
不平衡超限学习机的全局惩罚参数选择方法
2017-10-17 12:35:59柯海丰卢诚波徐卉慧
哈尔滨工程大学学报 2017年9期
柯海丰,卢诚波,徐卉慧
(1. 浙江大学城市学院 计算机系,浙江 杭州 310015; 2.丽水学院 工学院,浙江 丽水 323000; 3.太平洋大学 工程与计算机科学学院, 加利福尼亚 斯托克顿 95211)
不平衡超限学习机的全局惩罚参数选择方法
柯海丰1,卢诚波2,徐卉慧3
(1. 浙江大学城市学院 计算机系,浙江 杭州 310015; 2.丽水学院 工学院,浙江 丽水 323000; 3.太平洋大学 工程与计算机科学学院, 加利福尼亚 斯托克顿 95211)
超限学习机在对不平衡数据集进行学习和分类时,正类样本容易被错分。而加权超限学习机只考虑了数据集类之间的不平衡,忽视了样本类内的不平衡的现象。本文阐述了超限学习机在不平衡数据集上分类效果欠佳的原因,提出了根据数据集选取惩罚参数的方法,采用将类间的惩罚参数与类内的惩罚参数相结合的方法,形成全局惩罚参数,即将类惩罚参数进一步精确到样本个体惩罚参数。结果表明:这种方法实现起来简单方便,与其他类型的超限学习机相比较,这种全局惩罚参数的选择方法在提高分类准确率方面能够取得更好的效果。
数据挖掘; 不平衡数据集; 单隐层前馈神经网络; 超限学习机; 加权超限学习机; 全局惩罚参数; 分类器
Abstract:Conventional extreme learning machines (ELMs) usually perform poorly in learning and classifying imbalanced datasets, because positive samples are likely to be misclassified. However, weighted extreme learning machine only considered between- class imbalance but ignored within- class imbalance. This paper explained why ELMs failed, and proposed a direct method to determine the penalty parameter, we considered both of the two kinds of imbalance, combine the between- class cost parameter with within- class cost parameter to form global penalty parameter, that was, class penalty parameterwas refined further to single sample cost parameter. Theory analysis and simulation experiments showed that the global penalty parameter selection for extreme learning machine is convenient in implementation, and performed better in improving the classification accuracy than some other types of extreme learning machine.
Keywords:data mining; imbalanced data set; single hidden layer feedforward networks; extreme learning machine;weighted extreme learning machine; global penalty parameter; classifier
不平衡现象广泛存在于现实世界中,例如,癌症诊断、恶意骚扰电话识别、信用卡欺诈等问题都是不平衡数据集[1-3]。大多数分类模型和学习算法都假设样本分布均衡,可实际数据集往往是不平衡的。不平衡数据集的主要特征是类间样本数不相等。在二分类问题中,人们通常把样本数较多的类称为负类(多数类),较少的类称为正类(少数类)。近年,不平衡学习问题得到了学术界、工业界和基金机构的广泛关注。2000年美国人工智能协会(the association for the advance of artificial intelligence,AAAI)举办了第一届不平衡数据集研讨会,主要关注了在类不平衡的情形下,如何评估学习算法,以及类不平衡和代价敏感学习的关系这两个主题[4]。此后,基本上每隔一两年就会召开一次关于不平衡学习的专题研讨会,讨论不平衡学习的最新研究成果[5-7]。
目前,不平衡学习的研究主要集中在数据层面与算法层面。数据层面上的研究通常是对训练集进行重构,包括过采样和欠采样。过采样的目的是通过增加正类样本数量,从而平衡类别分布。欠采样的目的与之相同,但是通过剔除训练集中的负类样本以达到平衡分布。两种采样方法各有优缺点[8-10]。非随机过采样一般是人为增加正类样本,其中具有代表性的方法是Chawla等提出的正类样本合成过采样技术(synthetic minority over- sampling technique, SMOTE),SMOTE通过内插的方式合成正类样本[11]。比较常用非随机欠采样技术有Tomeklinks[12]、编辑技术[13]、单边选择等[14]。除了数据层面上的研究,模型和算法层面的研究也是处理类别不平衡问题的重要方法。比较常用的有代价敏感学习[15],单类分类器方法[16]等。
文献[17]利用代价敏感学习的思想提出了加权超限学习机(weighted extreme learning machine, WELM),加权超限学习机作为标准超限学习机(extreme learning machine, ELM)的改进模型,在训练过程中使用不同的类惩罚参数对样本的类别差异所造成的影响进行相应的补偿以提高分类效果。但加权超限学习机只考虑了数据集的类间不平衡,而没有考虑类内的不平衡,实际上,类内的不平衡对分类性能的影响也很大[18]。 Boosting 算法虽然对样本赋予了独立的权值,但需要反复迭代,训练时间长[19]。
本文将类间的惩罚参数与类内的惩罚参数相结合,形成全局惩罚参数,即将类惩罚参数进一步精确到样本个体惩罚参数。该方法在提高不平衡数据集的分类准确率方面能够取得更好的效果。
1 超限学习机与不平衡数据集
由于单隐层前馈神经网络能够逼近任何复杂的非线性系统,这使得它在模式识别、自动控制及数据挖掘等许多领域得到了广泛的应用。
图1为一个单隐层前馈神经网络。
文献[20]中提出了一种称为超限学习机的单隐层前馈神经网络学习算法,该算法已被广泛地应用到模式识别、回归问题,高维数据的降维算法、全息数据的外推与插值技术[21-24]等各个领域,均取得了非常好的效果。
超限学习机与其他神经网络学习算法的主要区别在于隐层节点为随机产生,与训练样本无关。训练样本x的隐层输出表示为一个行向量h(x)=[f(ω1x+b1)f(ω2x+b2)…f(ωLx+bL)]。给定N个训练样本(xi,ti),单隐层前馈神经网络的数学模型为
Hβ=T
(1)
式中:H为隐层输出矩阵,β为输出权,T为目标矩阵,其中
H=[h(x1)…h(xN)]T
(2)
利用正交投影法计算H的广义逆后可得:
(3)
为了提高网络的泛化性能,引入了正实数C,其数学模型为[23]:

(4)
subject toHβ=T-ε
(5)
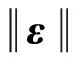
求解下列二次规划问题的最优解,可得
(6)
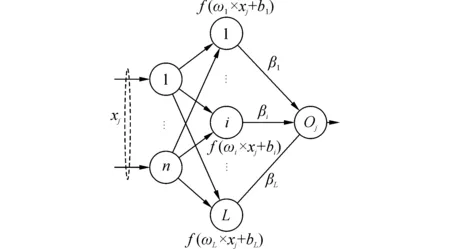
图1 单隐层前馈神经网络Fig.1 A single- hidden- layer feedfor ward neural network
2 全局惩罚参数的选择方法
2.1 类间惩罚参数的选择
加权超限学习机正类和负类选取不同的惩罚参数,每个类内的样本采取相同的惩罚参数,具体的选取方式为:

(7)
式中:W1为N阶对角矩阵,其对角线元素wii是对应于样本xi的惩罚参数,#(qi)为类qi中的样本个数,N为训练样本个数。
另一种选取方式采用黄金分割系数。
方式2:
(8)
式中AVG为类间样本数的均值。
上述两种类间惩罚参数的取法使得少数类中的样本能够获得比多数类中的样本更大的权值,实际上,权W2是无惩罚参数和类惩罚参数W1的权衡。为了最大化边界距离同时最小化所有训练样本的累积权误差,因此,计算图1中单隐层前馈神经网络的输出权,可以表示成下列优化问题:

subject to:ε=O-T=Hβ-T,
(9)
上述优化问题的解为
(10)
2.2 类内惩罚参数选择
加权超限学习机通过选取不同的类惩罚参数来调整类之间的不平衡分布,但对同一类内的样本赋予了相同的惩罚参数,而没有考虑类内的不平衡,实际上,类内的不平衡同样会影响分类器的分类性能。将根据样本近邻中同类样本分布的稠密性来决定该样本的类内惩罚参数,提高没有被充分表示的样本的类内惩罚参数,降低已被充分表示的样本的类内惩罚参数,使得惩罚参数发挥的作用更大。具体的选取方式有两种:
方式1:对于样本xi,选取xi的k个近邻样本,记这k个样本中属于同类样本的有q个,则该样本的类内惩罚参数为
(11)
式中:U1为N阶对角矩阵,其对角线元素wii是对应于样本xi的惩罚参数,N为训练样本个数。
注:若q=0,即意味着该样本的k个近邻中无同类样本,一些研究将此类样本视为“噪声”,但实际上,当数据集不平衡程度很严重时,很多非“噪声”的正类样本近邻中都可能没有同类样本。因此,折衷地将这些样本的类内惩罚参数取值为1。
方式2:对于样本xi,选取xi的k个近邻样本,分别计算xi到k个近邻中其他同类样本的距离之和,记作di, 以及xi到k个近邻中其他类样本的距离之和,记作Di,则该样本的类内惩罚参为
(12)
式中:U2为N阶对角矩阵,其对角线元素wii是对应于样本xi的惩罚参数
为了取得更好的分类效果,大多数分类算法在训练过程中都试图尽可能提高边界和边界附近样本的分类精度,这些样本比那些远离边界的样本更容易被错分,因此对分类器来说更为重要。
上述两种类内惩罚参数的取法使得处于边界和边界附近的样本获得更大的惩罚参数,即使得它们被错分的代价要大于同类的其他样本。
2.3 全局惩罚参数选择
我们给每个样本赋予两个惩罚参数,一个惩罚参数为每个样本的类间惩罚参数,采用式(7)或式(8)中的选取方式,第二个权值为每个样本的类内惩罚参数,采用式(11)或式(12)中的选取方式。全局惩罚参数为类间惩罚参数和类内惩罚参数的乘积。
设类间惩罚参数为W,类内惩罚参数为U,则全局惩罚参数为
D=W×U
(13)
使用全局惩罚参数,式(12)、(13)可修正为
(14)
单一地使用类间惩罚参数时,同一类中的训练样本被赋予了相同的惩罚参数,但由于类内不平衡现象的存在,少数类中也可能会存在冗余样本,结合类内惩罚参数,这些冗余样本的全局惩罚参数将被降低;同样,多数类中也可能会存在稀疏样本,结合类内惩罚参数,这些稀疏样本的全局惩罚参数将被提高,从而提高分类器对不平衡数据集的分类性能。
3 仿真实验
通过对各种不平衡程度的数据集进行分类测试,对ELM、加权超限学习机(W- ELM)和带全局惩罚参数的超限学习机(G- ELM)的分类性能进行比较。
在对不平衡数据集进行分类时,不能简单地采用总体的分类准确率来评价分类器的好坏。由于不平衡数据集中各类的样本数量相差较大,因此如果分类器能够完全识别负类样本,即使对正类样本的识别完全错误,总体的准确率也会维持在一个较高的水准。因此,目前较多采用几何平均值(G- mean)来评价分类器的有效性,即先计算分类器在每一类中的分类准确率,G- mean值为这些准确率的几何平均。例如,对于二分类问题,设TP和TN分别表示被正确分类的正类和负类样本个数,FN表示负数类中被误分为正数类的样本个数,FP表示正数类中被误分为负类的样本个数,则
(15)
G- mean值能够较准确地反映分类器在不平衡数据集上的识别性能。
实验中使用46个二分类的数据集和3个多分类的数据集作为测试样本,数据集描述如表1、2所示。
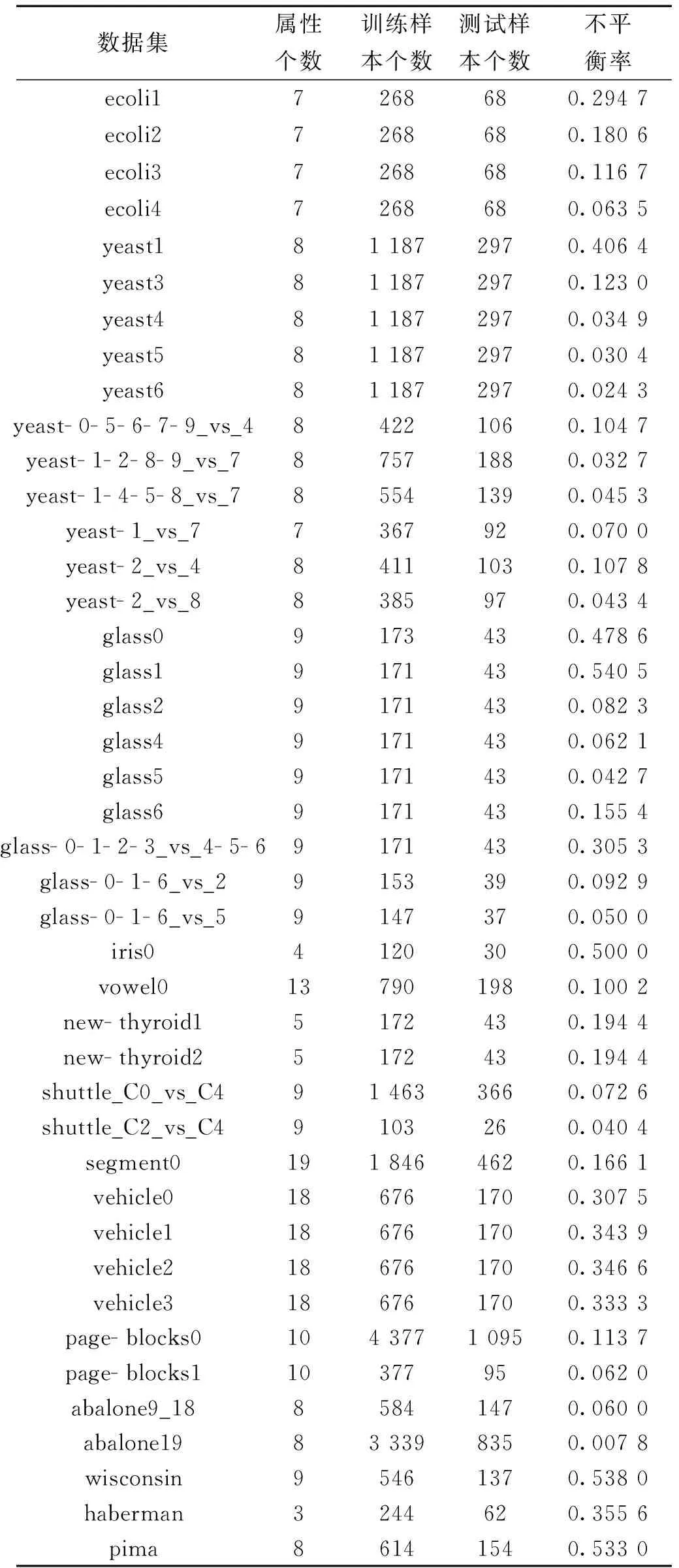
表1 双分类数据集细节
表2UCI中的双分类与多分类数据集细节
Table2DetailsofthebinaryandmulticlassdatasetsfromUCI
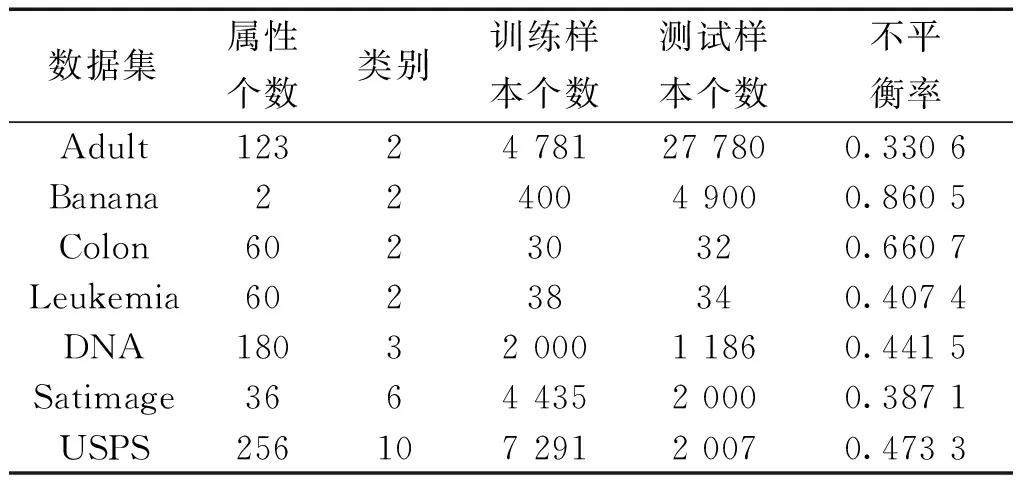
数据集属性个数类别训练样本个数测试样本个数不平衡率Adult12324781277800.3306Banana2240049000.8605Colon60230320.6607Leukemia60238340.4074DNA1803200011860.4415Satimage366443520000.3871USPS25610729120070.4733
注:表1和表2中的数据集可分别从网络中下载[25-26]
表1和表2中的不平衡率(IR)反映了数据集各类之间的不均衡程度,由式(16)、(17)计算得到
二分类集:
(16)
多类集:
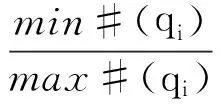
(17)
本节实验中采用的数据集不平衡率的值最低为0.007 8,最高为0.860 5,基本上含括了各种比例的不均衡程度。因此实验结果有代表性。

使用的仿真软件为:Matlab R2014a。该实验的环境为: Window 10 64bit操作系统,Intel Core i7-2620M2.70GHz,12GB内存。
实验中对于数据集采用5-折交叉验证,运行20次,计算G- mean值的平均值。为了便于比较,表1和表2采用文献[19]中相同的数据集,同时,标准超限学习机、加权超限学习机(W1)、加权超限学习机(W2)的G- mean值结果直接引用文献[19]中的结果。
从表3中的实验结果可以看出,由于未添加惩罚参数,标准的超限学习机在对不平衡数据集进行分类的时候表现最差。采用全局惩罚参数的不平衡超限学习机对于大多数不平衡数据集的分类效果要优于加权超限学习机与标准的超限学习机,这是因为不平衡数据集的不平衡程度并不完全由不平衡数据集类间的数量差异决定,也和各个类的类内空间分布有关。此外,当不平衡率较大时,对于加权超限学习机,无论是采用类权值W1还是W2,与标准超限学习机相比较,分类效果区别不大,但通过赋予每个样本全局惩罚参数之后,分类器的识别能力得到进一步提高。
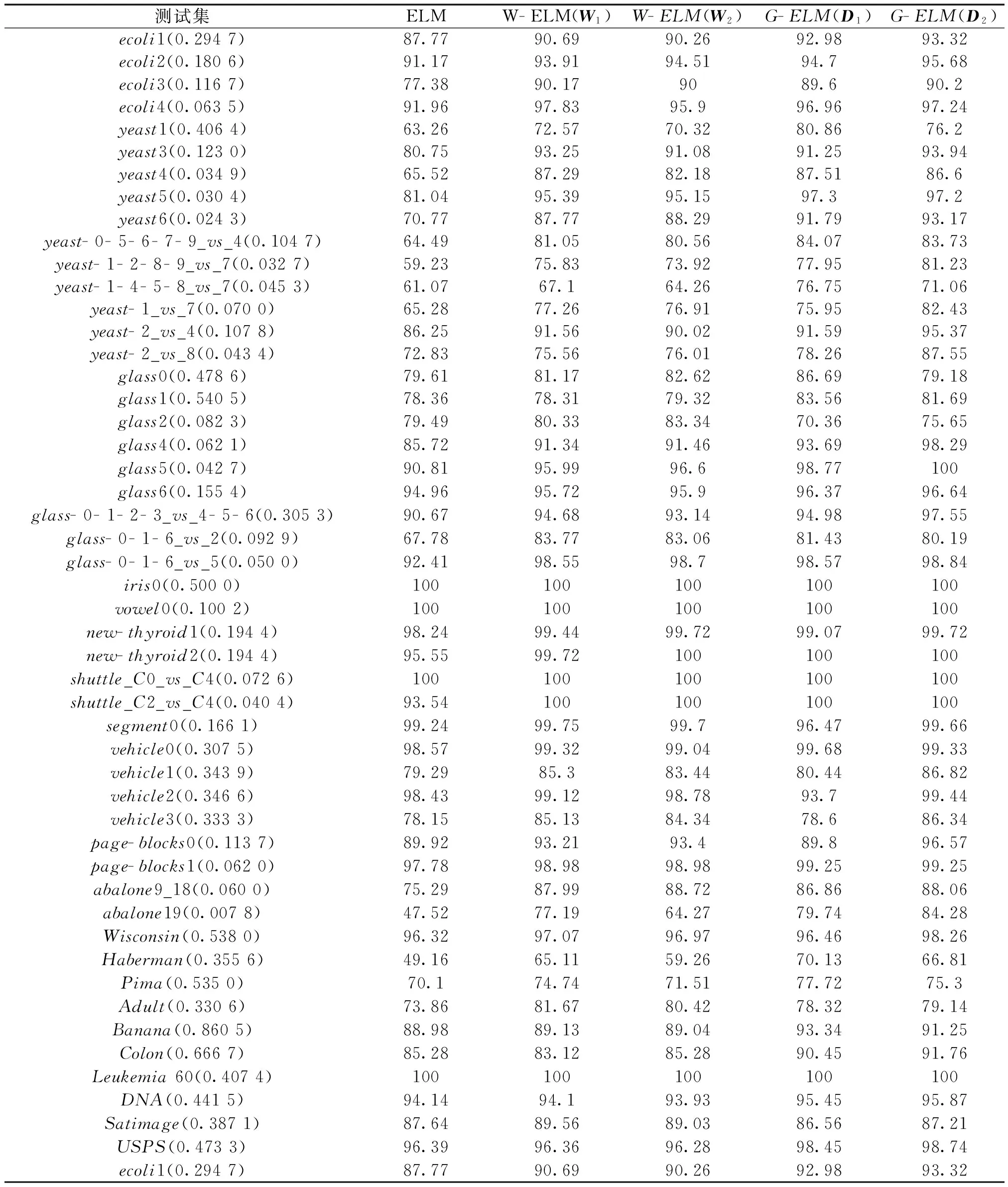
表3 分类器G- mean值比较
4 结论
1)提出了一种加权超限学习机惩罚参数的选取方法,进一步考虑了不平衡数据集的类内不平衡现象,提出了类内惩罚参数的概念,并设计了两种类内惩罚参数的选取方式,与类间的惩罚参数一起构成全局惩罚参数,将惩罚参数精确到了每个样本的惩罚参数,更大地发挥出来惩罚参数的作用。
2)该方法简单且易于实现,利用近邻样本的个数或者距离获得类内的惩罚参数,与类间惩罚参数结合,从而获得全局惩罚参数。
3)同时考虑了类间惩罚参数和类内惩罚参数,因此能够有效地处理不平衡数据集的分类问题,且同时保持了超限学习机的良好性能。
[1] GONZALEZ G F, JOHNSON T, ROLSTON K, et al. Predicting pneumonia mortality using CURB- 65, PSI, and patient characteristics in patients presenting to the emergency department of a comprehensive cancer center[J]. Cancer medicine, 2014, 3(4): 962-970.
[2] TRIVEDJ I, MONIKA, MRIDUSH M. Credit card fraud detection[J]. International journal of advanced research in computer and communication engineering, 2016, 5(1): 39-50.
[3] BAHNSEN A C, AOUADA D, STOJANOVIC A, et al. Feature engineering strategies for credit card fraud detection [J]. Expert systems with applications, 2016, 51: 134-142.
[4] PROVOST F. Machine learning from imbalanced data sets[C]// AAAI′2000 Workshop on Imbalanced Data Sets, 2000: 435-439.
[5] WEISS G, SAAR- TSECHANSKY M, ZADROZNY B. Report on UBDM-05: workshop on utility- based data mining[J]. ACM SIGKDD explorations newsletter, 2005, 7(2): 145-147.
[6] HULSE J V, KHOSHGOFTAAR T M, NAPOLITANO A. Experimental perspectives on learning from imbalanced data. Proceedings of the 24th international conference on Machine learning (ICML) [C]// Oregon State University, Corvallis, USA, 2007: 935-942.
[7] ERTEKIN S, HHUANG J, BOTTOU L, et al. Learning on the border: active learning in imbalanced data classification[C]// Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management, Lisbon, Portugal, 2007: 127-136.
[8] BARANDELA R, VALDOVINOS R M, SANCHEZ J S,et al. The imbalanced training sample problem: Under or oversampling[C]//Joint IAPR International Workshops on Structural, Syntactic, and Statistical Pattern Recognition (SSPR/SPR′04), Lecture Notes in Computer Science 2004, 3138: 806-814.
[9] NAPOLITANO A. Alleviating class imbalance using data sampling: Examining the effects on classification algorithms[D]. Boca Raton, Florida Atlantic University, 2006.
[10] VAN HULSE J, KHOSHGOFTAAR T M, NAPOLITANO A. experimental perspectives on learning from imbalanced data[C]// Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 2007: 935-942.
[11] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over- sampling technique[J]. Journal of machine learning research, 2002, 16: 321-357.
[12] TOMEK I. Two modifications of CNN[J]. IEEE trans on systems, man and communications, 1976, 6: 769-772.
[13] WILSON D L. Asymptotic properties of nearest neighbor rules using edited data sets[J]. IEEE Trans on systems, Man and Cybernetics 2 (1972): 408-421.
[14] KUBAT M, MATWIN S. Addressing the curse of imbalanced training sets: one- sided selection[C]// Proceedings of 14th International Conference on Machine Learning (ICML′97), 1997: 179-186.
[15] RAZZAGHI T, XANTHOPOULOS P,EREF O, Constraint relaxation, cost- sensitive learning and bagging for imbalanced classification problems with outliers[J].Optimization letters, 2015: 1-14.
[16] BARNABÉ- LORTIE V, BELLINGER C, JAPKOWICZ. Active learning for one- class classification[J]. IEEE international conference on machine learning &applications, 2015: 201-206.
[17] ZONG W W, HUANG G B, CHEN Y Q. Weighted extreme learning machine for imbalance learning [J].Neurocomputing, 2013, 101: 229-242.
[18] JAPKOWICZ N. Concept- learning in the presence of between- class and within- class imbalances[J]. Lecture notes in computer science, 2001: 67-77.
[19] FAN W, STOLFO S, ZHANG J, et al. AdaCost: misclassification cost- sensitive boosting[C]\ Proceedings of the 16th International Conference on Machine Learning. San Francisco, CA, 1999: 97-105.
[20] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: Theory and applications [J].Neurocomputing, 2006, 70(1-3): 489-501.
[21] SHRIVASTAVA N A, PANIGRAHI B K, LIM M H. Electricity price classification using extreme learning machines[J]. Neural computing &applications, 2016, 27(1): 9-18.
[22] FENG L, WANG J, LIU S L, et al. Multi- label dimensionality reduction and classification with Extreme learning machines[J].Systems engineering &electronics journal,2014, 25(3): 502-513.
[23] DENG W Y,ZHENG Q H, CHEN L. Regularized extreme learning machine[C]// IEEE Symposium on Computational Intelligence and Data Mining, 2009: 389-395.
[24] 孙超,何元安,商德江,等. 全息数据外推与插值技术的极限学习机方法[J].哈尔滨工程大学学报, 2014, 35(5): 544-551. SUN Chao, HE Yuanan, SHANG Dejiang, et al. Hologram data extrapolation method based on the extreme learning machine[J]. Journal of Harbin Engineering University, 2014, 35(5): 544-551.
[25] Keel Data, sethttp://sci2s.ugr.es/keel/study.php?cod=24 [DB]. 2017.
[26] UCI Data, http://archive.ics.uci.edu/ml/datasets.html [DB]. 2017.
Globalcostparameterselectionofextremelearningmachineforimbalancelearning
KE Haifeng1, LU Chengbo2, XU Huihui3
(1.School of computer & computing science, Zhejiang University City College, Hangzhou 310015, China; 2.Faculty of Engineering, Lishui University, Lishui 323000, China; 3.School of engineering and computer science, University of the Pacific, Stockton, 95211, USA)
10.11990/jheu.201610045
http://www.cnki.net/kcms/detail/23.1390.u.20170821.1833.002.html
TP183
A
1006- 7043(2017)09- 1444- 06
2016-10-12. < class="emphasis_bold">网络出版日期
日期:2017-08-21.
国家自然科学基金项目(61373057);浙江省自然科学基金项目(LY18F030003);浙江省教育厅科研项目(Y201432787, Y201432200).
柯海丰(1977-), 男,副教授; 卢诚波(1977-), 男,副教授.
卢诚波, E- mail:lu.chengbo@aliyun.com.
本文引用格式:柯海丰,卢诚波,徐卉慧. 不平衡超限学习机的全局惩罚参数选择方法[J]. 哈尔滨工程大学学报, 2017, 38(9): 1444-1449.
KE Haifeng, LU Chengbo, XU Huihui. Global cost parameter selection of extreme learning machine for imbalance learning[J]. Journal of Harbin Engineering University, 2017, 38(9): 1444-1449.
猜你喜欢
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
小读者(2020年2期)2020-03-12 10:34:06
阅读(快乐英语高年级)(2019年11期)2019-09-10 07:22:44
测控技术(2018年10期)2018-11-25 09:35:26
传感器与微系统(2018年7期)2018-08-29 00:44:42
趣味(语文)(2018年1期)2018-05-25 03:09:58
自动化学报(2018年2期)2018-04-12 05:46:21
制造技术与机床(2017年4期)2017-06-22 11:17:32
自动化学报(2017年4期)2017-06-15 20:28:55
