
基于分布式系统OceanBase的并行连接
2017-09-22 09:28徐石磊王雷胡卉芪钱卫宁周傲英
华东师范大学学报(自然科学版) 2017年5期
徐石磊,王雷,胡卉芪,钱卫宁,周傲英
(华东师范大学计算机科学与软件工程学院,上海200062)
基于分布式系统OceanBase的并行连接
徐石磊,王雷,胡卉芪,钱卫宁,周傲英
(华东师范大学计算机科学与软件工程学院,上海200062)
随着应用数据的飞速增长以及分布式数据库系统的不断涌现,数据存储在物理独立的节点已经成为一种趋势.在这种情况下,当应用需要进行复杂join查询时,就会不可避免地产生非常多的网络传输代价.所以,如何提高分布式系统中join查询的效率成为研究热点.本文在分析分布式数据库系统OceanBase执行nested loop join、Hash join、semi-join等算法的基础上,提出了合理利用硬件资源采用多线程并行执行join操作的优化思想,并在OceanBase数据库中分别对nested loop join、Hash join、semi-join等算法进行了并行改造.实验结果表明,在一定线程数内join算法执行效率与并行度呈正相关.
查询;semi-join;OceanBase;并行连接
0 引言
OceanBase[1]是阿里巴巴公司开发的分布式数据库,其设计目标是支持数百TB的数据量以及数十万TPS、数百万QPS的访问量.因此,如何实现对如此庞大数据的快速查询服务,给我们的工作提出了一个巨大的挑战.
通过对分布式数据库系统OceanBase的架构分析,可以知道,虽然OceanBase有多个数据存储节点和多个查询处理节点,但是,目前各个查询处理节点在处理join(连接)工作时尚且无法实现协同工作.因此,无法通过将任务分解给多个查询节点协同工作的方式实现高效快速查询.此外,在查询处理节点中,对于join查询操作,OceanBase只是简单地实现了串行化执行,并没有合理利用硬件资源和数据冗余存储的特性,由此给查询带来了极大的网络传输和join时间,导致系统在处理大表数据join查询时效率非常低下.针对这一缺点,我们提出了一种即时有效地并行连接优化方案:将数据进行范围切分,根据数据多重备份特性,设置多线程读取数据;每个线程独立读取数据,数据达到后独立执行join操作.从而实现了各个查询节点中join操作的并行化执行,极大地提高了OceanBase做复杂join查询的效率.本文的研究重点是nested loop join、Hash join、semi-join等join算法的并行化设计以及数据分片的切分方式.
论文的内容组织如下:第1节简要介绍OceanBase数据库的整体结构及传统的nested loop join,merge sort join、Hash join等join算法和semi-join、分布式join算法;第2节介绍OceanBase中传统join算法的查询原理和基于semi-join的传统join算法查询原理;第3节介绍在OceanBase中对nested loop join、Hash join、semi-join等join算法的并行优化设计;第4节从并行度对查询效率的影响、并行度对各join算法执行效率的影响,以及并行度对基于semi-join算法的各join算法执行效率的影响等3方面进行全面的实验验证;第5节对本文进行总结.
1 相关工作
OceanBase分布式数据库整体架构主要分为4个模块:主控服务器RootServer(以下简称为RS)、数据存储服务器ChunkServer(以下简称为CS)、增量数据服务器Update-Server(以下简称UPS)以及查询处理服务器MergeServer(以下简称为MS).RS负责管理集群中的所有服务器,一般设置一主一备两个RS;UPS主要负责处理系统的增量数据更新,一般也设置一主一备两个UPS;MS则负责接收和解析用户的SQL请求,经过词法分析、语法分析、查询优化等一系列操作后转发给相应的CS或者UPS;CS主要负责存储系统的基准数据,基准数据一般存储两到三份,可配置.
传统的连接算法有嵌套循环连接(nested loop join)算法、归并排序连接(merge sort join)算法以及哈希连接(Hash join)算法.这3种算法的提出都有特定的问题背景和适用情况.伴随着分布式数据库的发展和普及,Bernstein等[2]又提出了semi-join(半连接)算法,此算法可大幅减少join过程中数据的传输代价.此外,在分布式系统中,伴随着MapReduce、Spark等系统的发展,越来越多的分布式系统开始采用类似Map/Reduce[3]的计算模型,这类系统旨在通过任务分解的方式,减小join计算代价.下面简要介绍这些算法的特点以及研究发展情况.
1.1 nested loop join算法
Blasgen等[4]在1977年提出了nested loop join算法.该算法适合于两表数据量较小并且内存可以存放的情况.后来,在共享内存架构下,Zhou等[5]又提出了利用SIMD技术优化嵌套循环连接的3种方式:复制外层循环;复制内层循环;旋转方式.在无共享架构下,Spark结构中采用广播形式将数据传到其他节点上[6].
1.2 merge sort join算法
针对嵌套循环连接处理大数据时效率低的问题,Blasgen等[4]提出了merge sort join算法.该算法首先对两张表排序,然后进行顺序扫描;当其中一张表扫描结束后,算法也立即结束.这曾经被认为是最好的连接算法[7].在之后对归并排序连接算法的研究中,Kim等[8]指出了归并排序连接算法的效率与SIMD宽度有关.
1.3 Hash join算法
Babb[9]在1979年第一次提出了以哈希(Hash)函数为基础的连接算法.当小表数据量较小可放在内存中且小表的连接列具有非常好的选择性时,效率很好.随着硬件技术的更新换代,Boncz等[10]提出了Radix连接算法,算法充分利用了硬件资源,极大地优化了连接算法在内存中的Cache缺失和TLB缺失.
1.4 semi-join算法
Bernstein在1981年提出了semi-join算法.该算法针对一张小表和一张超大表的内连接,目的在于利用小表的连接列对大表进行过滤.但是semi-join算法需要构建过滤表达式以及一次额外的数据传输——将过滤表达式传到大表所在存储节点.因此,其适应于大表数据过滤后只有少量数据的情况.
1.5 分布式join算法
相比传统数据库处理join查询,分布式数据库处理复杂join查询时,可将join操作分解为多个join任务分配给多台机器独立执行,最后再将各部分join结果汇总.例如,文献[3]研究了如何将join操作分解成多个任务在Map/Reduce模型中执行.这类分布式join算法原理都是将一个完整的join操作分解成多个小的join操作,放在多个查询节点上并行执行,最终将网络传输代价、join计算代价分摊给多个查询处理节点.
2 分布式系统OceanBase中join算法的工作原理
2.1 nested loop join、merge sort join、Hash join算法工作原理
图1为nested loop join、merge sort join、Hash join流程图,其中,R表作为驱动表,S作为被驱动表,MS是查询处理节点,CS是数据存储节点.
join操作符左右各有一个Sort操作符和一个RpcScan操作符,其中RpcScan负责向CS存储节点请求数据.在存储节点CS上的Project、Filter操作符,用于过滤存储节点数据.当join查询产生时,join算法的左右两个子操作符RpcScan同时向CS请求数据,如果表数据量很大且没有附带充分的过滤条件,将会产生非常大的数据网络传输代价.请求得到的数据在join算子处进行逐行join操作.
2.2 基于semi-join的join工作原理
图2为基于semi-join的join流程图,其中,R表作为驱动表,S作为被驱动表,MS是查询处理节点,CS是数据存储节点.

图1 nested loop join、merge sort join、Hash join执行计划Fig.1 Nested loop join,merge sort join,Hash join execution plan
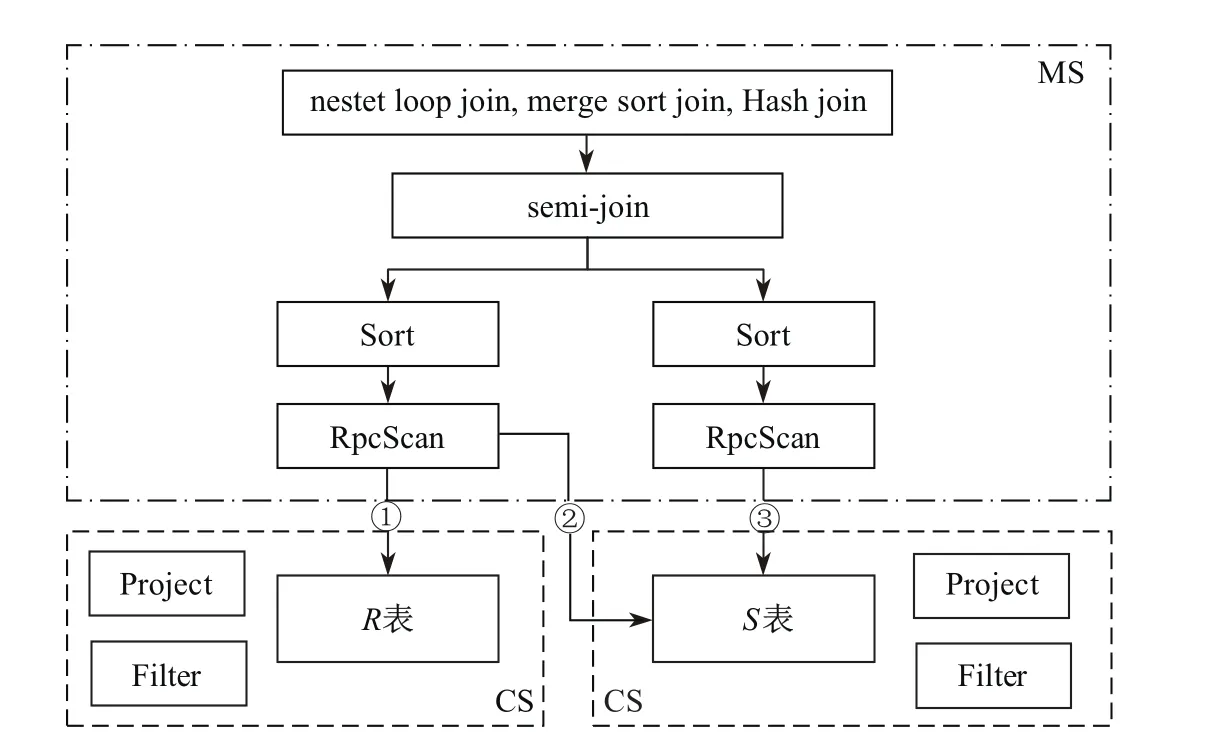
图2 基于semi-join的join执行计划Fig.2 Execution plan of join based on semi-join
基于semi-join的join算法步骤如下.
(1)向R表所在的CS并行发出请求,获得数据,这里获得的数据是经过Project和Filter过滤的、连接列上的、符合条件的数据.
(2)将(1)中所得到的数据构造成过滤表达式发送给S表所在的CS,之后会在S表所在的Server上执行这个过滤操作,过滤掉S表中不符合条件的数据.
(3)右表的RpcScan操作符开始拉去过滤后的S表数据.
(4)R表和S表过滤后的数据到达join操作符后,进行串行化逐行join.
3 并行优化设计
基于第2节描述的串行化逐行join情况,我们提出并行join优化方案.下面我们将对OceanBase数据库中的Hash join、nested loop join及semi-join进行并行优化设计.
3.1 Hash join的并行优化设计
首先,分配线程分别对两张表的数据调用Hash函数进行分区;然后根据分片数申请处理线程,每个线程读取一组对应分片数据后做连接操作;随后将输出结果发送给连接算子.具体流程如图3所示.

图3 Hash join的并行设计Fig.3 Parallel design of Hash join
1.首先分配两个线程,线程a和线程b,使用相同的Hash函数,并行地对R表和S表数据根据连接列进行分区处理,将R表分区成R1,R2,R3,…,Rn等多个结果集,同样将S表分成S1,S2,S3,…,S n,分区个数取决于具体的Hash函数.由于R表与S表的数据集大小不同,分区执行的时间也不同.因此,要等到两个线程分区工作都完成才能继续.如果出现两张表大小相差很大时,可以进一步分配多个线程对大表进行分区.这样,可以有效减少分区时间.
2.由于使用的Hash函数相同,对于分区后的结果集,我们将R1与S1对应,R2与S2对应,其他类似.
3.并行模块设置多个处理线程,线程1,线程2,线程3,…,线程n,分别对应2中的一组分区.每个线程并行地去各个存储节点拉取对应范围数据,随后进行join处理,例如,线程1负责〈R1,S1〉.多个线程同步执行,可以极大减少处理时间.处理线程具体步骤如下,以线程1为例.
(1)对R1分区的连接属性列,使用Hash函数构造Hash表T.
(2)对S1分区中的每一个连接列数据,使用相同的Hash函数对(1)中生成的Hash表T进行检测.
(3)如果S1分区中的连接列数据落在Hash表T中,则将对应行数据进行连接操作,生成中间结果集,并将结果集发送给连接算子操作符.
(4)处理线程结束,释放内存资源,清空环境信息,并重新挂起线程.
4.连接算子操作符接收处理线程发送过来的中间结果集,存在操作符内部的缓存区.直到所有数据集全部处理完,并接收到所有中间结果集,然后发送给客户端.
以上为Hash join的并行实现流程.并行设计体现在:首先,对于连接表数据读取进行并行操作;然后处理线程并行执行连接操作.
3.2 nested loop join的并行优化设计
与Hash类似,首先,分配线程对R表的数据进行切分;然后根据分片数申请线程,每个线程分别读取数据后将数据与S表做连接操作;随后将输出结果发送给连接算子.与Hashjoin的区别在于无需对S表进行切分.具体流程如图4所示.
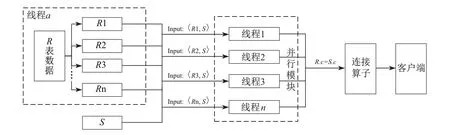
图4 nested loop join的并行设计Fig.4 Parallel design of nested loop join
1.首先分配一个线程,将R表分为等分的多个部分R1,R2,R3,…,Rn,具体分为多少部分由R的结果集和可用的线程数确定.
2.将1中R表等分产生的R1,R2,R3,…,Rn分别与S对应起来,例如〈R1,S〉,〈R2,S〉.
3.并行模块设置多个线程R1,R2,R3,…,Rn,分别对应2中的一组分区.每个线程并行地去各个存储节点拉取对应范围数据,随后进行join处理,例如,线程1负责〈R1,S〉,多线程同步执行.处理线程具体步骤如下,以线程1为例.
(1)R1作为外层循环表,S表作为内层循环表.
(2)将R1中的记录逐一与S表中的所有记录对比.如果对应连接列值匹配,则生成新的元祖作为中间结果集,执行这一操作,直到R1表中数据全部遍历完,并将结果集发给连接算子操作符.
(3)处理线程结束,释放内存资源,清空系统环境,重新挂起线程.
4.处理算子操作符接收处理线程发送过来的中间结果集,存在操作符内部的缓存区.直到所有数据集全部处理完,并接收到所有中间结果集,然后发送给客户端.
以上为nested loop join的并行实现流程.并行设计体现在:首先,多个线程并行地从存储节点读取相应范围的数据;然后处理线程并行执行连接操作.
3.3 semi-join的并行优化设计
首先,分配线程对R表的数据进行切分;然后根据分片信息申请线程,每个线程分别读取数据并构造过滤表达式,随后将输出结果发送给半连接算子.具体流程如图5所示.

图5 semi-jion并行设计Fig.5 Parallel design of semi-join
1.将R表结果集连接属性列等分为R1,R2,R3,…,Rn,具体分为多少份取决于系统资源以及R表结果集大小.
2.并行模块为R表结果集每个分片提供一个线程,各个处理线程分别拉取对应范围数据,并根据连接属性列信息并行执行过滤操作.此时的输出并非join结果集,而是S表中符合过滤条件的元组.随后提交给半连接操作符.处理线程具体步骤如下.
(1)根据输入R表分片信息构造过滤表达式.这里可以根据数据输入的R表结果集大小考虑构造In表达式或者Between表达式,具体构造哪种表达式取决于R表输入信息.
(2)将过滤表达式发送给S表所在存储节点.S表所在存储节点用过滤表达式根据连接属性列过滤S表数据.
(3)S表所在存储节点将符合条件的数据作为输出结果集发送到半连接操作符.
3.半连接接收处理线程陆续发来的结果集,并将结果集存在操作符内部的缓存区.当所有数据处理结束后,半连接算子操作符将缓存中的数据发送给连接算子操作符.此后,连接算子操作符才开始真正的join操作.
以上为semi-join的并行设计方案.并行设计体现在:根据R表输入并行构造过滤表达式;多线程并行读取各分片对应过滤表达式信息,随后并行用过滤表达式过滤S表数据;各连接算子并行做join操作.
4 实验分析
首先,测试不同并行度下,单表读取数据的效率;其次,测试在不同并行度下传统join算法的执行效率;最后,测试不同并行度下基于semi-join算法的传统join算法执行效率.
4.1 实验软件环境
本文选择OceanBase系统作为实验系统环境.实验使用5台服务器,OceanBase的实验版本为0.4.2,其中主控节点RS与UPS共用一台服务器,其余4台服务器分别部署CS与MS.整个OceanBase数据库集群中3台CS,1台MS.实验环境的OceanBase集群物理拓扑如图6所示.
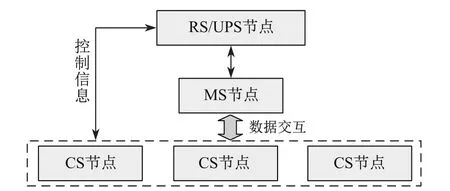
图6 OceanBase实验环境物理拓扑Fig.6 Physical topology of OceanBase experimental environment
4.2 实验硬件环境
本文测试所用硬件环境如表1所示,其中磁盘为SSD(Solid State Drive).

表1 集群服务器配置Tab.1 The cluster server conf i guration
4.3 实验数据集
本文测试用到的所有数据表的模式如表2所示.

表2 测试表的模式Tab.2 The schema of the test table
所有实验数据都是由Sysbench的数据生成器生成.实验一共涉及7张表,数据分布以及数据量如表3所示.

表3 测试数据表信息Tab.3 Test data table information
以R1为例,数据分布的连续性是指R1表的主键列ID的数据是按照升序排列的.
4.4 不同并行度下的连接查询响应时间
实验目的:单表情况下并行度以及数据过滤方式对查询响应时间的影响.
数据设置:使用表R2作为测试表,结果集为100万,并发度分别为1、5、15、20、25、30、35,数据过滤方式为主键定位、In表达式、Between表达式.
实验结果如图7所示.

图7 不同并行度单表数据查询的响应时间Fig.7 Response time for single table query with di ff erent parallel number
从实验结果可以得出,随着并行度的增加,响应时间总体呈下降趋势.因此通过并行的方式来提高数据的过滤速度,对减少连接查询的响应时间是有效的.
4.5 连接算子的执行效率
图8所示为在不同的并行度下,各连接算法的执行效率.在并行度为1的情况下,nested loop join在处理100万条数据的连接计算时花费的时间在78 s左右.由于与其他连接算子的响应时间相差太大,因此没有在图中完全显示.随着并行度的增加,各连接算子的响应时间都有所降低.

图8 不同并行度下连接算法的执行效率Fig.8 Execution effi ciency of join algorithms with dif f erent parallel number
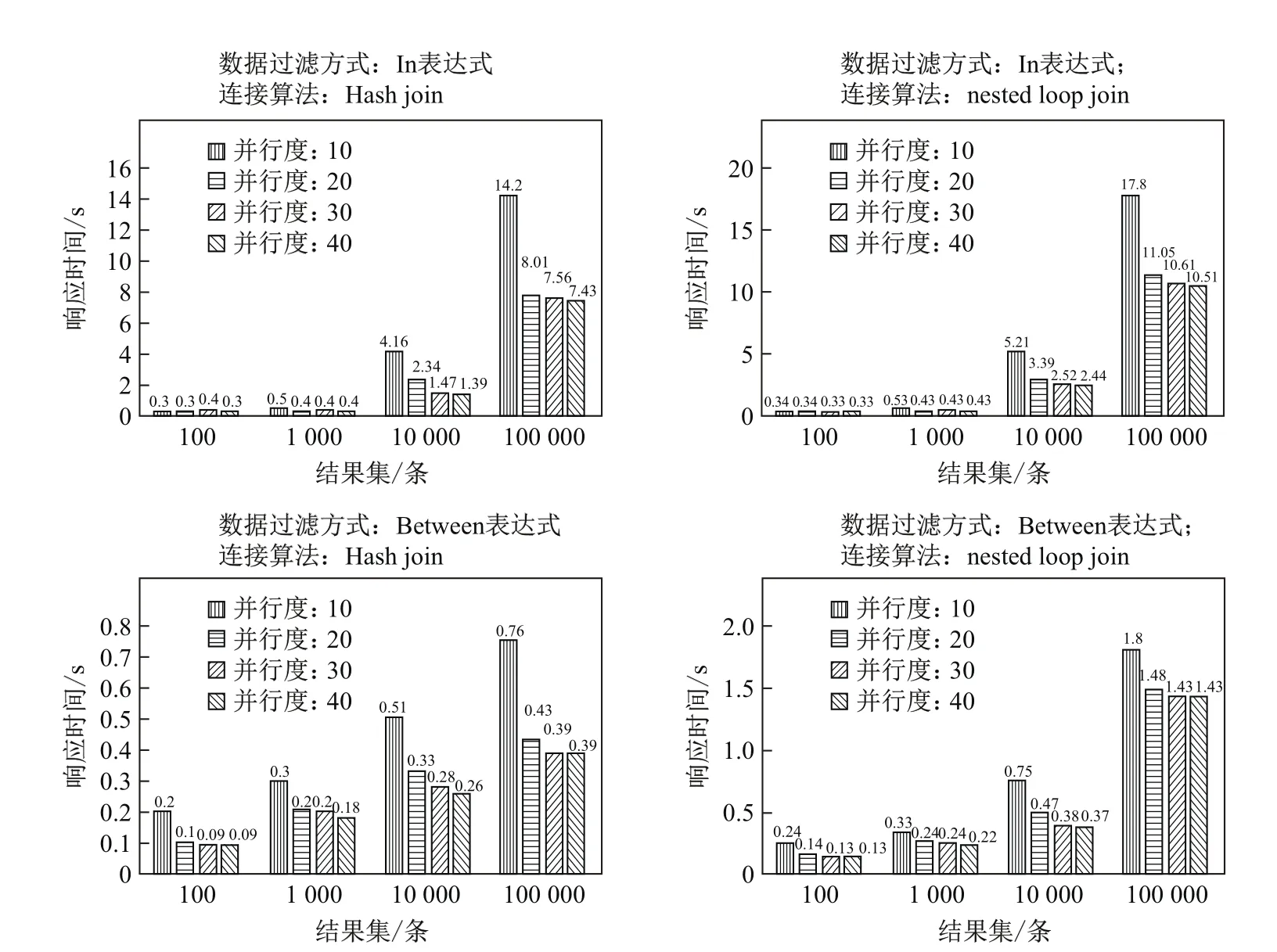
图9 不同并行度下基于semi-join的join执行效率Fig.9 Execution effi ciency of join based on semi-join in dif f erent parallel number
4.6 semi-join下各join算法的查询效率
如图9所示,随着并行度的提高,Hash join、nested loop join的响应时间都在逐渐降低.特别地,当结果集不断变大时响应时间的下降速度也随之加快.但是当并行度超过20后,响应时间的变化就变得不是非常明显,原因在于数据库系统的计算能力受制于服务器CPU的核心数目;而用于本文实验的服务器,在采用超线程技术后,可用的核心数目为24个,当并行度超过20后就有明显的调度以及资源争用问题,原因是,一方面受CPU核心数目的限制,另一方面本文也没有将任务线程与相应的CPU核心进行绑定,因此可能出现多个任务线程共用一个核心的情况.
5 总结
本文提出了一种在分布式数据库系统OceanBase中对传统Hash join、nested loop join等算法以及semi-join算法的并行连接优化方案,并且在OceanBase中进行了实验验证.该优化方案充分利用了分布式数据库多数据节点和服务器多核的特点.实验结果验证了并行连接优化的有效性:在服务器线程总数内,传统join算法和基于semi-join的传统join算法执行效率都有所提高.但是本文方案还有进一步优化的空间.如何根据数据分布信息动态选择使用何种join算法、如何实现线程资源的极大化利用、如何实现不同查询处理节点间的交互、如何实现多个查询处理节点间的协同工作,这些都将是以后研究的重点.
[1]杨传辉.大规模分布式存储系统[M].北京:机械工业出版社,2013.
[2]BERNSTEIN P A,GOODMAN N,WONG E,et al.Query processing in a system for distributed databases (SDD-1)[J].ACM Transactions on Database Systems,1981,6(4):602-625.
[3]ZHANG X F,CHEN L,WANG M.Effi cient multi-way theta-join processing using MapReduce[J].Proceedings of the VLDB Endowment,2012,11(5):1184-1195.
[4]BLASGEN M W,ESWARAN K P.Storage and access in relational databases[J].IBM Systems Journal,1977, 16(4):363-377.
[5]ZHOU J R,ROSS K A.Implementing database operations using SIMD instructions[C]//Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data.2002:145-156.
[6]ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:Cluster computing with working sets[C/OL]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing.(2010-06-25)[2017-04-01].https://www.usenix.org/legacy/events/hotcloud10/tech/full papers/Zaharia.pdf?CFID=973306186& CFTOKEN=67460167.
[7]MERRETT T H.Why sort-merge gives the best implementation of the natural join[J].ACM Sigmod Record, 1983,13(2):39-51.
[8]KIM C,PARK J,SATISH N,et al.CloudRAMSort:Fast and effi cient large-scale distributed RAM sort on shared-nothing cluster[C]//ACM SIGMOD International Conference on Management of Data.ACM,2012: 841-850.
[9]BABB E.Implementing a relational database by means of specialzed hardware[J].ACM Transactions on Database Systems,1979,4(1):1-29.
[10]BONCZ P A,ZUKOWSKI M,NES N.MonetDB/X100:Hyper-pipelining query execution[C/OL]//Proceedings of the 2005 CIDR Conference on Innovative Data Systems Research.2005:225-237[2017-04-01]. https://www.researchgate.net/publication/45338800 MonetDBX 100 Hyper-Pipelining Query Execution.
(责任编辑:李艺)
Parallel join based on distributed system OceanBase
XU Shi-lei,WANG Lei,HU Hui-qi,QIAN Wei-ning,ZHOU Ao-ying
(School of Computer Science and Software Engineering,East China Normal University, Shanghai 200062,China)
With the rapid growth of application data and the continued development of distributed database systems,data storage in physical independent nodes has become a trend.In this trend,when the application needs to perform complex join queries,it inevitably generates a lot of network traffi c.Therefore,improving the effi ciency of join query in distributed system is a hot topic.Based on the analysis of the nested loop join, Hash join,semi-join in the OceanBase,this paper puts forward the optimization idea of using hardware resources reasonably and using multithread to execute join operations in parallel.We implement experiment on OceanBase with nested loop join algorithm,Hash join algorithm,semi-join algorithm respectively.The experimental results conf i rm that the effi ciency of join algorithm is positively related to parallelism in a certain number of threads.
query;semi-join;OceanBase;parallel join
TP392
A
10.3969/j.issn.1000-5641.2017.05.001
1000-5641(2017)05-0001-10
2017-06-19
2017年上海市青年科技英才扬帆计划(17YF1427800)
徐石磊,男,硕士研究生,研究方向为数据存储与数据挖掘.E-mail:xsl118857@sina.com.
胡卉芪,男,助理研究员,研究方向为数据库.E-mail:hqhu@dase.ecnu.edu.cn.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
山西电子技术(2021年3期)2021-06-28
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
应用数学(2020年2期)2020-06-24
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
现代计算机(2019年6期)2019-04-08
