
基于深度学习的PD致病基因活性预测
2017-09-23 02:57李自臣田生伟刘江越高双印
计算机应用与软件 2017年9期
李自臣 田生伟 刘江越 高双印
1(乌鲁木齐职业大学信息工程学院 新疆 乌鲁木齐 830002)2(新疆大学软件学院 新疆 乌鲁木齐 830008)
基于深度学习的PD致病基因活性预测
李自臣1,2田生伟2*刘江越1高双印2
1(乌鲁木齐职业大学信息工程学院 新疆 乌鲁木齐 830002)2(新疆大学软件学院 新疆 乌鲁木齐 830008)
帕金森病PD(Parkinson’s disease)是一种神经性系统疾病,多发于中老年人。目前,该病情的病因和发病机制尚不明确,但根据多国临床试验数据统计与分析,PINKs基因是影响整个PD发病的重要原因之一。针对该基因的活性结构数据进行研究,提出基于深度学习的深度信念网络(DBN)与稀疏自编码(SAE)预测方法。该算法能通过深层网络特征单元自动学习到适合分类器分类的高层非线性组合特征,并将这些高层次特征输入到分类器中进行数据分析。实验结果表明,DBN算法的平均预测精度较SVM与ANN分别提高了28.04%、18.84%;SAE算法的平均预测精度较SVM与ANN分别提高了23.51%、14.31%。所以,提出的基于深度学习的PINKs活性预测方法具有较高的预测精度和稳定性,与理论分布也较为相吻合,适用于该基因活性的研究与探讨。
活性 深度学习 SAE 预测 研究
0 引 言
帕金森病是一种常见的神经系统变性疾病,多发于老年人。临床症状主要表现为禁止性震颤、肌强直、运动迟缓和平衡失调障碍,同时患者可伴有抑郁、 便秘和睡眠障碍等非运动症状[1-2]。帕金森病最主要的病理改变是中脑黑质多巴胺DA(dopamine)能神经元的变性死亡,从而引起纹状体DA含量显著性减少。目前,导致这一病理改变的确切病因仍不清楚,遗传因素、环境因素、年龄老化、氧化应激等均可能参与PD多巴胺能神经元的变性死亡过程[3-5]。
在帕金森病综合征治疗方式中,最常用的是小干扰RNA疗法。小干扰RNA(Small interfering RNA;siRNA)有时称为短干扰RNA(short interfering RNA)或沉默RNA(silencing RNA),是一个长20到25个核苷酸的双股RNA,在生物学上有许多的用途。在抗病毒治疗方面,帕金森病综合征采用RNA干扰疗法效果出色[6-8]。
在小干扰RNA疗法的就诊过程中,越来越多的证据表明线粒体自噬功能障碍是导致帕金森综合症产生的最关键因素[9-11]。已经确定的有PD联合基因组PINKs对阻止机能失调的线粒体的积累有很大的促进作用。PINKs基因在脑组织中广泛表达,其功效有助于缓解帕金森综合症产生的神经性损伤。
本文利用计算机信息科学,结合相关的理论计算方法来获得PINKs基因的结构参数和理化参数,再将这些参数用统计学方法建立数学模型,从而描述化合物结构与其活性之间的定量关系。目前,尚未发现利用深度学习算法针对PINKs基因进行研究。
本文提出基于稀疏自编码(SAE) 和深度信念网络(DBN)模型的PINKs基因活性预测方法,并设计实验对模型进行训练及验证。实验结果表明,与其他模型相比,基于SAE与DBN模型的PINKs基因活性预测能取得良好的测试效果。
1 SAE和DBN模型简介
1.1 SAE
SAE是深度学习领域中广泛采用的无监督特征学习技术,是一种模仿人工神经网络特征而建立的网络结构,其利用逐层训练的思想主动提取输入数据中深层次的特征。SAE的结构分为输入层、隐藏层和输出层,其结构简图如图1。

图1 SAE结构图
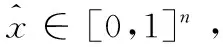
h=fθ(x)=sigm(Wx+b)
(1)
(2)

SAE采用随机梯度算法进行训练,其代价函数的定义为:


(4)
其中,∂是学习率。θ={W,b,c},W∈RM×N,b∈RM,c∈RN。
为了获得PINKs基因活性数据的深层特征,利用优化参数θ′,通过式(5)对活性数据的网络结构进行进一步学习:
(5)

1.2 DBN
DBN也是深度学习算法中被广泛是用的一种方法,其通过组合较低层的特征来计算出较高层的具有代表性的特征,从而挖掘出输入数据的优化分布结构。从网络组成上可以看出,DBN是由多个无监督学习的受限玻尔兹曼机和一个有监督学习的反向传播网络合成。其拓扑结构如图2所示。

图2 DBN结构图
RBM是一种基于能量的网络模型,其结构与普通神经网络相似,但仅是由一层可视层和一层隐藏层组成,无输出层。假设可视层的可见节点和隐藏层的隐含节点皆为二值变量,如式(6):
∀i,jVi∈{0,1}Hj∈{0,1}
(6)
其中,Vi表示第i个可见节点的状态。Hj表示第j个隐含节点的状态,则对于给定状态(V,H), RBM具备的能量定义为:
(7)
(8)
其中,θ={Wij,Bi,Cj}是RBM的参数。Wij是可见层节点Vi与隐藏层节点Hj的联结权值,Bi和Cj分别表示Vi和Hj的偏置量(bias),其均为实数。基于以上定义,我们可以得到(V,H)的联合概率分布:
(9)
对于现实问题,RBM更常用的是联合概率的边缘分布P(V|θ),又称为似然函数:
(10)
RBM采用层层迭代的方式进行训练,最终获得学习参数θ=(Wij,Bi,Cj)的值,以拟合给定的训练数据。参数θ通过在训练集上的极大对数似然函数得到,即:
(11)
最后,将经过RBM择优后的参数θ,输入BP神经网络进行微调,再反复计算,最终得到最优DBN拓扑结构。
2 实验及结果分析
2.1 数据源
PubChem是美国国家生物技术信息中心的一个公共分子信息库,提供了分子生物活性的信息并提供免费下载。在本实验中,分别随机选取了PINKs基因的活性化合物和非活性化合物各8 000条数据进行研究。为了充分验证本文实验的实用性,采用MOE分析工具对PINKs基因的化学分子结构进行计算,并使用四折交叉算法对测试结果进行验证。
2.2 实 验
本文将实验数据划分为训练集和测试集,分别建立了基于ANN、SVM、SAE和DBN的PINKs活性预测模型,表1为实验数据分配细则。

表1 数据分配
在测试模型中,不同的预设参数对实验效果会产生一定的影响。经过大量实验,本文选择出较优异且较稳定的设定值作为各个模型的首选参数,如表2所示。

表2 各个模型参数设定
基于上述设定值,本文对PINKs基因的化学结构数据进行了大量的测试和验证,以下就是实验的具体内容:
1) 数据量对各个算法性能的影响
随着PINKs活性数据的不断增多,不同模型的测试结果也产生了明显的差异。在本组实验中,为了对不同算法进行客观检测,本文设定参与对比的算法皆输入特征数为150,网络模型的网络层数皆为1层。图3是检测结果。

图3 不同模型受数量级的影响
由图3可以看出,SVM的测试效果最差,平均预测精度仅为50.01%;DBN的测试效果最佳,平均预测精度可达78.05%。SAE与ANN的测试效果保持中间水平,SAE的平均预测精度为73.52%, ANN的平均预测精度为59.21%。相比较而言,深度学习模型的预测效果明显高于浅层模型的预测效果。
2) 输入数据的维度大小和深度大小对各个算法性能的影响
对于不同算法的性能检测,输入数据的维度和深度也会对实验效果产生重要影响。当输入数据的维度逐渐增大,各个算法的性能也会面临更大的考验。图4是特征数从30递增到150时不同预测模型的检测结果。
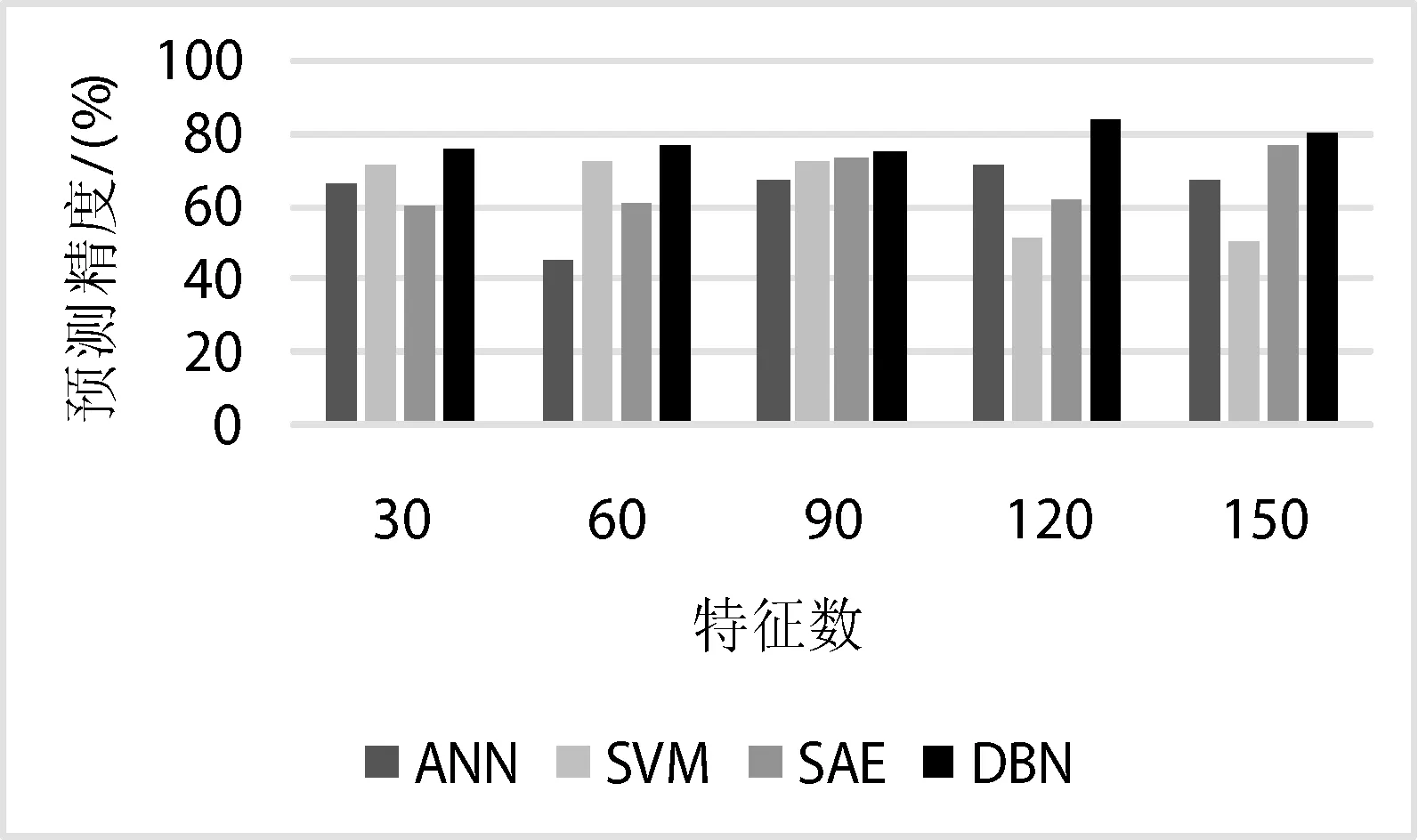
图4 不同模型受特征数的影响
从图4可知,随着特征数的增多,ANN与SVM的预测精度产生了明显波动。ANN预测精度最高为65.41%,最低为44.31%;SVM预测精度最高为72.01%,最低为50.10%。对于SAE而言,实验结果也出现了些许浮动,最高的预测精度为76.55%,最低为60.05%。DBN的预测效果最好,最高预测精度可达83.55%,最低也能达74.91%。综合分析,SAE与DBN皆优越于浅层学习算法ANN与SVM。
基于上组实验,为了更有利于后续模型的性能检测,本研究对具有网络结构的SAE和DBN作了层数分析,从中挑选出最佳网络层数,测试结果如图5所示。从图5可知,SAE与DBN的网络结构皆为2层时预测精度最高,预测精度分别可达到86.11%和83.55%。
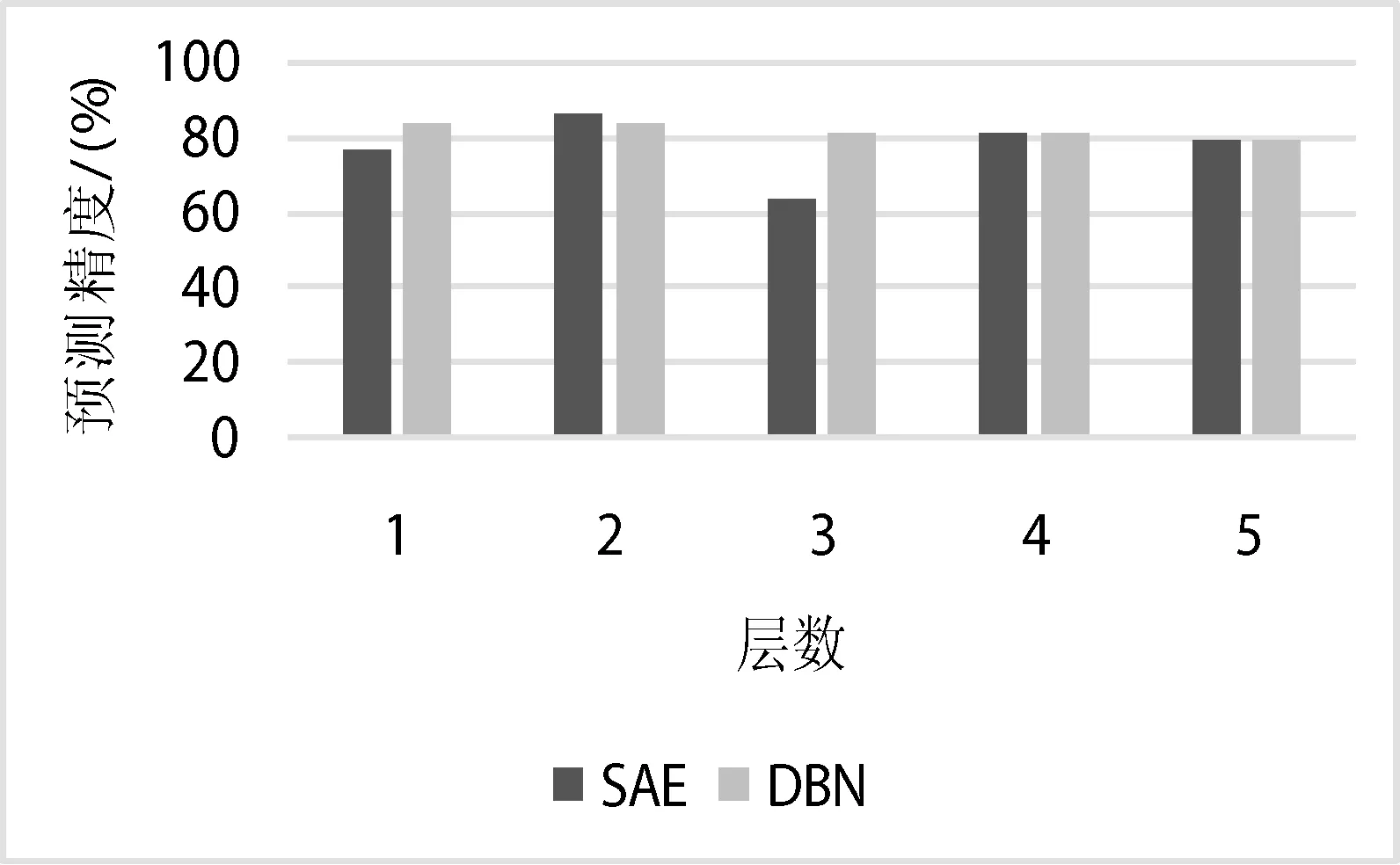
图5 SAE和DBN模型受层数的影响
3) 各个性能指标对不同算法的检测结果分析
继承上述检测结果,本文又选择出几项极具代表性的性能检测指标对不同算法进行了更深一步的探讨和研究。
(1) 马修斯相关系数
马修斯相关系数常常被用作二分类检测的核心,目的在于验证测试结果是否平衡。由图6可知,随着数据集的递增,DBN的马修斯相关系数呈一条平稳上升的光滑曲线,其值平均范围在0.5。SAE的马修斯相关系数出现稍许波动,但较其他模型优势也很明显,其值平均范围在0.46。SVM与ANN的马修斯相关系数皆呈明显下滑趋势,浮动也较为明显,其值平均范围在0.39和0.24。故知DBN与SAE对PINKs基因活性检测具有良好的效果,其稳定性较高,较符合于理论值分布。

图6 不同模型马修斯相关系数对比
(2) 敏感度
敏感度SEN(sensitivity):又称真阳性率TPR(true positive rate),即实际为真且被诊断为真获得的百分比。本文关于PINKs活性分子,在不同的数量级情况下分别应用SVM、ANN、SAE和DBN模型针对其敏感度进行了研究,实验结果如图7所示。
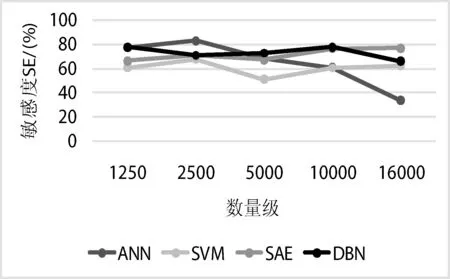
图7 不同模型敏感度对比
由图7可知,DBN与SAE的敏感度较高,曲线走势相对缓和,DBN的平均敏感度为75.44%,SAE为70.64%。SVM和ANN的敏感度较低,曲线走势相对陡峭,SVM的平均敏感度为60.12%,ANN为68.71%。
(3) 特异度
特异度SPE(specificity),又称真阴性率TNR(true negative rate),即实际为假且被诊断为假获得的百分比。本文针对PINKs基因活性分子,在不同模型算法中进行了特异度分析,分析结果如图8所示。

图8 不同模型特异度对比
由图8可知,DBN的特异度最高,平均预测值为82.33%;SAE预测结果出现一定浮动,平均预测值75.47%。 SVM与ANN的特异度曲线浮动相对较大,SVM平均预测值为55.03%,ANN平均预测值为57.28%。
综上所述,基于PINKs基因活性分子的DBN和SAE算法模型较其他算法模型体现出明显的优势,这是因为深度学习算法在学习过程中,可以自发挖掘出数据结构中的深层特征,再根据网络权值和阈值的优化处理,使得测试结果优良。
3 结 语
本文基于深度学习算法,提出了PINKs活性预测深度模型。实验结果表明,与浅层学习方法比较,深度检测模型预测值和真实值吻合效果明显,预测精度高,稳定性高,是有效预防帕金森综合征病发的方式之一。本文所提及的DBN与SAE算法是深度学习中较常用的方法。今后,我们将对该算法进行改进,使其预测结果更加精准,同时,也可考虑其他更有效的算法模型进行该病症的深层次研究和探讨。
[1] 张淑静,高誉珊,孙红梅,等.慢病毒介导的小鼠pink1基因rnai载体的构建及在nih3t3细胞中的筛选[J].现代生物医学进展,2015,15(23):4401-4405.
[2] 李晋芳,林松俊,刘红敏.补肾活血疏肝汤对帕金森病伴抑郁症的临床疗效研究[J].湖北中医杂志,2016,38(7):34-35.
[3] 冯霄.8型腺相关病毒所介导的GDNF与产酶基因对6-OHDA损伤帕金森大鼠模型的保护与恢复性研究[D].吉林大学,2013.
[4] 于晓俊.帕金森病铁代谢异常的脑区差异和细胞易感性差异研究[D].青岛大学,2013.
[5] 王思,李秀华,杜鹃.侧脑室注射腺病毒介导的GDNF基因对帕金森病的保护作用[J].山东大学学报(医学版),2016,54(4):32-36.
[6] 钟建斌,范胜诺,肖颂华,等.沉默Nogo-A对脂多糖诱导的PC12细胞TNF-α、IL-6分泌及TH下调的影响[J].中山大学学报(医学科学版),2015,14(2):391-397.
[7] Li Z,Wang H,Song B,et al.Silencing HMGB1 expression by lentivirus-mediated small interfering RNA (siRNA) inhibits the proliferation and invasion of colorectal cancer LoVo cells in vitro and in vivo[J].Zhonghua Zhong Liu Za Zhi,2015,37(9):664.
[8] 李三党,景化忠,韩晓鹏,等.小干扰RNA靶向沉默β-catenin基因对胃癌AGS细胞人端粒酶逆转录酶的影响[J].现代生物医学进展,2015,15(11):2014-2017.
[9] 柏杖勇,李清华.PINK1/parkin,线粒体自噬与帕金森病[J].中国老年学杂志,2014(9):2609-2614.
[10] 郭涌斐,孙懿,赵欣,等.DJ-1蛋白对线粒体的功能调节在帕金森病中的作用[J].中国药理学通报,2016(1):22-26.
[11] 王苏,冯艳玲.线粒体功能障碍和帕金森病[J].脑与神经疾病杂志,2003,11(6):384-385.
PREDICTIONOFPDDISEASEGENEACTIVITYBASEDONDEEPLEARNING
Li Zichen1,2Tian Shengwei2*Liu Jiangyue1Gao Shuangyin21
(SchoolofInformationEngineering,UrumqiVocationalUniversity,Urumqi830002,Xinjiang,China)2(SchoolofSoftware,XinjiangUniversity,Urumqi830008,Xinjiang,China)
Parkinson’s disease (PD) is a kind of nerve system disease, more common in the elderly. At present, the condition of the etiology and pathogenesis is not clear, but according to multinational clinical trial data statistics and analysis, PINKs gene is one of the important reason to influence the whole PD pathogenesis. This paper study for the structure of activity gene, and the DBN and SAE are proposed for the PINKs activity prediction. The proposed algorithm can learn automatically by the characteristics of deep web unit is suitable for the high nonlinear combination classifier classification feature, and will these high-level features inputs to the classifier for data analysis. The experimental results show that the DBN algorithm the average prediction accuracy of SVM with ANN respectively increased by 28.04%, 18.84%; SAE algorithm the average prediction accuracy of the SVM and ANN respectively increased by 23.51%, 14.31%. In this paper, based on the deep study of PINKs activity prediction method has higher prediction accuracy and stability, in conformity with the theory of distribution are, also is applicable to the activity of research and discussion.
Activity Deep learning SAE Prediction Research
TP3
A
10.3969/j.issn.1000-386x.2017.09.037
2016-10-13。新疆研究生科研创新基金项目(XJGRI2015034)。李自臣,高工,主研领域:大数据分析。田生伟,教授。刘江越,讲师。高双印,硕士生。
猜你喜欢
中老年保健(2022年5期)2022-08-24
中老年保健(2022年4期)2022-08-22
保健医苑(2022年6期)2022-07-08
一重技术(2021年5期)2022-01-18
载人航天(2021年5期)2021-11-20
食品安全导刊(2021年20期)2021-08-30
昆明医科大学学报(2021年6期)2021-07-31
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
活力(2019年22期)2019-03-16
电子制作(2018年11期)2018-08-04
