
基于卷积神经网络的职位描述文本分类方法
2017-09-23 22:02陶宏曜梁栋屹
软件 2017年6期
陶宏曜+梁栋屹

引言
随着Internet的发展,网络上的信息量增长迅猛,互联网信息提取技术应运而生。自动分类是数据挖掘中一项关键的技术,在许多领域得到了广泛的应用。为了实现快速对大量文本自动分类,许多学者对这一问题做了大量的探索,在构造分类器时使用的技术大体可分为两类:机器学习和深度学习。
在机器学习领域中,有研究较为成熟的算法,如:樸素贝叶斯分类器,支持向量机,信息熵,条件随机场等。这些方法又可以分为三类:有监督的机器学习,半监督的机器学习和无监督的机器学习。其中李荣陆等人使用最大熵实现了对中文文本的分类。李婷婷等通过对文本数据构建若干特征,再利用传统的机器学习方法对文本进行分类。李文波等人提出了一种附加类别标签的LDA算法,该模型很好的解决了基于传统LDA分类算法时强制分配隐含主题的问题。解冲锋等人利用分类文本中旬子内部词语的相关性和句子间的相关性提出了一种基于序列的文本自动分类算法。
现有许多分类器效果的好坏大都取决于所构建特征的质量和分类模型。为了得到更好的分类效果,国内学者针对如何选取和生成特征,以及如何优化模型参数等问题做了大量的研究。其中陆玉昌等人深入分析了向量空间模型(VSM)的本质,找出了其分类正确率低的原因,并提出了一种利用评估函数代替IDF函数的改进方法。李荣陆等人提出了一种基于密度的KNN分类器训练样本裁剪方法,克服了KNN方法中存在的计算量大,而且训练样本的分布不均匀会造成分类准确率的下降的问题。尚文倩等人分析了基于矢量空间模型(VSM)的大多数分类器的瓶颈,通过对基尼指数进行文本特征选择的研究,构造了基于基尼指数的文本特征评估函数,提出了一种新的基于基尼指数的文本特征选择算法,进一步提高分类性能。刘赫等人针对文本分类中的特征加权问题,提出了一种基于特征重要度的特征加权方法。明显改善了样本空间的分布状态,简化了从样本到类别的映射关系。唐焕玲等人针对如何从高维的特征空间中选取对文本分类有效的特征的问题,提出了一种结合评估函数的TEF-WA权重调整技术,不仅提高了分类精确度,还降低了算法的时间复杂度。
近几年来,有关深度学习的理论研究与技术应用吸引学术界和工业界的广泛兴趣。特别是图像识别,语音识别等领域的成功应用,越来越多的学者尝试引入深度学习到自然语言的处理领域中来。梁军等人利用自动编码技术和半监督机器学习,实现了对微博文本的情感分析,大量减少了人工标注的工作量。陈翠平引入了深度学习的思想来完成文本分类任务,使用深度信念网络来完成提取文本特征的工作。Yoon等尝试利用卷积神经网络结构来解决情感分析和问题分类等若干自然语言处理任务,获得了不错的效果。
目前使用机器学习技术实现的中文文本分类器已达到了不错的效果,但仍然存在对混淆类数据处理不佳,特征不稀疏等问题。针对此问题本文提出了一种基于卷积神经网络结合新的TF-IDF算法和Word2vec工具的改良方法。本文在职位描述文本集上展开实验,通过调整调整卷积核,池化层大小以及隐藏层层数,分析新方法和传统方法在不同训练参数情况下,对职业描述文本进行自动分类的性能。
1基于卷积神经网络的文本分类模型
卷积神经网络是前馈神经网络的一种,其特点有局部感受野、权值共享,可以极大地减少需要训练的参数个数。基于卷积神经网络的文本分类器可以解决传统文本分类器中人工选取特征难且不准确的问题,其具体构架如图1所示:
第一层为数据预处理层:该层首先对职位描述文本进行分词处理,然后根据每个词的特性利用现有的算法提取每个词的特征,以作为第二层的输入层。
第二层为卷积层:该层通过4xl的卷积核对输入层的词特征进行组合过滤,再使用Relu神经元激励函数计算从而形成更抽象的特征模型。
第三层为池化层:对上一层的词特征的相邻小区域进行聚类统计,得到新的特征。
第四层为全连接层:在经过卷积层和池化层的处理之后,我们可以认为职位的描述信息已经被抽象成了信息含量更高的特征,需要使用全连接层来完成分类任务。
第五层为Softmax分类层:通过Softmax层,可以得到当前职位描述属于不同分类的概率分布情况。
数据预处理是整个分类方法的第一步,预处理的好坏直接影响着分类的效果的好坏。接下来将具体探讨职位描述文本词特征的提取问题。
2传统TF-IDF算法
TF-IDF(词频率一逆文档频率)是一种用于资讯检索与资讯探勘的常用加权技术。它的主要方法是:关键词在文档中的权重为该关键词在文档中出现的频数反比于包含该关键词的文档数目。TF表示关键词w在该文档中出现的频率,IDF表示所有文
通过TF-IDF能够提取出一篇文档的关键词,其含义是如果词w的在该文档中出现的频率高,在其他文档中出现的频率低,就代表词w能够很好的表示该文档的特征。S
TF-IDF将文档的内部信息与外部信息综合起来考虑特征词,能较为全面的反应文档的特性,但在IDF的设计中还存在缺陷,关键词的权重反比于逆文档频率。在实际情况中,往往判断一个文档的关键词权重并不总是反比于逆文档频率,特别是在短文本的关键词抽取中使用TF-IDF算法的效果不是很好。
假设总文档数为10,以表1为例,‘工作和‘java关键词在‘计算机类别和‘新闻传媒类别中的逆文档频率分别为2,2和5,0。其中‘工作的IDF为log(10/4+0.01)=0.41,‘iava的IDF为log(10/5+0.01)=0.31。在c1类别的同一文档中当wl与w2具有相同的TF时,TF×IDF x~>TF×IDFiava。TF-IDF和TF-IDF的值表明,‘工作比‘java根据代表力,但从关键词‘工作和‘iava在‘计算机和‘新闻传媒类别中的分布表明,‘java比‘工作具有更好的类别区分度。在短文本分类中如果单纯使用TF-IDF作为文本特征的抽取方法,往往达不到分类的效果,导致这一问题的原因可归结为两点:一是TF-IDF设计本身的缺陷;二是对文本表示的特征深度不够。对此可使用Word2vec的Skip-gram进一步提取文本特征来提高分类精确度。endprint
3Word2vec Skip-gram模型
Word2vec是Mikolov等所提出模型的一个实现,可以用来快速有效地训练词向量。Word2vec包含了两种训练模型,而skip-gram模型是其中的一种。采用该模型的最大优势在于,能够克服传统词向量训练模型中由于窗口大小的限制,导致超出窗口范围的词语与当前词之间的关系不能被正確地反映到模型之中的问题。Skip-gram模型的设计见图2所示。Skip-gram模型的训练目标就是使得下式的值最大。
其中,c是窗口的大小,在Skip-gram模型中就是指n-Skip-gram中的n的大小,T是训练文本的大小。在Word2vec中,使用的是c-Skip-gram-bi-grams。基本的Skip-gram模型计算条件概率公式如下:
其中,Vw和V分别是词w的输入和输出向量。
使用Word2vec对中文文本生成的词向量能够从词性,语法以及语义上表示一个词的特性。相比于TF-IDF算法,词向量所包含的信息量更为深入,所构造出的分类器精确度有所提高,但仍存在对混淆类的数据噪点处理不佳的问题。
4改进的TF-IDF表示
对于训练数据中存在像混淆类的噪点造成的文本分类不准确的问题,我们可以在保持原有特征信息量不变的基础上,可引入改进的TF-IDF特征表示来缓解问题。
对传统TF-IDF的改进工作主要有两点:一是对原算法的应用扩展,二是对函数的改造。传统TF-IDF解决是多个文档的特征提取,此处我们可以上升到对每个类别的关键词特征提取,具体算法是:
其中TF表示的是W在CJ类别中出现的频率,d代表Wi词在Cj类中出现的文档数,D代表q类的总文档数。
公式(7)构造的是一个阈值函数。公式(8)展开需要用到公式(7),N代表总类别数,WiCj含义具体可参照公式(6)的介绍。重新构造的IDF求的是关键词Wi在分类时出现概率的对数。此处使用的阈值函数主要是减少数据噪点对计算Wi词的真实IDF的影响。在计算完每个词在每一类中的TF-IDFmcj值后,可以运用概率期望来表示每一个词的TF-IDFwi权值,其具体计算方法详见公式(9)和公式(10)。公式(10)中n是总词数,m是总类别数。
利用改进后的TF-IDF词权重表示法结合Word2vec词向量构成的特征组再对卷积神经网络进行训练。实验结果表明这种方法,在缓解数据噪点对精确度的影响大的问题上是有效的。
5实验分析
5.1数据准备及预处理
本文实验采用从web上爬取的职位描述信息,共计四百万条信息。首先对职位描述文本进行分词以及去停词。接着使用Word2vec和改进前和改进后的TF-IDF算法对职位描述文本进行特征提取,并生成与之对应的特征表。
5.2测量标准
本文实验选择的测量标准有两个:一是最直接衡量分类效果的预测正确率,如公式(11)所示。另一个是经过Softmax回归之后的预测分类和正确分类之间的交叉熵,如公式(12)所示,其中p为正确概率,g为预测概率,x表示预测类别。
5.3样本数量
训练样本的大小是影响分类效果最直接的因素之一,它也是整个实验研究的基础。在对样本数量考察时,需保证只有样本数量这一变量。本次实验将样本数量分为100000条,200000条和300000条,实验结果见图3所示。结果表明当加大训练数量,可以改善分类的正确率。通过实验还发现随着训练样本数量的线性增加,对正确率的影响并不是线性的,数量越大,对正确率的影响越小。
5.4学习率的大小
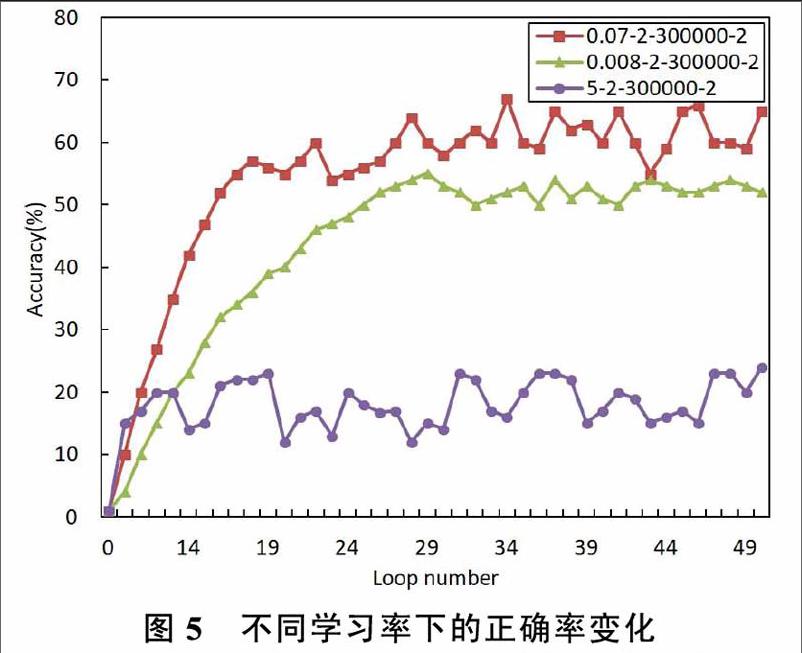
学习率的大小关系到神经网络的收敛速度。实验结果如图4和图5所示,可以观测到当学习率以5.0的速率训练时,整个网络会有很大的波动,且分类的结果也有比较大的误差。当学习率为0.008时,整个网络收敛相对稳定,但是收敛的速度较慢。学习率太大会造成无法收敛,学习率偏小则收敛速度过慢,正确率也得不到很好的提升。通过多次实验,我们发现当学习率为0.07时效果最好,收敛相对较快,且预测的正确率高。
5.5卷积核大小和全连接层数量
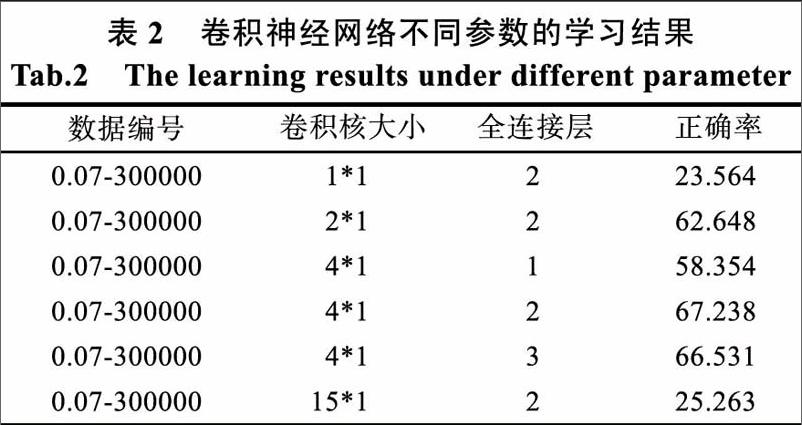
卷积核大小即一次抓取局部多少个的词的长度。全连接的层数表示拟合参数的维度。在相同学习率和训练数据,不同卷积核大小和全连接层节点数的情况下训练分类器,所得结果见表2所示。卷积核为4*1最为合适,如表2的第一行可知当卷积核太小时,整个神经网络学习不到特征间的联系,正确率相对较差。见表2第6行所示,当卷积核太大则会使学习的特征太过泛化,提升不了分类的正确率。经表2第3,4,5行比较显示,全连接层为2层最佳,当层数太低无法学习到更深的规则,当层数过大时对分类效果的影响不大,反而还加大了算法的时间复杂度。
5.6不同分类算法和训练特征
使用TF-IDF,Word2vec和改进后的TF-IDF的中文词特征提取法。对传统kNN分类器与基于卷积神经网络的分类器进行了对比,实验结果见表3所示。通过对表3的kNN列和CNNs列的比较我们可以发现,无论在哪种情况下使用卷积神经网络来对职位描述文本分类时都占有得天独厚的优势,其中使用Word2vec词向量和改进后的TF-IDF特征表示所训练处来的分类器预测的结果最为准确,证实了该方法在处理混淆类等噪点数据时有一定的成效。
6结语
本文探讨利用卷积神经网络构造分类器的方法,分析了传统分类器中TF-IDF特征提取算法的不足,提出了一种新的TF-IDF表示方法。通过实验分析,深入了解到了样本数量,学习率,卷积核大小,隐藏层层数对分类器效果的影响机制,进一步对分类器进行了调优,同时验证了新方法在解决传统分类器中存在解决学习深度不够,对混淆类数据噪点处理不佳等问题上是可行的。endprint
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中华养生保健(2020年7期)2020-11-16
电子测试(2018年1期)2018-04-18
家教世界·创新阅读(2016年11期)2016-12-27
信息安全研究(2016年4期)2016-12-01
天津护理(2016年3期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
