
浅谈MapReduce与关系型数据库技术的融合
2017-10-19 07:58邹香玲
河北软件职业技术学院学报 2017年3期
门 威,邹香玲
(河南广播电视大学,郑州 450000)
浅谈MapReduce与关系型数据库技术的融合
门 威,邹香玲
(河南广播电视大学,郑州 450000)
虽然关系数据库擅长于OLTP事务处理,但在处理大规模数据时却性能不足。MapReduce凭借其易操作性、高扩展性和高并发性,在大规模数据处理中占据优势。结合这两种技术,设计出兼有两者优点的技术架构是解决大数据分析问题的重要途径之一。二者共生的大数据生态系统成为技术融合的重要趋势。
关系型数据库;MapReduce;大数据分析
0 引言
在数据存取方面,传统的关系型(分布式)数据库在OLTP事务处理方面表现出高性能的特性,但是当索引和数据集增长到一定程度时,却性能不足[1]。MapReduce是一种基于并行计算的数据处理架构,可运行在分布式服务器集群上,通过“分治策略”提高数据处理效率,在大规模数据处理和分析方面表现出高效能和高容错性的特点。关系型数据库与MapReduce各有特点,如何从数据查询或组织等中心环节入手,整合两种技术,设计出既具备关系型数据库的高性能,又支持MapReduce高扩展性的混合架构,成为大数据分析技术的重要研究方向之一。
1 MapReduce数据处理架构
MapReduce计算模型最初于2004年由Google提出,其为大数据处理与分析提供了一种有效的解决方案[2]。MapReduce可被理解成一类编程模型,在不同的编程语言中有不同的实现,其函数式用于处理和构建大数据集,可并行执行在大规模计算机集群上。MapReduce架构为程序员屏蔽底层复杂性,甚至允许没有分布式编程经验的程序员轻松利用函数接口执行大规模数据的分布式运算。MapReduce是由Map与Reduce两个阶段组成的。Map函数用于处理输入数据(Key/Value对)并产生中间结果,Reduce函数对中间结果排序、合并、计算并输出最终结果。具体过程如图1所示。
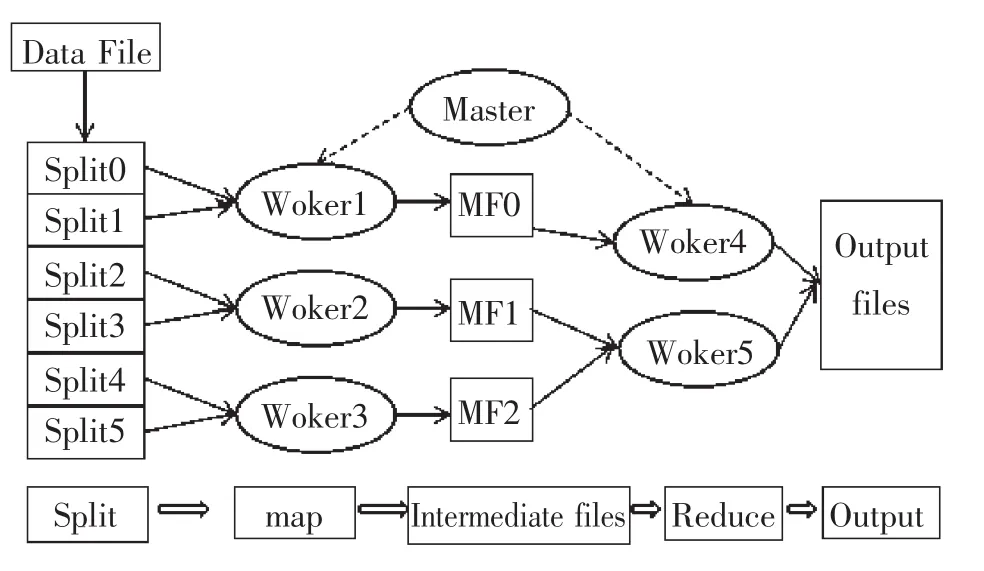
图1 MapReduce计算模型
(1)MapReduce函数库中的文件分隔函数将存储数据文件分割成M块(自Split[0]至Split[M-1]),块的大小可使用参数设定。
(2)子块被加载到集群中的工作节点(Worker)上。主控节点(Master)负责调度各工作节点,将M个Map任务与N个Reduce任务分解到多个空闲的Worker节点上。
(3)Worker节点接到任务后会自动读取和处理相关输入数据,并将中间结果以Key/Value对的形式缓存起来。
(4)当缓冲区内的数据超过阈值或到达定时器节点时,被flush到本地存储。Master负责将数据块位置信息等元数据传输给Reduce Workers,它们将读取中间数据并按照Key值进行排序,使Key值相同的记录聚集在一起。
(5)Reduce Worker利用自定义的Reduce函数处理Key值相同的中间数据,并将各自区域的数据输出到输出文件。
(6)在所有的Map和Reduce任务都完成后,Master负责将数据汇总输出并返回到程序调用点。
MapReduce采用“分治”策略,将单任务分解成多个任务,通过任务并行达到提高数据处理效率的目的。
2 MapReduce与关系型数据库融合技术
在MapReduce与关系型数据库技术融合方面,中国人民大学谭雄派等在《大数据分析——RDBMS与MapReducede的竞争和共生》[3]一文中指出:关系数据库相对于MapReduce具有更高的性能,而MapReduce在容错性和扩展性方面更胜一筹,两者各有优缺点。如何将二者进行融合,设计出同时具备两者优点的数据存储架构成为大数据分析技术的重要研究方向。
HadoopDB在MapReduce和关系型数据库技术融合方面采取的策略是将系统分为两层:下层利用关系型数据库Postgresql进行数据查询,而上层利用Hadoop技术对任务进行划分和调度。该方法既利用Hadoop数据处理机制提高了系统的容错能力和扩展能力,又利用关系型数据库提高了数据查询和存储性能。试验结果,HadoopDB的数据查询性能依然无法与关系型数据库相匹敌,这需要改进和优化MapReduce架构以提升其性能。
Aster Data和Greenplum公司在关系型数据库的基础上,将MapReduce内置于大规模并行处理机MPP,将MPP核心引擎与MapRed作业引擎整合,将查询分析函数交给MapReduce执行,这些分析函数可以并行执行在MPP上,相对于关系型数据库的自定义函数来说,性能得到极大提高。分析函数以分析软件包的形式发布。该策略利用MapReduce架构提高了分析函数的执行效率。
Vertical、Oracle、Teradata 等数据库公司也在致力于研究关系型数据库与MapReduce的融合技术。各自策略虽有不同,但基本类似:在关系型数据库引擎内置MapReduce作业调度机制。Vertical数据库于2009年启动MapReduce技术整合研究。改进后的Vertical数据能够处理结构化、半结构化和非结构化数据。Teradata设计的架构相对简单,仅实现HDFS(Hadoop File System)和数据表之间的转换以及数据装载的加速。
2.1 Dumbo与LinearDB模型
中国人民大学高性能数据库实验室以数据组织和查询为切入点,研究MapReduce和关系数据库融合技术,设计出兼具关系数据库性能和MapReduce高扩展性的数据仓库查询框架,提出了下述两个研究方向[4]。
(1)Dumbo模式采用关系数据库技术,并使用MapReduce模式改造OLAP查询过程,提高其处理OLAP查询的效率。Dumbo根据HDFS的特点优化存储数据,采取有效的层次编码技术把维表数据压缩至事实表。Dumbo在MapReduce框架的基础上进行扩展,设计了新型的OLAP处理框架 TMRP,即 Transform、Map、Reduce、Postprocess流程。
在Dumbo架构下,数据查询首先被转换成MapReduce任务。在Map阶段,该任务以流水线模式扫描和汇聚本地数据,并在Reduce阶段执行数据运算、筛选、排序与合并等操作。Master在Postprocess阶段负责Data Node上数据集的连接操作。经实验表明,Dumbo数据查询性能高于HadoopDB。
(2)LinearDB借用MapReduce的设计思想提高OLAP查询的可扩展性。该模型采用无连接雪花模型,利用层次编码技术将维表信息压缩至事实表,使事实表进行独立的谓词、聚集等数据查询操作,从而把大规模集群上的数据连接操作转化成局部操作。LinearDB查询过程简称TRM(Transform、Reduce&Merge)。在 Transform 操 作 中,Master将维表上的谓词判断、聚集等操作转换成事实表的操作。在Reduce阶段,Data Node并行扫描数据,将结果提交给Master。最后在Merge阶段,Master对Data Node返回的数据进行过滤、排序和合并。TRM模型的主旨是将查询划分成多个子任务并加载到MPP上并发执行。执行失败的子任务可在其他备份节点上重新执行,具备较好的容错性。LinearDB结合了MapReduce处理模式和关系型数据库的层次编码、泛型关系等技术,其执行代价主要在于Reduce操作复杂度。该模型可以获得接近线性扩展能力。
Dumbo与LinearDB在一定程度上实现了关系型数据库和MapReduce的技术融合,但在数据预处理上花费的时间较多(约是普通预处理时间的7倍左右),有待进一步优化。
2.2 基于分块机制的ChunkDB模型
东北大学师金钢等在借鉴分布式文件系统HDFS架构的基础上,提出了基于分块机制的数据库模型ChunkDB[5]。该数据库模型整体结构如图2所示。
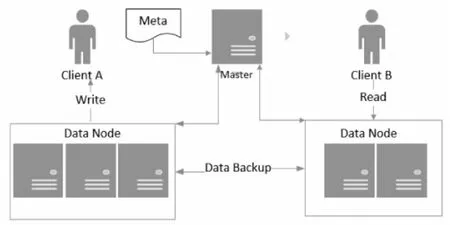
图2 数据存取架构图
图2 中显示了系统的三个主要角色:Master、Data Node和Client。其中Master负责数据块基本信息和Data Node信息的管理,如实时监测节点运行状况、维护节点信息表、存储数据块位置和副本信息;Data Node负责数据存储,受Master统一管理;Client负责运行客户端应用程序。
为通过并行计算提高查询效率,系统首先要将待存储数据表进行分块并存储到多个数据节点中。系统采用类似于基于列(类似HBase)或基于记录的分块划分方式。若采用基于记录的划分方式,各子块可被独立查询或添加索引。数据表被划分成多个子块的同时,也创建子块副本,以保障系统容错性。当子块尺寸和副本数量确定后,Client便可根据设定参数向Data Node写数据,同时将元数据信息写入到Master。当Client读取数据时,首先读取Master中的元数据,然后根据元数据信息读取Data Node。
子块在Data Node中的分配方法可采用轮询或哈希策略。其中轮询策略将排序好的数据块按顺序存储,哈希分布策略则根据块id计算出的hash值将数据块存储到相应的Data Node上。
通过借鉴HDFS架构,Master中应包含集群节点信息表、已存储数据表基本信息表、数据块分布表和分块策略表等。
集群节点信息表用于存储集群节点信息,包括节点id、类型、角色、用户、密码、RDBMS连接字符串、数据库驱动和节点状态等信息。所有的节点由Master统一管理,并保持实时通信。
数据表基本信息表用于存储数据表的基本信息,包括表id、表名称、表大小、是否分块、分块大小、副本个数等信息。Client读取数据时,首先获取id,通过元数据关联查询获取数据子块信息。
数据块分布表用于存储数据块基本信息,包括数据块id、编号、地址、所在Data Nodeid、从属的数据表id、副本编号等。Client通过表关联查询到某数据表的所有数据块,然后从数据块中读取最终数据。
用户提交任务后,系统首先读取Master数据表,判断任务中涉及的数据表是否在系统中存在,如果表存在,则继续读取数据块分布表,找出数据表的所有分块并启动map任务,将多个分块传递给map任务进行数据检索,最后利用Reduce操作对结果进行排序、筛选、合并和聚集,最终输出结果(与MapReduce处理流程相同)。
MapReduce默认的DBInputFormat接口多用于操作单一的数据库,因此系统需要对该接口进行扩展以适应分布式数据库环境。类似于HDFS从Name Node读取文件数据块信息的方式,系统从Master中读取数据块信息,然后由分块信息生成输入数据块。扩展后的接口在操作分布式数据库方面和HDFS的操作方式相同。
3 基于MapReduce与关系型数据库的共生系统
在海量数据处理过程中,大数据分析的基本原则是将计算放在数据中,避免数据移动。传统的基于关系型数据库的大数据分析系统借助于外部ETL工具将待分析数据导入到数据库中,利用SQL语言进行数据分析并生成报表。由于SQL语言的局限性,系统需要将数据导出到外部工具(SPSS等)进行数据分析。这种模式的缺点在于数据导入导出过程造成大规模数据移动,导致系统性能下降。相对于关系型数据库,MapReduce在计算或存储模式上具有更好的容错性与扩展性,能为大数据分析提供更好的平台。在深度分析方面,MapReduce的函数表达式胜过SQL函数。
以Facebook为代表的新型大数据分析系统应运而生,如图3所示。Facebook单一集群的数据量超过100PB,每天新增的数据量超过500TB。在Facebook的数据架构中,OLTP事务处理由关系型数据库负责,交易数据的管理和分析由Hive负责。Hive系统的数据分析结果导入到关系型数据库中,用于用户查询。为减轻即时查询给Hive核心系统造成的压力,即时查询交给备份的Hive服务器。Facebook的数据分析系统利用基于MapReduce的Hive-Hadoop架构,实现了系统高扩展性,同时利用关系型数据库擅长OLTP事务的特点,使其用于处理数据的导入和分析结果的输出,从而有效结合二者优点。
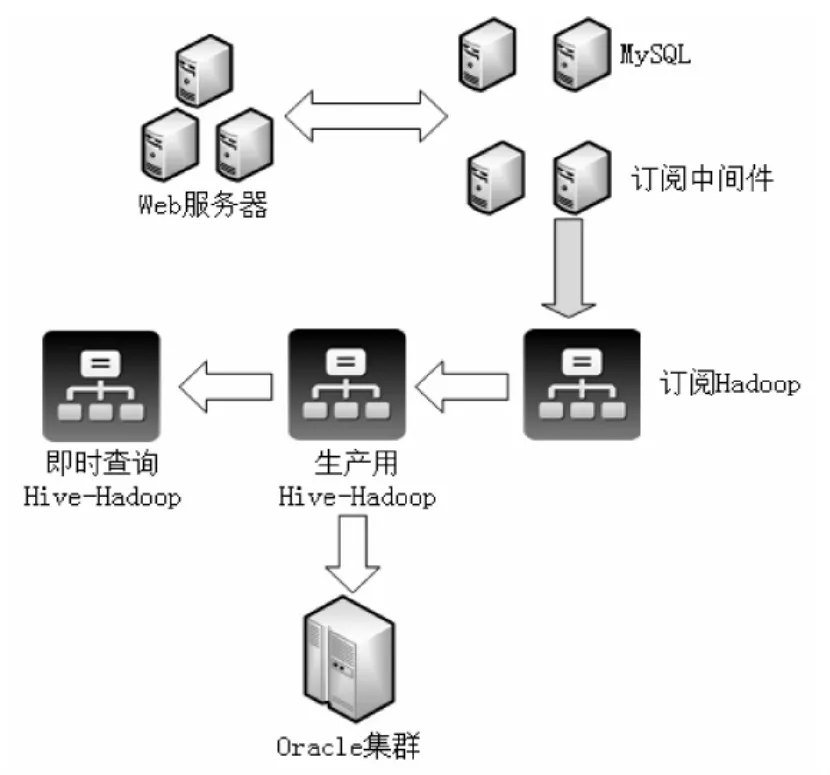
图3 Facebook数据平台架构
4 结论
在大数据分析处理过程中,关系型数据库在可扩展性方面的不足成为制约其性能的主要瓶颈,SQL语言难以满足复杂的数据分析需求。通过将关系型数据库和MapReduce进行技术融合,将MapReduce架构可扩展性、容错性等优势与关系型数据库的高性能结合起来,设计出同时具备二者优点的数据存储架构,是解决大数据分析问题的重要途径。在技术融合方面,Yale、Aster Data、Greenplum、中国人民大学高性能数据库研究小组以及东北大学于戈教授等分别给出了不同解决方案。其共同点是利用关系型数据库和MapReduce技术整合打破单一技术的局限性,最终通过两种技术的相互渗透、相互学习产生新的大数据生态系统。
[1]张滨,陈吉荣,乐嘉锦.大数据管理技术研究综述[J].计算机应用与软件,2014(11):1-5,10.
[2]李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011(11):2635-2642.
[3]覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce 的竞争与共生[J].软件学报,2012(1):32-45.
[4]王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011(10):1741-1752.
[5]师金钢,鲍玉斌,冷芳玲,等.基于MapReduce的关系型数据仓库并行查询[J].东北大学学报:自然科学版,2011(5):626-629.
A Brief Discussion on the Integration of MapReduce&Relational Database
MEN Wei,ZOU Xiang-ling
(Henan Radio and Television University,Zhengzhou 45000,China)
RDBMS is good at OLTP,but its performance is inadequate when dealing with massive data.MapReduce uses its easy operability,high scalability and high concurrency to show high efficiency on processing large-scale data.Technical architecture with both advantages is one of the important ways to solve the problem of big data analysis.The ecosystem with both symbioses is becoming an important trend of technology integration.
Relationed Datebase;MapReduce;Big Data Analysis
TP311
A
1673-2022(2017)03-0010-04
2017-03-21
河南省科技厅科研项目(172102210235);河南省教育厅科研项目(16B520008);国家开放大学科研项目(G16F2406Q)
门威(1988-),男,河南永城人,讲师,硕士,研究方向为软件工程;邹香玲(1987-),女,河南周口人,讲师,硕士,研究方向为计算机软件。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
房地产导刊(2022年4期)2022-04-19
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
汽车工程(2021年12期)2021-03-08
党员生活·下(2020年3期)2020-04-20
党员生活(2020年2期)2020-04-17
山东农业工程学院学报(2020年12期)2020-03-19
时代人物(2019年27期)2019-10-23
铁道通信信号(2018年10期)2018-12-06
计算机测量与控制(2017年6期)2017-07-01
