
基于SLDTM的主题提取方法
2017-10-17 09:11郭晓利周自岚
东北电力大学学报 2017年5期
郭晓利,周自岚
(东北电力大学 信息工程学院,吉林 吉林 132012)
基于SLDTM的主题提取方法
郭晓利,周自岚
(东北电力大学 信息工程学院,吉林 吉林 132012)
针对主题提取时现有的LDA模型对于主题数目和关键时间点的确定存在一定困难、对于主题结果的准确解释上存在难度的问题,本文提出的SLDTM融合了一种改进的聚类算法到DTM模型中,并在各个子集上采用标签信息进行监督学习。该模型中滑动窗口大小依据主题分布特征而变化,实现更合理的文本集分割,主题的个数也可变且易于理解。实验表明:和以往主题模型相比,SLDTM提取的主题更能体现内容发生的重要变化,语义也更加清晰。
主题提取;主题模型;标签;文本处理
互联网技术带来信息的爆炸式发展,海量信息资源使得人们掌握自己关注的信息存在困难[1-2]。由于信息是时序且随着时间等因素处于不断发展中,如何在时序信息中提取出让人能快速理解的主要内容,且快速分析出内容发生明显变化的时间点,这些热点问题在信息检索和舆情监督等[3-4]领域都具有重大研究价值。
LDA(Latent Dirichlet Allocation Model)模型[5]是一种有效的话题模型,能很好的模拟文档生成的过程。传统的主题模型是静态的,不能处理海量时序文本流。Hornik等[6]考虑时间因素,提出DTM模型(Dynamic Topic Model),根据文本出现的时间先后次序将其分派到各个时间窗口内,对每个时间窗口内的文本分别使用ILDA(Infinite Topic Model)进行建模。DTM能够得到主题热度及主题内容随时间的演化,但是演化效果取决于时间粒度的选择。Chen等[7]运用OLDA模型(Online LDA)将前后两时间片上的参数进行关联,能够对模型进行增量更新,从而有效地对随时间变化的主题进行发现和追踪。
以往模型往往是非监督的,主题词不易理解,存在无意义主题,不利于进一步分析[8]。一些可融合标签信息的监督式主题模型方法被提出,基本思路是尽量保证文档生成主题与标签信息存在一定的匹配性。Jameel等运用的Supervised LDA[9]和 Zhu 提出的Med LDA[10]都假设文档与单一的标签相对应,通过将文档类别标记或对应的连续变量映射为由主题混合方式产生的响应变量的方式来实现文档的类别判定,但只能处理含有一个类别标记的文档。Rao 等[11]提出L-LDA(Labeled LDA)在LDA中主将主题与情感标签集合进行对应,通过这种标记的相关映射找到文档的多标签,成功解决了主题表示问题。由于标签集合是已知的,也能确定主题数目。
要实现对新闻等文本内容的挖掘分析,需要一种兼顾标签信息的动态主题模型。在主题提取时,若将文本集划分为固定时间长度子集,则不能得到内容变化关键时间点[12],使主题变化和关联的边界变得模糊;主题数设定为一固定值,忽略了文本动态变化分布的特性,导致话题混乱和产生无意义话题,探测新主题的产生和旧主题的消亡变得困难[13]。因此,需要一种合理划分时序文本集和确定主题数目的方法。在对提取的主题的解释性上,非监督方法得到的主题往往解释性较差,很难被理解,甚至产生理解偏斜[14],影响模型的效果。
本文提出SLDTM模型,它首先在DTM模型上融合了一种时间片划分算法,通过前后时间片的主题分布变化来对文本集进行时间片的划分,找到主题转变的时间点。和DTM模型不同的是,它在每个时间片上运用L-LDA模型而不是LDA模型,通过建立标签与主题的约束和映射关系,提高主题语义概括能力,很方便的确定主题数目。所以SLDTM模型其实是同时融合了时间片分割算法、标签模型和DTM 模型,实现了准确率更高,语义表达更完善的主题提取。
1 基于SLDTM模型的主题提取
本文提出的基于SLDTM模型的主题提取方法的整体框架为:按照文本集的先后时序顺序,用滑动窗口将其进行划分;然后在初步划分好的窗口内采用L-LDA模型进行主题抽取,确定主题数目;接着用重叠率来衡量划分后得到的主题,对窗口大小进行调整,直到找到最优划分效果时间点,再在新的窗口中运用L-LDA模型,提取出最终的主题。
1.1 改进的时间片确定算法
时间片确定算法主要分为4步:
(1)按时间先后顺序分别用两个滑动窗口来分割文本集Dm(me[1,M]),每个窗口大小为最小时间粒度的n倍,n有一定取值范围;
(2)分别在两窗口内采用变分推理求解ILDA模型参数,确定各时间片的K值,提取主题;
(3)选出前后时间片各个主题排在前面的关键词,计算前后主题间的重叠率;
(4)根据重叠率找出最适合的时间片分割点,对文本集进行合理划分后回到(1),直到文本集全部被划分完毕。
时间片划分算法关键是计算出前后时间片主题间的重叠率,重叠率的关键在于比较分割点前后两阶段的话题内容在话题演化过程中存在的差异,具体表现为主题词项的变化,新词往往意味着新演化阶段的到来。描述某阶段各话题的词特征与其它阶段具有的差别,当该阶段主要话题特征发生改变,则话题发生阶段性演变[12]。本文比较前后时间段话题间共现特征词来衡量前后话题发生的变化,若变化明显,这分割点可能是个不错的划分点。
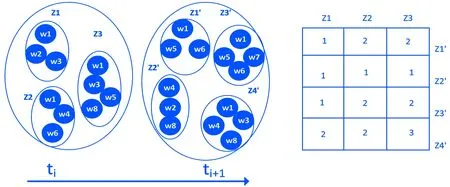
图1 列联表来评估两相邻窗口的主题分布独立性
按时间顺序遍历两个相邻窗口中各个主题,找出两个相邻窗口中的相同特征词的个数。如图1上部分的前后两个时间片ti有3个主题,ti+1有3个主题,Z1和Z1′拥有的相同特征词只有w1,所以相似性矩阵中个数为1。越多相同特征词则话题相似性更高,最后通过评估两个相邻窗口的主题相似性来对文本数据进行分割。计算相似性时定义了两种分布,两种分布分别是矩阵中的行分布P(R)和列分布P(C)。
一般对词共现的衡量是通过计算两个主题间词汇的共现度,再求平均来计算的,而本文对于两窗口之间主题分布的相似性,采用两窗口间所有的P(R)和P(C)与均匀分布的相对熵的平均值F来计算。由于各个主题在窗口中占的概率大小是不一样的,其在表示该窗口上的比重也是不一样的,考虑了主题分布概率函数M。F越小,两窗口间的主题相似性越小,主题变化就越显著。当F值达到局部最小时,在该处进行分割,剩余的时序文本数据则继续分割。目标函数F公式为
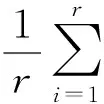
(1)

表1SLDTM的算法描述
1.2 融合标签和动态主题模型
1.2.1 模型简介
本文提出一种动态监督主题模型SLDTM,该模型在动态主题模型DTM的框架下通过时间划分方法将时间窗口进行灵活的划分,另外在各个窗口中结合文本集的标签信息进行模型的监督学习,最终提取出准确的主题。加入标签信息其实是为了提高模型提取出的主题解释性,在该模型中主题与标签对应,每篇文档都拥有几个标签,所以抽取主题时将从对应的带有标签的文本中进行抽取,从而实现监督学习。SLDTM 的图模型如图2所示,图中字符含义见表2。


图2 SLDTM的图模型

表2 SLDTM中的字符含义

表3 SLDTM的生成过程
对于每个时间片上的文档子集,本文用SLDTM建模,时间t的文章生成过程见表3所示。
1.2.2 参数推理与更新
对于模型中隐含参数变量的后验分布需要进行推理求解,本文采用变分推理[15-16]来近似后验分布,可用将其转换成变分优化问题来解决。它用一个似然函数分布来近似实际后验分布,当两分布之间的KL分歧足够小,那么该变分分布可用来代替求解真实后验分布。

(2)
设定的对应变分分布为
(3)

(4)
最后的近似变分分布为
(5)
对于变分分布与实际分布之间的KL分歧,对其求解该似然函数的下界。要使得KL分歧最小,该下界需要最大化:
实现下界的最大化可以采用坐标上升法进行优化,当公式(6)的下界的相对变化小于设定的阈值后,停止变量的迭代更新过程。
2 实验分析
2.1 实验数据集及评价指标
本论文使用了从2008年5月1日到2009年5月30日“汶川地震”共10120篇新闻报道作为话题挖掘算法的测试语料,对语料运用ICTCLAS系统对文本进行分词等预处理,生成词频矩阵。本文采用2个对比实验来检验所提出的SLDTM模型的效果。
实验一:将SLDTM应用于文本分类任务得到模型对文本的语义解释概括能力。对训练集上分别使用SLDTM、L-LDA和DTM进行训练,SLDTM能够得到时间序列的主题-词概率分布β1:T都是一个K*V维的矩阵,K是主题的个数,V是词汇的数目;为了对照实验保持一致,在实验中,预先把各模型的主题数目都设定为K,从而使得DTM也训练得到一组不同时间片上的主题-词概率分布并且也是一个K*V的矩阵;最后L-LDA训练得到的是一个固定不变的静态全局主题-词概率分布,由于L-LLDA也受到关键词标签的约束,因此该β也是一个K*V的矩阵。实验具体分为4步:
(1)固定主题数K,根据DTM、L-LDA和SLDTM得到K*V维主题-词汇概率分布;
(2)各自运用后验推理方法对测试集进行推理,得到相应K维的主题向量;
(3)然后将推理生成的主题向量作为该文档的特征值向量应用于分类算法Naïve Bayes来预测该文档的类别;
(4)最后采用准确率P(Precision)、召回率R(Recall)和F1值(F1-Measure)3个分类评价指标来得到3个模型的分类效果。3个评价指标公式如下:
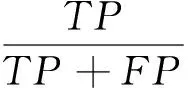
(7)
式中:TP为正确分到该类的文档数量,FP为分到该类但分的不正确的文档数,FN为没有分到但实际属于该类的文档数量。
实验二:分别用SLDTM模型和DTM模型对语料库进行主题挖掘,通过比较提取出的主题及其关键词,来表现模型捕捉某些词汇出现的概率随着时间变化情况的能力。另外采用困惑度Pe(perplexity)来衡量语言模型对测试语料建模能力的强弱。实验中将80%的数据用来训练相关的主题模型,20%作为测试集Dts来测试主题模型的困惑度。困惑度越小,表示模型的泛化能力越强,困惑度公式表示为
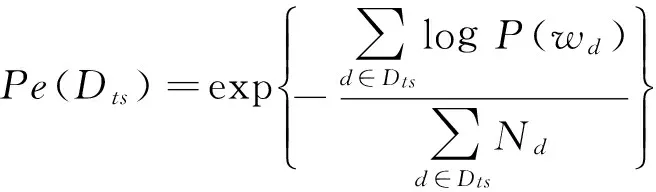
(8)
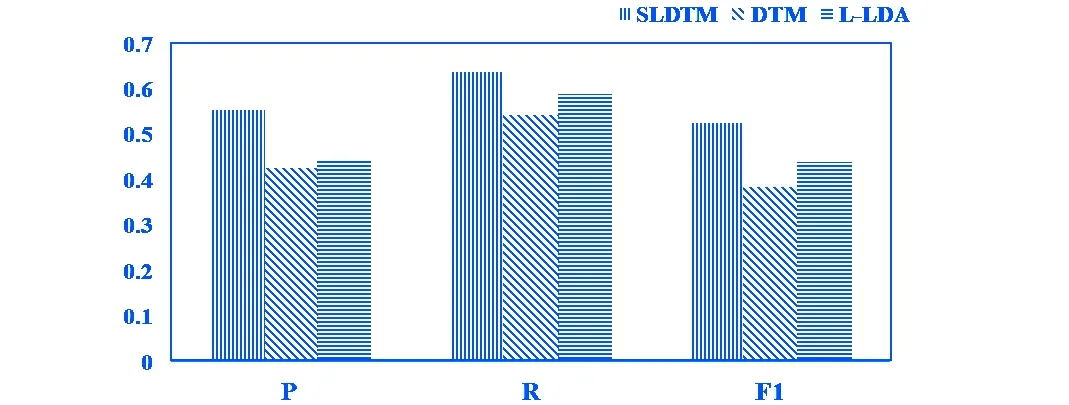
图3 模型主题向量分类能力
2.2 实验结果与分析
实验一得到的各个模型的分类时各项指标如图3所示。
可以看出:SLDTM 生成的主题特征向量各个指标上都取得了最佳分类效果。它主题-词汇分布是动态变化的,L-LDA采用固定主题-词汇分布,因此SLDTM 对分布的建模和语义概括更准确。DTM 效果最差,因为它在训练模型时没有加入主题标签约束,得到的主题结构相对不准确。
从表4可以看出算法挖掘的结果是合理的,符合事件发展逻辑。在地震灾难事件发生后开始最关心的是汶川受灾状况以及当地救灾情况;接下来的五个月中政府进行灾后救助,灾情得到了控制,这时最关心的变为了对当地人民的经济救助以及周边省份的对口支援等;伴随着元旦和新年到来,该事件重新被关注,慰问等活动展开,灾后重建工作也得到了很多媒体报道;到了第二年的5月时,由于是受灾一周年,对应的报道增多,“哀悼”、“失踪”等词体现了这一段时间的纪念活动主题的特征。

表4 SLDTM 模型挖掘结果
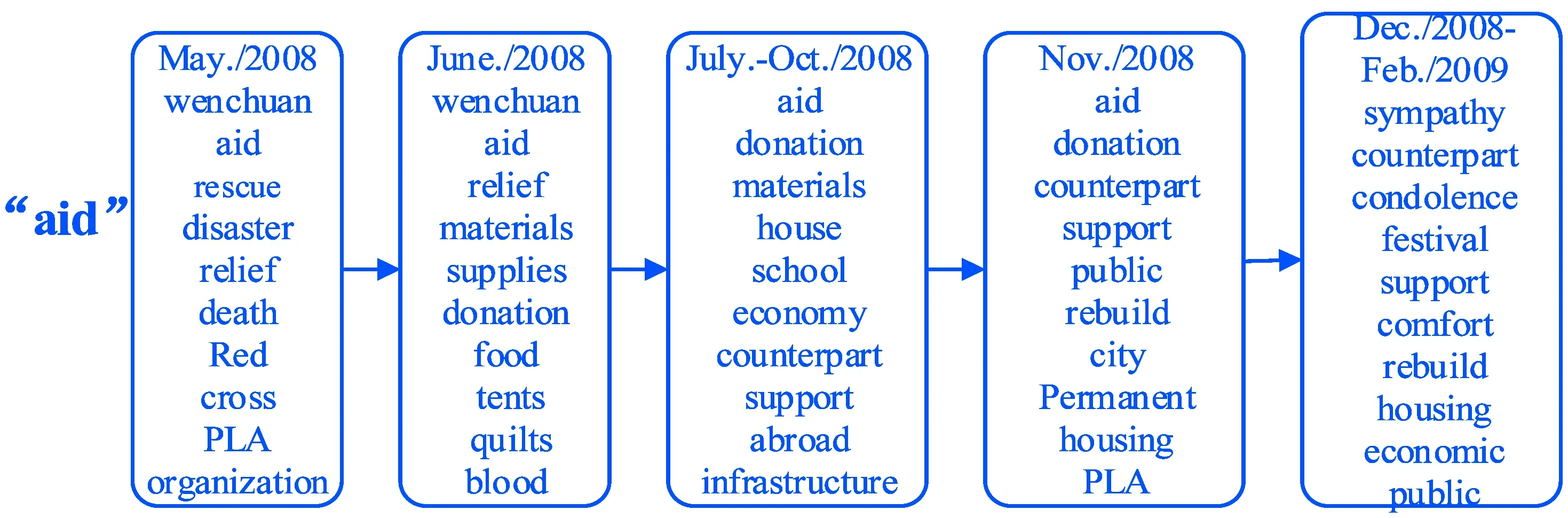
图4 不同时间片上关于“援助”的主题词

图5 模型困惑度比较
图4为映射到“援助”标签主题中随着时间出现的高频词汇,从图中我们可以发现出现概率最高的词与该标签相关程度高,说明经过SLDTM的监督训练,主题的语义更容易解释。同时,在各个时间片上虽然大部分词汇相同,但是有少部分词是不同的,这表明同一主题在不同时间片上的概率分布时变化的,说明模型可以挖掘主题的动态变化。
对于各个主题的困惑度情况如图5所示。可看出本文提出的模型具有更小的困惑度,这表明该模型有更好的预测能力,模型建模效果较好,引入标签监督后有较显著的提升。
3 结论与展望
本文提出SLDTM模型,该模型无需事先指定主题数和划分的时间片的大小,可依据文本集的主题分布特征来实现对前后主题集的划分,可得到更符合文本实际主题演化情况,方便找出更准确清晰的主题边界,发现其变化。另外结合标签信息监督主题的建模,约束模型学习过程,使得提取出的文本主题精确且数目易确定,能准确捕捉语义上的变化。实验表明,本文提出的模型不仅性能上很优秀,对文本集的主题提取也有很大的进步。
下一步工作将围绕模型数据挖掘的自适应性,结合Spark等[17-18]大数据并行计算平台来提高模型的训练速度。考虑结合复杂的HDP[19-21]模型进行实验,最后进行可视化研究。
[1] W.Cui,S.Liu,L.Tan,et al.TextFlow:towards better understanding of evolving topics in text[J].IEEE Transactions on Visualization and Computer Graphics,2011,17(12):2412-2421.
[2] 曲朝阳,范旭东,于华涛,等.基于本体的智能电网文本知识获取模型[J].东北电力大学学报,2014,34(5):60-68.
[3] 曹丽娜,唐锡晋.基于主题模型的BBS话题演化趋势分析[J].管理科学学报,2014,17(11):109-121.
[4] 曹建平,王晖,夏友清,等.基于LDA的双通道在线主题演化模型[J].自动化学报,2014,40(12):2877-2886.
[5] 徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[6] K.Hornik,B.Grun.topicmodels:An R package for fitting topic models[J].Journal of Statistical Software,2011,40(13):1-30.
[7] H E.Jianyun,X.Chen,D U.Min,et al.Topic evolution analysis based on improved online LDA model[J].Journal of Central South University,2015,46(2):547-553.
[8] 单斌,李芳.基于LDA话题演化研究方法综述[J].中文信息学报,2010,24(6):43-49.
[9] S.Jameel,W.Lam,L.Bing.Supervised topic models with word order structure for document classification and retrieval learning[J].Information Retrieval Journal,2015,18(4):1-48.
[10] J.Zhu,A.Ahmed,E P.Xing.MedLDA:maximum margin supervised topic models[J].Journal of Machine Learning Research,2012,13(4):2237-2278.
[11] Y.Rao,Q.Li,X.Mao,et al.Sentiment topic models for social emotion mining[J].Information Sciences,2014,266(5):90-100.
[12] 杨玉珍,刘培玉.融合扩展信息瓶颈理论的话题关联检测方法研究[J].自动化学报,2014,40(3):471-479.
[13] 胡艳丽,白亮,张维明.一种话题演化建模与分析方法[J].自动化学报,2012,38(10):1690-1697.
[14] S.Oeltze,D J.Lehmann,A.Kuhn,et al.Blood flow clustering and applications in virtual stenting of intracranial aneurysms[J].IEEE Transactions on Visualization and Computer Graphics,2014,20(5):686-701.
[15] 曲朝阳,陈帅,杨帆,等.基于云计算技术的电力大数据预处理属性约简方法[J].电力系统自动化.2014,38(8),67-71.
[16] A N.Rafferty,T L.Griffiths,D.Klein.Analyzing the rate at which languages lose the influence of a common ancestor[J].Cognitive Science,2014,38(17):1406-1431.
[17] S.Liu,X.Wang,Y.Song,et al.Evolutionary bayesian rose trees[J].IEEE Transactions on Knowledge and Data Engineering,2015,27(6):1533-1546.
[18] S.Liu,J.Yin,X.Wang,et al.Online visual analytics of text streams[J].IEEE Transactions on Visualization and Computer Graphics,2015,22(11):2451-2466.
[19] I.Pruteanu-Malinici,L.Ren,J.Paisley,et al.Hierarchical bayesian modeling of topics in time-stamped documents[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2010,32(6):996-1011.
[20] W.Ding,C.Chen.Dynamic topic detection and tracking:a comparison of HDP,C-word,and cocitation methods[J].Journal of the Association for Information Scienceand Technology,2014,65(10):2084-2097.
[21] 郭晓利,韩啸.电网知识协同发现策略研究[J].东北电力大学学报,2014,34(1):94-98.
Abstract:Owing to exist the difficult of determine the number of topics and key point of times and accurate interpretation of topics for existing LDA model.There present SLDTM,which fused an improved clustering algorithm to the DTM model and using the tag information for supervised learning in each subset.In this paper,a more reasonable text set segmentation can be achieved because the sliding window size of SLDTM can be changed according to the distribution characteristics of the topics.The number of topics is variable and can be understand easier.experimental results show that compared with the previous topic model,these extracted topics of SLDTM can reflect the important changes of the content and the semantics is clearer.
Keywords:Topic Extraction;Topic Model;Tag;Text Processing
TopicExtractionMethodBasedonSLDTM
GuoXiaoli,ZhouZilan
(School of Information Engineering,Northeast Electric Power University,Jilin Jilin 132012)
TP391
A
2017-05-12
郭晓利(1968-),女,硕士,教授,主要研究方向:人工智能技术、智能信息处理.
电子邮箱:243589657@qq.com(郭晓利);1422076216@qq.com(周自岚)
1005-2992(2017)05-0080-07
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
信息安全研究(2016年4期)2016-12-01
公民与法治(2016年10期)2016-05-17
小学教学参考(2015年20期)2016-01-15
