
对延迟敏感型应用的虚拟机调度算法
2017-09-23 02:57佘名高
计算机应用与软件 2017年9期
佘名高 张 颜
(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)
对延迟敏感型应用的虚拟机调度算法
佘名高 张 颜*
(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)
针对Credit调度算法不能保证实时性的不足提出两点改进。首先,当有大量I/O任务时对BOOST态虚拟CPU进行负载均衡来缩短系统响应时间。其次,利用动态时间片代替原来的固定时间片去适应虚拟CPU的动态变化。通过检测系统对任务的平均响应时间和周转时间来评估改进前和改进后对I/O任务的响应的影响。实验研究表明,改进之后的Credit调度算法平均响应时间与改进前相比降低了102.3%,可以显著提高I/O延迟敏感型应用的性能。
Xen Credit调度算法 虚拟化 负载均衡
0 引 言
随着近年来云计算的兴起,虚拟化技术也成为企业和学者研究的热门领域之一。大量企业利用Xen虚拟化技术管理自己的应用服务,通过虚拟化技术可以方便实现资源的充分利用,资源的快速重分配,以及增加系统的灵活性。这些都是影响应用服务成功交付的关键因素[1]。
当应用采用Xen虚拟化技术进行管理,Xen调度虚拟机会造成额外的开销,对某些应用程序的整体性能会造成一定的影响。一个典型的例子,如基于流的音频/视频服务是对延迟敏感的I/O密集型应用。通常情况下,这些应用不需要消耗大量的CPU计算资源,但是对服务响应的实时性要求较高。然而,Xen虚拟化技术缺省的Credit 调度算法针对延迟敏感型应用的性能还不够理想。改进Credit调度算法,使I/O延迟敏感型应用得到及时响应一直是虚拟化研究的热点领域。当前,Govindan等提出了一种在计算密集型应用中,通过牺牲短期的公平,来优先调度面向通信域的通信感知调度算法[2]。同样的,Ongaro等主张利用Boost/Tickle机制去提升I/O域的调度优先级[3]。
为了进一步探寻这些改进算法的性能。在本文中提出的改进算法可以看作是前人想法在多处理器平台上的一个拓展。首先,在多核系统中,通过均衡I/O密集型任务的优先级(即BOOST态虚拟CPU的优先级)来尽量减少系统的响应时间。其次,通过利用动态时间片而不是固定时间片来优化CPU切换的频率。
1 Xen虚拟机管理器以及Credit调度算法
Xen虚拟机管理器VMM是一个开放源代码的虚拟化管理软件,它工作在底层硬件资源之上,为上层虚拟机实例(又称为域,Domain)提供服务[4]。Xen的默认调度算法是Credit调度算法。
1.1 Credit调度算法的基本原理
Credit调度算法是公平共享的非抢占式调度算法[5]。它可以为每一个域分配Credit值,Xen按照Credit值公平调度各个域。
Xen-4.1之前的版本,Credit调度算法在调度时,Domain有两种优先级状态:UNDER状态和OVER状态。每个物理CPU都管理一个可运行的队列,根据VCPU的优先级将其进行排列入队。调度器会优先调度处于UNDER状态的VCPU,当发现虚拟CPU对应域的Credit值小于零时,就将VCPU的状态转化为OVER状态。当处于UNDER状态的虚拟机全部都调度完之后,处于OVER状态的虚拟机才会得到调度的机会。此时,Credit调度算法将重新为每个域赋予Credit值,然后把相应的VCPU调整为UNDER状态,如此周期循环。由于系统总是优先调度处于UNDER队列头的VCPU。此Credit调度算法仅适合于工作负载为计算密集型应用,却不适合I/O延迟敏感型应用。为了尽量减小I/O敏感型事件的响应延迟,Ongaro等提出在Credit调度算法中引入BOOST机制[3]。通过在系统中添加一个新的BOOST优先级,允许一个为BOOST状态的VCPU(即BOOST态VCPU)去抢占一个正在运行的UNDER态 VCPU。
加入BOOST机制的Credit调度通过事件信道接收事件,当有I/O操作的任务时,系统会将处于阻塞状态的UNDER态VCPU优先权提升到BOOST状态并将其唤醒。唤醒的VCPU立即抢占CPU资源而不是进入运行队列与其他域竞争。因此,I/O密集型任务响应时间减少。图1显示了Credit调度算法的结构图,其中四个域位于同一台机器上,以有效利用底层物理资源。

图1 Credit调度算法的结构图
1.2 Credit调度算法的性能分析
在这一部分,分析当前Credit调度算法中可能导致I/O延迟敏感型应用性能不足的两个问题,并把他们称为多BOOST态问题以及固定时间片问题。
1) 多BOOST态问题:是指多个域同时提升到BOOST状态导致调度算法性能降低的现象,这种情况通常在处理I/O密集型任务中时有发生。由于处于UNDER状态的虚拟CPU在队列中等待被调用,可能导致的响应延迟,通过加入BOOST状态,使得具有BOOST状态的虚拟机能立即被调度,以减少调度的响应时间。但是,当大量I/O应用并发执行时,这些应用对应域的VCPU都会进入BOOST状态,导致BOOST态的VCPU负载失衡,某些应用仍不能及时得到调度。如图2所示,在四核平台下的32个非特权域均匀分为四组,每组各8个域同时运行在Xen-4.4.2的虚拟机管理器上,测试两个程序(Ping和Zip)在物理CPU上运行BOOST态VCPU的时间。从图中数据可知BOOST 态VCPU分布不均。

图2 BOOST态VCPU在物理CPU上的分布
2) 固定时间片问题:当PCPU调度处于UNDER状态的VCPU时,允许相应的VCPU运行一个为30 ms的固定时间片,这个时间片的设置一方面独立于VCPU数量,另一方面还得确保域间调度的公平。因此这可能导致两个问题:当运行队列的VCPU数量小,固定时间片将导致在运行队列中的VCPU之间频繁切换,增加系统开销。当VCPU数量较多,固定时间片的设置将导致在队列的尾部VCPU响应时间过长。理论上,在一个固定的时间间隔内,时间片越长,表示越少的VCPU切换和越短的调度平均周转时间。对于一个延迟敏感型任务,响应时间与运行队列中等待任务的数量是密切相关的。因此,根据等待队列中VCPU的数量动态的调整调度时间片可能是更理想的方式。
2 改进调度算法的设计与实现
上文论述了Credit调度算法存在的不足,在这一节中,首先提出了Credit调度算法的改进算法,然后,描述算法的核心实现步骤。
2.1 对BOOST态的域进行负载均衡
在第1节中提到,Credit调度算法可能引起多BOOST态同时存在的问题,导致在PCPU之上的BOOST 域分布不均。虽然Credit调度算法可以实现全局负载均衡,但是当BOOST域较多时,会使得整个系统的响应速度降低。为了解决这个问题,实验中将物理机上每个PCPU对应运行队列的中BOOST态VCPU进行负载均衡,改进VCPU的响应速度。实验使用的负载均衡算法如下所示:
在BOOST域被唤醒并插入运行队列之后,VMM会给调度器一个与该PCPU调度相关队列的反馈。在这个操作被执行之前,先执行一个简单的负载平衡算法:
1) 检查相应PCPU上正在运行的VCPU是否是BOOST状态。
2) 如果是,基于下文提出的标准选择目标PCPU,其中VCPU应该是可转移的。如果目标PCPU和源PCPU是相同的,那么就退出。否则,将VCPU插到目标PCPU的运行队列中。
3) 如果当前运行的VCPU不是BOOST态,那么就触发缺省的PCPU调度策略,然后退出。
在多核系统中,目标PCPU是根据以下标准选择:
1) 按照相同的内核,相同Socket的顺序搜索闲置的PCPU。如果找到,则返回的PCPU的数量。
2) 找到运行队列中包含BOOST 态VCPU最少的PCPU,然后返回PCPU数。
该标准背后的基本原理是计算的空间局部性。例如,如果两PCPU共享相同的内核,那么,它们也可以共享相同的本地缓存。
2.2 动态时间片
在Credit调度算法中,30 ms固定时间片的设置独立于VCPU状态。BOOST态VCPU时间片的运行分为两个阶段。在第一阶段,VCPU将在BOOST 状态下运行10 ms,然后切换到UNDER状态,进入第二阶段。BOOST状态下的时间长度是VCPU调度的关键。如果这个长度太长,其他相同优先级的VCPU可能被延迟,增加I/O响应时间。另一方面,如果太短,BOOST态 VCPU在被其他BOOST态VCPU抢占之前无法获得充分的执行时间。为了均衡系统的平均周转时间和I/O敏感型应用的平均响应时间,本文提出动态时间片,时间片的长度根据运行队列中VCPU的数量进行动态调整。时间片的优化算法是在选定VCPU之后进行以下步骤:
改变的BOOST第一阶段的运行时间片长度为2 ms,约为I/O程序运行在BOOST 态VCPU的时间长度,将它插入到运行队列,然后改变其优先级为UNDER。因此,被选定的VCPU在队列中将位于所有UNDER 态VCPU之前,所有BOOST 态VCPU之后。如果队列中没有其他的BOOST态 VCPU,那么刚插入的VCPU就可以继续调度执行。
根据队列中UNDER态VCPU的数量,计算UNDER态 VCPU 的时间片,通过以下公式得出:
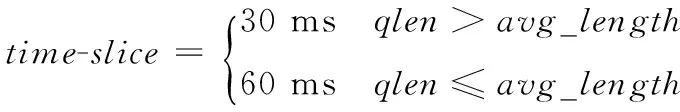
(1)
式中,avg_length为运行队列的缺省长度,在Credit调度算法中一般缺省设置为4。qlen指在计算时间片时队列中UNDER态VCPU的数量。
这个改进基于两点考虑。首先,在BOOST阶段,I/O密集型程序经常进入阻塞状态,基本不消耗VCPU。因此,该VCPU通常不需要分配很长的时间片。另一方面,如果除了阻塞I/O程序之外其他的程序同样运行在BOOST态VCPU中,这些应用程序还将继续运行在BOOST 态直到时间片结束。它将延迟其他BOOST态VCPU被调度的时间。因此需要先分配一小段时间片(2 ms)进行处理。其次,在UNDER阶段,又分为两种情况。其一,由于VCPU关联关系项很小,在队列中UNDER态VCPU的数量基本不变。如果有相当多的VCPU,可以增加时间片来减少调度开销。正如前面所讨论的,事实上,UNDER态 VCPU的数量与PCPU的数量关联性通常很小,改进算法应该优化这种常见的情况。其二,增加的时间片不应该在很大范围内变化,否则,它可能会损害Credit调度算法的目标公平性原则。因此,在本文提出的改进算法中,使用了两个固定值(30 ms和60 ms)优化调度器的运行队列,来实现调度算法公平的目标。
使用动态时间片来改进算法是比较容易实现的。首先,添加颜色属性到VCPU的数据结构中,当VCPU插入运行队列时设置为红色,当它从队列中出来重新计算时间片时设置为黑色。基于这个属性,改进算法执行以下步骤:
1) 检查选定的VCPU的状态。如果是在BOOST状态,那么时间片直接设置为30 ms。
2) 如果选定的VCPU不在BOOST状态,那么检查该VCPU的颜色。如果它是黑色的,时间片将设置为一个值,根据式(1)计算得出。否则,如果它是红色的,表示之前计算的时间片已经过期,算法需要重新计算它。
3) 锁定整个运行队列,计算VCPU的数量并根据式(1)重新计算时间片,然后设置所有的VCPU为黑色,存储时间片到每个PCPU的局部结构。
4) 计算下一个VCPU时间片的值。
3 实验与评估
在这一部分中,通过大量的实验来评估提出的改进算法。首先介绍实验装置,之后通过测量延迟敏感型应用的响应时间来评估提出的改进算法。实验数据表明,所提出的改进算法可以显著提高延迟敏感型任务的性能。
3.1 实验装置
实验所使用的设备包括两个物理机和32个虚拟机(不包括驱动域)。两个物理机的通过100 Mbps以太网连接,它们的配置如表1所示,所有的虚拟机安装在一台物理机器之上是通过Xen-4.4.2管理的,另一台物理机作为远程主机与这些虚拟机通信。实验中每个域的配置如表2所示,Domain0以CentOS-5.2作为客户操作系统。本研究的主要目的是通过优化Credit算法减少延迟敏感型应用的响应时间。实验选择Ping和一个基本的搜索程序作为实验测试的程序,这两种程序在此类研究中被广泛采用。具体地讲,一个远程系统发送Ping命令到客户操作系统,客户操作系统只确认收到Ping数据包不做任何其他的计算。通过网络延迟的时间作为参照,来评估本文提出的算法的性能。

表1 硬件配置

表2 虚拟机的配置
3.2 将BOOST 态负载平衡后的算法评估
在实验中,为了评估在BOOST 态虚拟机的负载情况,首先创建20个客户域平均分为两组,各有10个虚拟机。然后,让在第二组的虚拟机每隔一秒去Ping第一组的虚拟机,以产生大量BOOST 态VCPU。然后,通过计算每一个Ping的响应时间。算法改进前和改进后比较结果如图3所示。很明显优化之后数据包的响应时间不仅显著降低而且也更稳定。这表明对BOOST态VCPU进行负载平衡能有效提高系统性能。这种现象不难理解,BOOST态VCPU在运行队列中是有组织的等待,这将导致在队列前面的VCPU能更快地获得调度,从而缩短了Ping的响应时间,但在队列后面的VCPU他们会较慢获得调度,使Ping的响应时间较长,从而导致不稳定。与之相反,在改进负载平衡后,BOOST态 VCPU被均匀分布到每个PCPU的运行队列中,在每个运行队列中BOOST态VCPU平均增加的数量相应的降低。因此,即使BOOST态VCPU在运行队列的后端也不会等待太久。因此,Ping的响应时间波动较小(约在0.08 ms),平均响应时间与改进前相比降低了102.3%且更稳定。

图3 Boost态负载均衡前和改进后运行Ping程序响应时间的比较
3.3 改进动态时间切片算法的评估
为了全面评估改进算法,在实验中,我们集中评估了算法对延迟敏感型应用平均响应时间的影响和系统平均周转时间的影响。研究结果表明,改用动态时间片的算法,可以明显降低平均响应时间和平均周转时间。
VCPU的平均响应时间:在这个实验中,对基本搜索服务进行压力测试来测量VCPU平均响应时间。为此,首先配置一台作为搜索服务器的测试机,其中包括四个客户操作系统,并观察在不同强度搜索请求下客户操作系统中的响应情况。然后,使用四个客户操作系统的平均响应时间来度量评估改进动态时间片算法的性能。
如图4所示,随着请求数量增多,改进动态时间片后算法平均响应时间和改进之前相比要短。这是由于搜索服务器部署在虚拟机中,它可能发生多个进程在同一个VCPU中运行。算法改进前,当VCPU 进入BOOST状态,除了I /O进程,其他的计算密集型进程也会使BOOST态VCPU长时间执行,在对延迟敏感型任务较多时此方案不合理。改进后,时间片调整为
2 ms,只允许I/O程序的VCPU有BOOST状态而其他的VCPU只能处于UNDER状态 。在图4中,当请求强度较低时,改进前和改进后的平均响应时间几乎相同。这是因为在这种情况下,只有很少BOOST态VCPU在队列中等待。而随着请求强度的增加,BOOST态VCPU的数量不断增长,改进之后进行了BOOST态VCPU的负载均衡,结果显然是比改进之前的平均响应时间要低。

图4 优化动态时间片之前和之后的平均响应时间比较
平均周转时间:在Credit调度中,UNDER态的VCPU时间片设置为30 ms。而在改进的算法中,当等待运行队列长度小于缺省值时进行优化。表3显示了算法改进前和改进后在运行队列中VCPU数量从1到8时平均周转时间的对比,Credit算法缺省设置队列长度为4。随着VCPU的数量增多,可以观察到调度算法改进后的平均周转时间比改进前要低。并且,他们之间的差值随着执行时间的变化在逐渐增加,如图5所示。原因是当UNDER态VCPU数量小于预设值,该算法为了减少调度开销设置时间片为60 ms。然而,当UNDER态 VCPU队列长度大于预设值,改进前和改进后的两个算法具有相同的时间片30 ms。因此,它们表现出大致相同的周转时间。这些结果表明,当UNDER VCPU在队列中的数量较少时,增加时间片可以明显提高系统的性能。

表3 使用Benchmark工具,测试运行队列中VCPU数量和周转时间的关系

图5 随着Benchmark运行时间的延长,改进前与改进后平均周转时间的差值
4 结 语
本文分析了Xen缺省调度算法Credit算法的基本原理。研究了Credit调度算法对延迟敏感型应用存在的两个性能不足之处:多BOOST态导致CPU调度的负载不均衡以及固定时间片导致调度算法性能未能达到最优的情况。针对这两个不足给出改进算法的基本思想。实验结果表明,本文提出的改进算法与默认的Credit调度算法相比,在延迟敏感型应用中VCPU的平均响应时间更小且响应时间更加稳定,调度算法的性能相较于改进前有显著提升。
[1] Wu S,Zhou L,Sun H,et al.Poris:A Scheduler for Parallel Soft Real-Time Applications in Virtualized Environments[J].IEEE Transactions on Parallel and Distributed Systems,2016,27(3):841-854.
[2] Govindan S,Nath A R,Das A,et al.Xen and co.:communication-aware CPU scheduling for consolidated xen-based hosting platforms[C]//International Conference on Virtual Execution Environments,VEE 2007,San Diego,California,Usa,June.2007:1111-1125.
[3] Ongaro D,Cox A L,Rixner S.Scheduling I/O in virtual machine monitors[C]//International Conference on Virtual Execution Environments,VEE 2008,Seattle,Wa,Usa,March,2008:1-10.
[4] Wu J,Wang C Y,Li J F.LA-Credit:A Load-Awareness Scheduling Algorithm for Xen Virtualized Platforms[C]//Big Data Security on Cloud (BigDataSecurity),IEEE International Conference on High Performance and Smart Computing (HPSC),and IEEE International Conference on Intelligent Data and Security (IDS),2016 IEEE 2nd International Conference on.IEEE,2016:234-239.
[5] Zhou L,Wu S,Sun H,et al.Virtual Machine Scheduling for Parallel Soft Real-Time Applications[C]//2013 IEEE 21st International Symposium on Modelling,Analysis and Simulation of Computer and Telecommunication Systems.IEEE Computer Society,2013:525-534.
[6] Wang K,Hou Z.A relaxed co-scheduling method of virtual CPUs on Xen virtual machines[J].Journal of Computer Research & Development,2012,49(1):118-127.
[7] Xu C,Gamage S,Rao P N,et al.vSlicer:latency-aware virtual machine scheduling via differentiated-frequency CPU slicing[C]//International Symposium on High-Performance Parallel and Distributed Computing.ACM,2012:3-14.
[8] Xi S,Wilson J,Lu C,et al.RT-Xen:Towards Real-time Hypervisor Scheduling in Xen[C]//International Conference on Embedded Software,EMSOFT,2011:39-48.
[9] Seo J,Kim K H.A Prototype of Online Dynamic Scaling Scheduler for Real-Time Task based on Virtual Machine[J].International Journal of Electrical and Computer Engineering,2016,6(1):205-211.
[10] Cheng K,Bai Y,Wang R,et al.Optimizing Soft real-time scheduling performance for virtual machines with SRT-Xen[C]//Cluster,Cloud and Grid Computing (CCGrid),2015 15th IEEE/ACM International Symposium on.IEEE,2015:169-178.
[11] Venkatesh V,Nayak A.Optimizing I/O Intensive Domain Handling in Xen Hypervisor for Consolidated Server Environments[M].Green,Pervasive,and Cloud Computing. Springer International Publishing,2016:180-195.
VIRTUALMACHINESCHEDULINGALGORITHMFORLATENCY-SENSITIVEAPPLICATIONS
She Minggao Zhang Yan*
(SchoolofComputerScienceandTechnology,WuhanUniversityofTechnology,Wuhan430070,Hubei,China)
This paper proposes two improvements to the problem that the Credit scheduling algorithm can not guarantee the real-time. First, we can shorten the system respond time by loading balancing about the virtual CPU in BOOST state when it has a lot of I/O tasks. Second, we can use dynamic time slice instead of the former fixed time slice to adapt to the dynamic change of the virtual CPU. The impact of the improvement on the I/O task is evaluated by detecting the average response time and turnaround time of the task. The experimental results show that the average response time of the improved Credit scheduling algorithm is 102.3% lower than that before improvement, which can significantly enhance the performance of I/O latency-sensitive applications.
Xen Credit scheduling algorithm Virtualization Load balancing
TP3
A
10.3969/j.issn.1000-386x.2017.09.006
2016-11-28。佘名高,副教授,主研领域:计算机体系架构。张颜,硕士生。
猜你喜欢
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
计算机测量与控制(2019年6期)2019-06-27
电子制作(2019年10期)2019-06-17
军营文化天地(2018年2期)2018-12-15
电子制作(2018年14期)2018-08-21
