
变电站智能诊断和维护系统体系结构研究
2017-10-17 11:57:57李福鹏梁国坚陶熠昆郑洪波
电源技术 2017年9期
李福鹏,梁国坚,陶熠昆,郑洪波
(1.广东电网有限责任公司中山供电局,广东中山528400;2.浙江国自机器人技术有限公司,浙江杭州310053)
变电站智能诊断和维护系统体系结构研究
李福鹏1,梁国坚1,陶熠昆2,郑洪波2
(1.广东电网有限责任公司中山供电局,广东中山528400;2.浙江国自机器人技术有限公司,浙江杭州310053)
在实际运行的过程中,具有相似故障征兆的变压器往往具有大致相类似的故障原因,因此,依托于变压器的运行数据,采取基于数据驱动的变压器故障分析是实现变电站智能控制和诊断的有效方法。利用MapReduce构建了多数据源的并行特征提取与对比算法,可以有效地对变压器故障征兆进行分析,从而实现故障点的及时维护。
变电站;故障智能诊断;数据驱动
Abstract:In the process of actual operation,the transformer with similar fault symptom often had the similar cause of the fault.Therefore,it was an effective method to realize the intelligent control and diagnosis of the transformer based on the data failure of the transformer.MapReduce was used to construct a parallel feature extraction and comparison algorithm of multiple data sources,which could effectively analyze the fault symptoms of the transformer,so as to realize the timely maintenance of the fault point.
Key words:substation;fault intelligent diagnosis;data driven
随着电网复杂程度的提高,变电站作为供电方与用电方的中间变换环节,其作用也日益显著,而作为电网的重要一环,有效及时地实现变电站的故障维护是保证电网稳定运行的前提条件[1]。
我国现有的变电站大多都实现了自动化的管理,但管理大多停留在设备运行数据的采集、事故情况的记录、故障的报警等方面,对于故障的成因等深层次的故障诊断并未涉及。显然,随着电力系统的进一步复杂,利用现代的数据处理技术对大量的运行数据进行有效地处理,追根溯源,发现事故的深层次原因,对预防性变电站维护和缩短事故的处理时间,具有重要的意义
1 变电站故障诊断方法的研究
对于故障的诊断,目前常用的方法主要有三大类型,分别是基于常见问题点的数学模型的方法、基于故障点的知识分析的方法、基于运行数据驱动的分析方法[2]。
基于常见问题点的数学模型的方法比较适合于运行过程比较简单的场合,具有数据模型构造简单,故障检测反应时延小及准确的优点。但是,对于复杂的工业控制过程,由于工作的过程相对而言具有很强的非线性和时变性,同时系统与系统之间还存在着强耦合性,故构建数据模型的过程较为困难。对于变电站而言,利用数学模型来构建故障检测系统并不是一种最优的选择。
基于故障点的知识分析的方法主要是利用专家知识系统、神经网络、模糊算法、故障决策树等计算方法来对变电站的故障进行分析。这种方法的准确性依赖于所选计算方法的准确程度,而在实际运行的过程中,每一种计算方法所固有的缺点都会影响最终判断的结果,而对于大多数方法而言,构造出完全反映变电站的运行过程是一个比较困难的事情。
基于运行数据驱动的分析方法是从大量的运行过程数据中分析出准确的故障信息,所利用的技术是数据的挖掘技术,可以真实地反映出变电站的运行过程,是目前较好的一种故障分析方法。
2 基于数据驱动的变电站智能故障诊断系统结构分析
实现变电站有效的故障诊断,需要一个完整的监控体系,基于数据驱动的变电站监控体系基本功能构成如图1所示。
如图1所示,整个系统由三大部分组成,分别是数据采集端、数据处理端及集成监控端。数据采集端利用智能传感器来进行数据的采集,采集的数据主要包括:变电站进线电压、用电量、余电量、变压器温度、低压电压、ABC电流、功率因数等;利用视频、图像等手段对各仪表显示、各柜体表面、线圈表面等进行图像信息的扫描分析,以确定相应部位的完好;利用GIS信息系统对故障位置进行定位。
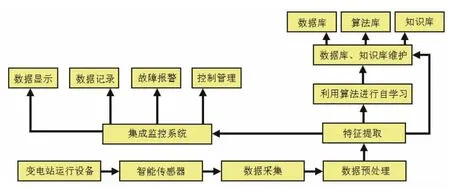
图1 监控系统基本构成
数据处理端是以数据驱动为核心的故障分析的基础。主要的工作环节是利用某种方式准确地从大量运行数据中提取有效地代表数据进行分析,分析的方法需要依靠运行数据数据库中的数据、知识库中的计算规则及计算的算法来支撑。本设计利用MapReduce构建了多数据源的并行特征提取与对比算法来完成这一功能。
集成监控端利用数据处理端所形成的决策结果实现对变电站内各设备的控制。控制的过程主要包括了数据显示、数据记录、故障报警及控制管理等。
3 多数据源的并行特征提取与对比算法
变电站中所蕴含的数据量大且非线性程度高,构建强的数据处理能力是解决问题的关键。在本例中,采用MapReduce对多数据源的并行特征进行提取,并通过对比算法,提炼出有效的数据,用来辅助决策。具体流程如图2所示。
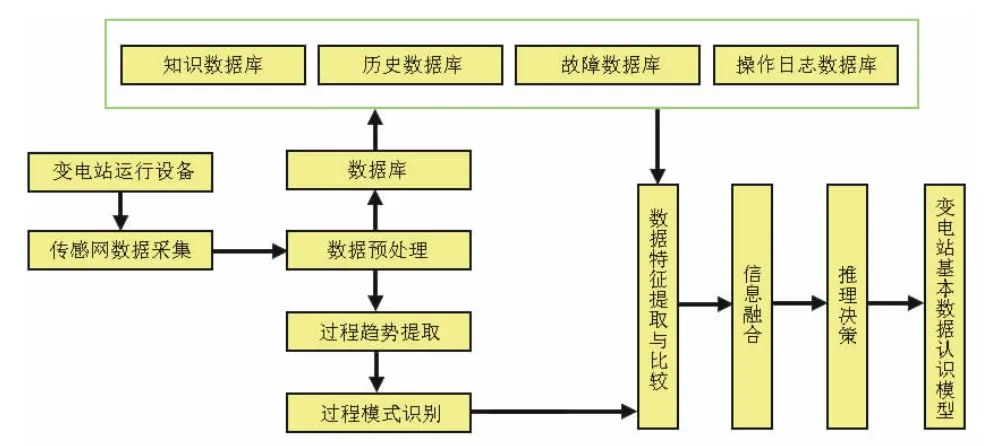
图2 多数据源数据处理过程
在变电站中,由于各种设备所更替的时间及厂家有所不同,所以所提供数据源可能来自不同的数据环境。面对多种多样的数据源,采用基于Hadoop的MapReduce分布式平行计算方式,可以有效地将变电站内不同的数据源进行整合,形成一个统一的数据模型与决策接口,有效提高数据处理的能力。
MapReduce分布式计算包括两个过程:map过程和reduce过程。map过程完成的是任务的分解与处理,是并行处理的基础;而reduce完成的是数据的整理和融合,为数据的处理提供统一的对外数据模型。在执行过程中,起主要核心作用的是两个处理事件,一个是Jobtracker,主要的任务中在两个阶段中调节数据Job的运行;而另一个核心是Tasktrackers事件,主要的任务将由Jobtracker切分的数据分片(split)按照一定的规则进行处理,最终提交给HDFS分布式文件系统,具体过程如图3所示。
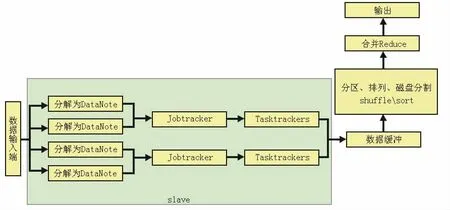
图3 map与reduce的数据处理过程
由于本例采用的是并行特征提取与对比算法,算法采用模糊聚类故障诊断与对比模型,核心算法采用Gustafson-Kessel(G-K)算法。在实际操作中,我们将某一故障的数据特征规定为一个聚类,并以此作为一个原型类的中心,采用线性圆的对比方式,在有效地区域半径r当中,将实际采集值与此聚类对象进行对比,实际值与中心值的均方差在有效半径之内的,就将此数据归于此类,进行统一的处理。由于故障特征数据的不同,系统会形成不同的数据特征聚类,这些聚类将分配到不同的Jobtracker及Tasktrackers上进行并行处理。每一次处理过程由Tracker周期性将所有数据节点上各种信息(主要包括机器的使用资源状况、任务执行进度及运行状态)通过心跳机制汇报给JobTracker,然后根据其结果调用LaunchTaskAction(启动任务)、CommitTaskAction(提交任务)、TaskTrackerReinitAction(重新初始化)等过程进行有效的任务完成。
整个处理的最后一步是形成统一的数据模型,在MapReduce中需要调用HDFS中的数据,由于多种数据源的模式不同,需要利用程序来进行MapRecuce参数的设置。以HBase数据模式为例,其接口程序如图4所示。

图4 HBase数据接口程序
4 总结
本例采用Gustafson-Kessel(G-K)算法构建了特征数据的并行处理功能,将变电站内大量的故障信息进行分类并行对比处理,并将此信息处理后的结果输出到集中管理系统中产生维护命令,从而提高故障诊断与维护的实时性和准确性。
[1]周志霞.变电站故障诊断系统的研究与开发[D].保定:华北电力大学,2003:3-5.
[2]吕宁.基于数据驱动的故障诊断模型及算法的研究[D].哈尔滨:哈尔滨理工大学,2009:24-26.
Research on operation and management mode of intelligent substation based on regulating and controling
LI Fu-peng1,LIANG Guo-jian1,TAO Yi-kun2,ZHENG Hong-bo2
(1.Zhongshan Power Supply Bureau of Guangdong Power Grid Co.,Ltd.,Zhongshan Guangdong 528400,China;2.Zhejiang Guozi Robot Technology Co.,Ltd.,Hangzhou Zhejiang 310053,China)
TM 131
A
1002-087X(2017)09-1369-02
2017-02-12
李福鹏(1977—),男,广东省人,本科,高级工程师,主要研究方向为变电运行管理。
猜你喜欢
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:48
计算机与生活(2018年3期)2018-03-12 08:38:11
电子测试(2017年12期)2017-12-18 06:35:36
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:54
测绘科学与工程(2013年3期)2013-03-11 15:07:36
