
基于机器学习的用户窃电行为预测
2017-10-10 01:35:52李红娇陈晶晶
上海电力大学学报 2017年4期
许 智, 李红娇, 陈晶晶
(上海电力学院 计算机科学与技术学院, 上海 200090)
基于机器学习的用户窃电行为预测
许 智, 李红娇, 陈晶晶
(上海电力学院 计算机科学与技术学院, 上海 200090)
新型智能电表普及后,为了准确检测出电网中的窃电用户,可以结合机器学习的方法.为此,选择了支持向量机、随机森林和迭代决策树3种机器学习中较常用的大数据算法进行分析,通过不断调整试验数据集的大小,对3种算法的效率和准确率进行测试.对比分析结果发现,随机森林算法运行的时间和数据量的大小基本呈线性关系,效率较高,且准确率稳定在86%以上,表现较好.
窃电; 智能电表; 随机森林; 支持向量机; 迭代决策树
各种窃电行为在社会上时有发生,给电网带来很大的损失,电网公司必须对窃电行为进行检测并做出预防.文献[1]和文献[2]中对窃电行为从宏观上进行了详细的分类和研究,并给出了防止窃电行为的方法.
在电网融合的大趋势下,新型智能电表的产生具有重要意义[3]:一是它可以采集更多更精确的数据,便于进一步分析;二是无线通信技术的应用摆脱了传统手工抄表带来的麻烦[4].这些新的特性一方面为传统的数据处理带来挑战,另一方面也使窃电行为进一步多样化、复杂化,电网公司为了解决这些问题必须付出巨大的精力和财力.
随着大数据时代的到来,巨大且复杂的数据使分析手段进一步提升,机器学习呈现出广阔的应用前景,电网数据也在其适用范围内[5].如果利用大数据的优势找到一种方法,可以直接从电网公司的数据中进行分析,从而对用户是否存在窃电行为做出判断的话,那么就相当于从源头上解决了该问题.
1 基础知识
大数据分析算法包括分类、聚类、回归、关联规则等几大类,每类算法实现的功能各不相同.预测用户是否存在窃电行为属于数据分类问题.
用于数据分类的算法也有许多个,较常用的有k-近邻算法、神经网络、支持向量机、随机森林等.在不同数据量和数据复杂度下,各种算法的表现各有优劣.
支持向量机(Support Vector Machine,SVM)是较早应用于分类问题的算法之一,拥有较高的认可度,因此选择该算法进行对比实验.迭代决策树(Gradient Boosting Decision Tree,GBDT)在其提出时就被认为是与SVM一样拥有较好的泛化能力的算法,对于多维度数据的处理表现优异,所以选择该算法进行参照对比.随机森林(Random Forest,RF)则是一种较新的算法,能很好地预测多达数千个变量的作用,是当前非常热门的算法之一.选择这3种各具特色的算法进行比较,希望能找出一种适合电网数据结构的分析算法.
1.1 支持向量机
早在1995年,由Vapnik领导的贝尔实验室小组基于统计学习理论中的VC理论和结构风险最小化原理,提出了一种统计学习理论的新型通用学习方法,即为支持向量机算法[6].
SVM的基本思想是:存在一个训练样本{(xi,yi)}(i=1,2,3,…,m),可以被某个超平面wx+b=0准确地分类.其中,xi∈Rn,yi∈{-1,1},m为样本个数,Rn为n维实数空间.
但实际情况下,能将训练样本划分开的超平面可能有很多,此时定义与不同类样本点距离最大的分类超平面叫做最优超平面,图1中wx+b=0表示的就是最优超平面.本文算法的目的就是为了找出这样一个最优超平面对数据进行分类.
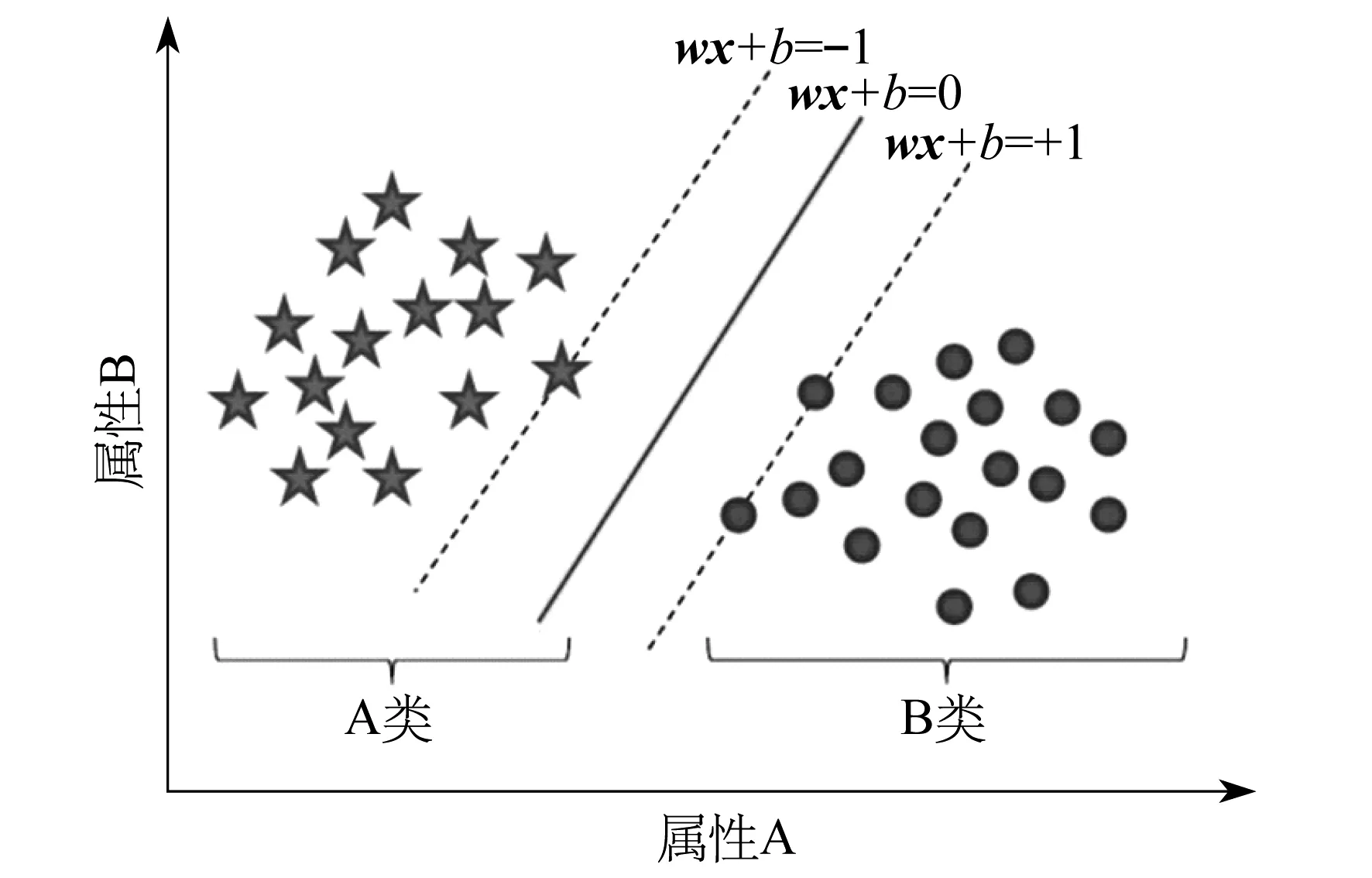
图1 最优超平面
在线性不可分的情况下,支持向量机通过某种事先选择的非线性映射(核函数)将输入变量映射到一个高维特征空间,在这个空间中构造最优分类超平面.在高维属性空间中实现超平面的分割,避免了在原输入空间中进行非线性曲面的分割计算.
1.2 随机森林
RF算法可以解决很多因变量Y受到众多自变量(X1,X2,X3,…,Xk)影响而产生的作用[7].假如因变量Y中有N个观察值,其中有k个与自变量相关,那么在创建分类树时,RF通过自助法(bootstrap)重采样技术,从最初的训练样本集P中有放回地抽取k个样本,生成新的训练集合,再由这些集合生成l个决策树(Decision Tree,DT),形成一个随机构成的决策树森林,而这些决策树之间是没有关联的.一般RF算法会同时生成几百到几千个分类树,形成森林.当有新的样本进入时,森林中的每棵决策树都会对该样本属于哪一类做出判断,然后对所有的判断结果进行统计,数量最多的结果,就是最终的预测结论[8].
在建立决策树的过程中,需要注意采样和完全分裂这两个过程.采样可以分为行采样和列采样两个部分.
(1) 行采样过程 假如有P个输入样本,那么行采样的个数也为P个,在采样过程中,使用有放回的采样方法,可以使算法不容易出现过拟合.
(2) 列采样过程 从M种属性中选择出m个(m< 将经过采样的数据使用完全分裂的方法构造决策树,决策树的任一个叶子节点都不能再进一步划分.为了能准确地表示出分裂属性,使用信息增益和基尼(Gini)指数这两个度量来表示决策树的分裂程度. (1) 信息增益 RF算法模型中样本分类时的默认期望值可以表示为: Y(S1,S2,S3,……,Sm)= ∑pi×log2pii=1,2,3,…,m (1) 式中:Si——数据集S中的某个种类,i=1,2,3,…,m; pi——第i类样本出现的概率,pi=|si/s|. 分类时Y(S1,S2,S3,……,Sm)越小,表示这样分类的效果越明显,所以在选择分裂属性时,应将具有最大信息增益的属性作为分裂属性. (2) 基尼指数 若集合T包含N个类别的记录,那么Gini指标就是pj类别j出现的频率,如果集合T分成m个部分,即N1,N2,N3,…,Nm,且每个部分出现的概率是:p1,p2,p3,…,pm,那么这个分割的Gini就是: G=sumpi(1-pi)=1-sumpipi (2) 选择分裂属性时,遍历完所有的分类属性后,优先选择具有最小基尼指数的属性作为分裂属性. 实验中,由于数据属性较少,故随机森林选择其中3个属性进行抽样,并仅建立600棵决策树. 迭代决策树是通过建立多棵树对样本进行训练,然后预测出某个属性值的分类器算法[9].它是由多个分类回归树(Classification And Regression Tree,CART)形成的,每棵树使用的训练集是采用有放回的方式从总的训练集中抽取的.每棵树的训练特征是从所有特征中随机无放回选取.这个算法大致可以分为两个部分. 1.3.1 回归树 决策树分为回归树(Regression Decision Tree,RDT)和分类树(Classification Tree,CT)两大类.前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度等;后者用于分类标签值,如晴天、阴天、雾、雨等.前者的结果可以相加减,如10岁+5岁-3岁=12岁;后者则不行,如男+男+女,结果并不具有意义.GBDT中的树都是回归树,不是分类树,其核心在于累加所有树的结果作为最终结果. 回归树在每个节点(不一定是叶子节点)都会有一个预测值.以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值.分枝时穷举每种属性的每个阈值,找出最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差. 1.3.2 梯度迭代 梯度迭代(Gradient Boosting,GB),通俗地说就是通过结合多棵树的结论来共同决策.GBDT是将所有树的结论累加起来变成最终结论,即每棵树的结论都是前面所有树结论的累加.GBDT的核心是,新的决策树学习前一棵决策树的结果,通过不断修正前者的误差,最后得到一个满足精度要求的结果. 其中,每棵决策树都需要满足: (3) 式中:θ——函数;Rj——区域;rj——某个深度上的返回值;I(x∈Rj)——函数,当x∈Rj成立时,值为1,否则为0; J——可调参数,表示树的深度. 对3个算法的准确率和效率进行评估,实验在Window10系统下利用Python2.7开发完成.实验用的电脑配置为:英特尔酷睿i7-3770@3.40 GHz处理器,DDR3 800 M Hz,4 GB内存,7200转机械硬盘.实验数据为某电力公司一段时间内用户的用电情况,算法流程见图2. 图2 算法流程 数据集中的内容是用户每天的用电量信息,有的用户给出的数据量比较多,包含了最近3个月的用电情况,而有的用户给出的用电数据比较少,只有几天的用电量.另外,数据集中还存在一定程度的缺失值. 该数据集中的数据一共有6种属性,分别代表不同的信息,如表1所示. 表1 数据集的属性 2.2.1 数据集拆分 不同的用户拥有的信息量也不相同,因此可以按照不同的属性将数据集进行划分,如时间、用电量、用户ID等. 本实验将数据集按照用户ID进行划分,生成很多个不等样本数量的数据子集,每个子集代表一个用户的用电情况. 2.2.2 提取特征值 由于各用户的数据量不相等,为避免给实验造成影响,就需要从这些不对等的样本中,提取出共性特征,通过这些特征对样本进行宏观分析,使得不同数据量的个体都能拥有较平等的分析前提. 实验用4个参数来评估用户的数据情况,分别是方差、均值、缺失值百分比和0数据百分比.方差,用来反映用户在数据采集的时间段中用电量的波动程度.均值,用来反映用户日常的用电量.这两个参数的选择都是认为用户在一段时间里,每天的用电量是基本不变的.缺失值百分比表示的是数据中的缺失值占总数据量的百分比,虽然电表通信过程存在一些不可靠因素[10],但当大量缺失值出现时,很有可能是窃电行为所导致的.0数据百分比表示的是电表数据为0的情况占该用户总数据量的百分比,虽然不排除有空闲房屋的存在,但毕竟是少数,所以当用户用电量数据长期为0时,也需要考虑该用户可能存在窃电行为. 通过对原有数据集的划分和计算,得到了每个用户用电量的4个特征值.将新的结果作为样本进行测试,此时的样本中只包含6种属性,这就使得每个用户用于分析的信息不再完全受到原始数据数量的影响.新的数据集属性见表2. 表2 新数据集的属性 将处理好的数据样本分成训练集和测试集.其中,训练集包含label列,而测试集的label列需要由算法给出,通过比较算法给出的label和原有label的匹配率,就可以得出算法模型预测的准确率kAUC. (4) 式中:nTP——算法正确识别出窃电用户的数量; nTY——算法正确识别出非窃电用户的数量; nFP——算法错误识别出窃电用户的数量; nFY——算法错误识别出非窃电用户的数量. 为了对算法进行多样化比较,各个算法的效率也被作为评价标准. 通过改变样本的数量来分析训练集的大小对算法准确率和运行效率的影响,而训练集和测试集各自所占样本的百分比并未改变.进行4次实验,数据量从10 000个开始,每次递增10 000个数据,实验结果如表3和表4所示.根据不同数据量训练模型,对测试集进行测试,记录每次实验结果的准确率,考虑到实验数据较多且为了时间测量的准确性,故并没有采取交叉验证的办法. 算法的效率是根据每一次的运行时间来衡量的,即算法开始执行和运行结束这两个时间的差值就是算法的实际运行时间. 表3 不同数据量时算法的准确率情况 表4 不同数据量时算法的运行时间 从表3和表4中可以看出,随着训练集的增加,这3种算法始终都能维持较高且恒定的准确率.这说明3种算法并不需要很大的训练集,就可以达到较理想的效果.但3种算法的效率存在较大的差距. (1) 随着数据量的增加,RF算法的运行时间基本呈线性变化,较为理想,这是由于其建模过程中总是随机地采集一定比例的数据量,数据量增加,采样次数才相应增加,因此在实验过程中始终拥有最短的运行时间; (2) SVM算法需要找出数据中的最优超平面,这就需要对数据进行大量运算,由于实验数据集本身的数据维度并不高,所以计算复杂度相对要低一些.但随着数据量的增加,其中的弊端也逐渐显露出来,当数据量增大到原来的4倍时,运行时间是原来的37倍; (3) GBDT始终是3种测试算法中运行效率最低的,这是因为该算法建模时,新决策树学习的是前一棵树的结论和残差,这样所有的树并不是一次性建好,而是在学习过程中逐渐建立的,所以当数据量很大时,这一过程就显得特别漫长.从实验中可以看出,当数据量增加到原来的4倍时,运行时间变为原来的88倍. 随着智能电表的普及,结合机器学习的方法对电网公司的数据进行分析,可以有效地预测出电网中的窃电行为.优秀的算法将大大简化这一过程,经过实验测试,随机森林算法表现较好,具有以下特点:运行时间和数据量基本呈线性关系,适合数据量较大的情况使用;算法准确率基本稳定维持在86%,但是否能满足实际应用仍有待进一步的研究. [1] 刘强.用电监察中窃电和反窃电探析[J].通讯世界,2015(14):156-157. [2] 杨志友.用电监察中窃电与反窃电技术分析.[J].电子世界,2015(15):193-194. [3] 于飞.智能电表发展前景及市场容量分析[J].工程技术:全文版,2016(6):24-27. [4] 贺宁.智能电表故障大数据分析探究[J].中小企业管理与科技,2016(19):142-145. [5] 丁全.基于数据挖掘的电力信息分类及搜索技术探析[J].通讯世界,2016(19):149-150. [6] LOSASSO F.Simulating water and smoke with an octree data structure[J].ACM SIGGRAPH,2004(23-3):457-462. [7] 向涛,李涛,赵雪专,等.基于随机森林的精确目标检测方法[J].计算机应用研究,2016(9):2 837-2 840. [8] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013(4):1 190-1 197. [9] 王天华.基于改进的GBDT算法的乘客出行预测研究[D].大连:大连理工大学,2016. [10] 王媛媛.智能电表通信测试系统分析与研究[J].现代工业经济和信息化,2016(9):98-99. (编辑 白林雪) PredictionofUserStealingBehaviorBasedonMachineLearning XUZhi,LIHongjiao,CHENJingjing (SchoolofComputerScienceandTechnology,ShanghaiUniversityofElectricPower,Shanghai200090,China) Accurate detection of the power grid users can be combined with the machine learning method after the popularity of new smart meters.For this purpose,three kinds of machine learning more commonly used in large data algorithm are chosen for analysis:random forest,support vector machine and gradient boosting decision tree.The efficiency and accuracy of the three algorithms are tested by constantly adjusting the size of the test data set.Analysis of the results shows that the random forest algorithm runs in a linear relationship with the amount of time and the amount of data,while the accuracy rate of stability is higher than86%,with better performances. stealing electricity; smart meter; random forest; support vector machine; gradient boosting decision tree 10.3969/j.issn.1006-4729.2017.04.016 2017-03-09 许智(1992-),男,在读硕士,山西晋中人.主要研究方向为电力信息安全.E-mail:15801937317@163.com. 国家自然科学基金(61403247);上海市信息安全综合管理技术研究重点实验室开放课题项目(AGK2015 005);上海市科学技术委员会地方能力建设项目(15110500700). TP18;TM715 A 1006-4729(2017)04-0389-051.3 迭代决策树
2 实验过程

2.1 数据集说明

2.2 数据预处理

2.3 评价参数说明

2.4 实验数据


2.5 结果分析
3 结 语
猜你喜欢
数学年刊A辑(中文版)(2021年3期)2021-11-05 08:36:32
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:37:58
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
数学物理学报(2019年1期)2019-03-21 05:26:12
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
