
印刷体锡伯文文字切分技术研究
2017-10-21 14:27樊小超
新智慧·上旬刊 2017年11期
樊小超
【摘要】锡伯文是以单词为单位进行书写的黏连体文字,根据字母在单词中的不同位置,字母具有多种变体形态,目前锡伯文的字母切分和识别技术的研究刚刚起步。本文总结了黏连体文字的切分技术,主要包括行/列切分、单词切分和字母切分,并重点探讨了不同字母切分方法对黏连体文字识别的影响,从而为今后锡伯文的文字切分及识别提供必要的理论基础和技术指导。
【关键词】锡伯文切分技术;印刷体识别;字母识别
锡伯文记载着本民族的历史记忆和众多民俗文化,展示着锡伯族的特征和文化内涵,更是锡伯族非物质文化遗产的重要载体[1]。锡伯文是在满文字符基础上改革而形成的拼音文字,两种文字之间存在着一脉相承的关系,而满文曾经是清朝政府的官方文字,留下了海量的满文档案及文献资料,研究锡伯文的文字识别有利于珍贵历史文献的保护和考据;锡伯文是新疆通用的六种民族语言文字之一,在锡伯族的交际活动中占主要地位,许多报纸、期刊仍使用锡伯文,研究锡伯文的文字切分识别技术有利于锡伯族群众更好的融入现代化生活;锡伯族长期与汉民族共同生产生活,有逐渐失去本民族的语言文字的趋势,锡伯文文字切分识别技术研究有利于锡伯族语言、文字等文化要素的保存、传承和发扬,因此,锡伯文文字切分识别技术研究具有重要的理论价值和实际应用价值。本文的目的在于对现有的黏连体文字的切分技术进行梳理和总结,为今后的锡伯文识别算法提供理论基础和技术指导。
一、锡伯文字母识别
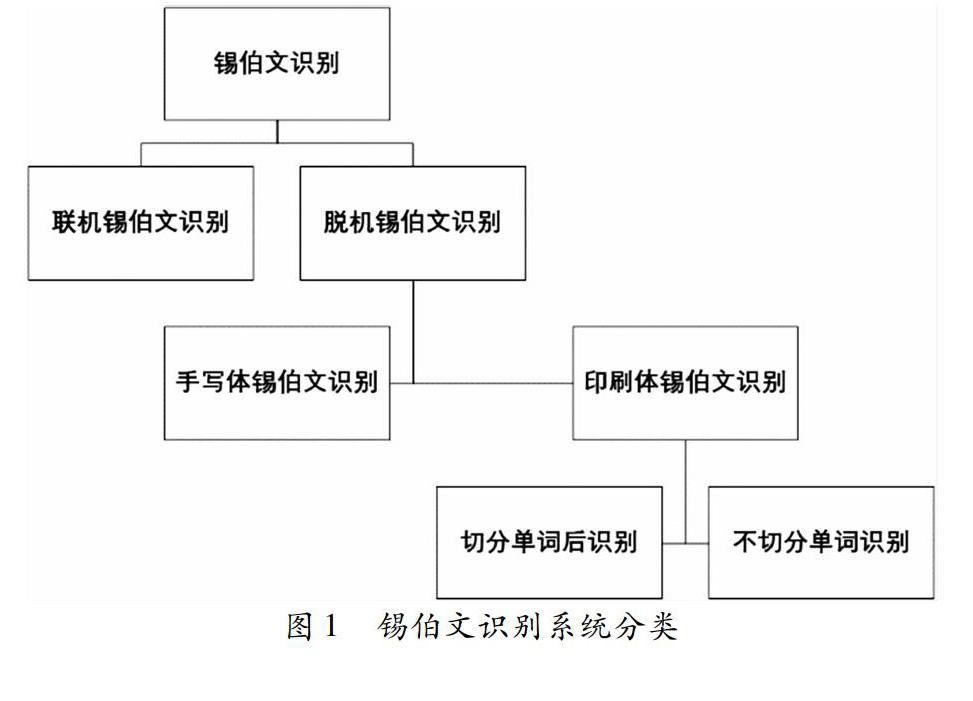
如图1所示,根据输入的字符信号的形式,字符识别可分为联机字符识别和脱机字符识别。脱机字符识别系统处理的是事先扫描好的书面文本图像。脱机识别又可分为两类:手写体字符识别和印刷体字符识别。手写体字符,可能由多个作者书写,书写没有统一规范,样式和大小各不相同。印刷体字符通常比较规范,采用统一的字体样式和大小。锡伯文识别领域,更多的需求是对印刷体锡伯文进行识别,通常识别有两种方式:不对锡
图1锡伯文识别系统分类
伯文单词进行切分,直接将单词作为一个整体进行识别,另一种方式是先将单词切分成字母,再识别出每个字母,根据识别出的字母及拼写规则还原出对应的单词。识别整个单词省略了切分過程,避免了切分过程对单词识别的影响,但是直接识别单词的难度却有所提升。切分后识别,识别的字母数量较少,对于字母的识别率较高,由识别出的字母还原单词比较简单,但是切分的质量直接影响着识别的效果。
二、字母切分技术
锡伯文识别过程中需要将文本切分成单元,如行、单词或字母,切分是一个重要的阶段,切分的好坏对锡伯文的识别结果具有直接的影响。切分可以分为以下几个阶段:
列切分:经过扫描的图像需要经过版面分析切分成多个部分,如文本、表格、图像等,将不同的部分给予标记,然后对文字部分图像进行段落划分[2]。阿拉伯文通常采用水平投影[3]的方法进行行切分。而对于锡伯文,由于其书写是自左到右,自上而下,所以不能采用水平投影的方法,可采用垂直投影法。
单词切分:将行或列切分后,需要进一步将其分割成单词。将一行/列分割成单词取决于单词之间的空间。锡伯文与中文不同,单词之间存在明显的空间,且印刷体较为规范,单词间空隙长度一致。常用的采用分析连通分量之间的距离来进行单词切分[4]。朱满琼等[5]对含有图像背景的满文图片进行了单词的提取,并进行了去燥、细化等处理。
字母切分:将单词切分成对应的多个字母。由于印刷体锡伯文书写时以单词为单位,不同的单词长度不同,单词的长度取决于该单词包含字母的数量,因此在进行锡伯文识别时,通常需要进行字母的切分。李伟等[6]提出了一种基于主干线的蒙古文切分方法。Lorigo等[7]提出了一种基于字母形状特征来进行脱机手写体阿拉伯文的字母切分和识别的算法。张广渊等[8]根据满文的文字结构特征提出了一种新的笔画提取方法。赵骥等[9]首先将满文单词分解为笔画基元,然后采用基于笔画序列的方法对满文进行识别。
锡伯文由于黏连的特性,字母的切分将是一项艰巨的任务,字母切分技术可以分为以下几类:
基于直方图:该方法将文本图像沿不同方向进行投影,根据黑色像素点的分布,基线的位置,以及计算得到的直方图的阈值进行图像的切分。Liu[10]等将直方图方法应用到阿拉伯文的图像切分中取得了较好的效果。春花[11]提出了一种基于基线的蒙古文切分方法。
基于细化:该方法通过连接相邻的聚类中心点从而生成字符的骨架,而字符骨架提供了关于字符形状的基本信息。细化通常可以通过检测字符的边缘点、断点和首尾点或进行模板匹配两种方式实现[12]。Tellache等[13]提出平行细化方法用于阿拉伯文字母切分和识别。
基于轮廓跟踪:该方法通过跟踪单词的外轮廓来切分单词。Sari等[14]中提出了一种基于轮廓分析和拓扑规则的字符分割算法,首先找到轮廓的局部极小点,然后利用拓扑规则确定局部极小点是否为分割点。
基于形态学:该方法根据图像的形态学特征选取合适的结构元素,然后对图像进行数学形态学计算以达到图像分割的目的。Albadr等[15]提出了一种基于符号形状的形态学方法,对无噪声的数据的识别准确率达到了99.4%,但该方法对有噪声的数据效果较差。
基于神经网络:该方法通过神经网络对有效的分割点进行验证。Hamid[16]提出了一种基于ANNs的手写阿拉伯语文本分割技术,首先利用形态学特征对单词进行预切分,然后用神经网络模型对预分割的分割点进行判定。Hongxi wei[17]等使用具有特定结构的BP神经网络对蒙古文进行切分和识别并取得了良好的性能。
然而,目前提出的大部分分割算法都不能解决锡伯文中字符重叠的问题。切分阶段是识别中最困难的阶段,也是错误的主要来源。因此,锡伯文的切分技术在锡伯文识别中仍然是最具挑战的问题。
三、结语
锡伯族的语言文字被完整的保留至今,然而随着时代的发展,锡伯语言文字受到了严重的威胁,亟待保护与传承。锡伯文的文字的切分及识别研究刚刚起步,研究成果较少,本文梳理了与印刷体锡伯文相似的黏连体文字,如蒙古文、满文及维吾尔文等的文字切分技术,主要包括列/行切分,单词切分和字母切分技术。字母的切分是锡伯文等黏连体文字在识别过程中面临的主要的问题与挑战,本文归纳总结了基于直方图、基于细化、基于轮廓跟踪、基于形态学和基于神经网络等多种方法进行的字母切分技术,为今后的锡伯文字母切分及识别技术的研究提供了理论基础和技术指导。
参考文献:
[1]李树兰,仲谦.锡伯语简志[M].北京:民族出版社,1986.
[2]陈明,丁晓青,梁健.复杂中文报纸的版面分析、理解和重构[J].清华大学学报(自然科学版),2001,41(1):29~32.
[3]田学东,郭宝兰.基于组合特征的中文版面分析方法[J].中文信息学报,1999,13(4):23~29.
[4]Aghbari Z A,Brook S. HAH manuscripts:A holistic paradigm for classifying and retrieving historical Arabic handwritten documents[J].Expert Systems with Applications,2009,36(8):10942~10951.
[5]朱满琼,李敏,许爽.图像背景下的满文文字提取[J].大连民族大学学报,2014,16(1):78~81.
[6]李伟,高光来,侯宏旭.印刷体蒙古文字识别技术中切分方法的设计与实现[J].内蒙古大学学报(自然版),2003,34(3):357~360.
[7]Lorigo L,Govindaraju V. Segmentation and pre-recognition of Arabic handwriting[C].International Conference on Document Analysis & Recognition. IEEE,2005.
[8]張广渊,李晶皎,王爱侠.脱机手写满文笔画基元的提取和识别[J].计算机工程,2007,33(22):200~202.
[9]赵骥,李晶皎,张广渊,等.脱机手写体满文文本识别系统的设计与实现[J].模式识别与人工智能,2006,19(6):801~805.
[10]Liu Zhi-Qiang,Jin-Hai Cai,Richard Buse.Handwriting recognition: soft computing and probabilistic approaches[J].Springer,2012(133).
[11]春花.印刷体蒙古文文字识别的研究[J].内蒙古民族大学学报(自然科学版),2014(6):627~628.
[12]Altuwaijri M,Bayoumi M. A new thinning algorithm for Arabic characters using self-organizing neural network[C].IEEE International Symposium on Circuits & Systems. IEEE,1995.
[13]Tellache M,Sid-Ahmed M A,Abaza B. Thinning algorithms for Arabic OCR[C].IEEE Pacific Rim Conference on Communications,Computers & Signal Processing. IEEE,1993.
[14]Sari T,Souici L,Sellami M. Off-line handwritten Arabic character segmentation algorithm: ACSA[C].International Workshop on Frontiers in Handwriting Recognition.IEEE,2002.
[15]Albadr B,Haralick R M. Segmentation-free word recognition with application to Arabic[C].International Conference on Document Analysis & Recognition.IEEE,1995.
[16]Hamid A,Haraty R. A neuro-heuristic approach for segmenting handwritten Arabic text[C].IEEE International Conference on Computer Systems & Applications. IEEE,2001.
[17]Wei H,Gao G. Machine-Printed Traditional Mongolian Characters Recognition Using BP Neural Networks[C].International Conference on Computational Intelligence & Software Engineering.IEEE,2009.
