
基于k-泛化技术的时空数据个人隐私保护方法
2017-09-22 09:28杨姿宁博李毅
华东师范大学学报(自然科学版) 2017年5期
杨姿,宁博,李毅
(大连海事大学信息科学技术学院,辽宁大连116026)
基于k-泛化技术的时空数据个人隐私保护方法
杨姿,宁博,李毅
(大连海事大学信息科学技术学院,辽宁大连116026)
近些年来,基于位置系统的设备越来越多,从而导致用户的大量位置信息被移动设备获取并利用,从数据挖掘的角度来说,这些数据具有不可估量的价值,但从个人隐私方面来说却恰恰相反,每个人都不希望自己的信息被泄露和利用,从而引发了人们强烈的隐私关注.目前许多文献都提出了隐私保护技术来解决这个问题,概括来说是干扰、抑制和泛化几大类.为了对个人时空数据的隐私进行保护,本文提出了k-泛化的方法.对用户可能出现的点进行范围限定,更好地提高了数据的可用性;对泛化节点的选取要使得用户的安全性最高;考虑了多个敏感节点存在情况下的解决方案,并且出于提高数据效用的目的对多个敏感节点进行了优化.最后通过实验评估了算法的性能并且验证了算法保护个人隐私是有效的.
隐私;时空数据;匿名;泛化
0 引言
随着计算机科学技术的发展,人们的生活发生了日新月异的变化.近年来,个人位置信息的可用性增加导致了越来越多的系统记录和处理位置数据,尤其是基于位置系统的设备的日益普及,例如智能手机、GPS设备等深入人们的生活[1],这些设备收集大量的关于用户的位置信息,这些位置信息加上时间的概念便是时空数据,设备得到的时空数据具有很大的实用价值,例如可以用来和朋友共享位置信息,寻找最近的饭店,甚至可以用来分析路况,调节交通流,避免道路拥堵等.
虽然基于位置的系统得到的个人时空数据已经被证明可以给个人和社会带来巨大的利益,但是越来越多用户的位置信息曝光引发了人们对于位置隐私的强烈关注,并提出了重要的隐私问题[2].首先,位置信息本身可以被认为是敏感的.此外,它可以很容易地链接到各种其他信息,通过定期收集和处理准确的位置数据,可以推断出个人的家庭或工作地点、政治观点或宗教倾向等.但是一个人通常并不希望泄露自己的个人信息.例如,一个人可能不希望别人知道他或她经常停留在夜总会[3].
解决隐私问题的最常用的方法是去除个人的标识符[4-6]以及将数据进行加密[7],例如标识符有姓名等,将标识符去除后将其他信息发布出去,攻击者看到的只是一系列的时空数据点而无法找到所对应的每个人[3];而加密则是将数据加密之后再发布,缺点在于加密所需要的计算代价很大.然而,这些方法是远远不够的,因为攻击者有自己的先验知识,例如邻域图,攻击者所拥有的额外的信息可以重新鉴定出被攻击的用户[8-9].为了克服链式攻击这个问题,一种称为k-匿名的算法被提出来.在时空数据方面,k-匿名的含义是对于目标用户的轨迹来说至少有k-1条区分轨迹[10].这就意味着,对于攻击者来说,相对于目标用户至少可以映射到一组k个轨迹从而分辨不出目标用户.但是,k-匿名技术也存在着缺陷,例如它在一个等价组中不执行多样性的敏感信息.之后Ashwin等人提出l-多样性的概念[11].l-多样性最基本的策略思想是保证每一个等价组的敏感属性至少有l个不同的值,即使得等价组中的状态呈现出多样性,以抵御同质攻击.
在论文中提出的k-泛化概念不同于之前的k-匿名,因为之前k-匿名的所有顶点都是一致的,论文区分了敏感和非敏感的点,非敏感节点被视为公共区域,不能够暴露用户的隐私,而对于敏感节点,假若用户停留,则被认为是一条敏感信息,应该被保护,敏感节点可以是夜总会等.论文根据数据表塑造一个模型地图,点对应于真实的位置节点,边对应于道路连接节点指示道路的方向.
本文的贡献点列举如下:
(1)对用户可能出现的点进行范围限定,更好地提高了数据的可用性;
(2)提出了k-泛化的概念,泛化的过程也出于数据可用性的考虑;
(3)对泛化节点的选择采用基于安全性最高的原则;
(4)当多个敏感节点存在时,我们出于数据效用的目的做了简单的优化.
论文的章节安排如下:在第1部分,提出了基于隐私保护的研究现状,介绍了当前所流行的隐私保护技术.在第2部分,提出了本文的模型定义,给出了攻击者模型以及图和轨迹的定义,也给出了k-泛化、近邻区域、相似轨迹集的概念等.在第3部分,给出了方法的详细实现过程以及例子描述.在第4部分,给定了真实的数据集并且对算法进行了性能分析.最后第5部分是本文的结论和未来的工作.
1 相关工作以及背景知识介绍
从原始数据中仅仅去除个人标识符之后进行数据发布已被证明是不足以保护隐私.其他在数据集中记录的属性,如年龄、性别和家庭住址等公共知识的存在同样可以用来链接到个人的身份.k-匿名技术最初提出是用于表格数据,而后在时空数据上进行了扩展,也同样适用.该方法保证了对于每一条记录,根据选定的属性,都至少有k-1条难以分辨的记录相对应.在匿名未能保护隐私在匿名组的所有成员都有相同的敏感信息,即不能抵抗同质性攻击.为了克服这个问题提出了l-多样性的技术,它限制了个人可以与一个敏感的信息相关联的概率.而l-多样性模型不能有效防止相似性攻击,即攻击者可以根据每个组的敏感属性值具有的语义相似性推测出用户的敏感信息,因此提出了t-clossness方法[12],该方法要求敏感属性值在每个组中的分布和原始数据集中的分布之间的差值不超过t.
通过抑制和扰动也是隐私保护的常用的方法.抑制的方法也就是说不发布敏感的地点;而扰动则是通过泛化或者加入假数据的方法将敏感节点进行隐藏,从而实现用户的隐私保护.而针对于轨迹数据来说,轨迹聚类亦可作为隐私保护的一个步骤[13-14].论文利用了泛化的思想,通过泛化将敏感节点进行隐藏.
文献[3]提出了基于位置服务的匿名和静态数据发布的时空数据的隐私保护,其目标和本论文类似,但是方法不同,他们的目标是发布一个轨迹数据集,同时保持数据集中的个人的身份.他们泛化/凝聚地实现k-匿名.本文的方法是先对用户可能出现的位置进行范围限定,去除掉“假的”位置.论文在泛化点的选择原则是保证最小的变动实现最高的安全性.文献[15]是在空间数据的隐私保护,在k-同构的基础上提出了k-对称的概念,并且设计了两个基于骨干的抽样算法.
除了上述方法,还有一种方法也很流行,叫做差分隐私[16].由于其严格的理论保证已成为隐私数据发布的常用的隐私模型.该模型的优点在于不需要特殊的攻击假设、不关心攻击者所拥有的背景知识,同时给出了定量化分析来表示隐私泄露风险.文献[17]提出了w-event的概念,提出了一个滑动窗口方法捕获广泛的w-event隐私机制,引入了预算分配和预算合并的方案,但是这种机制并不适用于本论文的时空数据.文献[18]提出了一个差异隐私机制,通过添加噪声给前缀树之后发布交通数据.作者讨论了在时间维度的轨迹上扩展他们的方法,但不包括任何复杂性分析或经验评估.文献[19]提出了l-轨迹的概念,设计严谨和灵活的隐私模型,弥合的理论局限性和实际需求之间的差距.它们以严谨性以及灵活性的重要性为目的,然后提出了两种差分隐私模型能够以一个实际的方式扩展差分隐私,它们和本文的目的不同,但是弥补理论局限和实际需求之间的差距是一样的,本文也考虑了效用性的要求使得文中的方法在实际应用中效用能够有一个很好的体现.文献[20]提出差分隐私的泛化概念,提出了平面拉普拉斯机制,该论文是在空间位置上进行的隐私保护,而本论文是基于时空数据.
2 问题的定义
本章假设攻击者具有的背景知识:
(1)攻击者知道敏感节点的所在,例如,我们都知道夜总会可以当成一个敏感节点,因此敏感节点对于攻击者来说是公开的;
(2)攻击者拥有移除掉个人标识符的轨迹数据集;
(3)攻击者可以根据一些背景知识推测出用户的轨迹,因为家庭住址和工作单位这些信息可以比较容易地获得.
本章将在每个时间戳i收集到的用户的时空数据点Di,i∈{1,n}.在Di中每一个数据点(用户i,时间t,地点v)表示用户i在时间t的地点是v,在表1中所示,其中0代表用户在相应的时间是停在了最早0之前出现的位置点.本章根据表1中的数据画出一个图M,如图1所示,不用的线代表不同的用户的轨迹.将用户经过的位置作为一个有向轨迹图M,M=(V,E),V代表顶点的集合,即V=(v1,v2,…,vn).E代表边的集合,即E=(e1,e2,…,em).ei=(vx,vy)代表从顶点vx到顶点vy的一条路径.敏感节点S⊂V, S=(s1,s2,…,sf),|S|表示敏感节点的总数.用户的轨迹用tr来表示.
在论文中,轨迹图包含兴趣点的节点(例如,学校、医院、酒吧、夜总会和酒店等).这样的兴趣点在数据表中出现并且位置的经纬度是已知的,那么这个兴趣点可以被添加在图中作为一个节点.其中定义1到4为已知定义,定义5到9是为了提出方法而新引入的定义.
定义1一个轨迹图M=(V,E),一组gi=(Vi,Ei)是一个M的连通子图,即ej=(vx, vy)∈Ei当且仅当ej∈E和vx,vy∈Vi.符号g.s表示在g中的敏感节点.
定义2地图M∗=(V∗,E∗)是M=(V,E)的泛化[3],当且仅当V∗=(V-Vi)∪B,其中B=(b1,b2,…,bi)表示由gi泛化出的区域.E∗=(E-Ei)∪P∪Q,其中P={(vx,ni)|∃vy∈Vi,(vx,vy)∈E∧vx∈V∗}并且Q={(ni,vx)|∃vy∈Vi,(vy,vx)∈E∧vx∈V∗},其中N={n1,…,nc}表示新加入的节点.
定义3用户的轨迹是由一系列有序的时间戳对组成的,{(v1,t1),(v2,t2),…,(vi, ti),…,(vm,tm)},其中(vi,vi+1)∈E,ti<ti+1.
本章用元组(vi,ti)表示一个用户的轨迹,其中用(0,ti)表示用户在ti时刻停在了ti时刻之前的最先出现的0之前的位置.其中,每个时间间隔是30 min,用户移动的速度v给定.例如tr1={(2,t1),(3,t2),(4,t3),(6,t4),(0,t5),(0,t6),(7,t7),(0,t8),(0,t9)},意思是用户1在t1时刻在2位置,之后t2时刻去了3位置,之后t3时刻去了4位置,之后t4时刻停在了6位置,停下的时间是1 h,而后在t7时刻去了7位置并停在了7位置.
定义4对于泛化得到的泛化区域gi,本章将轨迹中通过gi中的点的部分用gi代替,从而得到泛化之后的用户的轨迹tr∗,并且不指定gi的时间,因为时间都被隐含在通过gi的这段时间内部.如图1所示,泛化区域g1,对于用户2来说,用g1代替之后的轨迹列举如下tr1={(1,t1),(2,t2),(3,t3),(4,t4),(0,t5),g1,(5,t7),(0,t8),(7,t9)}
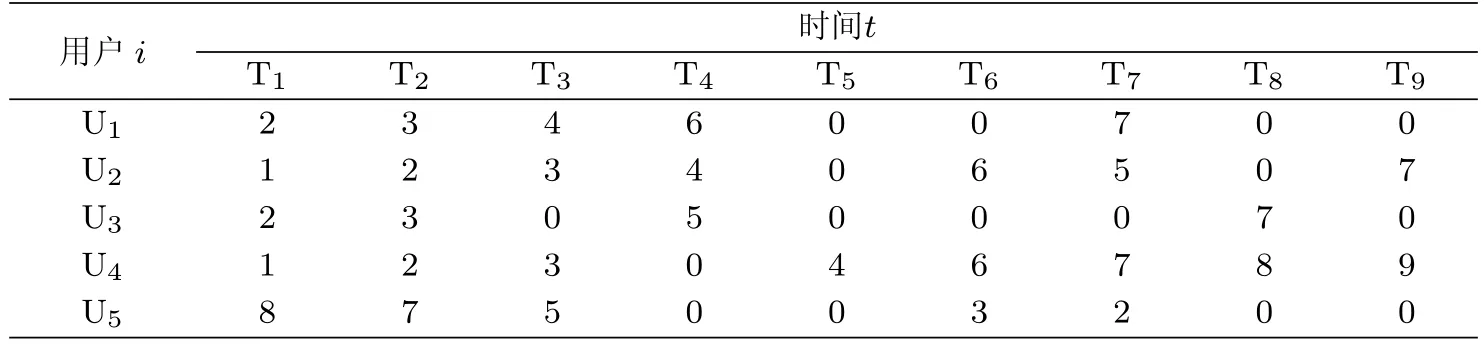
表1 用户轨迹数据表Tab.1 User trajectory data table

图1 用户轨迹图Fig.1 Graph of user trajectory
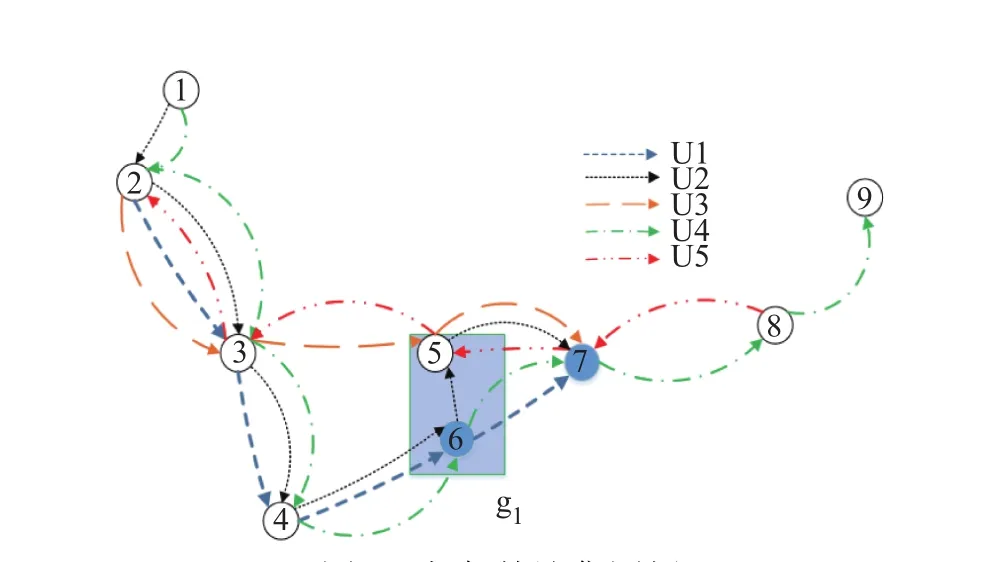
图2 相似轨迹集图例Fig.2 Similar trajectory set example
定义5近邻区域:近邻区域Close Area指以泛化区域gi为原点,以目标用户在敏感节点停下的时间间隔内所能走过的路程s为半径所得到的范围,s=v*t,t表示目标用户在敏感节点停下的时间间隔,表示的含义是目标用户在时间间隔内所能出现的所有可能的地点,而去除掉了不符合条件的地点.时间选用以目标用户在敏感节点停下的时间间隔的原因在于敏感节点存在泛化区域中并且攻击者攻击的目标是目标用户,因此采用目标用户的停留时间更为合理.采用这种方式首先去除用户在时间间隔内不能到达的地点,为泛化区域的选择圈定了选择范围,为了更好地达到“以假乱真”的效果,更好地提高了数据的可用性.因为假设有一种情况是将离目标用户很远的地点泛化到了泛化区域,那么攻击者可以很明确地知道该地点目标用户是无法在时间间隔内到达的,攻击者知道这个点是假的.
例如图1,假设用户U1停在敏感节点6,用户在停留时间内所能到达的距离是17,那么以节点6为圆点,半径17范围内为近邻区域,包含在近邻区域的点只有节点5.
定义6相似轨迹集Similar Trajectory Set:所有的和目标用户的轨迹方向相似,时间相近,在gi泛化点中停下的轨迹都可以被认为是相似轨迹集中的元素.通俗的说就是在一个相似轨迹集中的轨迹遵循相同的路径,那么就认为轨迹是相互相似的.
例如图2,假设目标用户是U1,轨迹是tr1,那么在泛化区域g1中,包含节点{5,6},停在泛化区域g1中的点的轨迹包括tr1,tr3,tr5,而tr5方向和目标用户相反,最终Similar Trajectory Set={tr1,tr3}.
定义7 gi泛化区域公开的概率:一般来说,最简单的方式是将停在敏感节点的轨迹值和所有在相似轨迹集中的轨迹的比值来定义,即

定义8 k-泛化:我们说泛化之后的图M∗满足k-泛化,当且仅当{p≤k|∀gi∈G},即所有的敏感节点的泛化之后的泛化区域gi公开的概率都满足k-泛化.
定义9收益比:

p−表示在gi中找的前一个点的泛化区域公开的概率,p+表示在gi中找的后一个点的泛化区域公开的概率.
提出收益比的意义在于要使得用户的安全性最高,安全性最高对于用户来说是被发现的概率最低,即在泛化区域中和用户类似的轨迹越多则用户越不容易被发现.假设在满足条件的前提下,添加点1进去泛化区域之后,用户被发现的概率是1/2,而如果添加点2进入泛化区域之后,用户被发现的概率是1/5,那么在同等条件下选择点2添加进泛化区域.
假设情形1:添加点1进入区域之后不满足k-泛化,需要继续添加;情形2:只添加点2,既使得用户被发现的概率低,又比情形1添加的点数少.因此,收益比的提出既提高了数据的效用性又保障了目标用户拥有更好的安全性.
3 k-泛化——时空数据隐私保护的方法
本章提出了我们算法的框架以及算法的实现,并用伪代码表示.
框架分为2个阶段,阶段一将数据构造成一张图,查找用户在敏感点停留时间内所能出现的范围,以此进行范围限定,将用户不可能出现的点去除掉,那么只将近邻区域中的点作为可能加入到泛化区域gi中的候选节点;阶段二:对敏感节点进行泛化,根据k值决定泛化的次数,直到所有的敏感节点泛化之后都满足k-泛化,将泛化之后的图发布轨迹匿名.
由定义9可知,目标是限制攻击者知道目标用户停在敏感节点的概率,实现的方式是通过泛化敏感节点并且使得目标轨迹满足k-泛化.当有多个敏感节点存在时,要使得目标用户的整个轨迹在任何一个泛化区域gi都要满足k-泛化.其次,基于提高效用的目的,本章要对泛化区域中的点进行优化.要使得匿名后的数据有最大程度的效用,本章提出两个准则:
Rule1:泛化区域gi要尽量少;
Rule2:泛化区域gi中的点数要尽量少.
gi中的点数越少,被泛化的点数越少,数据越真实,既保护了目标用户的隐私又能达到提高效用的目标.针对Rule1,泛化区域gi中的点要尽量少,本章在第2阶段实现.采用的方法是对各个节点分别加入泛化区域,计算收益比pr,根据pr挑选出点加入到泛化区域,既保证了数据的效用性又保证了用户拥有更高的安全性;针对Rule2,倘若敏感节点和泛化区域gi相连,则将敏感节点加入泛化区域gi中.此方法使得泛化区域gi减少,提高了算法的效率也使得数据可用性提高.
本章提出一个算法:将隐私值k,轨迹数据集D S,敏感节点集S作为输入,输出一个匿名后的地图M∗.
算法1展示了算法的内容.
步骤1:统计轨迹数据集形成一个图(行1-2),getSet(数据集)方法表示将数据集放入到数据库中,creatGraph(DS)表示将数据构成为一个图,G表示所有泛化区域以及泛化后的轨迹的集合.S为敏感节点集.

表1 参数估计模拟结果Tab.1 Simulation results of parametric estimation
步骤2:将一个敏感节点放入gi中,之后查找用户在敏感节点停留的时间间隔,按用户的r=v*t来计算用户在停留时间段内所能走过的路程,以泛化区域gi为圆心,路程r为半径画圆,找出在包含在圆内的所有的节点(行3-13),candidateSet是可能被添加进泛化区域的候选节点,即在圆内中的点的集合,gi是泛化区域,p是存在路径,三元组<gi,vi,p>表示和泛化区域gi之间存在路径.
步骤3:判断是否有敏感节点在圆内并且和泛化区域相连,若有则直接加入到泛化区域(行14-15),若没有则以此圆为范围,泛化区域中的点在圆内中选择,遍历在圆内并且和泛化区域gi中的点相连的点(行16-17).
步骤4:寻找停留在泛化区域的路径并且方向要和目标用户的路径方向一致的前一个节点,之后计算概率p,记为p−;之后寻找后一个节点,加入计算概率p,记为p+,利用收益比,用收益比和1比较,假若比1小则将前一个点加入泛化区域,否则将后一个点加入到泛化区域,将符合在圆内且和泛化区域gi相连的点遍历完成(行18-31).Similar Trajectory Set(g,candidateSet[i])候选节点添加到泛化区域gi之后的相似轨迹集,Eq表示泛化之后用户轨迹,p−表示候选集合中第i个节点加入泛化区域之后的概率,p+表示候选集合中第i+1个节点加入泛化区域之后的概率,pr表示收益比,fNode表示概率最小的点,G.add(gi,Eq)表示将泛化区域gi以及泛化后的相似轨迹添加到G中.至此将p值最小的点加入到了泛化区域,假若此时满足k-泛化则结束,若不满足,则将此泛化区域作为圆点继续按上一步骤进行循环,直到满足k-泛化.直到所有的敏感节点都满足k-泛化.
步骤5:发布匿名后的地图M∗,anonymizeMap(M,G)表示将M匿名化为地图M∗,M∗表示匿名后的发布的地图.
图3、4和5展示了算法流程的例子.敏感节点是6和7,目标用户为U1,所有用户的轨迹如下所示:


图3 只有一个点的泛化区域g1Fig.3 Generalization region g1with just one vertex
从单个的敏感节点6开始,泛化点g1只包含节点6.此时停在敏感节点的只有目标用户U1,造成了隐私泄露,因此扩大泛化点g1.如图3所示.首先第一步寻找范围.假设用户的速度是30 km/h,停留的时间是2个间隔,即1 h,那么圆的半径是30 km,由图中可知在范围内的点包括{4,5},若将节点4加入到g1中,此时停在g1点的轨迹包括tr1和tr2,分别表示为tr1={(2,t1),(3,t2),g1,(7,t7),(0,t8),(0,t9)},tr2={(1,t1),(2,t2),(3,t3),g1,(5,t7),(0,t8), (7,t9)},形成的相似轨迹集是{tr1,tr2}此时p−(4)=0.5;若将节点5加入g1中,此时停在g1的轨迹包括tr1、tr2、tr3和tr5,因为tr5方向和目标用户的方向相反,因此去除,此时相似轨迹集中的轨迹是{tr1,tr2,tr3},p+(5)=1/3.收益比pr=p−/p+=3/2,因此将节点5加入到g1中.此时g1中泛化的点是{5,6},如图4所示.
若k≥1/3,则泛化过程结束,若k<1/3,假设k=1/4,则继续将g1泛化,第一步找范围,范围扩大到{3,4,7},首先判断节点7是敏感节点,加入到g1,当把节点3放入g1时,此时的相似轨迹集是{tr1,tr2,tr3,tr4},p−(3)=1/4,当把节点4放进g1时,p+(4)=1/3,收益比pr=p−/p+=3/4,将节点3放入g1,此时满足k-泛化,结束泛化.最终g1中的节点是{3,5,6,7},完成匿名,发布匿名图M∗.如图5所示.
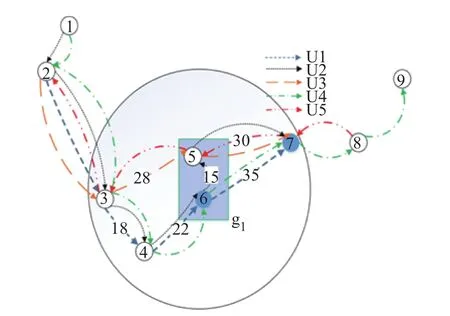
图4 有两个点的泛化区域g1Fig.4 Generalization region g1with two nodes
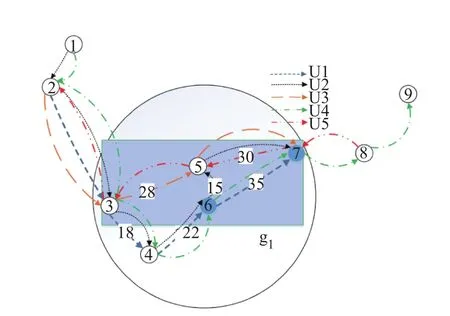
图5 最终的泛化区域g1Fig.5 Final generalization region g1
4 实验
本章评估算法的性能,评估数据集采用2个真实的轨迹数据集,数据集是共享单车数据,所在城市是美国纽约.分别是2016年的数据和2017年的数据.数据量为126 000条.顶点为603个,边数为124 287条.实验通过改变给定的k值的大小来说明各项指标的变化.
泛化区域的大小,算法泛化敏感节点周围的轨迹,通过用一个泛化区域代表轨迹的一部分,更换泛化区域中轨迹的节点,从而到达隐藏目标轨迹的目的.因此,在泛化区域中的轨迹是伪轨迹.直观来说,如果泛化的区域越大,内部包含的节点越多,泛化区域中的伪轨迹越多,轨迹被扭曲越多,发布的数据的效用降低.讨论一个极端的情况,假设所有用户经过的所有的兴趣点都包含在一个泛化区域gi中,那么所有的轨迹都被伪装了,发布出的数据完全没有效用价值.因此,泛化区域的大小是评价算法效用的一个有用的指标.而算法运行的时间也是评判算法效用的一种方式,因此时间也可以作为一个评判标准.其次泛化率,即泛化轨迹和总的轨迹数量的比值,也体现了数据的效用性,若泛化率很高则表明数据的可用性很低,因此泛化率也可以作为评判算法优劣的标准.其次也列举了敏感节点n的个数对平均泛化区域的影响.
图6展示了参数k是如何影响平均泛化区域的大小的.实验结果是随着k值的减小,平均泛化区域的大小增加.因为k值越小,意味着更加严格的隐私,需要扩大泛化区域的大小才能满足k-泛化的要求,结果是一个较低水平的效用.

图6 参数k对平均泛化区域大小的影响Fig.6 Average generalization area size for the parameters k limit
图7显示了不同的k值对算法运行时间的影响.实验结果表明随着k值越大,运行时间越小.原因在于k值越大,所需要扩大泛化区域的次数减小,算法运行时间减少,效率有所提高.

图7 参数k对运行时间的影响Fig.7 Time performance for the parameters k limit
图8展示了不同的k值对泛化率的影响.实验结果表明k值越大,泛化率越小.因为k值增大,泛化区域中的点变小,通过泛化区域的轨迹自然减少,泛化率降低.由实验结果来看,在k=1/30时,泛化率也很小,而此时的k对于用户来说足够保护自己的隐私,攻击者发现用户的概率很小,因此,本文的算法数据的可用性可以保证.
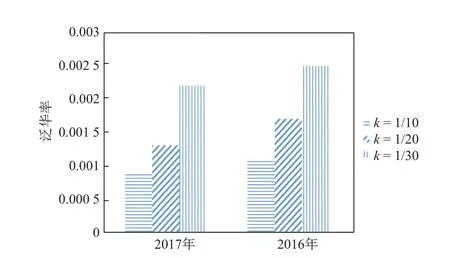
图8 参数k对泛化率的影响Fig.8 Generalization ratio for the parameters k limit
图9展示了敏感节点n的个数对平均泛化区域的影响.当敏感节点数固定时,k的值越小表明用户所要求的安全性越高,泛化区域的大小自然变大.当n=30时,k值是1/30时,平均泛化区域的大小对比于总的顶点数来说是很小的,而此时的k值完全能够保证用户的隐私.

图9 敏感节点n的个数对平均泛化区域的影响Fig.9 The inf l uence of the number of sensitive nodes n on the average generalization region
5 结论
本文提出了k-泛化的概念,通过泛化敏感节点来达到保护用户隐私的目的.本文的方法限制了一个用户停止在一个敏感位置的概率来抵抗强大的攻击者,攻击者知道基本的地图.本文将用户可能出现的点进行范围限定,更好地提高了数据的可用性;提出了k-泛化的概念,泛化的过程也出于数据可用性的考虑;对泛化节点的选择采用基于安全性最高的原则;当多个敏感节点存在时,本文出于数据效用的目的做了简单的优化.提出的算法既实现了最小的泛化又提高了用户的安全性.并且实验测试表明,本文的方法是能够保持实用性,同时满足用户提供的隐私参数.本文需要说明的是k-泛化方法能够很好的保护用户的隐私,但是并不能说明是最优的,即范围最小或覆盖点数最少.本文利用两个准则Rule1和Rule2最大程度的保障算法达到最优.未来的方向是将隐私保护进行扩展,例如对用户间的关系进行挖掘并且保护,从而使得用户的隐私更加得到更大范围的保护.
[1]XIAO Y,XIONG L.Protecting Locations with Dif f erential Privacy under Temporal Correlations[C]//The ACM Sigsac Conference on Computer and Communications Security.New York:ACM,2014:1298-1309.
[2]GEDIK B,LIU L.Protecting location privacy with personalized k-anonymity:Architecture and algorithms[J]. IEEE Transactions on Mobile Computing,2008,7(1):1-18.
[3]CICEK A E,NERGIZ M E,SAYGIN Y.Ensuring location diversity in privacy-preserving spatio-temporal data publishing[J].The VLDB Journal,2014,23(4):609-625.
[4]HUNDEPOOL A J,WILLENBORG L C R J.Mu-and tau-argus:Software for statistical disclosure control[J].
[5]SAMARATI P.Protecting respondent’s identities in microdata release[J].IEEE Trans Knowl Data Eng,2001, 13(6):1010-1027.
[6]YU T,JAJODIA S.Secure Data Management in Decentralized Systems[M].New York:Springer,2007.
[7]田秀霞,王晓玲,高明,等.数据库服务-安全与隐私保护[J].软件学报,2010(5):991-1006.
[8]ABUL O,BONCHI F,NANNI M.Never Walk Alone:Uncertainty for Anonymity in Moving Objects Databases[C]//IEEE,International Conference on Data Engineering.[S.l.]:IEEE Computer Society,2008: 376-385.
[9]ATZORI M,ATZORI M,SAYGIN Y.Towards trajectory anonymization:A generalization-based approach[C]// Sigspatial ACM Gis 2008 International Workshop on Security and Privacy in Gis and Lbs.New York:ACM, 2008:52-61.
[10]SWEENEY L.K-anonymity:A model for protecting privacy[J].International Journal on Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):557-570.
[11]MACHANAVAJJHALA A,KIFER D,GEHRKE J.L-diversity:Privacy beyond k-anonymity[J].Acm Transactions on Knowledge Discovery from Data,2007,1(1):3.
[12]LI N H,LI T C,VENKATASUBRAMANIAN S.t-Closeness:Privacy Beyond k-Anonymity and l-Diversity[C]// IEEE,International Conference on Data Engineering.[S.l.]:IEEE,2007:106-115.
[13]MAO J,SONG Q,JIN C,et al.TSCluWin:Trajectory Stream Clustering over Sliding Window[M]//Database Systems for Advanced Applications.US:Springer,2016.
[14]ZHANG Z,WANG Y,MAO J,et al.DT-KST:Distributed top-k similarity query on big trajectory streams[J]. 2017:199-214.
[15]WU W,XIAO Y,WANG W,et al.k-symmetry model for identity anonymization in social networks[C]//EDBT 2010,International Conference on Extending Database Technology.Switzerland:DBLP,2010:111-122.
[16]DWORK C.Dif f erential privacy[J].Lecture Notes in Computer Science,2006,4052(2):1-12.
[17]KELLARIS G,PAPADOPOULOS S,XIAO X,et al.Dif f erentially private event sequences over inf i nite streams[J].Proceedings of the Vldb Endowment,2014,7(12):1155-1166.
[18]CHEN R,FUNG B C M,DESAI B C,et al.Dif f erentially private transit data publication:a case study on the montreal transportation system[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2012:213-221.
[19]CAO Y,YOSHIKAWA M.Dif f erentially private real-time data release over inf i nite trajectory streams[C]//IEEE International Conference on Mobile Data Management.[S.l.]:IEEE,2015:68-73.
[20]MIGUEL E ANDR´ES,NICOLAS E BORDENABE,LONSTANTINOS Chatzikokolakis,et al.Geo-indistinguishability:Dif f erential privacy for location-based systems[C]//Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications security.New York:ACM,2013:901-914.
(责任编辑:张晶)
Privacy preserving method of spatio-temporal data based on k-generalization technology
YANG Zi,NING Bo,LI Yi
(College of Information Science and Technology,Dalian Maritime University, Dalian Liaoning 116026,China)
In recent years,more and more devices based on location system,resulting in a large amount of location information by the mobile device users to access and use,from the perspective of data mining,the data is of immeasurable value,but in terms of personal privacy,people don’t want their information to be leaked and used to sparked strong privacy concerns.At present,many papers have proposed privacy protection technology to solve this problem.Generally speaking,there are several categories of interference, suppression and generalization.In order to protect the privacy of personal spatio-temporal data,this paper proposes a method of k-generalization.To limit the scope of the user may appear,improve the availability of data;selection of nodes to generalization so that the user’s maximum security;considers multiple sensitive node solutions exist under the condition,and for the purpose of improving the data utility on a number of sensitive nodesare optimized.Finally,the performance of the algorithm is evaluated by experiments,and it is proved that the algorithm is ef f ective to protect personal privacy.
privacy;spatio-temporal data;anonymous;generalization
TP391
A
10.3969/j.issn.1000-5641.2017.05.016
1000-5641(2017)05-0174-12
2017-06-20
国家自然科学基金广东联合基金重点项目(U1401256);辽宁省自然科学基金(201602094)
杨姿,女,硕士研究生,研究方向为时空数据隐私保护.E-mail:winni103@vip.qq.com.
宁博,男,副教授,硕士生导师,研究方向为数据管理,隐私保护. E-mail:ningbo@dlmu.edu.cn.
猜你喜欢
四川党的建设(2022年8期)2022-04-28
指挥与控制学报(2022年4期)2022-02-17
小学生学习指导(低年级)(2020年11期)2020-12-14
少儿美术(2019年7期)2019-12-14
作文大王·低年级(2018年10期)2018-12-06
爱你(2018年16期)2018-06-21
中国塑料(2016年9期)2016-06-13
小猕猴智力画刊(2016年5期)2016-05-14
指挥与控制学报(2015年4期)2015-11-01
