
基于微博文本分类的突发地震事件检测方法
2017-10-21 03:40吴新华栾翠菊
网络安全与数据管理 2017年19期
吴新华,栾翠菊
(上海海事大学 信息工程学院,上海 201306)
基于微博文本分类的突发地震事件检测方法
吴新华,栾翠菊
(上海海事大学 信息工程学院,上海 201306)
事件检测是文本挖掘的一个重要研究方向,以微博文本的突发地震事件检测为例做了深入研究。首先分别运用三种经典的分类算法来实现突发地震事件检测,将检测结果进行比较,选择出一种最优的分类算法和最适合的特征数。在此基础上提出关键词过滤和时间关系识别的方法将错分的实例进行再分类来提高检测结果。实验表明该方法的检测结果与仅采用经典分类算法相比F1值提高了5.3%。
事件检测;文本分类;关键字过滤;时间关系识别关键词
0 引言
地震会造成严重的经济损失和人员伤亡,对人类生命财产安全有着极大的威胁。中国是一个地震灾害严重的国家,提高应对突发地震灾害的能力成为当务之急,而震后快速准确地检测灾情信息是地震应急工作的关键。通常地震发生后,在震区的民众希望可以第一时间得到灾情信息。由于互联网的快速发展,微博等社交媒体平台在舆情分析、观点挖掘突发事件检测等领域起到了重要作用,已成为灾害信息管理过程中的重要信息来源和沟通媒介。由于微博广泛的公众参与性和实时性,在震后灾情提取中表现出良好的应用前景。鉴于此,通过新浪微博平台,利用文本挖掘技术,研究一种高效的地震事件检测方法,将有效提高对地震灾害的应急管理能力。
1 相关研究
近年来,国外针对Twitter的突发事件检测[1-2]研究已取得了一定的成果。文献[3]提出了基于Twitter的实时地震监控系统;文献[4]通过调查150万个推特消息,结果表明Twitter的数据可以被用来作为一个有用的资源跟踪受自然灾害影响的公众情绪,以及一个早期预警系统。
国内关于利用社交媒体检测地震的研究甚少,大多偏向研究文本聚类[5-7]的突发话题检测技术。聚类目标是把相似的东西聚到一起,不关注具体类别。而分类的目标明确,将未知的数据分到已有的类别中。微博文本的突发地震事件检测要识别出突发地震的文本,判断一条微博是否属于突发地震事件的类别。因此采用分类的方法来实现更加有效。
白华[8]利用文本分类技术进行灾害事件探讨中,实现了地震灾害的爆发检测,研究过程中主要讨论了4种常见的文本分类算法。分别应用分类算法进行分类,最后得出支持向量机表现最优,F1值达到了0.890。基于此,本文应用文本分类来实现突发地震事件检测,在此基础上提出关键词过滤和时间关系识别来提高检测结果。
2 系统框架
本文研究主要概括为两个部分:文本分类与基于关键词过滤和时间关系识别的再分类。首先分别运用三种经典的分类算法来实现突发地震事件检测,将检测结果进行比较,选择一种最优的分类算法和最适合的特征数。在此基础上提出关键词过滤和时间关系识别的方法进行再分类来提高检测结果。系统框架图如图1所示。下面将详细描述文本分类和再分类的具体过程。
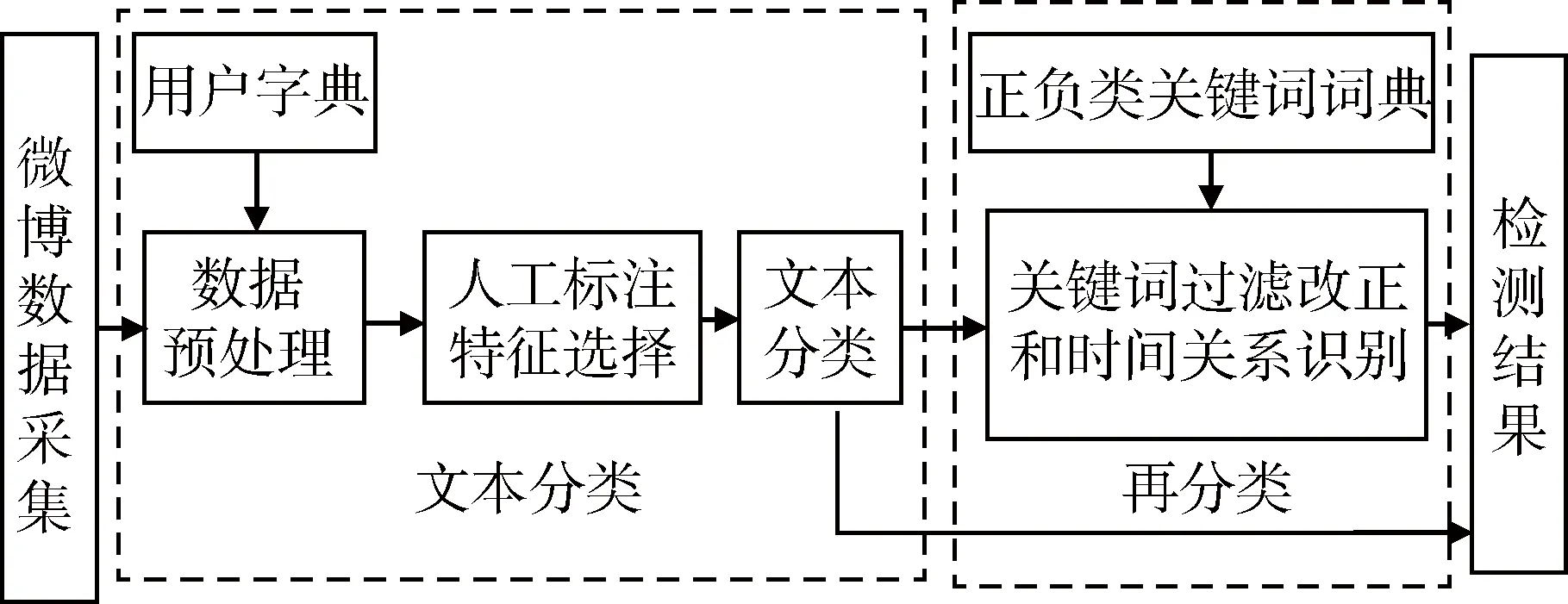
图1 突发地震事件检测框架图
2.1文本分类
实验主要通过调用数据挖掘工具weka接口编程实现,分别运用三种经典的文本分类算法:决策树[9](J48)、支持向量机[10-11](SMO)和朴素贝叶斯多项式模型[12](NaiveBayesMultinomial),这三种方法均在传统文本分类领域中取得了很好的分类效果。
2.1.1数据集
数据的获取是通过在微博搜索页面设置关键字“地震”和“震中”查询地震有关的微博,并对页面进行解析来爬取微博文本和微博发表的时间,经过去重后实验数据总数为1 368条,分别为2016-9-9~2016-12-22日之间与地震相关的微博文本。在这个数据集上进行人工标注,将描述突发地震事件的微博数据标为正类positive,其他标为负类negative。标注后正类数据703条,负类数据665条。至此,突发地震事件的检测问题就转化为二值分类问题。正负类示例数据如下表1所示。

表1 正负类示例数据表
2.1.2数据预处理
本文的数据预处理包括两部分,首先对微博文本分词,其次通过weka实现微博文本的向量空间的转换。
(1)中文分词。采用中科院提供的NLPIR汉语分词系统并根据本次实验中地震数据的特点建立用户词典进行中文分词,用户词典包含“防震减灾”、“地震活动盘点”等地震领域词汇,同时去掉微博文本中“@用户名”这样的内容。
(2)文本表示。通过weka平台StringToWordVecter过滤器将微博文本转换成向量空间模型,权重计算采用TFIDF算法。
2.1.3特征选择
构成文本的词汇数量越大表示向量空间的特征维度越大,为了提高分类效率和减小计算复杂度而又不影响分类的效果,需要对类别影响大的重要特征进行特征选择。实验中文本数据总特征数是1 653,分别取400、700、1 000、1 300、1 600五种数量的特征数进行分类比较。本文采用信息增益进行特征选择。在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。如式(1):
IG(wi,cj)=H(C)-H(C|wi)
(1)
2.1.4分类
分别运用三种经典的分类算法:决策树、支持向量机和朴素贝叶斯多项式模型进行分类,并分别取不同的特征数目,观察不同特征数对分类算法的影响,找出一种最优分类算法和最合适的特征数组合,以此作为改进的基础。
在二值分类问题中,分类结果有四种情况:将正类预测为正类(TP)、将负类预测为负类(TN)、将正类预测为负类(FN)和将负类预测为正类(FP)。
对分类算法性能的评估方法通常按照以下3个指标:准确率P=TP(TP+FP)、召回率R=TP/(TP+FN)、F1值F1=2TP/(2TP+FP+FN)。
图2是通过十折交叉验证取平均值算出的不同算法不同特征数对分类性能的影响指标。通过图2可以看出,表现最好的是Naive Bayes Multinomial特征算法在数为1 300和1 600时,它们的F1值都达到0.859。因此下一步将采用Naive Bayes Multinomial特征数为1 300作为分类基础进行分类改进并比较。
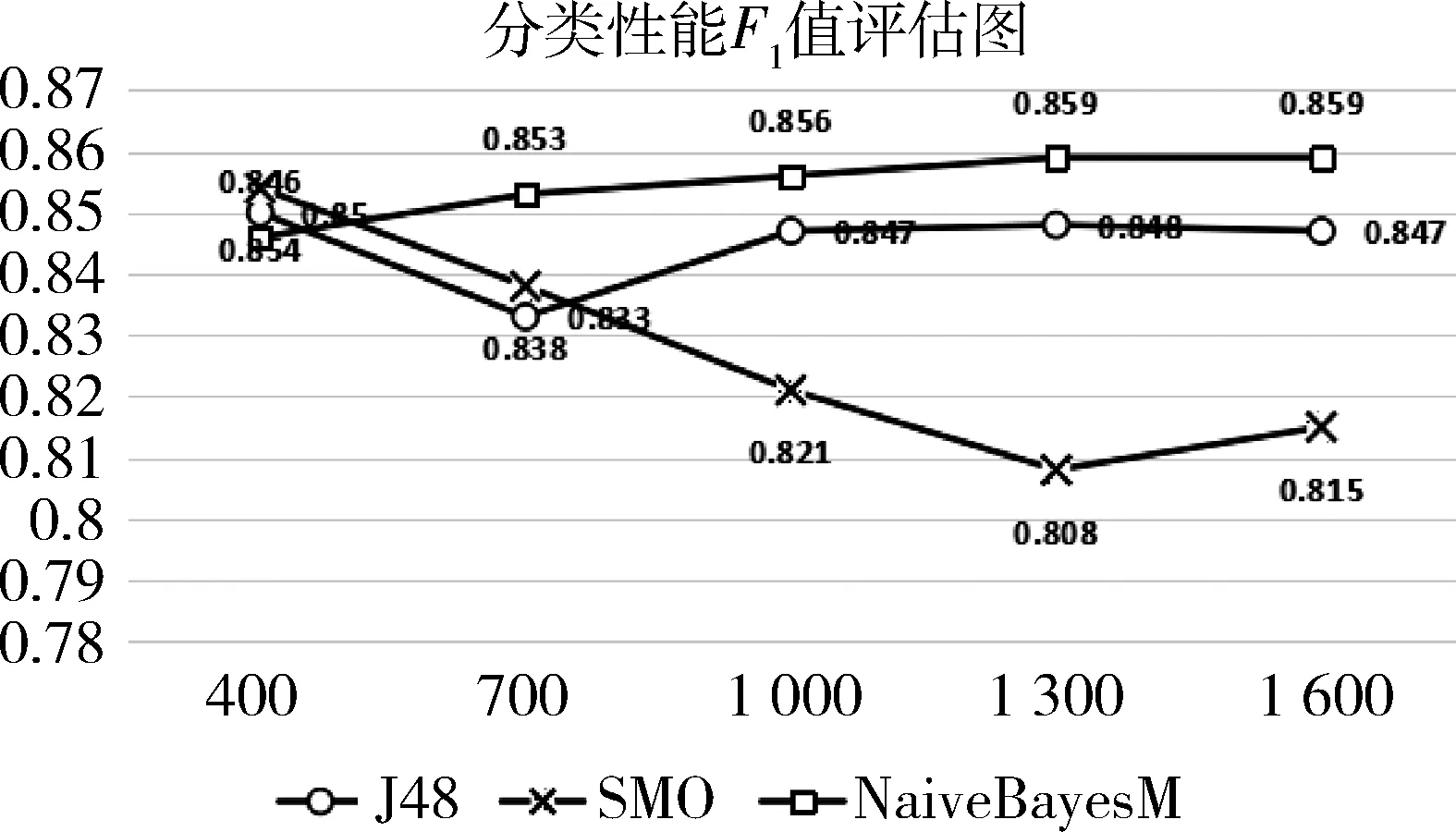
图2 分类性能评估表
2.2基于关键词过滤和时间关系识别的再分类
通过经典分类算法检测得出4种情况,其中分错的情况是将正类预测为负类(FN)和将负类预测为正类(FP)。预测错误的两类数据示例如表2所示。

表2 预测错误数据示例表
再分类的思想是尽量降低错误率,而这两类数据均有各自特点,通过这些特点把预测错误数据重新归为正确类别中。正类预测为负类的数据中大部分是描述刚发生的地震,含有“刚刚地震”、“?小时前地震”等两个关键词的组合,根据这些数据特点,提出关键词过滤的方法来纠正错误分类的数据。负类预测为正类的数据,该类微博数据是描述地震知识、防灾预警、描述历史地震等,其大部分含有“演习”、“防震减灾”、“悼念”等关键词,描述历史地震的微博中带有时间词的特点。根据这些数据的特征,先通过关键词过滤纠正,之后剩下的微博通过识别微博文本中所描述事件的时间并与微博发表的时间对比,以此判断是否为突发事件。
2.2.1将正类预测为负类的数据纠正
首先根据这些数据的特征,建立一个正类关键词词典KeyP,用来纠正被错误分类的含有正类关键词的微博数据,将其归为正类。正类关键词词典示例表如下表3所示。
但是,这两个关键词在微博文本中出现的位置不一定是相邻的,因此在建立正类关键词词典之后再利用集合的包含关系进行判断微博中是否包含组合关键词,方法是把整个的预测错误的微博数据看作一个大的文本集Text,每一条分完词的微博看作一个小集合Texti,集合的元素是该条微博中的每一个词,即Texti=(w1,w2,…,wn),再把正类关键词词典中每一组关键词看作一个集合KeyPxj={kx,k},如果微博数据Texti中包含任意一个关键词集合KeyPj,即Texti⊇KeyPj,则认为该条数据是描述突发地震事件并将其纠正为正类。
2.2.2将负类预测为正类的数据纠正
先通过关键词过滤纠正,建立一个负类关键词词典KeyN,将负类预测为正类的数据经过负类关键词词典过滤一遍,如果数据中含有词典中的任意关键词就把该数据归为负类。负类关键词词典示例如表4所示。

表4 负类关键词词典示例表
在经过负类关键词词典过滤后未能成功纠正的数据中,虽然不含有负类关键词,但大部分具有时间词的特征。因此,可以通过识别微博文本中事件的时间关系[13-14]并与微博发表的时间对比来确定是否为突发事件。这些数据大部分是描述以前发生的地震事件,且这些数据中时间关系描述得比较简单规范,大部分都有出现“?年?月?日”,因此利用正则表达式进行时间匹配识别。用于匹配的正则表达式是“Pat =(\d{4}年)?(\d{1,2}月)?(\d{1,2}日)?”。匹配出了时间再与微博的发表时间作减法比较,时间间隔小于三天则认为是突发地震事件,否则不是。如果微博中只出现“?年”则只与微博发表的年份比较,如果微博中只出现“?月日”则只与微博发表的月日作比较,“?月”和“?日”同理。
2.2.3再分类算法
综上,具体的再分类过程如算法1所示。
算法1再分类过程算法
Procedure Reclassification
Input: label ← Texti中标记的分类标签;prelabel ← 分类预测的标签
Output:通过再分类的微博文本Text
Preliminary: prelabel<>label
1 FOR i = 0 to len[Text]-1
2 DO Texti←Text[i]
3 IF label=“positive”THEN
4 IF Texti⊇KeyPj THEN
5 prelabel←“positive”;
6 ELSE IF Texti⊇KeyNj THEN
7 prelabel←“negative”
8 ELSE publish_t←查找微博发表时间“date:”
9 Texti _ t←Pat = (\d{4}年)?(\d{1,2}月)?(\d{1,2}日)?
10 IF publish_t - Texti _ t>3 THEN
11 prelable←“negative”;
12 END IF
13 END IF
14 END FOR
15 RETURN prelable;
END Reclassification
3 实验结果
采用Naive Bayes Multinomial特征数1 300作为分类基础,进行再分类改进得出的结果与单纯使用Naive Bayes Multinomial特征数1 300得到的结果进行对比,如表5所示,F1值提高了5.3%,证明通过关键词过滤和时间关系识别的再分类得到了更好的突发地震事件检测效果。图3给出了用weka绘制改进前和改进后的方法评估ROC曲线图,从图中可以明显看出改进后(上面)的分类效果要比改进前(下面)的效果好,即通过关键词过滤和时间关系识别的方法提高了微博文本突发地震事件的检测效率。

表5 改进前改进后结果对比表

图3 ROC曲线图
通过关键词过滤和时间关系识别来进行再分类的检测结果中F1值达到0.912,与文献[8]中仅采用经典分类算法得到的结果“支持向量机表现最优F1值达到了0.890”相比,F1值有提高。
4 总结与展望
通过关键词过滤和时间关系识别进行再分类后F1值提高了5.3%,这对于地震灾情信息的获取和应急管理有很大帮助。但这种方法做得还不够完善:(1)正负关键词词典还不够完整,收录的仅仅是本次实验中用到的数据集中的一些特征词,需要从更多的数据中发现新词来扩充词典;(2)关键词过滤的方法考虑得过于简单,例如微博文本中出现关键词“梦到地震”就认为该条微博不是描述突
发地震事件,但是“梦到地震,醒来真的地震了,衣柜和床都在晃动”却是在描述突发的地震事件,对于这种情况,以后将考虑深层的语义分析;(3)本次实验的时间关系识别是简单的通过正则匹配来实现的,如果文本中出现了两个事件的时间词将默认匹配第一个,这也导致少量的一些具有多个时间词的数据分类结果不可信,未来将从事件抽取的角度出发去找出描述地震事件的时间词。
[1] ATEFEH F, KHREICH W. A survey of techniques for event detection in twitter[J]. Computational Intelligence, 2015,31(1): 132-164.
[2] LI R, LEI K H, KHADIWALA R, et al. TEDAS: a twitter-based event detection and analysis system[J]. 2012 IEEE 28th International Conference on Data Engineering,2012, 41(4):1273-1276.
[3] SAKAKI T, OKAZAKI M, MATSUO Y. Earthquake shake twitter users:real-time event detection by social sensors[C]. The 19th International Conference on World Wide Web, WWW’10.New York, ACM2010: 851-860.
[4] DOAN S, VO B K H, COLLIER N. An analysis of twitter messages in the 2011 tohoku earthquake[J]. Computer Science, 2011, 91: 58-66.
[5] 高永兵,郭文彦,周环宇,等.基于K-means的私人微博聚类算法改进[J].微型机与应用, 2014,33(14): 78-81.
[6] 王勇,肖诗斌,郭跇秀,等.中文微博突发事件检测研究[J]. 现代图书情报技术, 2013, 230(2): 57-62.
[7] 郭跇秀,吕学强,李卓.基于突发词聚类的微博突发事件检测方法[J].计算机应用, 2014, 34(2): 486-505.
[8] 白华,林勋国. 基于中文短文本分类的社交媒体灾害事件检测系统研究[J]. 灾害学, 2016,31(2): 19-23.
[9] ROKACH L, MAIMON O. Data mining with decision trees: theory and applications(2nd Edition)[M]. World Scientific, 2014.
[10] BY C J. Burges a tutorial on support vector machines for pattern recognition[J]. Data Mining & Knowledge Discovery, 2010, 2(2): 121-167.
[11] FLAKE G W, LAWRENCE S. Efficient SVM regression training with SMO[J]. Machine Learning, 2002, 46(1): 271-290.
[12] BERMEJO P, GMEZ J A, PUERTA J M. Improving the performance of Naive Bayes multinomial in e-mail foldering by introducing distribution-based balance of datasets[J]. Expert Systems with Applications, 2011, 38(3): 2072-2080.
[13] 谭红叶,郑家恒,梁吉业.时间关系识别研究进展[J].中文信息学报, 2011, 25(5):44-52.
[14] 王风娥, 谭红叶, 钱揖丽. 基于最大熵的句内时间关系识别[J]. 计算机工程, 2012, 38(4): 37-39.
A method for detecting sudden earthquake events based on micro-blog text classification
Wu Xinhua, Luan Cuiju
(Department of Information Engineering, Shanghai Maritime University, Shanghai 201306, China)
Event detection is one of the most important research fields in text mining, and an in-depth study is carried out in the case of micro-blog. First, used three kinds of classical classification algorithms to detection the sudden earthquake events, and the results were compared, selected an optimal classification algorithm and the most suitable number of features. Then, basis of this, put forward the method of keyword filtering and temporal relation recognition to classify the wrong examples to improve the detection results. Experimental results show that the proposed method can improve theF1value by 5.3% compared with the classical classification algorithm.
event detection; text categorization; keyword filtering; temporal relation recognition
TP18
A
10.19358/j.issn.1674- 7720.2017.19.017
吴新华,栾翠菊.基于微博文本分类的突发地震事件检测方法[J].微型机与应用,2017,36(19):58-61,65.
2017-04-10)
吴新华(1992-),通信作者,女,硕士,主要研究方向:数据挖掘、自然语言处理。E-mail: alicewoo_hi@163.com。栾翠菊(1974-),女, 博士, 副教授,主要研究方向:智能决策、数据挖掘等。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
数学小灵通(1-2年级)(2021年4期)2021-06-09
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
小学生作文·小学低年级适用(2018年12期)2018-04-11
初中生世界·七年级(2017年9期)2017-10-13
现代防御技术(2016年1期)2016-06-01
