确选择对算法有着重要影响。
nmin为ERF算法中节点分裂时所需的最小样本数量,是决策树停止准则中重要的参数。当节点中样本数小于最小分裂样本数时,该节点停止分裂,成为叶节点。较大的nmin不仅会降低树的深度和广度,还会导致较高的方差;但如果nmin较小,又容易出现过拟合现象,因此,原则上nmin最优值取决于数据集输出噪音的水平。
参数M表示集成树的数量,随机化方法的误差预测是M的单调递减函数。因此,M越高,表明其精确度越好。不同随机化方法对不同问题的解决,其收敛情况可能有差异,因为算法的收敛情况不仅取决于集成树的数量,还取决于样本量的大小和其他参数的设置。
1.3实验数据
919例慢性胃炎数据样本由上海中医药大学中医四诊信息综合研究实验室提供,采集自2008年9月~2010年10月上海中医药大学附属龙华医院、曙光医院、岳阳医院及上海市第八人民医院的胃镜检查室、病房和门诊等临床病例。所有病例都是经胃镜与病理组织学结果结合临床表现诊断确诊为慢性胃炎的患者。由具有中级职称以上(或具有博士学位)的医师根据问诊量表进行病史和症状、体征等方面数据的收集,记录包括面色、舌象及脉象等共113个特征,并标出每个样本具有的证型,制作成问诊量表。慢性胃炎中医诊断证型包括脾胃湿热、湿浊中阻、脾胃气虚、脾胃虚寒、肝气郁滞、肝胃郁热、胃阴虚、瘀血阻胃8个证型,但由于采集到的数据中,胃阴虚和瘀血阻胃出现的频次太少,本文中只对其他6个证型进行分析。
1.4比较方法
为了验证算法的性能,本文将ERF算法与BPMLL[21]、MLKNN[22]、RankSVM[23]、BSVM[24]、ECC[25]、LIFT[26]等多标记学习算法和C4.5和CART[27]等决策树算法进行了比较。
1.5实验性能评价准则
利用每个标签的分类准确率和多标记学习中常用的6个评价标准作为实验的性能评价指标[28],分别为覆盖距离(coverage)、汉明损失(hamming loss)、首标记错误(one-error)、排序损失(ranking loss)、平均精度(average precision)、平均AUC曲线下面积(average AUC)。
(1) average precision:高于某个特定标签y∈Y的相关标签的平均分数,其值越高越好,如式(9)所示。
(9)
(2) coverage:覆盖预测样本的所有相关标签,其值越小越好,如式(10)所示。
(10)
(3) hamming loss:汉明损失评估的是类别标签被错分的次数,其值越小越好,如式(11)所示。

(11)
(4) one-error:预测最高排序不属于相关标签集合的次数,其值越小越好,如式(12)所示。
(12)
(5) ranking loss:评估反向有序标签对的数目,即不相关标签排序比相关标签高的次数。其值越小越好,如式(13)所示。
|{(y1,y2)|f(xi,y1)≤f(xi,y2),
(13)
(6) average AUC[29]:即处于ROC(Receiver Operating Characteristic)曲线下方与一条斜率大小为1的直线所包含的那部分面积的大小,其值越大越好。
2 实验结果
将ERF算法与BPMLL、MLKNN、RankSVM、BSVM、ECC、LIFT等多标记算法和CART和C4.5算法进行比较。为了更清晰地比较各种算法的结果,使用双尾t检验将对应的10倍交叉数据进行统计分析,比较结果见表1,其中○表示ERF算法在统计学上劣于某算法,●表示ERF在统计学上优于某算法。
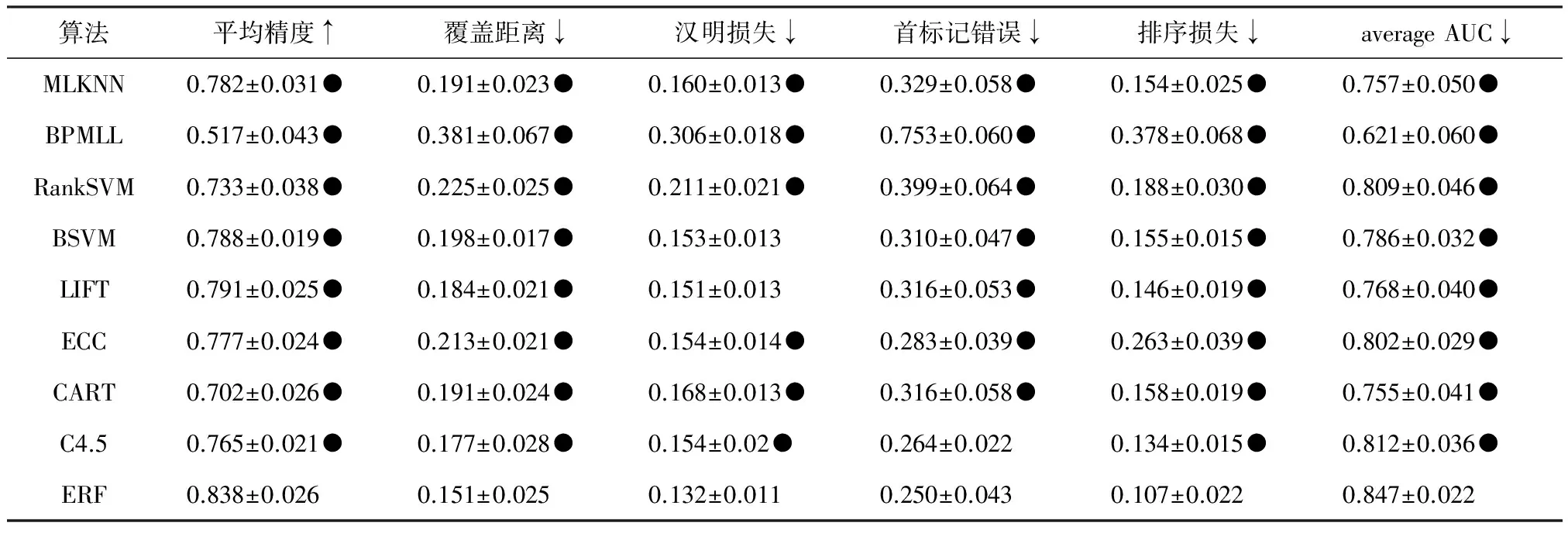
表1 各算法的多标记评价指标的实验结果
从表1可以看出,ERF算法在6个多标记评价指标上均优于其他几种算法,特别是在平均精度、覆盖距离、排序损失、平均AOC曲线下面积4个指标上具有明显优势。统计结果显示,在汉明损失上,BSVM和LIFT与ERF没有明显差异;在首标记错误上,C4.5与ERF也没有明显差异。
图1示出了各算法的证型分类准确率,从图1可以看出,ERF算法在脾胃湿热、脾胃气虚、脾胃虚寒、肝气郁滞上得到最高的分类准确率。对于湿浊中阻证,C4.5算法的分类准确率略优于ERF。对于脾胃虚寒证,ERF算法与MLKNN、BPMLL、BSVM、LIFT的分类准确率相同,分类效果最好。对于肝胃郁热证,MLKNN、BPMLL、LIFT的分类准确率略优于ERF算法。ERF算法在脾胃湿热、脾胃气虚、脾胃虚寒、肝气郁滞4个证型上取得了最好的分类准确率,在湿浊中阻和肝胃郁热2个证型上表现出了较好的分类准确率。
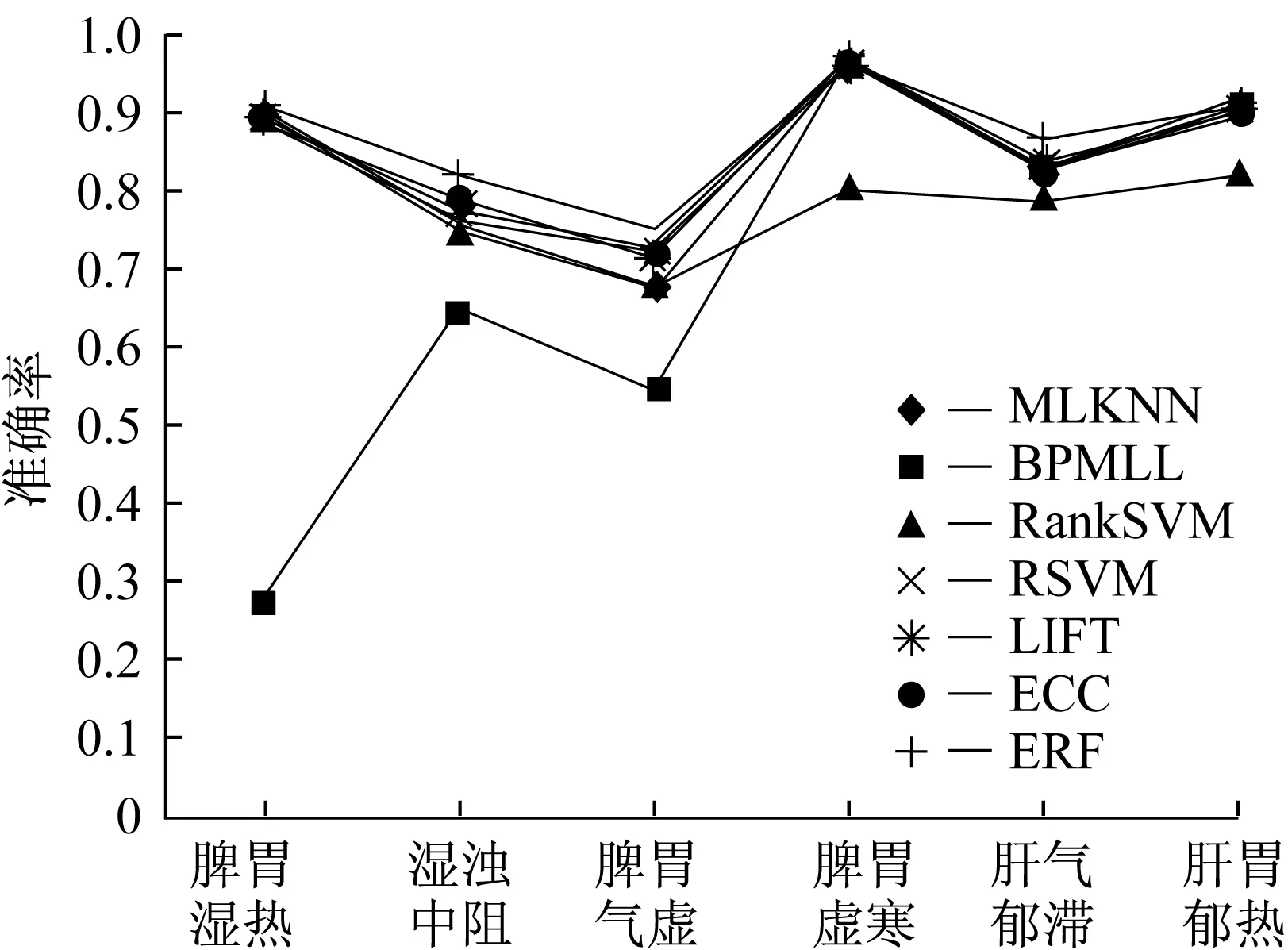
图1 各算法的证型分类准确率Fig.1 Classification accuracy of syndromes of each algorithm
3 讨 论

图2 平均精度随k/变化的结果Fig.2 Variation of average precision with different k/
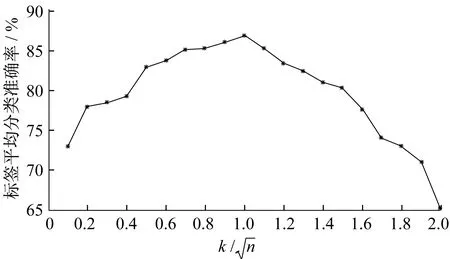
图3 标签平均分类准确率随k/变化的结果Fig.3 Variation of average classification
利用ERF算法推荐的参数设置可以提高精确度和降低计算复杂度,也减少了算法的运行时间,由于分割点是随机的,使得决策树在深度和广度上都有了一定的提高。ERF算法考虑了每个标签之间的联系,通过叶节点加权机制综合分量来处理兼证问题。决策树中每一条从根节点到叶节点的路径都有一个完整的决策规则,这就决定了算法模型有良好的可解释性。经过规则整理,本文对其中脾胃湿热证、脾胃气虚证分别给出一条辨证分类规则:
(1) 如果“苔腻:是”并且“舌色红:是”并且“舌中:是”并且“苔黄:是”并且“口粘腻:是”,那么该病人诊断为脾胃湿热。
(2) 如果“腻:否”并且“口气重:否”并且“乏力:是”并且“舌色淡白:是”并且“全舌:是”并且“苔白:是”并且“肢体沉重:是”,那么该病人诊断为脾胃气虚。
根据实证和虚症的诊断标准,这些决策规则基本符合中医理论,说明ERF算法具有良好的分类效果的同时,也具有较好的可解释性,这表明ERF算法能够有效地处理多标签的中医数据。因此,极值随机森林算法能够较好地处理症状和证型以及证型与证型之间的相互联系,所建立的模型具有良好的可解释性,有利于中医慢性胃炎证候诊断的标准化和客观化,也为中医诊断客观化提供了有益的参考和新的思路。
[1] 赵悦.概率图模型学习理论及其应用[M].北京:清华大学出版社,2012.
[2] 王勇.一种诊断外周神经系统疾病的专家系统[J].重庆大学学报,1994,17(4):104-109.
[3] 徐蕾,贺佳,孟虹,等.基于信息熵的决策树在慢性胃炎中医辨证中的应用[J].第二军医大学学报,2004,25(9):1009-1012.
[4] 查青林,何羿婷,喻建平,等.基于决策树分析方法探索类风湿性关节炎证病信息与疗效的相关关系[J].中国中西医结合杂志,2006,26(10):871-878.
[5] 廖晓威,马利庄,王彦.ES-ID3算法及其在中医辨证中的应用[J].计算机工程与应用,2008,44(32):191-195.
[6] BREIMAN L.Random forests[J].Machine Learning,2001,45(1):5-32.
[7] 刘永春,宋宏.基于随机森林的乳腺肿瘤诊断研究[J].电视技术,2014,38(15):253-255.
[8] 聂斌,王卓,杜建强,等.基于粗糙集和随机森林算法辅助糖尿病并发症分类研究[J].江西师范大学学报,2014,38(3):278-282.
[9] 范昕,赵桂新,孙萌,等.使用随机森林判别分析法预测黑加仑油胶囊治疗高血脂的效果[J].中医药信息,2012,29(4):43-47.
[10] 何志芬,杨明,刘会东.多标记分类和标记相关性的联合学习[J].软件学报,2014,25(9):1967-1981.
[11] DIMITROVSKI I,KOCEV D,LOSKOVSKA S,etal. Hierarchical classification of diatom images using ensembles of predictive clustering trees[J].Ecological Informatics,2012,7(1):19-29.
[12] VENS C,STRUYF J,SCHIETGAT L,etal.Decision trees for hierarchical multi-label classification[J].Machine Learning,2008,73(2):185-214.
[13] ZHOU T,TAO D.Multi-label subspace ensemble[C]//15thInternational Conference on Artificial Intelligence and Statistics.Berlin:Springer-Verlag,2012:1444-1452.
[14] JOLY A,GEURTS P,WEHENKEL L.Random forests with random projections of the output space for high dimensional multi-label classification[J].Lecture Notes in Computer Science,2014,8724:607-622.
[15] TAN S,SIM K C,GALES M.Improving the interpretability of deep neural networks with stimulated learning[J].IEEE Transactions on Neural Networks,2015,10:617-623.
[16] SHUKLA P K ,TRIPATHI S P.A Survey on interpretability-accuracy (I-A) trade-off in evolutionary fuzzy systems[C]//Fifth International Conference on Genetic and Evolutionary Computing.New Jersey:IEEE press,2011:97-101.
[17] OTERO F E B,FREITAS A A.Improving the interpretability of classification rules discovered by an ant colony algorithm:Extended results[J].Evolutionary Computation,2016,24(3):385-409.
[18] TURNER R.A model explanation system[EB/OL].[2015-12-22].http://www.inference.vc/accuracy-vs- explainability-in-machine-learning-models-nips-workshop-poster-review/.
[19] MAISTO D,ESPOSITO M.Improving accuracy and interpretability of clinical decision support systems through possibilistic constrained evolutionary optimization[C]//Eighth International Conference on Signal Image Technology and Internet Based Systems.Sorrento:Institute of Electrical and Electronics Engineers,2012:474-481.
[20] GEURTS P,ERNST D,WEHENKEL L.Extremely randomized trees[J].Machine Learning,2006,63(1):3-42.
[21] ZHANG M L,ZHOU Z H.Multi-label neural networks with applications to functional genomics and text categorization[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1338-1351.
[22] ZHANG M L,ZHOU Z H.ML-kNN:A lazy learning approach to multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048.
[23] TSOUMAKAS G,KATAKIS I,VLAHAVAS I.Data Mining and Knowledge Discovery Handbook[M].Berlin:Springer-Verlag,2010.
[24] BOUTELL M R,LUO J,SHEN X,etal.Learning multi-label scene classification[J].Pattern Recognition,2004,37(9):1757-1771.
[35] READ J,PFAHRINGER B,HOLMES G,etal.Classifier chains for multi-label classification[J].Machine Learning and Knowledge Discovery in Databases,2009,11:254-269.
[26] ZHANG M L.LIFT:Multi-label learning with label-specific features[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,37(1):107-120.
[27] TRENDOWICZ A,JEFFERY R.Classification and Regression Trees[M].Berlin:Springer-Verlag,2014.
[28] ZHANG M L,ZHOU Z H.A review on multi-label learning algorithms[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(8):1819-1837.
[29] DAVID J.Measuring classifier performance:A coherent alternative to the area under the ROC curve[J].Machine Learning,2009,77(1):103-123.
SyndromeClassificationofChronicGastritisBasedonExtremelyRandomizedForestAlgorithm
YANJian-jun1,HUZong-jie1,LIUGuo-ping2,WANGYi-qin2,FUJing-jing2,GUORui2,3,QIANPeng2
(1.SchoolofMechanicalandPowerEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China;2.LaboratoryofInformationAccessandSynthesisofTraditionalChineseMedicineFourDiagnosis,ShanghaiUniversityofTraditionalChineseMedicine,Shanghai201203,China;3.InstituteofInterdisciplinaryResearchComplex,ShanghaiUniversityofTraditionalChineseMedicine,Shanghai201203,China)
Syndrome differentiation and treatment,which is the essence of traditional Chinese medicine (TCM),contain abundant rules.The majority of machine learning algorithms can obtain good classification accuracy,but these models are difficult to be explained.The models established by random forests have great interpretability,while these models cannot deal with multi-syndrome that patients may simultaneously have more than one syndrome in TCM.In this paper,syndrome classification for Chronic Gastritis (CG) is researched by using extremely randomized forest (ERF) algorithm,and compared with state-of-the-art multi-label algorithms and the tree-based algorithms (such as C4.5,CART).The experimental results show that ERF algorithm has better performance than other algorithms in the classification accuracy of every label and the six evaluation metrics of multi-label learning.The rules obtained in the model are basically in accord with TCM theory.
syndrome classification; extremely randomized forest; interpretability; chronic gastritis; decision tree
R241
A
1006-3080(2017)05-0698-06
10.14135/j.cnki.1006-3080.2017.05.015
2016-12-30
国家自然科学基金(81270050,81302913,30901897,81173199)
颜建军(1975-),男,副教授,主要研究方向为复杂机电系统控制、中医四诊数字化和客观化、医学信号处理和图像处理。 E-mail:jjyan@ecust.edu.cn
刘国萍,E-mail:13564133728@163.com
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21 07:04:38
中老年保健(2021年5期)2021-12-02 15:48:21
今日农业(2021年19期)2021-11-27 00:45:49
基层中医药(2021年8期)2021-11-02 06:24:56
基层中医药(2021年8期)2021-11-02 06:24:54
基层中医药(2021年10期)2021-06-05 07:15:12
世界科学技术-中医药现代化(2021年12期)2021-04-19 12:31:06
基层中医药(2020年1期)2020-07-27 02:44:06
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
